- 1Python+Appium+夜神模拟器 全流程从环境搭建到实现自动化(APP自动化)_如何实现appinum控制夜神模拟器
- 2华为应用市场上传APP失败多次因为:您的应用在用户同意隐私政策前申请获取用户的(MAC地址)个人信息。_华为上传app,隐私链接怎么设置不了
- 3【NLP入门教程】十三、Word2Vec保姆教程_word2vec教程
- 4【8个Python数据清洗代码,拿来即用】_python进行文本清洗时的去除噪声的代码
- 5Docker 基础 ( 二十 ) 部署Redis集群,问题记录_could not connect to redis at 127.0.0.1:6380 创建集群
- 6【开题报告】基于SpringBoot的在线乐器购物商城的设计与实现_陈刚. 基于spring boot+thy me leaf+mysql的动态表单功能模块设计与实现
- 7Linux命令行模式安装VMware Tools详解_linux安装vmware tools
- 8【Python Django Web项目】利用 Python+Django+Pycharm+MySQL 搭建一个自己的Web网站项目的步骤(详细图文)上集
- 9WEB渗透之文件包含漏洞_include($demo); 漏洞
- 10了解机器学习(深度学习)的几个特点_机器学习系统的特点
医疗Transformer应用综述_医学图像分割中的transformer
赞
踩
医疗Transformer应用综述
Transformers in Medical Imaging: A Survey
Abstract
在自然语言任务上取得了前所未有的成功后,Transformers 已成功地应用于若干计算机视觉问题,取得了最新的成果,并促使研究人员重新考虑卷积神经网络(CNN)作为事实上的算子的优越性。利用计算机视觉的这些进步,医学成像领域也见证了对Transformers 的兴趣日益增长,与具有局部感受野的CNN相比,Transformers 能够捕捉全局环境。受这一转变的启发,在本次调查中,我们试图全面回顾Transformers 在医学成像中的应用,涵盖各个方面,从最近提出的结构设计到尚未解决的问题。具体来说,我们调查了Transformers 在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的使用。特别是,对于这些应用程序中的每一个,我们都开发了分类法,确定了特定于应用程序的挑战,并提供了解决这些挑战的见解,并强调了最近的趋势。此外,我们还对该领域的整体现状进行了批判性讨论,包括确定关键挑战、公开问题,并概述了有希望的未来方向。我们希望这项调查将激发社区的进一步兴趣,并为研究人员提供有关Transformers 模型在医学成像中应用的最新参考。最后,为了应对这一领域的快速发展,我们打算定期更新相关的最新论文及其开源实现https://github.com/fahadshamshad/awesome-transformers-in-medical-imaging.
1 INTRODUCTION
Convolutional Neural Networks(CNN)[1]–[4]由于能够以数据驱动的方式学习高度复杂的表示,对医学成像领域产生了重大影响。自其复兴以来,CNN在许多医学成像方式上取得了显著的进步,包括放射照相术[5]、内窥镜检查[6]、计算机断层扫描术(CT)[7]、[8]、乳房X光摄影图像(MG)[9]、超声图像[10]、磁共振成像(MRI)[11]、[12]和正电子发射断层扫描术(PET)[13],等等。CNN中的主力是卷积算子,它在局部操作并提供平移等变。虽然这些特性有助于开发高效且通用的医学成像解决方案,但卷积运算中的局部感受野限制了捕捉远距离像素关系。此外,卷积滤波器具有在推断时不适合给定输入图像内容的平稳权重。
与此同时,视觉界已经做出了重大的研究努力,将注意力机制[14]–[16]整合到CNN启发的架构[17]–[22]中。这些基于注意力的“Transformer”模型已经成为一个有吸引力的解决方案,因为它们能够编码长期依赖关系并学习高效的特征表示.最近的研究表明,通过对一系列图像块进行操作,这些Transformers 模块可以完全取代深度神经网络中的标准卷积,从而产生视觉Transformers (VIT)[22]。自其诞生以来,ViT模型已被证明在许多视觉任务中推动了最先进的技术,包括图像分类[22]、目标检测[24]、语义分割[25]、图像着色[26]、低级视觉[27]和视频理解[28]等等。此外,最近的研究表明,与CNN相比,VIT的预测误差更符合人类的预测误差[29]–[32]。VIT的这些理想特性引起了医学界的极大兴趣,使其适应医学成像应用,从而减轻了CNN固有的感应偏差[33]。
Motivation and Contributions:
最近,医学成像界见证了基于Transformers 的技术的数量呈指数级增长,尤其是在ViTs问世之后(见图1)。这个话题现在在著名的医学影像会议和期刊上占据主导地位,由于论文的迅速涌入,要跟上最近的进展变得越来越困难。因此,对现有相关工作的调查是及时的,以便全面介绍这一新兴领域的新方法。为此,我们对Transformers 模型在医学成像中的应用进行了全面概述。我们希望这项工作能为研究人员进一步探索这一领域提供路线图。我们的主要贡献包括:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L3dc41dd-1651114044172)(D:/Typora_img/image-20220426100459974.png)]](https://img-blog.csdnimg.cn/a0600c68695142c1a8ba2316e7e70eb2.png)
1)、这是第一篇全面介绍Transformers在医学成像领域的应用的调查论文,从而弥合了这一快速发展领域的视觉和医学成像界之间的差距。具体而言,我们将对125多个相关项目进行全面概述报道最新进展的论文。
2)、我们通过根据论文在医学成像中的应用对其进行分类,提供了该领域的详细报道,如图2所示。对于这些应用程序中的每一个,我们都开发了一个分类法,强调了特定于任务的挑战,并根据回顾的文献提供了解决这些问题的见解。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ChRMKZ1o-1651114044173)(D:/Typora_img/image-20220426101211844.png)]](https://img-blog.csdnimg.cn/741fc252ace24cfc914ff9b308ae453b.png)
3)、最后,我们从整体上对该领域的现状进行了批判性讨论,包括确定关键挑战、突出未决问题,以及概述有希望的未来方向。
4)、虽然本次调查的主要重点是视觉Transformers,但我们也是自大约五年前最初的Transformer问世以来,第一个在临床报告生成任务中广泛介绍其语言建模能力的人(见第9节)。
Paper Organization
论文的其余部分组织如下。在Sec.2中,我们提供该领域的背景知识,重点介绍Transformers的重要概念。 从Sec3到Sec10.如图2所示,我们全面介绍了Transformers在几种医学成像任务中的应用。特别是,对于这些任务中的每一项,我们都开发了一个分类法,并确定了特定于任务的挑战。Sec11提出了整个领域的开放性问题和未来方向。最后,在Sec。12.我们提出了应对该领域快速发展的建议,并对论文进行了总结。
2 BACKGROUND
在过去几十年里,医学成像方法取得了重大进展。在本节中,我们简要介绍了这些进展的背景,并将其大致分为三类:手工制作、基于CNN和基于ViT。对于手工制作的和基于CNN的方法,我们描述了基本的工作原理,以及它们在医学成像方面的主要优点和缺点。对于基于ViT的方法,我们强调了其成功背后的核心概念,并将进一步的细节推迟到后面的章节。
2.1 Hand-Crafted Approaches
略
2.2 CNN-based methods
CNN能够有效地学习区分性特征,并从大规模医学数据集中提取可概括的先验知识,从而在医学成像任务中提供优异的性能,使其成为基于人工智能的现代医学成像系统的一个组成部分。CNN的进步主要得益于新颖的体系结构设计、更好的优化程序、特殊硬件(如GPU)的可用性和专门构建的开源软件库[64]–[66]。我们向感兴趣的读者推荐与CNNs在医学成像中的应用相关的综合调查论文[56],[67]–[75]。尽管表现相当出色,然而,CNN对大型标记数据集的依赖限制了其在全谱医学成像任务中的适用性。此外,基于CNN的方法通常更难解释,并且通常充当黑盒解决方案。因此,医学成像界越来越努力地融合手工制作和基于CNN的方法的优势,从而产生了先验信息引导的CNN模型[76]。这些混合方法包含特定领域的特殊层,包括展开优化[77]、生成模型[78]和基于学习的去噪方法[79]。尽管有这些架构和算法上的进步,CNN成功背后的决定性因素主要归因于它们在处理尺度不变性和建模局部视觉结构方面的图像特定归纳偏见。虽然这种固有的局部性(有限的感受野)为CNN带来了效率,但它削弱了CNN在输入图像中捕捉长距离空间相关性的能力,从而导致性能停滞[33](见图3)。这就需要一种能够模拟远距离像素关系的替代架构设计,以便更好地进行表征学习。
2.3 Transformers
Vaswani等人[14]引入了Transformers,作为机器翻译的一个新的注意力驱动构建块。具体地说,这些注意块是神经网络层,从整个输入序列中聚合信息[80]。从一开始,这些模型就在多个自然语言处理(NLP)任务上展示了最先进的性能,因此成为了循环模型的默认选择。在本节中,我们将重点介绍基于vanilla Transformer模型[14]的视觉Transformers(VIT)[22],它通过级联多个Transformers层来捕获输入图像的全局上下文。具体来说,Dosovitskiy等人[22]将图像解释为一系列补丁,并使用NLP中使用的标准Transformers编码器对其进行处理。这些ViT模型延续了从模型中去除手工制作的视觉特征和归纳偏见的长期趋势,以利用更大数据集的可用性,同时增加计算能力 ,ViTs在医学影像学界引起了极大的兴趣,最近提出了许多基于ViTs的方法。在用于医学图像分类的算法1中,我们逐步强调了ViT的工作原理。
Algorithm 1 ViT Working Principle
1:S将医学图像分割为固定大小的patch
2:通过展平操作分割图像patch
3:通过可训练线性层从矢量化patch创建低维线性嵌入
4:将位置编码添加到低维线性嵌入
5:将序列输入到ViT编码器,如图4所示
6:在大规模图像数据集上预训练ViT模型
7:在下游医学图像分类任务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pDk94JlL-1651114044173)(D:/Typora_img/image-20220426105332932.png)]](https://img-blog.csdnimg.cn/5c61da33f67f4e72b0a7f222c1a31739.png)
下面,我们简要介绍了ViTs成功背后的核心要素,即自我关注和多头自我关注。为了对众多ViT体系结构和应用程序进行更深入的分析,我们请感兴趣的读者参考最近的相关调查论文[23]、[81]–[84]。
2.3.1 Self-Attention
Transformer模型的成功被广泛归因于自我注意(SA)机制,因为它能够模拟长期依赖性。SA机制背后的关键思想是学习自对准,即确定单个token(补丁嵌入)相对于序列中所有其他令牌的相对重要性[80]。对于2D图像,我们首先重塑图像 x ∈ R H × W × C x∈R^{H×W×C} x∈RH×W×C为一系列平坦的二维patch x p ∈ R N × ( P 2 C ) x_p∈ R^{N×(P^2C)} xp∈RN×(P2C),其中H和W分别表示原始图像的高度和宽度,C是通道数,P×P是每个图像块的分辨率, N = H W / p 2 N=HW/p^2 N=HW/p2是生成的块数。这些平坦的patch通过可训练的线性投影层投影到D维,并且可以用矩阵形式表示为X∈ RN×D**.自我关注的目标是捕捉所有目标之间的互动通过定义三个可学习的权重矩阵**将输入X转换为Queries(通过 W Q ∈ R D × D q W^Q∈ R^{D×Dq} WQ∈RD×Dq),Keys(通过 W K ∈ R D × D k W^K∈ R^{D×Dk} WK∈RD×Dk)和Values(通过 W V ∈ R D × D v W^V∈ R^{D×Dv} WV∈RD×Dv),其中 D q = D k D_q=D_k Dq=Dk。首先将输入序列X投影到这些权重矩阵上,得到 Q = X W Q Q=XW^Q Q=XWQ、 K = X W K K=XW^K K=XWK和 V = X W V V=XW^V V=XWV。相应的注意矩阵 A ∈ R N × N A∈ R^{N×N} A∈RN×N可以写成:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eUdxHJTe-1651114044174)(D:/Typora_img/image-20220426111313841.png)]](https://img-blog.csdnimg.cn/437e637583344521a1d6e1562f51dd4d.png)
输出 Z ∈ R N × D v Z∈ R^{N\times Dv} Z∈RN×Dv然后,SA层由下式给出:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iR1aK9Iz-1651114044175)(D:/Typora_img/image-20220426111513859.png)]](https://img-blog.csdnimg.cn/8be311806a6d473db13cf8ffc4099070.png)
2.3.2 Multi-Head Self-Attention
多头自我注意(MHSA)由多个SA块(头部)组成,这些SA块按通道连接在一起,以模拟输入序列中不同元素之间的复杂依赖关系。每个头部都有自己的可学习权重矩阵,用{ W Q i , W K i , W V i W^{Q_i},W^{K_i},W^{V_i} WQi,WKi,WVi表示,其中i=0···(h−1) h表示MHSA块中的头总数。具体来说,我们可以写,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gUZXDelJ-1651114044176)(D:/Typora_img/image-20220426111736721.png)]](https://img-blog.csdnimg.cn/ca6ce5b2e4b3488fbda6b992f346422c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xKkwYOZj-1651114044176)(D:/Typora_img/image-20220426111808384.png)]](https://img-blog.csdnimg.cn/d146a7f542b042fb9741ca5755f82962.png)
请注意,计算SA块的softmax的复杂性与输入序列的长度有关,这可能会限制其对高分辨率医学图像的适用性。最近,人们做出了大量努力来降低复杂性,包括稀疏注意[85]、线性化注意[86]、低秩注意[87]、基于记忆压缩的方法[88]和改进的MHSA[89]。我们将在相关章节中结合医学成像讨论有效的SA。
此外,我们发现有必要澄清,基于卷积结构的文献中已经探讨了几种替代注意方法[90]–[93]。在这项调查中,我们重点关注Transformers模块(MHSA)中使用的特殊注意,它最近在医学图像分析中获得了重要的研究关注。接下来,我们将概述这些根据特定应用领域分类的方法。
3 MEDICAL IMAGE SEGMENTATION
准确的医学图像分割是计算机辅助诊断、图像引导手术和治疗计划的关键步骤。Transformers的全局上下文建模能力对于精确的医学图像分割至关重要,因为通过建模空间距离像素之间的关系(例如,肺部分割),可以对分布在大感受野上的器官进行有效编码。此外,医学扫描中的背景通常是分散的(例如,超声扫描[94]);因此,学习与背景对应的像素之间的全局上下文可以帮助模型防止误分类。下面,我们将重点介绍集成基于VIT的医学图像分割模型的各种尝试。我们将基于ViT的分割方法大致分为器官特异性和多器官类别,如图5所示,这是因为两种方法都需要不同程度的上下文建模。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3XYDooXR-1651114044177)(D:/Typora_img/image-20220426112207989.png)]](https://img-blog.csdnimg.cn/5257925a190543d7884ede62281a49ec.png)
下面,我们将重点介绍集成基于VIT的医学图像分割模型的各种尝试。我们将基于ViT的分割方法大致分为器官特异性和多器官类别,如图5所示,这是因为两种方法都需要不同程度的上下文建模。
3.1 Organ-Specific Segmentation
基于ViT的器官特异性方法通常考虑基础器官的特定方面,以设计建筑构件或丧失功能。我们在本节中提到了此类设计选择的具体示例。根据输入类型,我们进一步将特定器官分类为基于2D和3D的方法。
3.1.1 2D Segmentation
在这里,我们描述了基于器官特异性ViT的二维医学扫描分割方法。
Skin Lesion Segmentation
准确的皮肤病变分割对于识别黑色素瘤(癌细胞)至关重要用于癌症诊断和后续治疗计划。然而,由于皮肤损伤区域的颜色、大小、遮挡和对比度存在显著差异,导致边界模糊[98],从而导致分割性能恶化,因此这仍然是一项具有挑战性的任务。为了解决边界模糊的问题,Wang等人[97]提出了一种新的边界感知Transformers(BAT)。具体来说,他们在Transformer架构中设计了一个边界智能注意门,以利用关于边界的先验知识。边界注意门的辅助监督为有效训练蝙蝠提供反馈。ISIC 2016+PH2[99]、[100]和ISIC 2018[101]上的大量实验验证了其边界先验的有效性,如图6所示。类似地,Wu等人[102]提出了一种基于双编码器的特征自适应Transformers网络(FAT-Net),该网络由编码器中的CNN和Transformers分支组成。为了有效地融合这两个分支的特征,设计了一个内存高效的解码器和特征自适应模块。ISIC 2016-2018[99]、[101]、[103]和PH2[100]数据集上的实验证明了FAT-Net融合模块的有效性。
Tooth Root Segmentation
牙根切分是根管治疗中治疗牙周炎(牙龈感染)的关键步骤之一[104]。然而,由于边界模糊、曝光过度和曝光不足,这是一个挑战。为了应对这些挑战,Li等人[105]提出了组TransformersU-Net(GT U-Net),它由Transformers层和卷积层组成,分别对全局和局部上下文进行编码。提出了一种形状敏感的傅立叶描述子损失函数[106]来处理模糊的牙齿边界。此外,GT U-Net还引入了分组和瓶颈结构,以显著降低计算成本。在他们的内部牙根分割数据集上进行了六个评估指标的实验,证明了GT U-Net体系结构组件和基于傅立叶的损失函数的有效性。在另一项工作中,Li等人[107]提出了一种多分支Transformers(AGMBTransformers),以结合群卷积[108]和渐进Transformers网络的优点。在他们自己收集的245张牙根X射线图像数据集上的实验表明了AGMBTransformers的有效性。
Cardiac Image Segmentation
尽管Transformers在医学图像分割方面有着令人印象深刻的性能,但它们在计算上要求很高,而且参数预算也很高。为了应对心脏图像分割任务面临的这些挑战,邓等人[109]提出了一种轻量级参数高效混合模型TransBridge。TransBridge由Transformers和基于CNN的编解码结构组成,用于超声心动图中的左心室分割。具体来说,使用shuffling层[110]和组卷积重新设计了Transformers的补丁嵌入层,以显著减少参数数量。在大规模左心室分割数据集、回声心动图[111]上进行的大量实验证明了TransBridge方法优于CNN和基于Transformers的基线方法[112]。
Kidney T umor Segmentation
通过计算机诊断系统精确分割肾脏肿瘤可以减少放射科医生的工作量,是相关外科手术的关键步骤。然而,由于肾脏肿瘤的大小不同,以及肿瘤与其解剖环境之间的对比,这是一个挑战。为了应对这些挑战,Shen等人[117]提出了一种混合编码器体系结构COTR Net,它由卷积层和Transformers层组成,用于端到端肾脏、肾囊肿和肾肿瘤的分割。具体地说,COTR网络的编码器由几个卷积Transformers块组成,解码器由几个上采样层组成,这些上采样层具有来自编码器的跳转连接。编码器权重已使用预先训练过的ResNet[118]架构进行初始化,以加速收敛,并在解码器层中利用深度监督来提高分割性能。此外,将形态学操作作为后处理步骤来细化分割模板。在肾脏肿瘤分割数据集(KiTS21)[119]上进行的大量实验证明了COTR网络的有效性。
Cell Segmentation
受检测Transformers(DETR)[132]的启发,Zhang等人提出了Cell DETR[133],这是一个基于Transformers的框架,用于生物细胞的分割。具体来说,他们将一个专门的注意力分支集成到DETR框架中,以获得除框预测之外的瞬时分割掩码。在训练过程中,焦点丢失[134]和索伦森骰子丢失[132]用于分割分支。为了提高性能,他们在Cell DETR中集成了三个剩余解码器块[118],以生成准确的实例掩码。在其内部酵母细胞数据集上的实验证明了Cell DETR相对于基于U-Net的基线的有效性[114]。类似地,由于受试者的运动导致边缘模糊,现有的医学图像分割方法通常难以获得角膜内皮细胞[135]。这就要求保留更多的地方细节,充分利用全球环境。考虑到这些属性,Zhang等人[136]提出了一种由卷积层和Transformers层组成的多分支混合Transformers网络(MBT网络)。具体来说,他们提出了bodyedge分支,该分支提供精确的边缘位置信息,并促进局部一致性。对他们自行收集的TM-EM3000和角膜内皮细胞的公共泽泻碱数据集[137]进行的广泛消融研究表明,MBT网络结构组件是有效的。
Histopathology.
组织病理学是指在显微镜下对组织疾病进行诊断和研究,是癌症识别的金标准。因此,组织病理学图像的精确自动分割可以大大减轻病理学家的工作量。最近,Nguyen等人[131]根据PAIP肝脏组织病理学数据集的整张幻灯片图像,系统地评估了六种最新VIT和基于CNN的方法的性能[130]。他们的结果(如表1所示)表明,几乎所有基于Transformers的模型确实表现出优于基于CNN的方法的性能,因为它们能够对全球环境进行编码。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kamECTBJ-1651114044177)(D:/Typora_img/image-20220427084829118.png)]](https://img-blog.csdnimg.cn/428fd7c8c03e4281bbe30f9d3ff6bf10.png)
3.1.2 3D Medical Segmentation
在这里,我们描述了基于ViT的体积医学数据分割方法。
Brain Tumor Segmentation.
自动准确的脑肿瘤分割方法可以及时诊断阿尔茨海默病等神经系统疾病。最近,基于ViT的模型被提出来有效分割脑肿瘤。Wang等人[138]通过在空间和深度维度上有效地建模局部和全局特征,首次尝试利用Transformers进行3D多模式脑肿瘤分割。具体来说,他们的编码器-解码器架构TransBTS使用3D CNN提取局部3D体积空间特征,并使用Transformers对全局特征进行编码。基于3D CNN的解码器中的渐进式上采样用于预测最终的分割图。为了进一步提高性能,他们利用了测试时间的增加。在BraTS 20191和BraTS 20202数据集上进行的大量实验表明,与基于CNN的方法相比,他们提出的方法是有效的。与大多数基于ViT的图像分割方法不同,TransBTS不需要在大型数据集上进行预训练,而是从头开始训练。在另一项工作中,受TransBTS[138]建筑设计的启发,Jia等人[139]提出了Bi Transformer U-Net(BiTr UNet),该网络在BraTS 2021[140]分段挑战中表现相对较好。与TransBTS[138]不同,BiTr UNet由一个注意模块组成,用于完善编码器和解码器功能,并有两个ViT层(而不是TransBTS中的一个ViT层)。此外,BiTr-UNet采用后处理策略,如果预测分割的体积小于阈值[141],则消除该体积,然后通过多数投票进行模型集成[142]。类似地,Peiris等人[143]提出了一种重量轻的UNet形体积TransformersVT UNet,以分层方式分割3D医学图像模式。具体来说**,VT UNet的编码器中引入了两个自我注意层,以捕获全局和局部上下文**。此外,在解码器中引入基于窗口的自我注意和交叉注意模块以及傅里叶位置编码,显著提高了VT UNet的准确性和效率。在BraTs 2021[140]上的实验表明,VT UNet对数据伪影具有鲁棒性,并具有很强的泛化能力。在另一项类似的工作中,Hatamizadeh等人[145]提出了基于Swin-UNet的架构Swin-UNETR,该架构由作为编码器的Swin transformer和基于CNN的解码器组成。具体而言,Swin-UNETR采用高效的移位窗口划分方案计算自我注意,是BraTs 2021[140]验证集上性能最好的模型。在表2中,我们为3D multimodal BraTs 2021数据集提供了各种基于Transformers的模型的dice分数和其他参数【140】。
Histopathology.
Boxiang等人[116]提出了用于高光谱病理图像的光谱Transformers(SpecTr) 分割,它使用Transformers来学习光谱维度的上下文特征。为了丢弃不相关的光谱带,他们引入了一种基于稀疏性的方案[146]。此外,它们对每个波段采用单独的分组归一化,以消除光谱图像之间分布不匹配造成的干扰。在高光谱病理数据集胆管癌[147]上进行的大量实验显示了SpecTr的有效性,如图7所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TOAJnV7s-1651114044178)(D:/Typora_img/image-20220427085921587.png)]](https://img-blog.csdnimg.cn/55c793a2c8c14de8a0aa001e6ac05632.png)
Breast Tumor Segmentation
在早期发现乳腺癌可以将死亡率降低40%以上[148]。因此,乳腺肿瘤的自动检测对医生来说非常重要。最近,Zhu等人[149]提出了一种区域感知Transformers网络(RAT Net),可以有效地将乳腺肿瘤区域信息融合到多个尺度,以获得精确的分割。在大型超声乳腺肿瘤分割数据集上进行的大量实验表明,RAT Net优于CNN和基于transformer的基线。类似地,Liu等人[150]还提出了一种混合架构,该架构由3D UNet[151]解码器部分的Transformers层组成,以有效地从体积乳腺数据中分割肿瘤。
3.2 Multi-organ Segmentation
多器官分割的目的是同时分割多个器官,由于类间不平衡以及不同器官的大小、形状和对比度不同,因此具有挑战性。ViT模型特别适合于多器官分割,因为它们能够有效地建模全局关系并区分多个器官。我们根据架构设计对多器官分割方法进行了分类,因为这些方法不考虑任何器官特定的方面,通常侧重于通过设计高效的架构模块来提高性能[152]。我们将多器官分割方法分为纯Transformers(仅ViT层)和混合结构(CNN和ViT层)。
3.2.1 Pure Transformers
纯Transformers结构仅由ViT层组成,与混合结构相比,其在医学图像分割中的应用较少,因为全局和局部信息对于分割等密集预测任务至关重要[96]。最近,Karimi等人[153]提出了一种基于纯Transformers的三维医学图像分割模型,该模型利用了三维医学图像块相邻线性嵌入之间的自我关注[17]。他们还提出了一种方法来有效地预培训他们只有少数标记图像可用时建模。大量实验表明,他们的无卷积网络在三个与大脑皮质板[154]、胰腺和海马相关的基准3D医学成像数据集上是有效的。在分割中使用纯Transformers模型的缺点之一是自我注意相对于输入图像维度的二次复杂性。这可能会妨碍ViTs在高分辨率医学图像分割中的适用性。为了缓解这个问题,Cao等人[125]提出了Swin-UNet,与Swin Transformer[126]一样,Swin-UNet在局部窗口内计算自我注意,并具有与输入图像相关的线性计算复杂性。Swin-UNet还包含一个用于上采样解码器特征映射的补丁扩展层,与双线性上采样相比,它在恢复细节方面表现出优越的性能。在Synapse和ACDC[155]数据集上的实验证明了Swin-UNet体系结构设计的有效性。
3.2.2 Hybrid Architectures
基于混合体系结构的方法结合了Transformers和CNN的互补优势,可以有效地建模全局环境并捕获局部特征,从而实现精确分割。我们进一步将这些混合模型分为单尺度方法和多尺度方法。
3.2.2.1 Single-Scale Architectures:
这些方法只在一个尺度上处理输入的图像信息,由于与多尺度结构相比计算复杂度较低,在医学图像分割中得到了广泛的应用。我们可以根据Transformers层在模型中的位置对单尺度体系结构进行细分。这些子类别包括Transformer
in Encoder, Transformer between Encoder and Decoder, Transformer in Encoder and Decoder, and T ransformer in Decoder.
Transformer in Encoder.
大多数最初开发的基于Transformers的医学图像分割方法在模型的编码器中有Transformers层。这一类的第一个工作是Transune[96],它由编码器中的12个Transformers层组成,如图8所示。这些Transformers层对来自CNN层的标记化图像块进行编码。通过解码器中的上采样层对得到的编码特征进行上采样,以输出最终的分割图。通过加入skip connection,Transune在synapse多器官分割数据集[156]和自动心脏诊断挑战赛(ACDC)[155]上创造了新记录(出版时)。在其他工作中,Zhang等人提出了输液[157],通过分流模块有效地融合Transformers和CNN层的特征。BiFusion模块利用自我关注和多模式融合机制,有选择地融合功能。在多个模式(2D和3D)上对输血进行广泛评估,包括息肉分割、皮损分割、髋部分割和前列腺分割,证明其有效性。Transune[96]和TransFuse[157]都需要在ImageNet数据集[158]上进行预训练,以有效地学习图像的位置编码。为了在没有任何预训练的情况下了解这种位置偏差,Valanarasu等人[128]提出了一种改进的门控轴向注意层[159],该层在小型医学图像分割数据集上运行良好。此外,为了提高分割性能,他们提出了一种局部-全局训练方案来关注输入图像的细节。在脑解剖分割[160]、腺体分割[161]和MoNuSeg(显微镜)[162]上进行的大量实验证明了他们提出的门控轴向注意模块的有效性。
在另一项工作中,Tang等人[163]介绍了Swin-UNETR,这是一种新的自监督学习框架,具有代理任务,可以在CT数据集的5050张图像上预训练Transformers编码器。他们根据MSD和BTCV分割数据集的下游任务,使用基于CNN的解码器微调Transformers编码器,从而验证预训练的有效性。类似地,Sobirov等人[164]表明,基于Transformers的模型可以在头颈部肿瘤分割任务上取得与基于CNN的最先进方法相当的结果。很少有工作通过以即插即用的方式将Transformers层集成到基于UNet的架构的编码器中来研究Transformers层的有效性。例如,Cheng等人[165]提出了TransClaw UNet,将Transformers层集成到爪形UNet的编码部分[166],以利用多尺度信息。与Synapse多器官分割数据集上的Claw-UNet相比,TransClaw-UNet在骰子分数上获得了0.6的绝对增益,并表现出良好的泛化能力。类似地,受LeViT[167]的启发,Xu等人[168]提出了LeViT UNet,旨在优化准确性和效率之间的权衡。LeViT UNet是一种多级体系结构,在Synapse和ACDC基准测试中表现出良好的性能和泛化能力。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1gEpj7IP-1651114044178)(D:/Typora_img/image-20220427092618902.png)]](https://img-blog.csdnimg.cn/cb2e89e1449c4f12aac152bb39871365.png)
Transformer between Encoder and Decoder.
在这一类中,Transformers层位于U形架构的编码器和解码器之间。这些架构更适合避免在编码器层中的下采样期间丢失细节。这一类的第一项工作是TransAttUNet[169],它利用引导注意力和多尺度跳转连接来增强传统TransUNet的灵活性。具体来说,在UNet的编码器和解码器之间嵌入了一个健壮的自我感知注意模块,以同时利用全局空间注意和变换器自我注意的表达能力。在五个基准医学图像分割数据集上的大量实验证明了Transattune架构的有效性。类似地,Yan等人[170]提出了轴向融合变换器UNet(AFTerUNet),该变换器在编码器和解码器之间包含一个计算效率高的轴向融合层,用于有效地融合用于3D医学图像分割的切片间和切片内信息。在BCV[171]、Thorax-85[172]和Segtor[173]数据集上的实验证明了他们提出的融合层的有效性。
Transformer in Encoder and Decoder.
为了更好地利用医学图像分割的全局环境,很少有工作将Transformers层集成到U形结构的编码器和解码器中。这一领域的第一项工作是UTNet,它有效地将自我注意机制的复杂性从二次型降低为线性[174]。此外,为了有效地建模图像内容,UTNet利用了二维相对位置编码[20]。实验表明,UTNet在多标签和多供应商心脏MRI挑战数据集队列中具有很强的泛化能力[175]。类似地,为了将卷积层和Transformers最佳地结合起来用于医学图像分割,Zhou等人[144]提出了NNFORER,一种基于交织编码器-解码器的架构,其中卷积层编码精确的空间信息,Transformers编码全局上下文,如图9所示。与Swin Transformers[126]一样,nnFormer中的自我注意在一个局部窗口内计算,以降低计算复杂度。此外,解码器层中的深度监控被用来提高性能。在ACDC和Synapse数据集上的实验表明,NNONER在Synapse数据集上比Swin-UNet[125](基于Transformers的医学分割方法)高出7%(dice分数)。在其他工作中,Lin等人提出了双Swin-Transformer-UNet(DS-TransUNet)[176],将Swin-Transformer的优点结合到医学图像分割的U形结构中。他们将输入图像分割成两个尺度上的非重叠块,并将它们输入编码器的两个基于SWITransformers的分支。提出了一种新的Transformers交互式融合模块,用于建立编码器中不同尺度特征之间的远程依赖关系。在与息肉分割、ISIC 2018、GLAS和Datascience bowl 2018相关的四个标准数据集上,DS TransUNet优于基于CNN的方法。
Transformer in Decoder.
Li等人[177]研究了在用于医学图像分割的UNet解码器中使用Transformers作为上采样块。具体来说,他们采用了基于窗口的自我注意机制,以更好地补充上采样特征图,同时保持效率。在MSD大脑和突触数据集上的实验表明,与双线性上采样相比,它们的结构具有优越性。在另一项工作中,Li等人[190]提出了SegTran,一种用于二维和三维医学图像分割的压缩和扩展Transformers。具体来说,挤压块使注意力矩阵正则化,而扩展块学习各种表示。此外,还提出了一种可学习的正弦位置编码,帮助模型对空间关系进行编码。对息肉、BraTS19和REFUGE20(眼底图像)分割挑战的大量实验表明,Segtran具有很强的泛化能力。
3.2.2.2 Multi-Scale Architectures:
这些结构以多个尺度处理输入,有效分割形状不规则、大小不同的器官。在这里,我们重点介绍了为医学图像分割集成多尺度体系结构的各种尝试。我们进一步根据输入图像类型将这些方法分为2D和3D分割类别。
2D Segmentation.
大多数基于ViT的多器官分割方法难以在多个尺度上捕获信息,因为它们将输入图像分割为固定大小的面片,从而丢失有用信息。为了解决这个问题,Zhang等人[183]提出了一种金字塔医疗TransformersPMTrans,它利用多分辨率注意力,使用金字塔结构在不同的图像比例下捕获相关性[201]。PMTrans通过自适应的贴片分割方案处理多分辨率图像,以访问不同的感受野,而不改变自我注意计算的总体复杂性。在GLAS[161]、MoNuSeg[184]和HECKTOR[189]三个医学成像数据集上进行的拉伸实验表明,利用多尺度信息是有效的。在其他工作中,Ji等人[39]提出了一种多复合变换器(MCTrans),它不仅可以学习相同语义类别的特征一致性,还可以捕获不同语义类别之间的相关性,以便进行准确的分割[202]。具体来说,MCTrans通过Transformer自我注意模块捕获跨尺度上下文依赖,并通过Transformer交叉注意模块学习不同类别之间的语义对应。为了提高同一语义范畴的特征相关性,还引入了辅助损失。在六个基准分割数据集上的大量实验证明了MCTrans体系结构组件的有效性。
3D Segmentation.
大多数多尺度结构已经被提出用于二维医学图像分割。为了直接处理体积数据,Hatamizadeh等人[35]提出了一种基于ViT的三维医学图像分割架构**(UNETR**)。UNETR包含一个纯Transformers作为编码器,用于学习输入音量的序列表示。编码器通过跳过连接连接到基于CNN的解码器,以计算最终的分段输出。如图10所示,UNETR在BTCV[203]和MSD[171]分段数据集上取得了令人印象深刻的性能。UNETR的缺点之一是在处理大型3D输入量时计算复杂度高。为了缓解这个问题,Xie等人[112]提出了一种计算效率高的可变形自我注意模块[204],该模块使用多尺度特征,如图11所示,以减少计算和空间复杂性。在BTCV[203]上的实验证明了他们的可变形自我注意模块在3D多器官分割中的有效性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6N3WJuQ-1651114044179)(D:/Typora_img/image-20220427101917030.png)]](https://img-blog.csdnimg.cn/c412aa2a1db343ef9dca632d416b409c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wvExTcw0-1651114044179)(D:/Typora_img/image-20220427101930915.png)]](https://img-blog.csdnimg.cn/8d4fd3de29044d73a06fd96cf143bd03.png)
3.3 Discussion
从本节回顾的大量文献中,我们注意到,医学图像分割领域受到基于Transformers的模型的严重影响,自第一个ViT模型诞生以来,一年内发表了50多篇论文[22]。我们认为,这种兴趣是由于大型医学分割数据集的可用性,以及与其他医学成像应用相比,在顶级会议上与之相关的挑战性竞争。如图12所示,与基准Transformers模型相比,最近基于Transformers的混合架构能够在dice分数方面实现13%的性能增益,这表明该领域的快速发展。简言之,基于ViT的体系结构在基准医疗数据集上取得了令人印象深刻的结果,与基于CNN的分割方法相比具有竞争力,而且在大多数情况下都有所改进(详情见表3)。下面,我们简要描述了基于ViT s的医学分割方法面临的一些挑战,并根据讨论的相关论文给出了可能的解决方案。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HUojt14P-1651114044180)(D:/Typora_img/image-20220427104100479.png)]](https://img-blog.csdnimg.cn/db2e8fee174a4ae4be869c1e87968def.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-by2pZJnw-1651114044180)(D:/Typora_img/image-20220427102536976.png)]](https://img-blog.csdnimg.cn/26e471932b36483095bd751a6f788a05.png)
如前所述,在多个层次上提取特征的高计算成本阻碍了多尺度体系结构在医学分割任务中的适用性。这些多尺度体系结构利用在多个级别处理输入图像信息,并实现比单尺度体系结构更高的性能。因此,为多尺度处理设计高效的Transformers结构需要更多的关注。
大多数基于ViT的模型都是在ImageNet数据集上预训练的,用于医学图像分割的下游任务。这种方法是次优的,因为自然和医学图像模式之间存在较大的领域差距。最近,很少有人尝试研究医学影像数据集的自我监督预训练对ViT分割性能的影响。然而,这些研究表明,在一种模式(CT)上预训练的ViT在直接应用于其他医学成像模式(MRI)时表现不佳,这是因为大的域间隙使其成为一种令人兴奋的探索途径。我们将有关后续医学成像任务ViT预培训的详细讨论推迟到Sec。11.1.
此外,最近基于ViT的方法主要集中在二维医学图像分割上。通过结合时间信息来设计定制的建筑构件,以便对体积图像进行高效的高分辨率和高维分割,目前还没有得到广泛的研究。最近,很少有人做出努力,例如,UNETR[35]使用基于Swin Transformer[126]的架构来避免二次计算的复杂性;然而,这需要社区的进一步关注。
除了关注数据集的规模外,随着ViTs的出现,我们注意到需要收集更多多样且具有挑战性的医学影像数据集。尽管多样且具有挑战性的数据集对于衡量ViTs在其他医学成像应用中的性能也至关重要,但由于基于ViT的模型在该领域大量涌入,它们对于医学图像分割尤其重要。我们相信这些数据集将在探索ViTs在医学图像分割中的局限性方面发挥决定性作用。
4 MEDICAL IMAGE CLASSIFICATION
医学图像的准确分类在临床护理和治疗中起着至关重要的作用。在本节中,我们将全面介绍ViTs在医学图像分类中的应用。由于与这些类别相关的一组不同的挑战,我们将这些方法大致分为2019冠状病毒疾病、肿瘤和基于视网膜疾病分类的方法,如图13所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pTgobbRJ-1651114044181)(D:/Typora_img/image-20220427104158043.png)]](https://img-blog.csdnimg.cn/8bdeb07d0c484c7f83765b184223278c.png)
4.1 COVID-19 Diagnosis
研究表明,与繁琐的实时聚合酶链反应(RT-PCR)检测相比,2019冠状病毒疾病可能通过放射成像得到更好的诊断【205】–【207】。最近,ViTs已成功用于2019冠状病毒疾病的诊断和严重程度预测,显示出SOTA性能。在本节中,我们简要介绍ViTs在推进2019冠状病毒疾病诊断过程自动化图像分析方面的最新努力方面的影响。这些工作大多使用三种模式,包括计算机断层扫描(CT)、超声扫描(US)和X射线。根据可解释性水平,我们进一步将基于ViT的2019冠状病毒疾病分类方法分为黑盒模型和可解释模型。
4.1.1 Black-Box Models
基于ViT的2019冠状病毒疾病图像分类黑盒模型通常侧重于通过设计新颖高效的ViT架构来提高准确性。然而,这些模型不容易解释,因此很难获得用户信任。根据输入图像类型,我们将黑盒模型进一步细分为2D和3D类别。下面,我们简要介绍这些方法:
2D:
VIT的高计算成本阻碍了其在便携式设备上的部署,从而限制了其在实时2019冠状病毒疾病诊断中的适用性。Perera等人【208】提出了一种轻型护理点Transformers(POCFormer),用于根据便携式设备采集的肺部图像诊断2019冠状病毒疾病。具体来说,POCFormer利用Linformer[174]将自我注意的空间和时间复杂性从二次型降低到线性型。POCFormer有200万个参数,约为MobileNet V2[209]的一半,因此适合实时诊断。在2019冠状病毒疾病lungs POCUS数据集上的实验【210】,【211】证明了他们提出的体系结构的有效性,分类准确率达到90%以上。在其他研究中,Liu等人[212]提出了基于ViT的COVID19诊断模型,利用了一种名为视觉观察者(VOLO)的新注意机制[213]。VOLO可以有效地将精细级别的特征编码为ViT标记表示,从而提高分类性能。此外,他们利用迁移学习方法来处理2019冠状病毒疾病数据集不足和普遍不平衡的问题。在两个公开的2019冠状病毒疾病CXR数据集上进行的实验【211】、【214】证明了其架构的有效性。类似地,Jiang等人【215】利用Swin T Transformer【126】和T Transformer-in-T Transformer【216】将2019冠状病毒疾病图像与肺炎和正常图像进行分类。为了进一步提高精度,他们采用了使用加权平均的模型置乱。基于ViT的2019冠状病毒疾病诊断方法的研究进展受到严重阻碍,因为需要大量标记的2019冠状病毒疾病数据,因此需要医院之间的合作。由于患者的同意有限、隐私问题和道德数据使用[217],这种合作很困难。为了缓解这个问题,Park等人[218]提出了一个联邦分割T询问不可知论(FESTA)框架,该框架利用了联邦和分割学习的优点[219],[220],利用ViT同时处理多个胸部X射线任务,包括在大规模分散数据集上的2019冠状病毒疾病胸部X射线图像中的诊断。具体而言,他们将ViT分为共享的转换器主体和任务特定的头,并通过利用多任务学习(MTL)[221]策略,证明ViT主体适合在相关任务之间共享,如图14所示。他们通过在CXR数据集上的大量实验,确认了ViTs在医学成像应用中的协作学习的适用性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0SF5SEOl-1651114044181)(D:/Typora_img/image-20220427112854799.png)]](https://img-blog.csdnimg.cn/582919336e1c4818ae4c3591331c1ad1.png)
3D:
大多数基于ViT的2019冠状病毒疾病分类方法仅对2D信息进行操作。然而,正如Kwee等人[222]所指出的,2019冠状病毒疾病的症状可能在不同患者的不同深度(切片)出现。为了同时利用2D和3D信息,Hsu等人[223]提出了一种由Transformers和CNN组成的混合网络。具体来说,他们通过以Swin Transformer[126]为主干网络的Wilcoxon符号秩检验[224],根据CT扫描中的显著症状确定切片的重要性。为了进一步利用空间和时间维度的内在特征,他们提出了一个卷积CT扫描感知Transformers模块**,以完全捕获3D扫描的上下文**。在COVID-19-CT数据集上进行的大量实验表明,他们提出的架构组件是有效的。类似地,Zhang等人【225】,【226】还提出了基于SWN Transformer的两阶段框架,用于在3D CT扫描数据集中诊断2019冠状病毒疾病【227】。具体来说,他们的框架包括基于UNet的肺分割模型,然后使用Swin Transformer[126]主干进行图像分类。
4.1.2可解释模型
可解释模型旨在显示对模型决策影响最大的特征,通常通过基于显著性的方法、Grad CAM等可视化技术。由于其可解释性,这些模型非常适合获得医生和患者的信任,因此为临床部署铺平了道路。我们进一步将可解释模型分为基于显著性[228]和基于梯度CAM[229]的可视化方法。
Saliency Based Visualization.基于显著性的可视化。
Park等人[231]提出了一种基于ViT的2019冠状病毒疾病诊断方法,该方法利用了从预先训练的主干网络中提取的低水平CXR特征。主干网络以自我监督的方式(使用基于对比学习的SimCLR[232]方法)进行训练,以从CheXpert[233]的大型且精心策划的CXR数据集中提取异常的CXR特征嵌入。ViT模型利用这些特征嵌入对2019冠状病毒疾病图像进行高水平诊断。对从不同医院获得的三个CXR测试数据集进行的大量实验表明,与基于CNN的模型相比,他们的方法具有优越性。他们还验证了他们提出的方法的泛化能力,并采用显著图可视化[234]来提供可解释的结果。类似地,Gao等人[235]建议将新冠病毒ViT从非新冠病毒图像中分类,作为MIA-COVID19挑战的一部分[227]。他们在3D CT肺部图像上的实验证明了基于ViT的方法在F1评分方面优于DenseNet[236]基线。在另一项研究中,Mondal等人【230】介绍了xViTCOS,用于从肺部CT和X射线图像筛查2019冠状病毒疾病。具体来说,他们在ImageNet上预先训练XVITCO,以学习通用图像表示,并在大型胸部X射线照相数据集上微调预先训练的模型。此外,XVITCO还利用了可解释性驱动的基于显著性的方法[234],具有临床可解释的可视化,以强调关键因素在结果预测中的作用,如图15所示。对新冠病毒CT-2A[237]及其私人收集的胸部X光数据集进行的实验证明了xViTCOS的有效性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VKlG6hLz-1651114044182)(D:/Typora_img/image-20220427112935118.png)]](https://img-blog.csdnimg.cn/2910033f46ba4da2bac94240377bd3aa.png)
Grad-CAM Based Visualization.基于梯度CAM的可视化。
Shome等人[238]提出了一种基于ViT的模型,用于大规模诊断2019冠状病毒疾病感染。他们结合了几个开源的2019冠状病毒疾病CXR数据集,形成了一个大规模的多类和二元分类数据集。为了更好的视觉表现和模型解释性,他们进一步创建了基于梯度CAM的可视化[229]。
4.2 Tumor Classification
肿瘤是身体组织的异常生长,可以是癌性(恶性)或非癌性(良性)。早期恶性肿瘤诊断对后续治疗计划至关重要,可以极大地提高患者的生存率。在本节中,我们将回顾基于ViT的肿瘤分类模型。这些模型主要分为黑盒模型和可解释模型。我们用粗体突出显示相关解剖结构。
Black-Box Models.
TransMed[240]是第一个利用ViTs进行医学图像分类的工作。它是一种基于CNN和transformer的混合架构,能够在多模式MRI医学图像中对腮腺肿瘤进行分类。TransMed还采用了一种新的图像融合策略,有效地从不同模式的图像中捕获互信息,从而在其私人收集的腮腺肿瘤分类数据集上获得竞争性结果。后来,Lu等人[241]提出了一个两阶段框架,首先对大脑中的胶质瘤子类型分类进行对比预训练,然后通过提出的基于变压器的稀疏注意模块进行特征聚合。对TCGA-NSCLC[242]数据集的消融研究显示了其两阶段框架的有效性。对于乳腺癌分类的任务,Gheflati等人[243]系统地评估了纯和混合预训练ViT模型的性能。Al Dhabyani等人提供的两个乳房超声数据集上的实验。[244] Yap等人[245]表明,基于Vit的模型在将图像分为良性、恶性和正常类别方面比CNN的模型提供更好的结果。类似地,其他工作也采用混合变压器CNN架构来解决不同器官的医学分类问题。例如,Khan等人[246]提出了基因转换器来预测肺癌亚型。在TCGANCLC[242]数据集上的实验证明了基因转换器优于CNN基线。Chen等人[247]提出了一种多尺度GasHis变压器,用于诊断胃癌。Jiang等人[248]提出了一种利用对称交叉熵损失函数诊断急性淋巴细胞白血病的混合模型。
Interpretable Models.
由于标注过程昂贵且费力,在基于全玻片成像(WSI)的病理诊断中,一个标签被分配给一组实例(bag)。这种类型的弱监督学习被称为多实例学习[249],其中,如果一个包中至少有一个实例为正,则该包被标记为正;如果一个包中的所有实例都为负,则该包被标记为负。目前大多数MIL方法都假设每个包中的实例是独立的、相同分布的,因此忽略了不同实例之间的相关性。邵等人[239]提出了TransMIL,以探索弱监督WSI分类中的形态学和空间信息。具体而言,TransMIL使用两个基于变压器的模块和一个位置编码层来聚合形态信息,如图16所示。为了对空间信息进行编码,提出了一种金字塔位置编码生成器。此外,如图17所示,来自传送的注意分数已可视化以证明可解释性。TransMIL在三个不同的计算病理学数据集CAMELYON16(乳腺)[250]、TCGA-NSCLC(肺)[242]和TCGA-R(肾)[251]上展示了最先进的性能。为了诊断肺部肿瘤,Zheng等人[252]提出了图形变压器网络(GTN),以利用WSI的基于图形的表示。GTN由一个图卷积层[253]、一个转换器层和一个池层组成。GTN还使用GraphCAM[234]识别与类别标签高度相关的区域。对TCGA数据集[242]的广泛评估表明了GTN的有效性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-56mQdtai-1651114044182)(D:/Typora_img/image-20220427110824928.png)]](https://img-blog.csdnimg.cn/243eaf8dcfa34552b49e0efa4e2a7f5d.png)
4.3 Retinal Disease Classification视网膜疾病分类 **
Yu等人[258]提出了MIL-ViT模型,该模型首先在大型眼底图像数据集上进行预训练,然后在视网膜疾病分类的下游任务上进行微调。MIL-ViT体系结构使用基于MIL的磁头,可与ViT以即插即用的方式一起使用。对APTOS2019[255]和RFMiD2020[259]数据集进行的评估表明,MIL ViT的性能比基于CNN的基线更好。大多数数据驱动的方法将糖尿病视网膜病变(DR)分级和病变发现视为两个独立的任务,这可能是次优的,因为错误可能会从一个阶段传播到另一个阶段。为了共同处理这两项任务,Sun等人[260]提出了损伤感知变压器(LAT),该变压器由基于像素关系的编码器和损伤感知变压器解码器组成。特别是,他们利用transformer解码器将病变发现表述为一个弱监督病变定位问题。LAT模型设定了Messidor-1[261]、Messidor2[261]和EyePACS[262]数据集的最新技术。Yang等人[273]提出了一种由卷积层和变换层组成的混合结构,用于在OIA数据集上进行眼底疾病分类[274]。同样,Wu等人[275]和Aldahou等人[276]也验证了ViT模型在DR分级中比CNN模型更准确。
4.4 Discussion
在这一部分中,我们将全面概述大约25篇与ViT s在医学图像分类中的应用相关的论文。特别是,我们看到了基于变压器的诊断2019冠状病毒疾病体系结构的激增,迫使我们相应地开发分类法。下面,我们简要介绍与该领域相关的一些挑战,确定近期趋势,并提供值得进一步探索的未来方向。
缺乏大型2019冠状病毒疾病数据集阻碍了ViT模型诊断2019冠状病毒疾病的适用性。Shome et al.(238)最近的一项工作试图通过组合三个开源2019冠状病毒疾病数据集来创建一个包含30000幅图像的大型数据集来缓解这个问题。尽管如此,创建多样化和大型的2019冠状病毒疾病数据集仍具有挑战性,需要医学界做出重大努力。
必须更加重视设计**可解释(以获得最终用户的信任)和高效(用于护理点检测)**的ViT 2019冠状病毒疾病诊断模型,使其成为未来RTPCR检测的可行替代品。
我们注意到,大多数作品都使用原始的ViT模型[22]作为即插即用的方式来提高医学图像分类性能。在这方面,我们相信,集成特定领域的上下文并相应地设计架构组件和损失函数可以提高性能,并为未来设计有效的基于ViT的分类模型提供更多见解。
最后,让我们重点介绍Matsoukas等人[33]的激动人心的工作。该工作首次证明,在ImageNet上预先训练的VIT在医学图像分类任务中的表现与CNN相当,如表5所示。这也提出了一个有趣的问题:“在医学影像数据集上预训练的ViT模型能否比在ImageNet上预训练的用于医学影像分类的ViT模型表现更好?”谢等人[277]最近的一项工作试图通过在大规模2D和3D医学图像上对ViT进行预训练来回答这个问题。在医学图像分类问题上,与在ImageNet上预训练的ViT模型相比,他们的模型获得了显著的性能提升,这表明该领域值得进一步探索。表4简要概述了基于ViT的医学图像分类方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DEQ3paT8-1651114044183)(D:/Typora_img/image-20220427113413017.png)]](https://img-blog.csdnimg.cn/746b26d5d1c14983aed944f4fb48a3ed.png)
5 MEDICAL IMAGE DETECTION
略
6 MEDICAL IMAGE RECONSTRUCTION
略
7 MEDICAL IMAGE SYNTHESIS
略
8 MEDICAL IMAGE REGISTRATION
略
9 CLINICAL REPORT GENERATION
略
10 OTHER APPLICATIONS
略
11 OPEN CHALLENGES AND FUTURE DIRECTIONS开放的挑战和未来方向 ***
我们回顾了视觉转换器在医学图像分析中令人兴奋的应用。尽管它们的表现令人印象深刻,但仍有几个悬而未决的研究问题。在本节中,我们概述了它们的一些局限性,并强调了未来有希望的研究方向。具体而言,我们将讨论大型数据集的预训练(第11.1节)、基于ViT的医学成像方法的可解释性(第11.2节)、对抗性攻击的鲁棒性(第11.3节)、为实时医疗应用设计高效ViT体系结构(第11.4节)、在分布式环境中部署基于ViT的模型的挑战(第11.5节),和域适应(第11.6节)。此外,在可能的情况下,我们会让感兴趣的研究人员参考相关的基于CNN的医学成像资源(最近的研究、数据集、软件库等),以探索基于VIT的模型在医学成像中尚未开发的应用,如对抗性稳健性。
11.1 Pre-training
由于在建模局部视觉特征时缺乏内在的归纳偏差,VIT需要通过大规模训练数据集的预训练,自行找出特定于图像的概念[22]。这可能是它们在医学成像中广泛应用的一个障碍,由于成本、隐私问题和某些疾病的罕见性,通常情况下,与自然图像数据集相比,数据集要小几个数量级,从而使VIT难以在医学领域进行有效培训。现有的基于学习的医学成像方法通常依赖于通过ImageNet预训练传递学习,这可能是次优的,因为医学图像和自然图像之间的图像特征截然不同。最近,Matsoukas等人[33]通过在多个医学成像数据集上进行的一系列广泛实验,研究了预训练对ViTs图像分类和分割性能的影响。下面,我们简要介绍他们工作的主要发现。
1)当使用随机权重初始化时,CNN在医学图像分类任务方面优于ViTs
2)CNN和VIT从医学图像分类的ImageNet初始化中获益匪浅。VIT似乎从迁移学习中受益更多,因为他们弥补了使用随机初始化观察到的差距,表现与CNN同行不相上下
3)CNN和VIT通过DINO[271]和BYOL[388]等自我监督的预训练方法表现更好。在这种情况下,VIT在医学图像分类方面的表现似乎比CNN好一点。
简而言之,尽管最近基于ViT的数据高效方法,如DeiT[389]、令牌对令牌[290]、变压器中变压器[216]等,在通用视觉应用中报告了令人鼓舞的结果,但以数据高效的方式学习这些专为特定领域的医学成像应用定制的变压器模型的任务具有挑战性。最近,Tang等人[163]试图通过研究自我监督学习作为特定领域医学图像预训练策略的有效性来处理这个问题。具体来说,他们提出了基于3D transformer的分层编码器Swin UNETR,并在对5050张CT图像进行预训练后,通过对医学图像分割的下游任务进行微调,证明了其有效性。医学影像数据集的预培训也减少了注释工作与随机初始化从头开始训练Swin UNETR相比。这如图27所示,在图27中可以看出,预训练的Swin-UNETR可以通过仅使用60%的数据实现与随机初始化的Swin-UNETR使用100%的标记数据实现相同的性能。这将导致手动注释工作量减少40%。此外,如图27所示,与随机初始化的UNETR相比,对下游医学图像分割进行微调预训练的Swin UNETR可获得更好的定量和定性结果。尽管做出了这些努力,但仍然存在一些开放的挑战,例如,在CT数据集上预先训练的Swin UNETR在直接应用于其他医学成像模式(如MRI)时,由于CT和MRI图像之间存在较大的域差距,其性能不令人满意。此外,Swin UNETR在其他下游医学成像任务(如分类和检测)上的有效性需要进一步研究。此外,CNN最近的工作表明,与仅在ImageNet上进行预训练相比,ImageNet和医学数据集上的自监督预训练可以提高分布移位医学数据集[390]上模型的泛化性能(用于分类)。我们相信,基于ViT模型的此类研究,以及利用患者元数据的多实例对比学习[391],将为社区提供进一步的见解。类似地,将自我监督和半监督的预培训结合到ViTs的医疗成像应用中也是一个值得探索的有趣途径[392]。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ZktWiy6-1651114044183)(D:/Typora_img/image-20220428095556563.png)]](https://img-blog.csdnimg.cn/134624ac65c248a0955804fa10352eaf.png)
11.2 Interpretabilitys
虽然变形金刚的成功经验已经在大量医学成像应用中得到证实,但迄今为止,它还没有得到令人满意的解释。在大多数医学成像应用中,ViT模型被部署为block-boxes块盒,因此无法提供洞察并解释其用于预测的学习行为。VIT的这种黑匣子性质阻碍了其在临床实践中的应用,因为在医疗应用等领域,必须识别设计系统的局限性和潜在故障案例,其中可解释性起着至关重要的作用[393]。虽然已经开发了几种可解释的基于人工智能的医学成像系统,以便对临床应用CNNs模型的工作有更深入的了解[394]–[396],但是,基于ViT的医学成像应用的工作仍处于初级阶段。尽管自我注意机制具有内在的可解释性,因为它能够明确地模拟图28[397]所示图像a中每个区域之间的相互作用。最近对基于ViT的可解释医学成像模型的研究利用了基于显著性的方法[234]和基于Grad-CAM的可视化[229]。尽管做出了这些努力,但基于可解释和可解释的ViT方法的开发,特别是为生命关键医学成像应用量身定制的方法,是一个具有挑战性和开放性的研究问题。此外,还必须解决基于可解释ViTs的医疗成像系统的形式主义、挑战、定义和评估协议。我们相信,这方面的进展不仅有助于医生决定是否应该遵循并信任基于ViT的自动模式决策,而且还可以从法律角度促进此类系统的部署。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E71WH0zq-1651114044184)(D:/Typora_img/image-20220428100343186.png)]](https://img-blog.csdnimg.cn/425645a34d3c4a3e832e1524cc7c90ae.png)
11.3 Adversarial Robustness
对抗性攻击的进展揭示了现有基于学习的医学成像系统在输入图像中不易察觉的干扰[404]–[406]时的脆弱性。考虑到支撑医疗成像行业的巨额资金,这不可避免地带来了一种风险,潜在攻击者可能会试图通过操纵医疗系统获利,如图29所示。例如,攻击者可能试图操纵患者的检查报告,以进行保险欺诈或虚假的医疗报销申请,从而引发安全问题。因此,在生命攸关的医学成像应用中,确保VIT的鲁棒性,以抵御对抗性攻击至关重要。尽管有大量文献与CNN在医学成像领域的稳健性有关,但据我们所知,目前还没有关于ViTs的此类研究,这也是一项令人兴奋的研究挑战探索的方向。最近,很少有人尝试评估VIT对自然图像的对抗性攻击的鲁棒性[407]–[416]。这些尝试的主要结论,忽略了它们之间的细微差别,可以总结为ViTs比CNN更能抵御对手攻击。然而,这些健壮的ViT模型不能直接用于医学成像应用,因为医学图像中的图案和纹理的种类和类型与自然域存在显著差异。因此,评估VIT对抗对抗性学习的稳健性的原则方法见表9:医疗对抗性深度学习中常用数据集的描述。数据集名称数据集大小模式RSNA[264]29700 X射线JSRT[194]247 X射线BraTS 2018[398]1689 MRI BraTS 2019[185]1675 MRI OASIS[399]373-2168 MRI HAM1000[272]10000皮肤镜ISIC 18[101]3594皮肤镜LUNA 16[400]888 CT扫描NIH胸部X射线[196]112000 X射线APTOS[255]5590眼底镜胸部X射线[401]5856 X射线NSLT[402]75000 CT扫描糖尿病视网膜病变[403]医学成像背景下的35000例眼底镜检查和眼底镜检查为恢复能力奠定了基础,可以作为在临床环境中部署这些模型的关键模型。此外,医学成像研究人员对提供VIT性能和稳健性保证的理论理解(如CNN[417])可能非常感兴趣。在表9中,我们描述了用于对抗性医学学习的数据集,以评估CNN的稳健性,供感兴趣的研究人员对基于VIT的模型的稳健性进行基准测试。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BB8fDp2G-1651114044184)(D:/Typora_img/image-20220428100407176.png)]](https://img-blog.csdnimg.cn/2c3e65daeaf74a26b29d54ac1f67095e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4NKOsnyz-1651114044185)(D:/Typora_img/image-20220428100531977.png)]](https://img-blog.csdnimg.cn/3540f251b6ef4fdb9e72a4ae8b5d52ae.png)
11.4 ViTs for Medical Imaging on Edge Devices(边缘设备医学成像用VIT )****
尽管VIT在许多医学成像应用中取得了巨大成功,但对内存和计算的密集需求阻碍了它们在资源有限的边缘设备上的部署[423],[424]。由于边缘计算的最新进展,医疗保健提供商可以在本地处理、存储和分析复杂的医疗成像数据,加快诊断速度,改进临床医生的工作流程,增强患者隐私,并节省时间和潜在的生命。这些边缘设备提供了对大量医疗成像数据的极快且高度精确的处理,因此需要高效的硬件设计,以使基于ViT的模型适用于基于边缘计算的医疗成像硬件。最近,利用增强的块循环矩阵表示[425]和神经结构搜索策略[426]来压缩基于变压器的模型的工作很少。由于VIT的卓越性能,我们认为迫切需要为边缘设备量身定制的领域优化架构设计。它可以对基于医学成像的医疗保健应用产生巨大影响,在这些应用中,按需洞察可以帮助团队对患者做出关键和紧急的决策
11.5 Decentralized Medical Imaging Solutions using ViTs(分布式)
建立基于深度学习的医学影像模型在很大程度上取决于训练数据的数量和多样性。由于严格的隐私法规、某些疾病的低发病率、数据所有权问题以及有限的风险,单个机构可能无法获得训练可靠且稳健模型所需的训练数据病人的数量。**联邦学习(FL)**旨在促进多医院协作,同时避免数据传输。具体而言,在FL中,使用来自多个设备的分布式数据构建共享模型,其中每个设备使用其本地数据训练模型,然后与中心模型共享模型参数,而不共享其实际数据。尽管有很多方法可以解决基于CNN的医学成像应用中的FL问题,但VIT的研究仍处于起步阶段,需要进一步关注。最近,在分布式医学成像应用中利用ViT固有结构的研究很少。Park等人【218】提出了一个联邦分割任务不可知论(FESTA)框架,该框架整合了联邦和分割学习的力量【219】,【220】利用ViT同时处理多个胸部X射线任务,包括在大型分散数据集上诊断2019冠状病毒疾病CXR图像。具体来说,他们将ViT分为共享身体和任务特定的头部,并证明通过利用多任务学习(MTL)[221]策略,具有足够能力的ViT身体可以在相关任务之间共享。然而,FESTA只是一项概念验证研究,其在临床试验中的适用性还需要进一步的实验。此外,基于ViT的FL医疗成像系统的隐私攻击和抗通信瓶颈的鲁棒性等挑战需要深入研究。一个有趣的未来方向是探索最近的隐私增强方法,如差分隐私[427],以防止ViTs环境下基于FL的医学成像系统上的梯度反转攻击[428]。简言之,我们相信,分布式机器学习框架的成功实施,加上ViTs的优势,将为大规模实现精确医学带来巨大潜力。这可能导致ViT模型产生公正的决策,对罕见疾病敏感,同时尊重治理和隐私问题。在表10中,我们重点介绍了为实现分布式安全深度学习而开发的各种工具和库。这可以为希望在分布式环境下快速原型化基于ViT的医学成像模型的研究人员提供有用的信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yrAkS4Aq-1651114044186)(D:/Typora_img/image-20220428101701522.png)]](https://img-blog.csdnimg.cn/492c340f105f4543b8b42c8d63b54b23.png)
11.6 Domain Adaptation and Out-of-Distribution Detection
近年来,基于ViT的医学成像系统的研究主要集中在提高准确性上,并且总体上缺乏一种原则性的机制来评估其在不同分布/域转移下的泛化能力。最近的研究表明,测试误差通常会随着训练数据集和测试数据集之间的分布差异而成比例增加,因此,在ViTs的背景下进行研究是一个至关重要的问题。在医学成像应用中,这些数据分布变化是由以下几个因素引起的:在不同的医院使用不同的设备型号获取的图像、训练数据集中未包含的某些未发现疾病的图像、准备不正确的图像,例如对比度差、图像模糊,等等。在医学成像中,对基于CNN的分布外检测方法进行了广泛的研究[431]–[435]。最近,很少有人试图证明,大规模预训练的VIT由于其高质量的表示,可以显著提高跨不同数据模式的一系列分布外任务的最新水平[386]、[430]、[436]。然而,这些工作中的调查大多是在玩具数据集(如CIFAR-10和CIFAR100)上进行的,因此不一定反映了在具有复杂纹理和图案、特征尺度高度差异(如X射线图像)和局部特定特征的医学图像上的分布外检测性能。这就需要进一步研究设计基于ViT的医学成像系统,该系统应该能够准确地用于训练期间看到的课程,同时为异常和看不见的课程提供校准的不确定性估计。我们相信,使用转移学习和领域适应技术在这一方向上进行的研究将使从事基于医学成像的生命关键应用的从业者感兴趣,以设想潜在的实际部署。在图30中,我们强调了与CNN相比,VIT在分布外检测方面的性能增益,以启发希望探索这一领域的医学成像研究人员。另一个可能的方向是探索持续学习[437]的最新进展,以有效缓解使用VIT的领域转移问题。探索这一方向的初步努力很少[438];然而,这项工作仍处于起步阶段,需要社区进一步关注。此外,还需要为医学成像应用中的域适配建立标准化和严格的评估协议,类似于自然图像领域中的DOMAINBED[439]框架。这样一个框架也将有助于倡导模型的可复制性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fotd7vKQ-1651114044186)(D:/Typora_img/image-20220428101844346.png)]](https://img-blog.csdnimg.cn/e852c52b72a24af88d9d16eccd75f1c3.png)
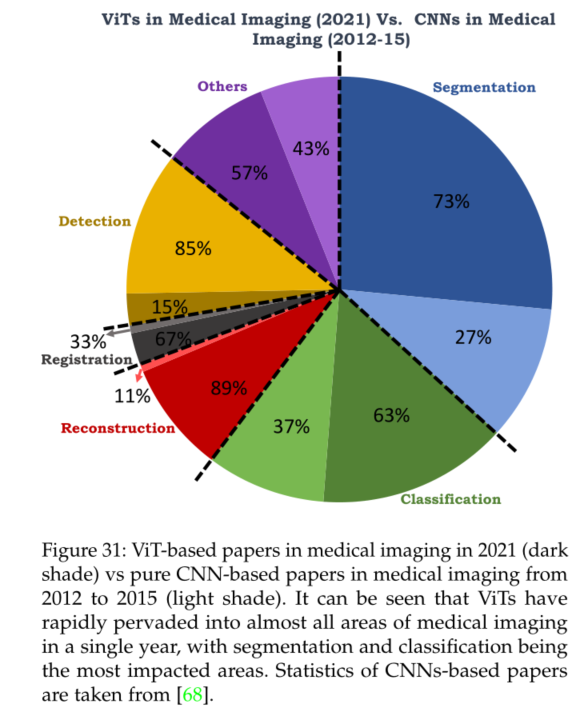
12 DISCUSSION AND CONCLUSION
从本次调查中回顾的论文可以看出,VIT已渗透到医学成像的各个领域(见图31)。为了跟上这一快速发展的步伐,我们建议在顶级计算机视觉和医学影像会议上组织相关研讨会,并在著名期刊上安排专题,以快速向医学影像界传播相关研究。最后,我们首次全面回顾了变压器在医学成像中的应用。我们简要介绍了变压器模型成功背后的核心概念,然后对变压器在广泛的医学成像任务中的应用进行了全面的文献综述。具体来说,我们综述了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的应用。特别是,对于这些应用程序中的每一个,我们都开发了分类法,确定了特定于应用程序的挑战,并给出了解决这些问题的见解,并指定了最新的趋势。尽管变压器的性能令人印象深刻,但我们预计,在医学成像领域,变压器仍有许多探索有待完成,我们希望这项调查能够提供更多信息