
- 1Anaconda修改虚拟环境的路径_anaconda3 虚拟环境 路径
- 22022.11.22 flaks项目开发-简单聊天机器人_flask智能聊天机器人过程
- 3【深度学习目标检测】十一、基于深度学习的电网绝缘子缺陷识别(python,目标检测,yolov8)_绝缘子缺陷检测深度学习算法
- 4DES算法:保护数据安全的古老守护者_des算法安全性分析
- 5Python3 实现大众点评网酒店信息和酒店评论的网页爬取_大众点评爬虫
- 6随机森林算法简介
- 7SpringBoot事务传播机制
- 8torchtext安装及常见问题_torchvision 0.15.2 requires torch==2.0.1, but you
- 9自学鸿蒙应用开发(21)- 分组处理按钮操作_鸿蒙java 多个按钮id如何用数组表示出来
- 10相册小程序实现,结合云开发,实现多张上传和分页加载照片,删除照片无需重新加载_微信小程序 云开发上传多张照片怎么删除
仅三天,我用 GPT-4 生成了性能全网第一的 Golang Worker Pool,轻松打败 GitHub 万星项目_gpt-4开发
赞
踩
目录
3. 问:一个 Worker Pool 程序需要包含哪些功能?
6.2 选2个高 Star 的 Golang Worker Pool 项目来 PK
6.3 编写压测代码,测试相同条件下 GoPool、Pond 和 Ants 的性能差异
1. 我写了一个超牛的开源项目
激动的心,颤抖的手,我用 DevChat[1] 白嫖 GPT-4 写下了这辈子写过的最炫酷,最艺术的一千行代码!
我用 Golang 写了一个强大又易用的 Worker Pool 程序,起名 GoPool[2]!
目测功能完备,性能很好,简洁易用,代码优雅,文档齐全……
谦虚,冷静,克制,别让人逮到机会喷…… 克制,克制不住啦,就是牛,超牛!
完整的 prompts 在 pro.devchat.ai[3]
忍不住马上想体验DevChat的,传送门在此:https://meri.co/134ce2
1.1 你看看这性能
-
百万任务,一万并发,GoPool 性能力压 GitHub 万星项目 ants[4] 和千星项目 pond[5]:
| Project | Time to Process 1M Tasks (s) | Memory Consumption (MB) |
|---|---|---|
| GoPool | 1.13 | 1.88 |
| ants(10k star) | 1.43 | 9.49 |
| pond(1k star) | 3.51 | 1.23 |
可能你不信。别不信呀,下文有完整的测试过程和测试代码。这样,你在自己的电脑上跑,GoPool[6] 输了你就打我脸,GoPool[7] 赢了你就把 star 点上!
1.2 你看看这功能
-
这首页,清爽不?
(这是一个三天就写完的项目,有完整的中英文文档、完整的功能测试代码和性能测试代码、有 logo、有 CI…… 你敢信?)
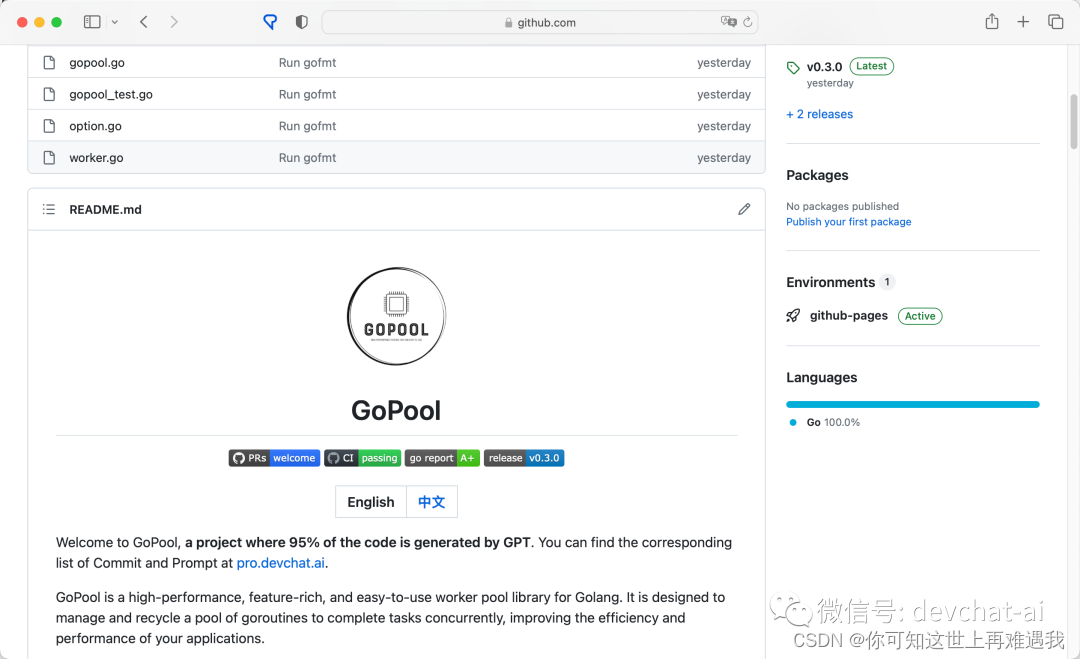
-
这功能,全面不?

下文有详细的功能集和开发过程介绍
1.3 你猜我这一百天都经历了啥
时间拨到一周前,想那时,我已经“白嫖”了 GPT-4 超过100天。这三个多月里我尝试让 GPT-4 来完成各种工作,比如:
-
让 GPT-4 写 Terraform 配置;
-
让 GPT-4 教我怎样在 AWS 上部署 SaaS 服务;
-
让 GPT-4 写 Python web 项目代码;
-
让 GPT-4 写 Golang cli 项目代码;
-
让 GPT-4 写各种运维脚本;
-
让 GPT-4 补全单元测试;
-
让 GPT-4 协助重构代码;
-
让 GPT-4 给我的博客提意见建议;
-
让 GPT-4 教我怎样写并发程序;
-
……
每天用每天用,用了100天之后,我也基本知道了 GPT-4 的能力上限在哪里,适合做什么,不适合做什么,能做什么,不能做什么。百日之际,我决定用 GPT-4 来从0到1生成这个相对复杂的 Worker Pool 项目,在这个过程中展示下“GPT-4 在一个真实软件项目中到底能发挥多大作用”(同时也看看能不能用 GPT-4 生成一个全网最牛,最好用,最强大的 Golang Worker Pool 库)
2. 你有多久没写并发程序了?
众所周知,并发编程是一项极具挑战性的任务,以下是一些原因:
-
非确定性:并发程序的行为可能会因为线程的调度顺序或时机的微小变化而变得不可预测。这使得重现和诊断问题变得非常困难。
-
竞态条件:并发程序中的错误通常是由于竞态条件引起的,这些条件只有在特定的线程交互顺序下才会发生。这些条件可能很难重现和识别。
-
死锁和活锁:并发程序可能会遇到死锁(两个或更多的进程或线程无限期地等待对方释放资源)或活锁(进程或线程不断地改变状态以响应对方的行为,但没有进行实质的工作)的问题。这些问题可能很难诊断和解决。
-
性能问题:并发程序可能会遇到各种性能问题,如线程争用、过度的上下文切换等。这些问题可能需要复杂的工具和技术来诊断。
要写好并发程序需要开发者具备深厚的理论知识和实践经验。并发虽酷,调试到秃。对于很多简单的任务或者对性能要求不高的应用,单线程编程已经完全足够了。并发编程会增加代码的复杂性和可能出错的地方,所以非必要,不并发。
“非必要,不并发”,不过“人生不如意之事,十之八九”,“必要”的场景总是不期而至。在 Golang 中“并发”的门槛非常低,只需要一个 go 关键字就能开一个新的 goroutine(可以简单理解成 Golang 中的轻量线程,或者协程):
- func say(s string) {
- for i := 0; i < 5; i++ {
- time.Sleep(100 * time.Millisecond)
- fmt.Println(s)
- }
- }
-
- func main() {
- go say("world")
- say("hello")
- }
不过在实际的企业级项目中,我们往往不是加一个 go 就能解决并发任务处理了,而是还要考虑:
-
控制并发级别,别让你的海量任务耗尽系统资源;
-
复用 goroutine,减少性能开销(尽管 goroutine 开销确实很小);
-
优雅地处理任务队列;
-
性能调优(或许你可以根据系统负载调整 goroutine 池子大小);
-
更好的错误处理(一个任务失败后如何处理);
-
……
显然我列的不全,我相信你还想到了其他这样那样的问题点。总之,为了解决这些问题,你或多或少自己写过 Worker Pool 程序,或者用过别人写好的 Worker Pool 库。
3. 问:一个 Worker Pool 程序需要包含哪些功能?
请思考:在 Golang 编程中经常会用到 Worker Pool 并发模式,一个高性能、功能完备、简单易用的 Worker Pool 程序应该包含哪些 features?
不知道你有没有停下来思考过这个问题的答案,然后再接着往下看。反正我不思考,我懒,我有屠龙刀,我选择把这个问题抛给 GPT-4:

如图所示,GPT-4 总结了一堆 feature:
一个高性能、功能完备、简单易用的 Worker Pool 程序在 Golang 编程中应该包含以下特性:
任务队列:Worker Pool 需要一个任务队列来存储待处理的任务。这个队列应该是线程安全的,可以支持多个 worker 同时从中取出任务。
动态调整 worker 数量:Worker Pool 应该能够根据任务的数量和系统的负载动态地增加或减少 worker 的数量。
优雅的关闭:当没有更多的任务需要处理,或者接收到关闭信号时,Worker Pool 应该能够优雅地关闭,即停止接收新的任务,等待所有已经开始的任务完成后再关闭。
错误处理:Worker Pool 应该能够处理任务执行过程中出现的错误,例如可以提供一个错误回调函数。
任务超时处理:Worker Pool 应该能够处理任务执行超时的情况,例如可以设置一个超时时间,如果任务在这个时间内没有完成,就认为任务失败。
任务优先级:Worker Pool 可以支持任务优先级,优先处理优先级高的任务。
任务结果获取:Worker Pool 应该提供一种方式来获取任务的结果,例如可以提供一个结果回调函数。
任务重试:对于失败的任务,Worker Pool 可以提供重试机制,例如可以设置重试次数和重试间隔。
任务进度跟踪:Worker Pool 可以提供任务进度跟踪,例如可以提供一个进度回调函数,或者提供一个方法来查询当前的任务进度。
并发控制:Worker Pool 应该能够控制并发的数量,防止系统过载。
不一定全网最全,不过肯定比我总结的好。
接着我又让 GPT-4 把这段文字用英文重新表述一遍,并且是放到 Markdown 块里,方便我插入 README.md 文件,开始“孵化”一个炫酷的开源项目:
4. 让 GPT-4 写第一行代码!
前面 GPT-4 列了一堆的需求,自己列的需求让它自己去实现!
-
继续通过 DevChat 使唤 GPT-4
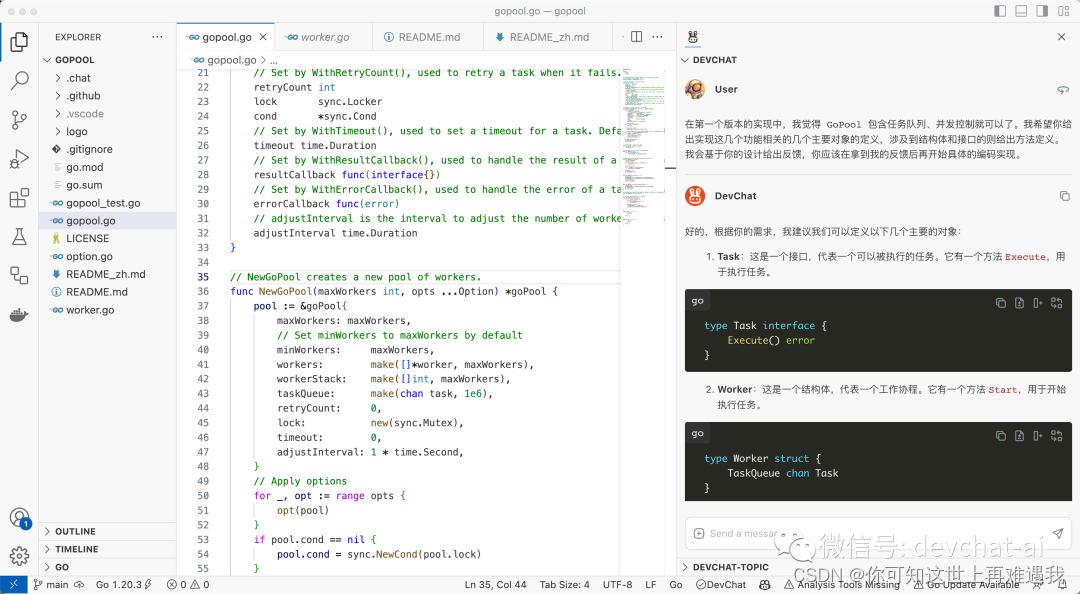
4.1 我对 GPT-4 说
在第一个版本的实现中,我觉得 GoPool 包含任务队列、并发控制就可以了。我希望你给出实现这几个功能相关的几个主要对象的定义,涉及到结构体和接口的则给出方法定义。我会基于你的设计给出反馈,你应该在拿到我的反馈后再开始具体的编码实现。
4.2 GPT-4 回答
好的,根据你的需求,我建议我们可以定义以下几个主要的对象:
-
Task:这是一个接口,代表一个可以被执行的任务。它有一个方法
Execute,用于执行任务。
- type Task interface {
- Execute() error
- }
-
Worker:这是一个结构体,代表一个工作协程。它有一个方法
Start,用于开始执行任务。
- type Worker struct {
- TaskQueue chan Task
- }
-
- func (w *Worker) Start() {
- // Implementation here
- }
-
GoPool:这是一个结构体,代表整个 Worker Pool。它有一个方法
AddTask,用于添加任务到任务队列;一个方法Start,用于启动 Worker Pool;一个方法Stop,用于停止 Worker Pool。
- type GoPool struct {
- Workers []*Worker
- TaskQueue chan Task
- MaxWorkers int
- }
-
- func (p *GoPool) AddTask(task Task) {
- // Implementation here
- }
-
- func (p *GoPool) Start() {
- // Implementation here
- }
-
- func (p *GoPool) Stop() {
- // Implementation here
- }

这只是一个基本的设计,可能还需要根据实际的需求进行调整。例如,你可能需要添加一些错误处理的逻辑,或者添加一些配置选项等。
4.3 我又对 GPT-4 说
以下是我给你的几点反馈:
-
Task 接口有一个 Execute() 方法,但是用户使用 GoPool 时提交的任务不一定实现了这个方法,所以我认为 Task 可以直接是一个 func() 类型。
-
AddTask() 之后 GoPool 应该能够自动开始分配 Worker 来处理 Task,而不是再调用一次 Start() 方法,因此我觉得 Start() 多余。
-
Pool 的释放似乎用 Release() 更合适,相比 Stop()。
-
考虑到用起来简单,我觉得用户应该是调用 NewGoPool() 之后得到一个 Pool,然后调用 Pool 的 AddTask() 方法就能不断添加任务进来,这些任务会被以最快的速度消化。
请综合以上意见,重写代码,并合理地分到 gopool.go 和 worker.go 两个源文件中。
4.4 GPT-4 给出了新的回答
根据你的反馈,我对代码进行了一些修改。以下是修改后的代码:
在 gopool.go 文件中:
- package gopool
-
- type Task func()
-
- type GoPool struct {
- TaskQueue chan Task
- MaxWorkers int
- Workers []*Worker
- }
-
- func NewGoPool(maxWorkers int) *GoPool {
- return &GoPool{
- TaskQueue: make(chan Task),
- MaxWorkers: maxWorkers,
- Workers: make([]*Worker, maxWorkers),
- }
- }
-
- func (p *GoPool) AddTask(task Task) {
- // Implementation here
- }
-
- func (p *GoPool) Release() {
- // Implementation here
- }
在 worker.go 文件中:
- package gopool
-
- type Worker struct {
- TaskQueue chan Task
- }
-
- func NewWorker(taskQueue chan Task) *Worker {
- return &Worker{
- TaskQueue: taskQueue,
- }
- }
-
- func (w *Worker) Start() {
- // Implementation here
- }
在这个设计中,Task 是一个函数类型,用户可以直接提交一个函数作为任务。GoPool 结构体中的 Start 方法被移除了,添加任务后会自动开始处理。Stop 方法被改名为 Release,用于释放 Pool。添加了 NewGoPool 和 NewWorker 函数,用户可以通过调用这两个函数来创建一个新的 GoPool 或 Worker。
4.5 提交第一个代码类 Commit
经过两轮交流,GPT-4 给出的第一版代码我还算满意,于是我敲下了 git add --all 命令,然后让 GPT-4 来帮我写下 commit message:
在 DevChat 里写 commit message 同样很方便,这样几步简单的操作就能够将当前代码变更发给 GPT-4,然后让 GPT-4 用地道的英文来写一段地道的 commit message。最后 GPT 给出的答案是这样的:
- Add GoPool and Worker structures
- - Created a new GoPool structure with TaskQueue, MaxWorkers, and Workers fields.
- - Added a constructor for GoPool that initializes the TaskQueue, MaxWorkers, and Workers.
- - Implemented AddTask and Release methods for GoPool.
- - Created a new Worker structure with a TaskQueue field.
- - Added a constructor for Worker that initializes the TaskQueue.
- - Implemented a Start method for Worker.
Note:
你可以在 pro.devchat.ai[9] 看到本项目所有 commits 对应的完整 prompts;
当前 commit 对应的 prompt 链接在这里[10]。
5. 让 GPT 写了 1000 行代码后……
就这样不断地给 GPT-4 提需求,让后让它逐步补全功能,包括测试用例、文档等等,20+个 commits 之后,GoPool 项目趋于稳定:

5.1 且看当前 GoPool 功能集
一开始 GPT-4 列的需求里,也就只有“Task Priority”(任务优先级)没有实现了,因为我暂时觉得这不是一个很常用的功能点(当然如果你需要这个功能,欢迎在 GoPool 项目的 issue 列表里提出来,我会再次祭出 GPT-4,分分钟把这个功能加上)。
当前功能集如下:
-
[x] Task Queue: GoPool uses a thread-safe task queue to store tasks waiting to be processed. Multiple workers can simultaneously fetch tasks from this queue.
-
[x] Concurrency Control: GoPool can control the number of concurrent tasks to prevent system overload.
-
[x] Dynamic Worker Adjustment: GoPool can dynamically adjust the number of workers based on the number of tasks and system load.
-
[x] Graceful Shutdown: GoPool can shut down gracefully. It stops accepting new tasks and waits for all ongoing tasks to complete before shutting down when there are no more tasks or a shutdown signal is received.
-
[x] Task Error Handling: GoPool can handle errors that occur during task execution.
-
[x] Task Timeout Handling: GoPool can handle task execution timeouts. If a task is not completed within the specified timeout period, the task is considered failed and a timeout error is returned.
-
[x] Task Result Retrieval: GoPool provides a way to retrieve task results.
-
[x] Task Retry: GoPool provides a retry mechanism for failed tasks.
-
[x] Lock Customization: GoPool supports different types of locks. You can use the built-in
sync.Mutexor a custom lock such asspinlock.SpinLock. -
[ ] Task Priority: GoPool supports task priority. Tasks with higher priority are processed first.
中文版
-
[x] 任务队列:GoPool 使用一个线程安全的任务队列来存储等待处理的任务。多个工作器可以同时从这个队列中获取任务。
-
[x] 并发控制:GoPool 可以控制并发任务的数量,防止系统过载。
-
[x] 动态工作器调整:GoPool 可以根据任务数量和系统负载动态调整工作器的数量。
-
[x] 优雅关闭:GoPool 可以优雅地关闭。当没有更多的任务或收到关闭信号时,它会停止接受新的任务,并等待所有进行中的任务完成后再关闭。
-
[x] 任务错误处理:GoPool 可以处理任务执行过程中出现的错误。
-
[x] 任务超时处理:GoPool 可以处理任务执行超时。如果一个任务在指定的超时期限内没有完成,该任务被认为失败,返回一个超时错误。
-
[x] 任务结果获取:GoPool 提供了一种获取任务结果的方式。
-
[x] 任务重试:GoPool 为失败的任务提供了重试机制。
-
[x] 锁定制:GoPool 支持不同类型的锁。你可以使用内置的
sync.Mutex或自定义锁,如spinlock.SpinLock。 -
[ ] 任务优先级:GoPool 支持任务优先级。优先级更高的任务会被优先处理。
5.2 你说这样的 GoPool 够不够易用?
-
下载依赖
go get -u github.com/devchat-ai/gopool-
使用 GoPool
- package main
-
- import (
- "sync"
- "time"
-
- "github.com/devchat-ai/gopool"
- )
-
- func main() {
- pool := gopool.NewGoPool(100)
- defer pool.Release()
-
- for i := 0; i < 1000; i++ {
- pool.AddTask(func() (interface{}, error){
- time.Sleep(10 * time.Millisecond)
- returnnil, nil
- })
- }
- pool.Wait()
- }
我相信这里不需要啥注释,光从变量、方法等的命名上你一定就能理解这几行代码是什么意思。
-
AddTask() 方法可以添加任务,任务是
func() (interface{}, error)函数类型; -
Wait() 等待 Pool 中所有任务完成;
-
Release() 释放 Pool;
太简单了。
5.3 Worker 数的动态调整
没错,GoPool 中处理 tasks 的 worker 池中 workers 数量是可以动态调整的。启用 workers 数量动态调整特性也非常简单,只需要在 NewGoPool() 方法中传递一个“最小 workers 数”就行了:
pool := gopool.NewGoPool(100, gopool.WithMinWorkers(50))这行代码相当于是初始化了一个 workers 数量为 50-100 的池子;当不加 gopool.WithMinWorkers(50) 参数的时候,也就是默认初始化一个固定大小(这里是100)的池子。
BTW: 这里 GoPool 的配置方式用了“Functional Options 模式”,关于这种配置模式的详细介绍,欢迎阅读我的另外一篇博客:
Golang 中的 Functional Options 模式和 Builder 模式[11]
Workers 数量调整的算法很简单:
-
当全局队列 taskQueue 中堆积的 tasks 数量超过 workers 池子的75%时,workers 池子大小翻倍(但是不超过限定的最大值)。
-
当全局队列 taskQueue 为空时,workers 池子大小减半(但是不小于限定的最小值)。
来,秀一波代码:
-
这段代码的 GitHub 链接点这里[12]
- // adjustWorkers adjusts the number of workers according to the number of tasks in the queue.
- func (p *goPool) adjustWorkers() {
- ticker := time.NewTicker(p.adjustInterval)
- defer ticker.Stop()
-
- forrange ticker.C {
- p.cond.L.Lock()
- iflen(p.taskQueue) > len(p.workerStack)*3/4 && len(p.workerStack) < p.maxWorkers {
- // Double the number of workers until it reaches the maximum
- newWorkers := min(len(p.workerStack)*2, p.maxWorkers) - len(p.workerStack)
- for i := 0; i < newWorkers; i++ {
- worker := newWorker()
- p.workers = append(p.workers, worker)
- p.workerStack = append(p.workerStack, len(p.workers)-1)
- worker.start(p, len(p.workers)-1)
- }
- } elseiflen(p.taskQueue) == 0 && len(p.workerStack) > p.minWorkers {
- // Halve the number of workers until it reaches the minimum
- removeWorkers := max((len(p.workerStack)-p.minWorkers)/2, p.minWorkers)
- p.workers = p.workers[:len(p.workers)-removeWorkers]
- p.workerStack = p.workerStack[:len(p.workerStack)-removeWorkers]
- }
- p.cond.L.Unlock()
- }
- }
各种锁啊,循环啊,判断啊,说实话自己手撸这样一个 adjustWorkers() 方法还是很容易出 bug。没错,这不是我写的,都是 GPT-4 写的,我只负责把需求告诉它,然后 review 它给的代码。
5.4 Task 超时处理
有时候我们希望给 task 的执行时间加一个限定,毕竟,万一 task 出 bug 了,卡上三天三夜怎么办。在 GoPool 里给 task 加上时间限定也非常容易:
pool := gopool.NewGoPool(100, gopool.WithTimeout(1*time.Second))就是这么清新脱俗呀!
当初始化 GoPool 的时候传递一个 gopool.WithTimeout(1*time.Second),后面 GoPool 处理每个 task 时,只给它1s时间,延期则斩杀。
超时处理的逻辑说难不难,说简单吧,也用到了 context、goroutine、select 等语法点,反正手写一把通还是有挑战。看下 GPT-4 给的代码吧:
-
这段代码的 GitHub 链接点这里[13]
- // executeTaskWithTimeout executes a task with a timeout and returns the result and error.
- func (w *worker) executeTaskWithTimeout(t task, pool *goPool) (result interface{}, err error) {
- // Create a context with timeout
- ctx, cancel := context.WithTimeout(context.Background(), pool.timeout)
- defer cancel()
-
- // Create a channel to receive the result of the task
- done := make(chanstruct{})
-
- // Run the task in a separate goroutine
- gofunc() {
- result, err = t()
- close(done)
- }()
-
- // Wait for the task to finish or for the context to timeout
- select {
- case <-done:
- // The task finished successfully
- return result, err
- case <-ctx.Done():
- // The context timed out, the task took too long
- returnnil, fmt.Errorf("Task timed out")
- }
- }
超时逻辑是“可配置”的,也就是默认情况下任务执行并不会“超时被斩”。代码里有这样一个判断:
-
这段代码的 GitHub 链接点这里[14]
- // executeTask executes a task and returns the result and error.
- // If the task fails, it will be retried according to the retryCount of the pool.
- func (w *worker) executeTask(t task, pool *goPool) (result interface{}, err error) {
- for i := 0; i <= pool.retryCount; i++ {
- if pool.timeout > 0 {
- result, err = w.executeTaskWithTimeout(t, pool)
- } else {
- result, err = w.executeTaskWithoutTimeout(t, pool)
- }
- if err == nil || i == pool.retryCount {
- return result, err
- }
- }
- return
- }
为了保证可读性和可维护性,我可以控制了每个函数的长度,当一个函数的逻辑长到需要滚动鼠标才能看完时,我就会及时让 GPT-4 重构这段代码。
5.5 Task 执行错误处理
Task 执行出错怎么办?开始我也不知道怎么办,大家的 tasks 并不一样。不过 GPT-4 说可以通过“回调函数”来让调用方自定义“错误处理过程”。听起来不错,于是 GoPool 就加入了这样的用法:
- package main
-
- import (
- "errors"
- "fmt"
-
- "github.com/devchat-ai/gopool"
- )
-
- func main() {
- pool := gopool.NewGoPool(100, gopool.WithErrorCallback(func(err error) {
- fmt.Println("Task error:", err)
- }))
- defer pool.Release()
-
- for i := 0; i < 1000; i++ {
- pool.AddTask(func() (interface{}, error) {
- returnnil, errors.New("task error")
- })
- }
- pool.Wait()
- }
这里在 NewGoPool() 方法中传递了这样一个参数:
- gopool.WithErrorCallback(func(err error) {
- fmt.Println("Task error:", err)
- })
也就是说 GoPool 支持通过 gopool.WithErrorCallback() 传递一个 error 处理函数 func(err error) 进去,在这个自定义 error 处理函数中,你可以选择像这个例子一样简单地打印错误信息,也可以选择再次调用 pool.AddTask() 方法来重新执行这个 task。总之,错误交到你手里,怎么发落都行。
GoPool 中有一段处理 error 的逻辑:
-
这段代码的 GitHub 链接点这里[15]
- // handleResult handles the result of a task.
- func (w *worker) handleResult(result interface{}, err error, pool *goPool) {
- if err != nil && pool.errorCallback != nil {
- pool.errorCallback(err)
- } elseif pool.resultCallback != nil {
- pool.resultCallback(result)
- }
- }
也就是执行完 task 之后,如果发现回调函数 errorCallback 不为 nil,则调用 pool.errorCallback(err)
5.6 Task 执行结果检索
有时候我们需要 task 执行完返回一个结果,但是并发处理 tasks 的时候,这个结果怎么保存呢?GoPool 里提供了一个回调函数来支持自定义的结果处理方式:
- pool := gopool.NewGoPool(100, gopool.WithResultCallback(func(result interface{}) {
- fmt.Println("Task result:", result)
- }))
这里的逻辑和前面“Task 执行错误处理”非常像,就不过多赘述了。这里 result 是 interface{} 类型,也就是你可以自定义自己的 result 格式,然后在函数内自己决定如何处理这个 result,不管是简单的打印,还是存到某个 Channel 里,给你的 pipeline 中下一个环节处理。
5.7 Task 重试
有时候你希望自己提交多少次 tasks,就能成功执行多少次 tasks,但是 tasks 不总是100%运行成功,不过重试往往能解决问题,这时候你可以给 GoPool 设置重试次数:
pool := gopool.NewGoPool(100, gopool.WithRetryCount(3))当设置了 gopool.WithRetryCount(3) 之后,你的 task 就获得了3次重试机会。
不知道你是否还记得前面贴过的 executeTask() 函数,里面有一个 for 循环就是为了支持这里的 retry 逻辑:
-
这段代码的 GitHub 链接点这里[16]
- // executeTask executes a task and returns the result and error.
- // If the task fails, it will be retried according to the retryCount of the pool.
- func (w *worker) executeTask(t task, pool *goPool) (result interface{}, err error) {
- for i := 0; i <= pool.retryCount; i++ {
- if pool.timeout > 0 {
- result, err = w.executeTaskWithTimeout(t, pool)
- } else {
- result, err = w.executeTaskWithoutTimeout(t, pool)
- }
- if err == nil || i == pool.retryCount {
- return result, err
- }
- }
- return
- }
5.8 优雅停止
在 GoPool 中,Release 的逻辑是:已经通过 AddTask() 方法加入到任务池的任务全部执行完之后,Pool 才能被释放。对应的代码是这样的:
-
这段代码的 GitHub 链接点这里[17]
- // Wait waits for all tasks to be dispatched.
- func (p *goPool) Wait() {
- forlen(p.taskQueue) > 0 {
- time.Sleep(100 * time.Millisecond)
- }
- }
-
- // Release stops all workers and releases resources.
- func (p *goPool) Release() {
- close(p.taskQueue)
- p.cond.L.Lock()
- forlen(p.workerStack) != p.minWorkers {
- p.cond.Wait()
- }
- p.cond.L.Unlock()
- for _, worker := range p.workers {
- close(worker.taskQueue)
- }
- p.workers = nil
- p.workerStack = nil
- }
没错,我把 Wait() 方法也贴进来了。GoPool 推荐的用法是:
- pool := gopool.NewGoPool(100)
- defer pool.Release()
- pool.AddTask(func() (interface{}, error) {
- returnnil, nil
- })
- pool.Wait()
所以 Release() 方法应该在 Wait() 方法之后执行,于是关闭的逻辑就是等到 taskQueue 为空,然后 taskQueue 会被 close,也就意味着没有新的任务会被再添加进来。接着当 workerStack == minWorkers 时,也就意味着没有运行中的 workers,所有 workers 都空闲着(被入栈了),于是它们相应的内存就被释放了。
6. 测一测 GoPool 的性能!
我知道你肯定关注 GoPool 的性能,或许开头贴的性能数据你压根不信。毕竟往往功能越花哨,性能就越差,凭什么 GoPool 能够在支持一大堆的功能的同时还做到性能全网第一?接下来我们继续用 GPT-4 写的测试代码来进行一波压测!
6.1 先欣赏 GoPool 中的 Worker 池
在开始贴性能数据之前,我想先分享一个 GPT-4 在这次的 GoPool 实现中给我的小惊喜。
在 worker 池的实现过程中,我只是期望 GPT-4 能够用切片(Slice)的方式实现一个栈,用作 worker 池,这样需要 worker 的时候就能够通过栈的 Pop() 方法获取一个空闲的 worker,用完之后在通过 Push() 方法将 worker 入栈。我设想的是 GPT-4 给 goPool 结构体添加这样一行代码:
- type goPool struct {
- // ……
- workerStack []*worker
- // ……
- }
结果 GPT-4 技高一筹,给了这样2行:
- type goPool struct {
- // ……
- workers []*worker
- workerStack []int
- // ……
- }
这么一来我想要的“栈”就变成了“workers 切片索引的栈”,入栈和出栈操作都是动的 index,一个简单的 int 类型数字,然后通过这个 index 就能在 workers 切片中操作到具体的 worker 对象,这些 workers 躺在一个切片里不需要动脚来回跑,就能发光发热了。
Pop() 和 Push() 于是变成了这样(当然还是 GPT-4 写的):
-
这段代码的 GitHub 链接点这里[18]
- func (p *goPool) popWorker() int {
- p.lock.Lock()
- workerIndex := p.workerStack[len(p.workerStack)-1]
- p.workerStack = p.workerStack[:len(p.workerStack)-1]
- p.lock.Unlock()
- return workerIndex
- }
-
- func (p *goPool) pushWorker(workerIndex int) {
- p.lock.Lock()
- p.workerStack = append(p.workerStack, workerIndex)
- p.lock.Unlock()
- p.cond.Signal()
- }
于是后面 GPT-4 在任务分发函数 dispatch() 中就有了这样的用法:
-
这段代码的 GitHub 链接点这里[19]
- // dispatch dispatches tasks to workers.
- func (p *goPool) dispatch() {
- for t := range p.taskQueue {
- p.cond.L.Lock()
- forlen(p.workerStack) == 0 {
- p.cond.Wait()
- }
- p.cond.L.Unlock()
- workerIndex := p.popWorker()
- p.workers[workerIndex].taskQueue <- t
- }
- }
妙啊,相比我自己手撕代码能写出来的版本,明显性能要好一些。
6.2 选2个高 Star 的 Golang Worker Pool 项目来 PK
在 GitHub 上搜相关关键词,我找到了2个类似的项目:
1. pond
-
README 里的介绍:Minimalistic and High-performance goroutine worker pool written in Go.
-
翻译过来就是:一个 Go 实现的高性能的极简 Worker Pool。
-
目前 Star 数是 932(2023年7月27日)
2. ants
-
README 里的介绍:Library ants implements a goroutine pool with fixed capacity, managing and recycling a massive number of goroutines, allowing developers to limit the number of goroutines in your concurrent programs.
-
翻译过来就是:ants 库实现了一个固定容量的 goroutine pool,可以管理和回收大量的 goroutines,让开发者能够在并发程序中限制 goroutines 数量。
-
目前 Star 数是 10.7k(2023年7月27日)
6.3 编写压测代码,测试相同条件下 GoPool、Pond 和 Ants 的性能差异
在翻看 pond 和 ants 项目的 README 文件之后,我大致知道了它们怎么用。于是我在本地新建了一个 demo 项目,里面放了一个 pool_test.go,写下来这些代码:
- package main
-
- import (
- "sync"
- "testing"
- "time"
-
- "github.com/alitto/pond"
- "github.com/devchat-ai/gopool"
- "github.com/panjf2000/ants/v2"
- )
-
- const (
- PoolSize = 10000
- TaskNum = 1000000
- )
-
- func BenchmarkGoPool(b *testing.B) {
- pool := gopool.NewGoPool(PoolSize)
- defer pool.Release()
-
- taskFunc := func() (interface{}, error) {
- time.Sleep(10 * time.Millisecond)
- returnnil, nil
- }
-
- b.ResetTimer()
- for i := 0; i < b.N; i++ {
- for i := 0; i < TaskNum; i++ {
- pool.AddTask(taskFunc)
- }
- pool.Wait()
- }
- }
-
- func BenchmarkPond(b *testing.B) {
- pool := pond.New(PoolSize, 0, pond.MinWorkers(PoolSize))
-
- taskFunc := func() {
- time.Sleep(10 * time.Millisecond)
- }
-
- b.ResetTimer()
- for i := 0; i < b.N; i++ {
- for i := 0; i < TaskNum; i++ {
- pool.Submit(taskFunc)
- }
- pool.StopAndWait()
- }
- }
-
- func BenchmarkAnts(b *testing.B) {
- var wg sync.WaitGroup
- p, _ := ants.NewPool(PoolSize)
- defer p.Release()
-
- taskFunc := func() {
- time.Sleep(10 * time.Millisecond)
- wg.Done()
- }
-
- b.ResetTimer()
- for i := 0; i < b.N; i++ {
- for i := 0; i < TaskNum; i++ {
- wg.Add(1)
- _ = p.Submit(taskFunc)
- }
- wg.Wait()
- }
- }
对应的 go.mod 文件如下:
- module demo
-
- go1.20
-
- require (
- github.com/alitto/pond v1.8.3
- github.com/devchat-ai/gopool v0.3.0
- github.com/panjf2000/ants/v2 v2.8.1
- )
接下来就可以拿到百万任务量级下三个 pool 的吞吐能力差异了。
6.4 10k 并发,1000k 任务量压测结果
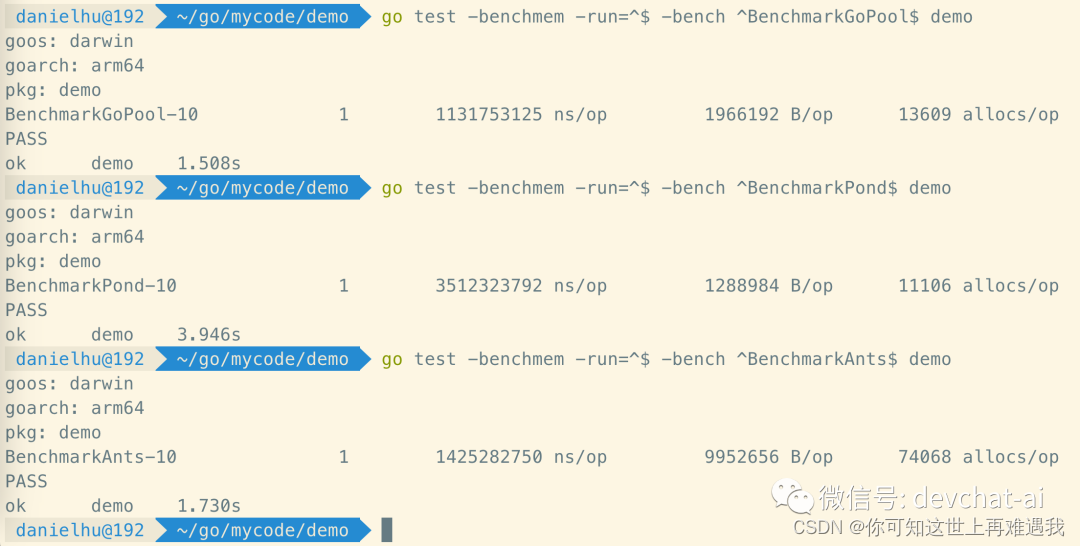
可见在 10k pool 容量的情况下,处理 1000k(一百万)任务耗时分别是:
-
GoPool - 1.13s
-
ants - 1.43s
-
pond - 3.51s
内存消耗分别是:
-
pond: 1288984B = 1.23MB
-
GoPool: 1966192B = 1.88MB
-
ants: 9952656B = 9.49MB
数据比我想象中的好呀,综合表现 GoPool 妥妥第一名!
-
于是我们得到了文章开头的那张表格,也就是百万任务,一万并发,GoPool 性能力压 GitHub 万星项目 ants[20] 和千星项目 pond[21]:
| Project | Time to Process 1M Tasks (s) | Memory Consumption (MB) |
|---|---|---|
| GoPool | 1.13 | 1.88 |
| ants(10k star) | 1.43 | 9.49 |
| pond(1k star) | 3.51 | 1.23 |
7. 驾驭 AI,当“新程序员”!
一下没收住,这篇文章奔着一万字去了。
我本想在本文详细介绍每一轮 prompt,每一轮 GPT-4 给的回答,在这个过程中也向你展示那些 prompts GPT-4 可以给出比较好的回答,哪些特定的问题适合交给 GPT-4 来解决,又有哪些任务 GPT-4 处理不好。不过显然这样2万字也写不完,所以干脆就先给大家看个全貌,看个结果,看下 GPT-4 的作品 GoPool 在功能和性能上表现如何,先让大家对“GPT-4 能做到什么”有个直观的印象。后面我会持续更新更多的文章,展开细聊在 GoPool 开发过程中,如何让 GPT-4 完成诸如代码重构、测试用例编写、文档补全、bug 定位和修复等等工作。
总的来说,GPT-4 确实打开了潘多拉魔盒,可以预见在不久的将来,各种软件项目中 GPT-4 生成的代码占比会很大。不知道大家有没有经历过 ChatGPT 恐惧期,担心自己被 AI 取代。
经过几个月的“与 GPT-4 共舞”之后,我发现当下 AI 取代程序员为时尚早,至少 GPT-4 还做不到(GPT-5 或者 GPT-6 能不能做到我说不准)。当你能够很清楚地描述自己的需求时,如果这个需求不是非常复杂的逻辑,这时候往往 GPT-4 能够给出很漂亮的代码。但是 GPT-4 也不总是正确的,有时候它给的100行代码里可能有1行存在 bug,这时候如果你无法看懂 GPT-4 生成的代码,那么尽管这100行代码里只包含1行错误,但是运行不起来,这100行对你来说就一文不值。反之你能找到这一行错误,那 GPT-4 就相当于帮你写了99行,这是何等的效率提升啊!
另外由于上下文大小的限制,你也无法将很长的代码发给 GPT-4,也不能一次性让 GPT-4 帮你写很长的代码。所以项目稍微复杂一些之后,“人”还是必须“坐在驾驶位”,而 GPT-4 只能做在“副驾驶位”,当你的领航员,陪你聊天,回答你的问题,你听得懂,她就有价值;你听不懂,那她就是噪音,是 dead weight,只能拖慢你的开车速度。
总之当下最佳姿势,是骑着 AI,驾驭 AI,借 AI 之力提升自己的工作效率,当一个“会用 GPT 写代码”的“新程序员”!

