
热门标签
热门文章
- 1Git入门-远程仓库GitHub_git是本地库吗,github是远程库吗
- 2【数模比赛】2023美国大学生数学建模比赛(思路、代码......)_数学建模比赛会运行代码吗
- 3Github 2024-05-18 开源项目日报 Top10
- 4统计各位数字之和是5的数_各位数字之和为5的数python
- 5MySQL分区Partition_mysql partition
- 6选择、冒泡、插入排序、二分法、异或应用_冒泡排序与选择排序的时间复杂度与数组的初始状态无关
- 7LitCTF2023 郑州轻工业大学首届网络安全赛 WP 部分_[litctf 2023]vim yyds
- 82. Python--pandas库_pandas python 字典
- 9人工智能相关的比赛_人工智能比赛项目
- 10GitHub优秀开源项目收集
当前位置: article > 正文
python 使用 pdf2image 库将PDF转换为图片
作者:Gausst松鼠会 | 2024-05-30 20:57:32
赞
踩
pdf2image
在数字化时代,PDF(Portable Document Format)文件成为了一种常见的文件格式,但有时我们需要将PDF文件转换成图片以便于在网页、演示文稿或其他应用中使用。本文将介绍如何使用Python的pdf2image库来将PDF文件转换为图片
初
希望能写一些简单的教程和案例分享给需要的人
环境
Python 3.10.12
系统: ubuntu 22.04
步骤一:安装pdf2image库
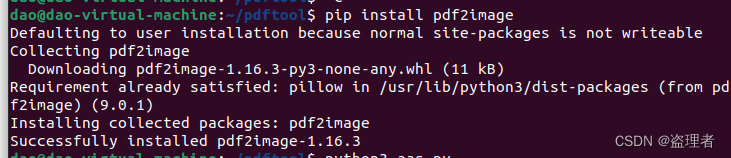
首先,我们需要安装pdf2image库,这可以通过以下命令在命令行中进行安装:
pip install pdf2image
- 1
步骤二:导入必要的库
在您的Python脚本中,首先导入所需的库,包括我们即将使用的pdf2image库:
from pdf2image import convert_from_path
- 1
步骤三:指定PDF文件路径
将要转换为图片的PDF文件放置在您选择的路径下,并将该路径赋值给变量pdf_path:
pdf_path = 'test.pdf'
- 1
请确保将test.pdf替换为您实际的PDF文件路径。
步骤四:将PDF转换为图片
使用convert_from_path函数从指定的PDF文件中提取图像,并将它们存储在一个名为images的列表中:
images = convert_from_path(pdf_path)
- 1
步骤五:保存图像为图片文件
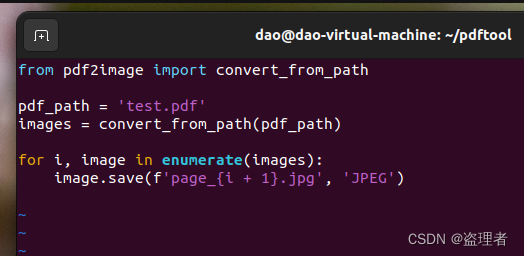
遍历images列表,将每个图像保存为JPEG格式的图片文件。我们使用循环为每个图像文件命名,命名格式为page_i.jpg,其中i表示页码:
for i, image in enumerate(images):
image.save(f'page_{i + 1}.jpg', 'JPEG')
- 1
- 2
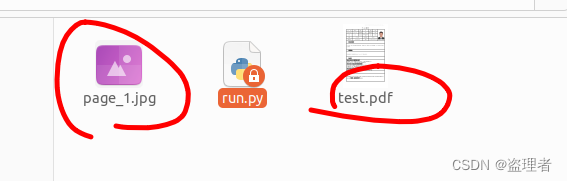
当这一步骤完成后,您将在脚本所在的目录中找到与PDF文件页数对应的图片文件。
完整代码
from pdf2image import convert_from_path
pdf_path = 'test.pdf'
images = convert_from_path(pdf_path)
for i, image in enumerate(images):
image.save(f'page_{i + 1}.jpg', 'JPEG')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加上注释的代码如下:
# 导入所需库
from pdf2image import convert_from_path
# 指定PDF文件路径
pdf_path = 'test.pdf'
# 将PDF文件转换为图片
images = convert_from_path(pdf_path)
# 遍历图片列表并保存为图片文件
for i, image in enumerate(images):
image.save(f'page_{i + 1}.jpg', 'JPEG')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行结果
python3 run.py
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/648579
推荐阅读
相关标签

