- 1赠书 | 程序员修炼的务实哲学
- 2Unity开发安卓游戏(2):基于安卓游戏的优化方案总结
- 3零代码上线小布对话技能:技能平台的实践与思考_语音助手技能开发管理平台
- 4K8S中的网络_k8s网络
- 5项目管理神器——Confluence篇_conf什么工作空间
- 6python创建窗口接收消息延迟_解决python tkinter 与 sleep 延迟问题
- 7关于小程序mock数据测试手机调试不显示数据问题_小程序云测 mock 失败
- 8驱动工程师面试_c驱动初级工程师面试问题
- 9UnityShader_多重编译_skip_variants
- 10卷积神经网络中的图像特征——以YOLOv5为例进行可视化_yolov5在测试的时候,怎么把所有图片上的标注都可视化出来
2023年 18篇神经架构搜索(Neural Architecture Search) ICCV ICML NIPS IJCAI 阅读笔记_construction of hierarchical neural architecture s
赞
踩
目录
1. EMQ: Evolving Training-free Proxies for Automated Mixed Precision Quantization (ICCV)
2. MixPath: A Unified Approach for One-shot Neural Architecture Search (ICCV)
3. Automated Knowledge Distillation via Monte Carlo Tree Search (ICCV)
5. Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks (ICML)
6. PreNAS: Preferred One-Shot Learning Towards Efficient Neural Architecture Search (ICML)
7. QAS-Bench: Rethinking Quantum Architecture Search and A Benchmark (ICML)
9. Relevant Walk Search for Explaining Graph Neural Networks (ICML)
11. Unsupervised Graph Neural Architecture Search with Disentangled Self-supervision (NIPS)
12. EvoPrompting: Language Models for Code-Level Neural Architecture Search (NIPS)
14. Multi-task Graph Neural Architecture Search with Task-aware Collaboration and Curriculum (NIPS)
15. Evolutionary Neural Architecture Search for Transformer in Knowledge Tracing (NIPS)
16.GeNAS: Neural Architecture Search with Better Generalization (IJCAI)
17. LISSNAS: Locality-based Iterative Search Space Shrinkage for Neural Architecture Search(IJCAI)
1. EMQ: Evolving Training-free Proxies for Automated Mixed Precision Quantization (ICCV)
| Aim: | 本研究的目的是解决混合精度量化(Mixed-Precision Quantization, MQ)在搜索每层比特宽度配置时的效率问题。传统的基于训练的搜索方法需要耗时的候选训练,而最近的一些无需训练的方法虽然提高了搜索效率,但这些方法和量化精度之间的关联性尚不清楚。因此,这项研究旨在通过构建MQ-Bench-101基准和自动搜索框架,来寻找更有效的MQ代理。 |
| Abstract: | 混合精度量化(MQ)可以在模型的精度和复杂度之间实现有竞争力的权衡。传统的基于训练的搜索方法需要耗时的候选者训练,以搜索 MQ 中优化的每层 位宽配置。最近,一些无需训练的方法提出了各种 MQ 代理,大大提高了搜索效率。大大提高了搜索效率。然而,这些代用指标与量化精度之间的相关性 之间的相关性却知之甚少。为了填补这一空白,我们首先建立了 MQ-Bench-101,其中涉及不同的位配置 和量化结果。然后,我们观察到现有的免训练代理在 MQ-Bench-101。为了有效地寻找更优的代理,我们开发了一个自动搜索代理的框架,通过 MQ 演化算法自动搜索代理框架。特别是,我们设计了一个精心设计的 搜索空间,并执行 进化搜索来发现最佳相关 MQ 代理。我们提出了一种多样性提示选择策略和 兼容性筛选协议,以避免过早收敛并提高搜索效率。这样,我们的 混合精度量化(EMQ)的演化代理 框架可以自动生成代理,而无需进行大量调整和学习专家知识。大量实验 广泛的实验 与各种 ResNet 和 MobileNet 系列在 ImageNet 上的广泛实验 证明,我们的 EMQ 的性能,而且成本显著降低。 |
| Conclusion: | EMQ框架能够有效地自动生成与混合精度量化高度相关的代理,从而在降低成本的同时,实现了超越现有混合精度方法的优越性能。这一结果在ImageNet上使用各种ResNet和MobileNet家族进行的广泛实验中得到了证明。此外,将公开代码以便进一步的研究和应用。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
The code will be released.
|


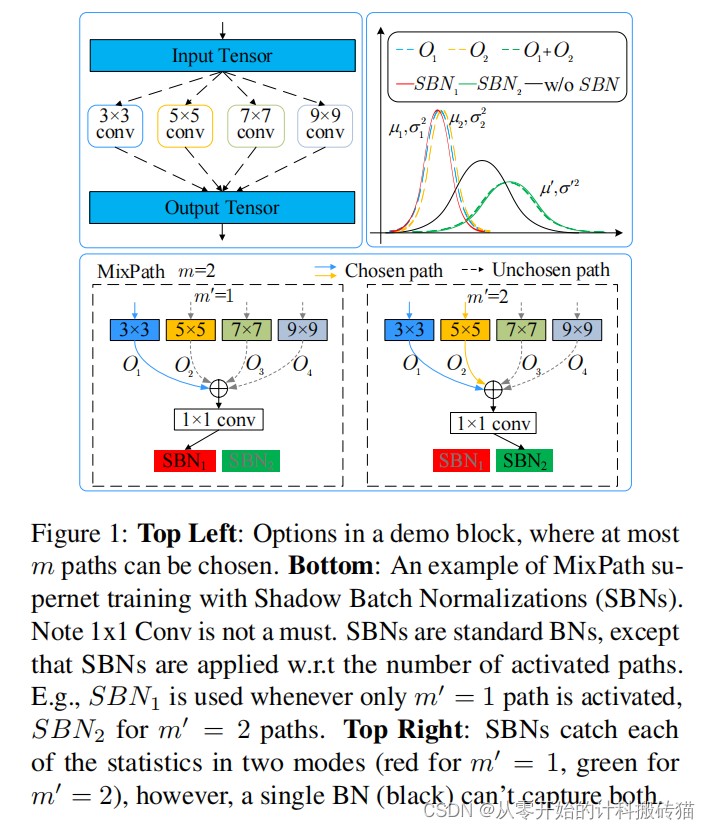
2. MixPath: A Unified Approach for One-shot Neural Architecture Search (ICCV)
| Aim: | 这项研究的目标是解决在神经架构设计中,如何高效搜索多路径结构模型的问题。尽管将多个卷积核融合在一起在神经架构设计中已被证明是有优势的,但当前的两阶段神经架构搜索方法主要限于单路径搜索空间。因此,这项研究旨在通过训练一种一次性多路径超网络(supernet),来准确评估候选架构。 |
| Abstract: | 混合多个卷积核在神经结构设计中具有优势。然而,目前的两阶段神经结构搜索方法主要局限于单路径搜索空间。如何有效地搜索多路径结构的模型仍然是一个难题。在本文中,我们的动机是训练一个一次性的多路径超网来准确地评估候选架构。具体地说,我们发现在所研究的搜索空间中,从多条路径求和的特征向量几乎是来自单个路径的特征向量的倍数。这种差异扰乱了超级网的训练及其排名能力。因此,我们提出了一种新的机制,称为阴影批处理归一化(SBN)来规范不同的特征统计量。大量的实验证明,sbn能够稳定优化和提高排名性能。我们称我们的统一多路径一次性方法为混合路径,它生成一系列的模型,在ImageNet上实现最先进的结果。 |
| Conclusion: | MixPath作为一个统一的多路径一次性方法,通过引入SBN机制,有效地解决了多路径结构模型在神经架构搜索中的评估和优化问题。通过这种方法,研究者能够生成一系列在ImageNet上取得最先进成果的模型,这验证了MixPath方法的有效性和优越性。 |
| Methods: |
|
| Keyresults: |
|
| Code: | None |
3. Automated Knowledge Distillation via Monte Carlo Tree Search (ICCV)
| Aim: | 这篇论文提出了Auto-KD,这是第一个自动化搜索框架,用于寻找最优的知识蒸馏设计。目的在于解决传统蒸馏技术需要专家手工设计和针对不同师生对进行广泛调整的问题。Auto-KD旨在通过实验研究不同的蒸馏器,找到它们可以如何被分解、组合和简化的方法。 |
| Abstract: | Auto-KD是一个有前景且实用的方法,广泛的实验表明,它能够很好地泛化到不同的CNN和视觉变换器模型,并在包括图像分类、目标检测和语义分割在内的一系列视觉任务中达到最先进的性能。提供的代码进一步促进了这一方法的应用和研究。Auto-KD是一个有前景且实用的方法,广泛的实验表明,它能够很好地泛化到不同的CNN和视觉变换器模型,并在包括图像分类、目标检测和语义分割在内的一系列视觉任务中达到最先进的性能。提供的代码进一步促进了这一方法的应用和研究。 |
| Conclusion: | Auto-KD是一个有前景且实用的方法,广泛的实验表明,它能够很好地泛化到不同的CNN和视觉变换器模型,并在包括图像分类、目标检测和语义分割在内的一系列视觉任务中达到最先进的性能。提供的代码进一步促进了这一方法的应用和研究。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/lilujunai/Auto-KD
|
4. ROME: Robustifying Memory-Efficient NAS via Topology Disentanglement and Gradient Accumulation (ICCV)
| Aim: | 这篇论文的目的是解决可微架构搜索(DARTS)的关键问题,尤其是在内存成本方面。虽然单路径DARTS因为只选择每一步的单一路径子模型而内存友好且计算成本低,但它也遭遇了性能崩溃的严重问题,类似于DARTS中由于过多无参数操作(如跳跃连接)而导致的问题。因此,这篇论文提出了一种新算法——RObustifying Memory-Efficient NAS (ROME),来解决这一问题。 |
| Abstract: | 尽管可区分的架构搜索(飞镖)是一种流行的架构搜索方法,但由于整个超级网络的内存成本在很大程度上被驻留在内存中。这就是单路径飞镖的作用所在,它在每一步只选择一个单路径子模型。虽然它对内存很友好,但其计算成本也很低。尽管如此,我们发现了一个没有被主要注意到的关键问题。也就是说,它也会遭受严重的性能崩溃,因为有太多的无参数的操作,就像飞镖一样。在本文中,我们提出了一种新的算法,称为旋转记忆高效NAS(罗马)给出治愈。首先,我们将拓扑搜索与操作搜索分离,使搜索和评价一致。然后,我们采用Gumbel-Top2重新参数化和梯度积累来改进笨拙的双级优化。我们在15个基准测试中广泛地验证了罗马,以证明其有效性和健壮性。 |
| Conclusion: | ROME算法成功地解决了单路径DARTS中的性能崩溃问题,提供了一种既稳健又内存高效的神经架构搜索方法。通过在多个基准测试中的应用,ROME证明了其在提高搜索效率和减少内存消耗方面的优越性。这些结果表明,ROME是一个有效的解决方案,适用于需要内存高效的神经架构搜索任务。 |
| Methods: |
|
| Keyresults: |
|
| Code: | None\ |

5. Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks (ICML)
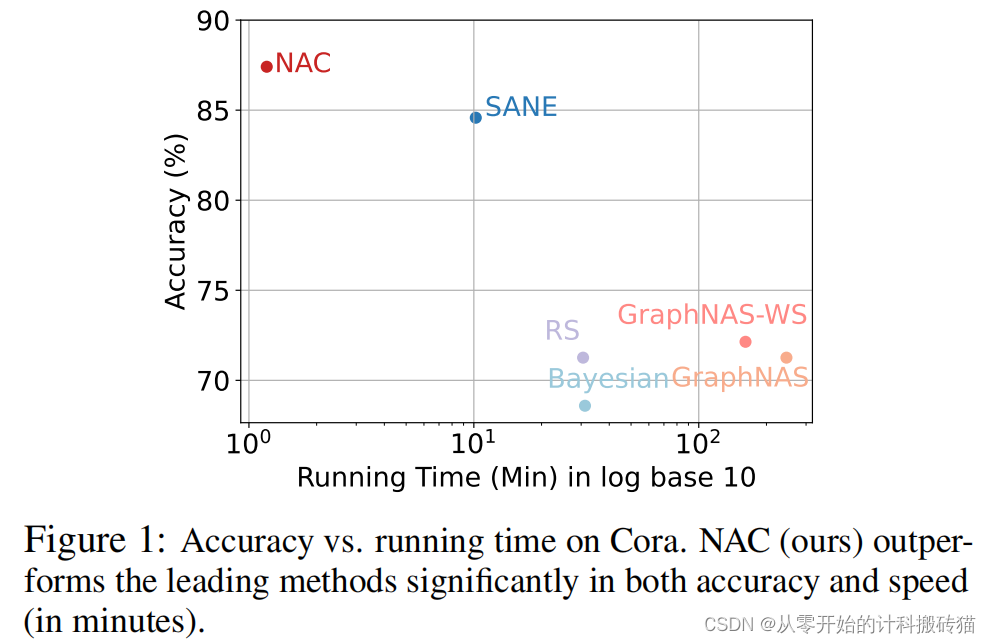
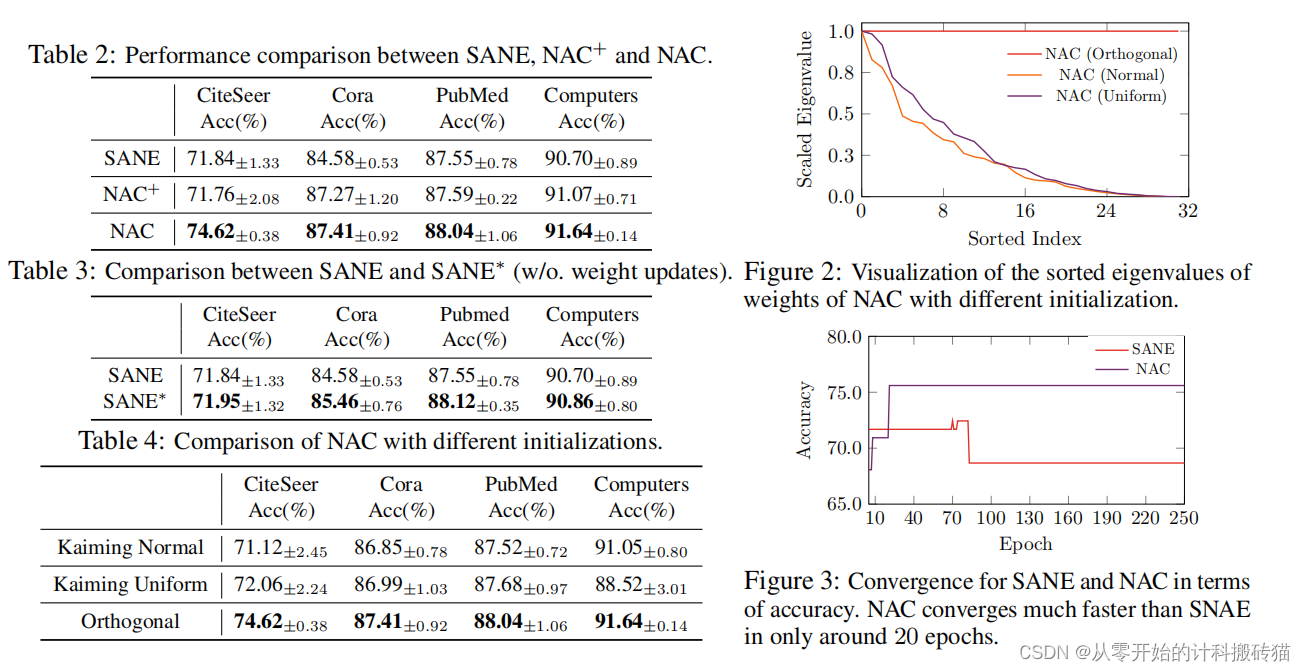
| Aim: | 这篇论文旨在解决图神经网络(GNNs)的神经架构搜索(NAS)问题,称为NAS-GNNs。虽然NAS-GNNs在手工设计的GNN架构上取得了显著性能提升,但这些方法继承了传统NAS方法的问题,如高计算成本和优化难度。更重要的是,以前的NAS方法忽略了GNN的独特性,即GNN即使在不经训练的情况下也具有表达能力。因此,本文提出了一种新的NAS-GNN方法——神经架构编码(NAC)。 |
| Abstract: | 图神经网络(GNNs)的神经体系结构搜索(NAS),称为NAS-GNNs,比人工设计的GNN体系结构取得了显著的性能。然而,这些方法继承了传统NAS方法的计算成本高、优化困难等问题。更重要的是,以往的NAS方法忽略了gnn的唯一性,即gnn在没有训练的情况下具有表达能力。利用随机初始化的权值,我们可以通过稀疏编码目标寻找最优的结构参数,并推导出一种新的NAS-GNNs方法,即神经结构编码(NAC)。因此,我们的NAC在gnn上采用了一种无更新的方案,并且可以在线性时间内有效地进行计算。对多个GNN基准数据集的实证评估表明,我们的方法导致了最先进的性能,比强基线更快200×,更准确18.8%。 |
| Conclusion: | NAC方法在GNN的神经架构搜索中实现了显著的性能提升,既减少了计算成本,又提高了优化效率。这一方法充分利用了GNN的独特表达能力,即使在权重随机初始化的情况下,也能寻找到最优的架构参数。这些成果表明,NAC是一个有效且实用的解决方案,适用于需要高效且精确的GNN架构搜索任务 |
| Methods: |
|
| Keyresults: |
|
| Code: | None\ |
6. PreNAS: Preferred One-Shot Learning Towards Efficient Neural Architecture Search (ICML)
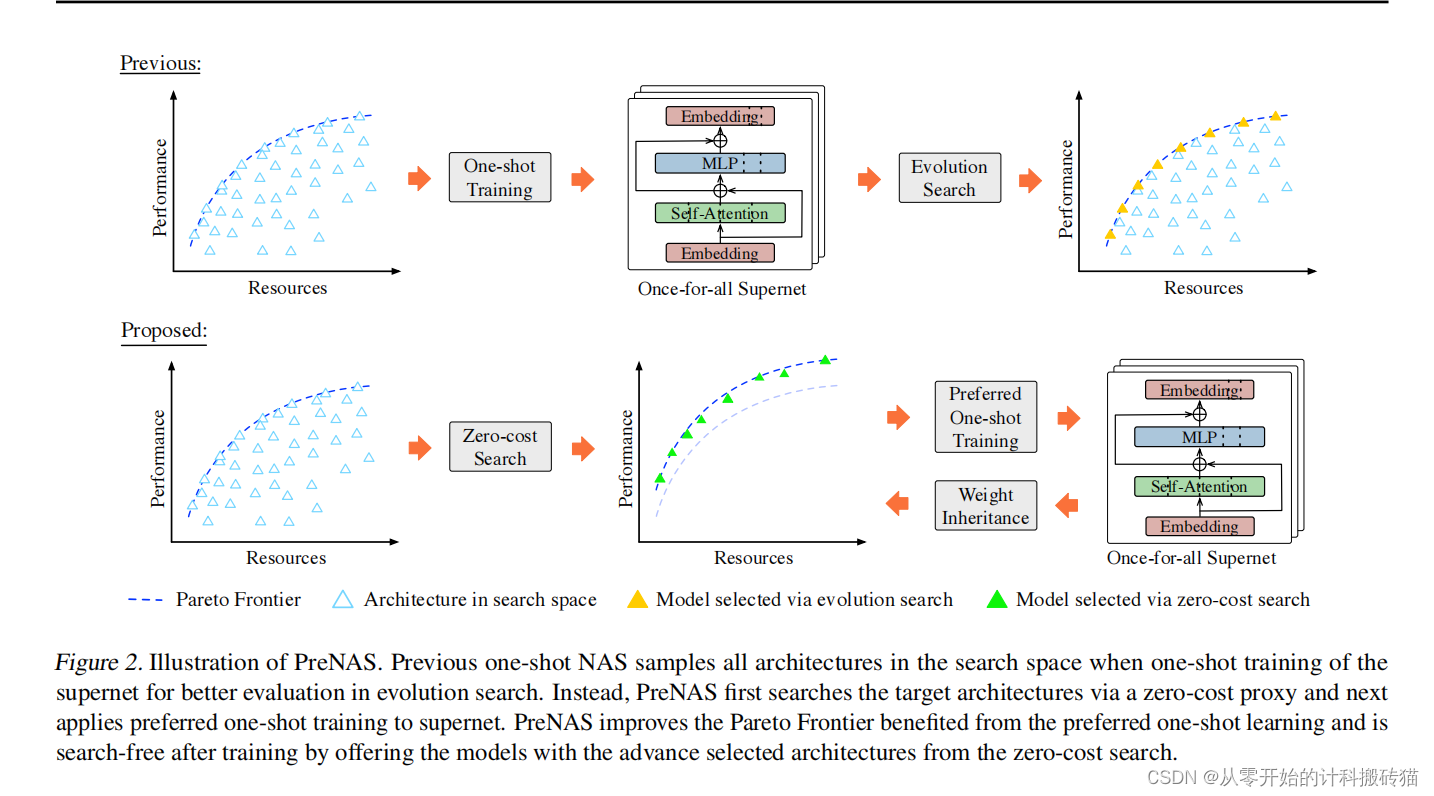
| Aim: | 这篇论文提出了PreNAS,一种无需搜索的一次性神经架构搜索(NAS)方法。这种方法旨在解决传统一次性NAS中存在的问题,即在庞大的样本空间内训练会损害单个子网络的性能,并且需要大量计算来搜索最佳模型。PreNAS的目标是在一次性训练中突出目标模型,减少搜索成本。 |
| Abstract: | 预训练模型的广泛应用推动了在热门神经结构搜索(NAS)中一劳永逸的训练的趋势。然而,在一个巨大的样本空间中进行训练会损害单个子网的性能,并且需要大量的计算来寻找最优模型。在本文中,我们提出了PreNAS,一种无搜索的NAS方法,在一次性训练中强调目标模型。具体来说,通过零成本选择器提前显著减少了样本空间,并在首选架构上进行一次共享训练,以缓解更新冲突。大量的实验表明,在视觉变压器和卷积架构方面,PreNAS始终优于最先进的一次性NAS竞争对手,而且重要的是,它能够在零搜索成本的情况下实现即时专业化。 |
| Conclusion: | PreNAS作为一种新颖的无需搜索的一次性NAS方法,通过预先减少样本空间和执行针对偏好架构的权重共享训练,有效地解决了传统一次性NAS中的性能损害和高计算成本问题。它在多个实验中展示了优于现有一次性NAS方法的性能,并且能够实现零搜索成本的即时模型专业化。这一方法的实用性和效率使其成为一种有吸引力的选择,特别是在需要快速而准确的架构搜索场景中。提供的代码进一步促进了这一方法的应用和研究。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/tinyvision/PreNAS.
|

7. QAS-Bench: Rethinking Quantum Architecture Search and A Benchmark (ICML)
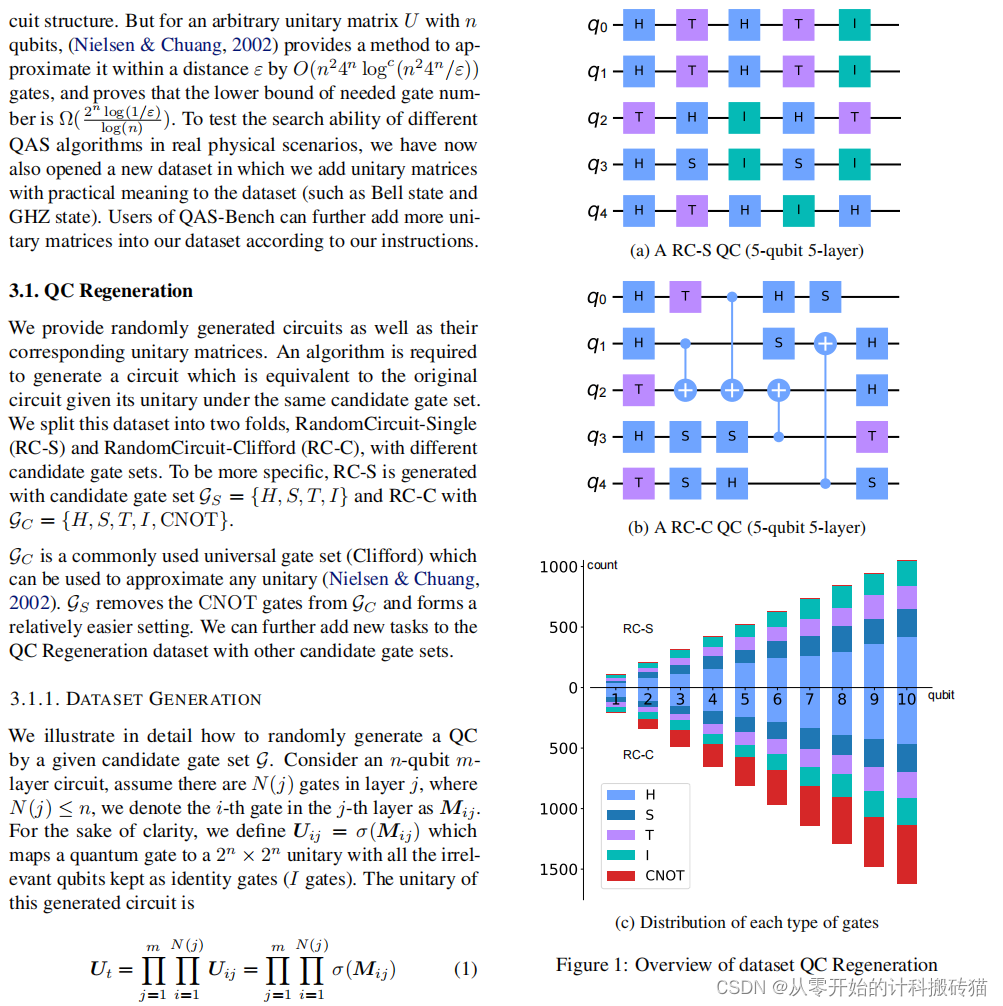
| Aim: | 本文的目的是在跨学科领域内广泛研究自动量子架构搜索(QAS),并超越特定领域,将QAS问题归纳为两个基本(且相对理想)的任务:i) 根据目标量子电路(QC)重建任意量子电路;ii) 近似任意幺正(oracle)。后者与各种量子机器学习任务和其他QAS应用的设置相关。基于这两项任务,论文提出了一个公共QAS基准测试,包括900个随机QCs和400个随机幺正矩阵,这在现有文献中尚未见到。 |
| Abstract: | 自动量子架构搜索(QAS)已经被广泛地研究,跨学科具有不同的含义。在本文中,超越一个特定的领域,我们将QAS问题表述为两个基本的(相对理想的)任务: i)给定的任意量子电路(QC)再生目标QC;ii)近似任意幺正(oracle)。后者可以连接到各种量子机器学习任务的设置和其他QAS应用程序。基于这两个任务,我们生成了一个公共的QAS基准,包括900个随机qc和400个随机酉矩阵,这些矩阵在文献中仍然缺失。自动量子架构搜索(QAS)已经被广泛地研究,跨学科具有不同的含义。在本文中,超越一个特定的领域,我们将QAS问题表述为两个基本的(相对理想的)任务: i)给定的任意量子电路(QC)再生目标QC;ii)近似任意幺正(oracle)。后者可以连接到各种量子机器学习任务的设置和其他QAS应用程序。基于这两个任务,我们生成了一个公共的QAS基准,包括900个随机qc和400个随机酉矩阵,这些矩阵在文献中仍然缺失。 |
| Conclusion: | 这篇论文通过建立一个新的公共QAS基准测试和提出一种新的评估协议,为自动量子架构搜索提供了一个更广泛和统一的研究框架。该研究突出了在不依赖领域特定设计和技术的情况下,对各种搜索方法的有效性进行评估的重要性。此外,通过对幺正近似任务的分析,本研究揭示了量子架构搜索领域面临的算法挑战,即需求探索更广泛的解空间以适应更复杂的量子任务。这些发现为量子机器学习和其他QAS应用提供了重要的洞见和指导。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/Lucky-Lance/QAS-Bench.
|
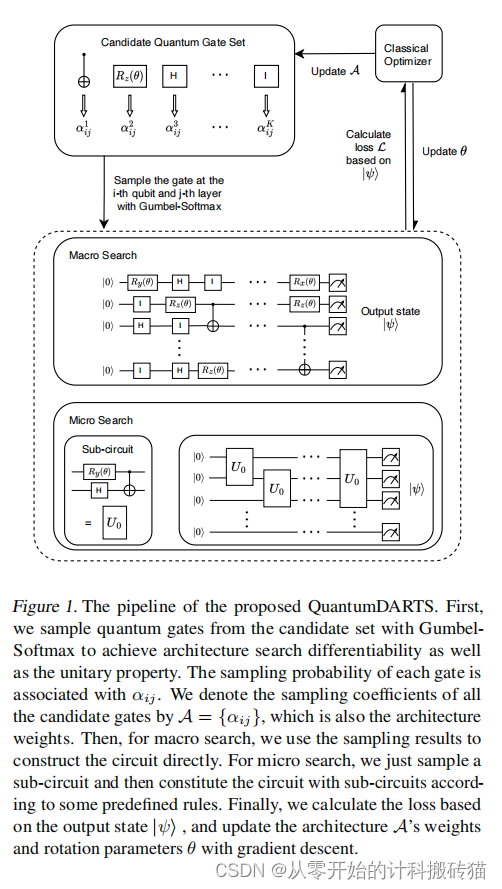
8. QuantumDARTS: Differentiable Quantum Architecture Search for Variational Quantum Algorithms (ICML)
| Aim: | 这篇论文可能旨在探索量子机器学习领域中的一种新方法:使用可微分量子架构搜索(QuantumDARTS)来优化变分量子算法。其主要目标可能是提高变分量子算法的性能和效率,同时降低设计复杂量子电路所需的专家知识和时间成本。 |
| Abstract: | 随着噪声中尺度量子(NISQ)时代的到来和机器学习的快速发展,变分量子算法(VQA)包括变分量子本征求解器(VQE)和变分神经网络(QNN)在可预见的将来受到了越来越多的广泛应用的关注。我们研究了VQA自动设计参数化量子电路(PQC)的量子架构搜索(QAS)问题。我们设计了一种基于Gumbel-Softmax的可微搜索算法,而不是针对那些通常需要大量电路采样和评估的同行方法。本文提供了我们的算法的两个版本,即宏观搜索和微观搜索,其中宏观搜索像其他文献一样直接搜索整个电路,而创新的微观搜索能够从小规模问题中推断出子电路结构,然后将其转移到大规模问题中。我们对非加权最大割、基态能量估计和图像分类进行了密集的实验。其优越的性能显示了宏观搜索的效率和能力,这只需要很少的先验知识。此外,微搜索实验表明了我们的算法在大规模QAS问题上的潜力。 |
| Conclusion: | QuantumDARTS可能展示了一种有效的方法来自动化量子算法的设计过程,尤其是在变分量子算法方面。这种方法可能证明了在量子计算领域,类似于经典机器学习的技术也可以被应用和适应。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/Lucky-Lance/QAS-Bench.
|
9. Relevant Walk Search for Explaining Graph Neural Networks (ICML)
| Aim: | 论文的目的是改进图神经网络(GNNs)的可解释性方法,尤其是通过图神经网络的层次相关传播(GNN-LRP)来评估网络中重要信息流的相关性。由于GNN-LRP在识别相关路径时存在的指数级计算复杂性,论文提出了一种多项式时间算法,用于找到最相关的前K个路径,从而显著降低计算成本,并提高GNN-LRP在大规模问题中的应用性。 |
| Abstract: | 图神经网络(GNNs)已成为图分析中重要的机器学习工具,其可解释性对于安全性、公平性和鲁棒性至关重要。针对GNNs的层次相关传播(GNN-LRP)通过评估路径的相关性来揭示网络中的重要信息流,并提供更高阶的解释,显示出比较低阶的节点-/边级解释更为优越。然而,GNN-LRP在识别相关路径时需要指数级的计算复杂性。本文提出了一种多项式时间算法,用于寻找最相关的前K个路径,显著降低了计算成本,增加了GNN-LRP在大规模问题中的应用性。我们的算法基于最大乘积算法,在神经元级别精确地、在节点级别近似地寻找最相关的路径。我们的实验展示了算法在不同领域的性能和实用性,如流行病学、分子和自然语言基准测试。我 |
| Conclusion: | 本文提出的算法有效地解决了GNN-LRP在识别相关路径时存在的计算复杂性问题,使其能够在大规模问题中得到应用。通过实验,证明了该算法在不同应用领域的有效性和实用性,为GNN的可解释性提供了一种有效的方法。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/xiong-ping/rel_walk_gnnlrp.
|

10. Shortest Edit Path Crossover: A Theory-driven Solution to the Permutation Problem in Evolutionary Neural Architecture Search (ICML)
| Aim: | 这篇论文的目标是提供对黑盒神经架构搜索(NAS)中变异、交叉和强化学习(RL)行为的首次理论分析,并提出一种新的交叉操作符以克服NAS中的排列问题。目的是为了使基于种群的搜索方法(如进化算法)在NAS中更有效,尤其是在利用交叉操作方面。 |
| Abstract: | 近期,基于种群的搜索方法作为强化学习(RL)在黑盒神经架构搜索(NAS)的可能替代方案出现。尽管该方法在实践中表现良好,但其理论基础尚不完善。特别是,传统基于种群的搜索方法(如进化算法)虽然在交叉操作中表现出力量,但在NAS中难以发挥优势,主要障碍是排列问题。本文首次对黑盒NAS中的变异、交叉和RL行为进行理论分析,并提出基于图空间中最短编辑路径(SEP)的新交叉操作符。理论上,SEP交叉操作符克服了排列问题,并且预期改进效果优于变异、标准交叉和RL。实证结果表明,SEP在最新NAS基准测试中性能优于其他方法。因此,SEP交叉操作符使得基于种群的搜索在NAS中的应用更加充分,其背后的理论为深入理解黑盒NAS方法提供了基础。 |
| Conclusion: | 这篇论文通过理论分析和实证测试展示了SEP交叉操作符在解决黑盒NAS中的关键问题——排列问题方面的有效性。SEP交叉操作符不仅在理论上克服了这一挑战,还在实际应用中展示了优于变异、标准交叉和RL的性能。因此,它为基于种群的NAS搜索方法提供了全新的视角,并为深入理解和发展黑盒NAS方法提供了坚实的理论基础。 |
| Methods: |
|
| Keyresults: |
|
| Code: | None |

11. Unsupervised Graph Neural Architecture Search with Disentangled Self-supervision (NIPS)
| Aim: | 这篇论文旨在研究无监督图神经架构搜索(GNAS)的问题,这是一个在文献中尚未探索的领域。目标是发现潜在的图因子,这些因子推动图数据的形成及其与最优神经架构之间的潜在关系。鉴于图因子与架构的高度交织性,解决这一问题具有挑战性。 |
| Abstract: | 现有的图神经架构搜索(GNAS)方法在搜索过程中严重依赖于监督标签,无法处理没有监督的普遍场景。在本文中,我们研究了文献中尚未探索的无监督图神经架构搜索问题。关键问题是发现推动图数据形成以及因子与最优神经架构之间潜在关系的潜在图因子。由于图的性质和神经架构搜索过程的复杂性,潜在图因子与架构高度交织在一起,处理这个问题具有挑战性。为了应对这一挑战,我们提出了一种新颖的解耦自监督图神经架构搜索(DSGAS)模型,该模型能够基于未标记的图数据以自监督的方式发现捕捉各种潜在图因子的最优架构。具体来说,我们首先设计了一个能够整合多种架构并进行因子解耦的图超网络,并同时进行优化。然后,我们通过我们提出的自监督训练和架构-图解耦来估计不同因子下架构的性能。最后,我们提出了一种带有架构增强的对比搜索方法,以发现具有因子特定专长的架构。在11个真实世界数据集上的广泛实验表明,提出的DSGAS模型能够以无监督的方式实现对几种基线方法的最先进性能。 |
| Conclusion: | 这篇论文提出的DSGAS模型成功地解决了无监督图神经架构搜索的问题,通过自监督训练和解耦策略,有效地发现了适应各种潜在图因子的最优架构。这种方法不仅在理论上具有创新性,而且在多个真实世界数据集上展示了其优越的性能,证明了其作为一种有效无监督学习方法的潜力。 |
| Methods: |
|
| Keyresults: |
|
| Code: | 有 |

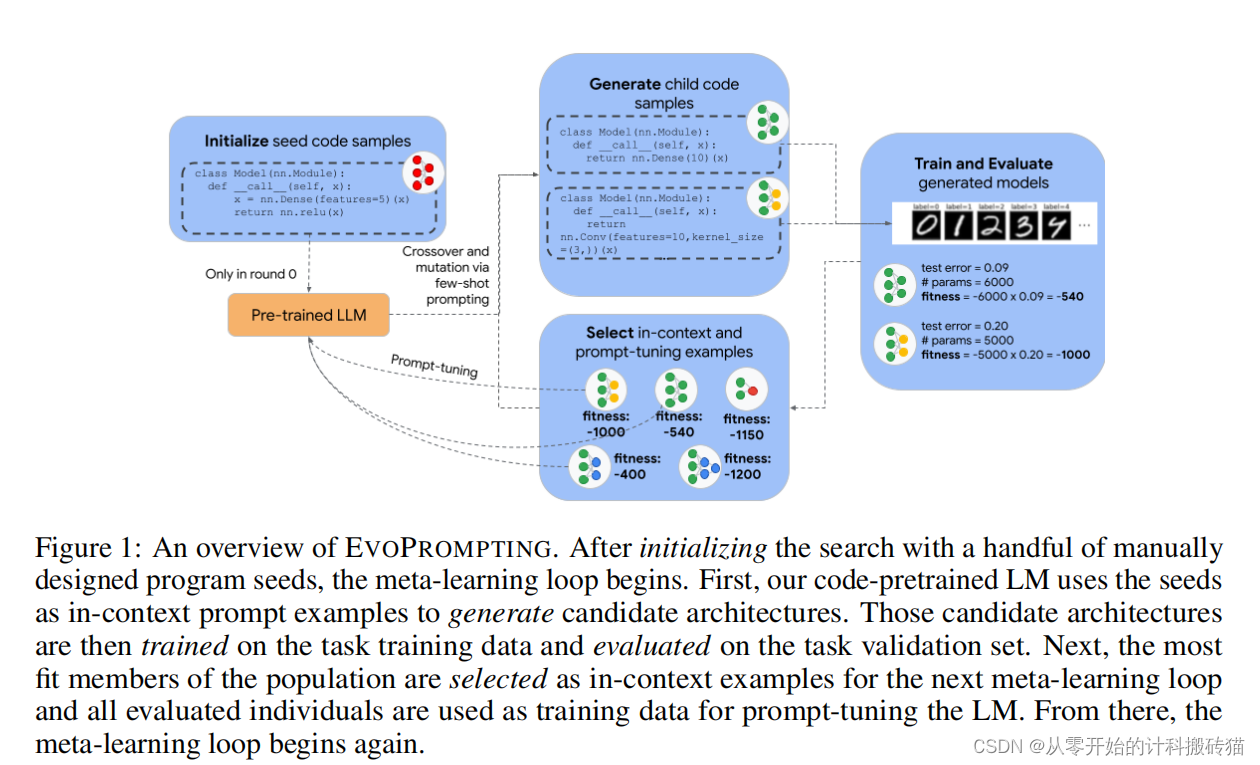
12. EvoPrompting: Language Models for Code-Level Neural Architecture Search (NIPS)
| Aim: | 本论文的目的是探索使用语言模型(LMs)作为进化神经架构搜索(NAS)算法的通用自适应变异和交叉操作符。尽管NAS仍然是一个对LMs来说过于困难的任务,无法仅通过提示就成功,但研究发现,将进化提示工程与软提示调整(我们称之为EVOPROMPTING)结合起来,可以一致地找到多样化且高性能的模型。 |
| Abstract: | 最近语言模型(LMs)在代码生成方面取得的令人印象深刻的成就,我们探索了使用LMs作为进化神经架构搜索(NAS)算法的一般自适应突变和交叉操作符。虽然NAS仍然被证明是仅仅通过提示来成功的任务,我们发现进化提示工程与软提示相结合,一种我们称为唤起的方法,始终找到多样化和高性能的模型。我们首先证明了诱发提示在计算效率高的MNIST-1D数据集上是有效的,在该数据集上,诱发提示产生的卷积结构变体,在准确性和模型大小方面优于人类专家设计和幼稚的少镜头提示。然后,我们将我们的方法应用于在CLRS算法推理基准上搜索图神经网络,其中唤起提示能够设计出新的架构,在30个算法推理任务中的21个上优于当前最先进的模型,同时保持相似的模型大小。诱发提示在在各种机器学习任务中设计准确和高效的神经网络结构方面是成功的,同时也足够通用,易于适应神经网络设计之外的其他任务。 |
| Conclusion: | EVOPROMPTING在设计准确且高效的神经网络架构方面取得了成功,这些架构适用于多种机器学习任务。同时,EVOPROMPTING具有足够的通用性,可以轻松适应神经网络设计之外的其他任务。这一方法展现了语言模型在神经架构搜索中的潜在应用价值,并为将来在更广泛的机器学习领域中应用这种技术提供了可能性。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
None
|
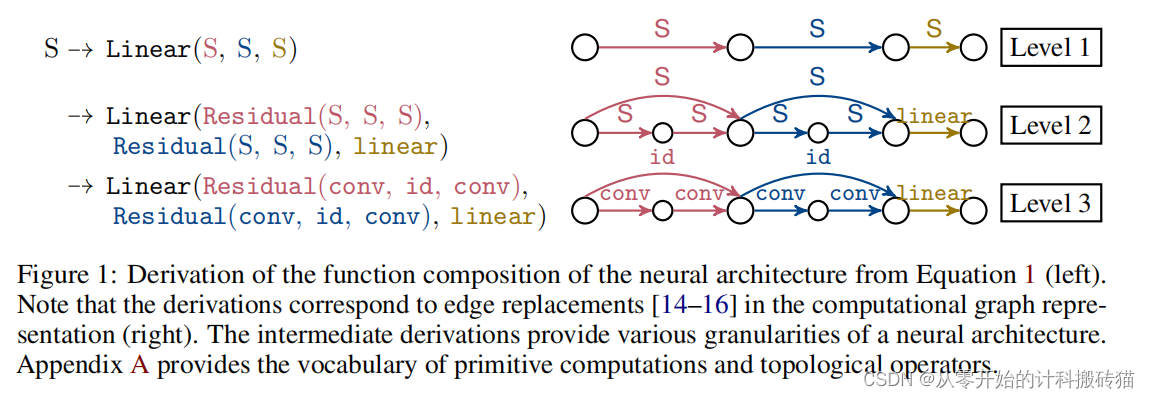
13. Construction of Hierarchical Neural Architecture Search Spaces based on Context-free Grammars (NIPS)
| Aim: | 本论文的主要目标是通过神经架构搜索(NAS)从简单的构建块中发现神经架构。特别地,研究聚焦于提出一个统一的搜索空间设计框架,该框架旨在克服现有分层搜索空间的局限性,这些搜索空间通常只能搜索架构的某些有限方面。 |
| Abstract: | 本研究通过引入一个基于上下文无关语法的统一搜索空间设计框架,有效地扩展了NAS的可能性,能够生成比传统方法更大、更具表达性的分层搜索空间。此外,提出的贝叶斯优化搜索策略的高效分层内核设计使得在这些庞大空间中的搜索成为可能。这些创新不仅显示了该框架在设计搜索空间方面的多功能性,而且还证明了其搜索策略在性能上优于现有的NAS方法,为NAS的未来发展提供了新的方向。 |
| Conclusion: | 本研究通过引入一个基于上下文无关语法的统一搜索空间设计框架,有效地扩展了NAS的可能性,能够生成比传统方法更大、更具表达性的分层搜索空间。此外,提出的贝叶斯优化搜索策略的高效分层内核设计使得在这些庞大空间中的搜索成为可能。这些创新不仅显示了该框架在设计搜索空间方面的多功能性,而且还证明了其搜索策略在性能上优于现有的NAS方法,为NAS的未来发展提供了新的方向。本研究通过引入一个基于上下文无关语法的统一搜索空间设计框架,有效地扩展了NAS的可能性,能够生成比传统方法更大、更具表达性的分层搜索空间。此外,提出的贝叶斯优化搜索策略的高效分层内核设计使得在这些庞大空间中的搜索成为可能。这些创新不仅显示了该框架在设计搜索空间方面的多功能性,而且还证明了其搜索策略在性能上优于现有的NAS方法,为NAS的未来发展提供了新的方向。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/automl/hierarchical_nas_construction.
|
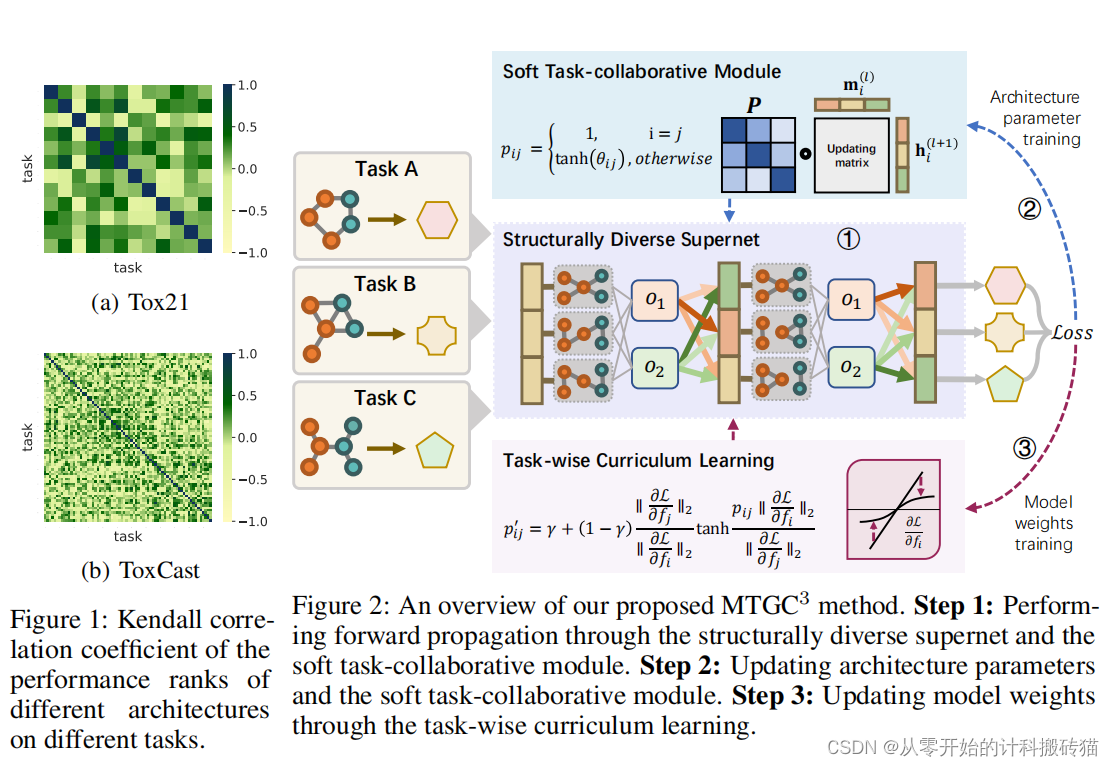
14. Multi-task Graph Neural Architecture Search with Task-aware Collaboration and Curriculum (NIPS)
| Aim: | 本论文旨在探索多任务图神经架构搜索(GraphNAS),这是一个能够同时处理多个任务并捕捉它们之间复杂关系和依赖的方法。尽管GraphNAS在自动设计图神经架构方面展现了巨大潜力,但目前文献中对能够处理多任务并学习任务间协作关系的GraphNAS研究还相对较少。论文提出的多任务图神经架构搜索模型(MTGC3)旨在同时发现不同任务的最优架构,并以联合方式学习不同任务之间的协作关系。 |
| Abstract: | 图神经结构搜索(GraphNAS)在自动设计与图相关任务的图神经结构方面显示出了巨大的潜力。然而,多任务GraphNAS能够同时处理多个任务并捕获它们之间的复杂关系和依赖关系,这在文献中尚未得到很大程度的探索。为了解决这一问题,我们提出了一种新的基于任务感知协同和课程的多任务图神经架构搜索(MTGC3),它能够同时发现不同任务的最优架构,并以联合的方式学习不同任务之间的协作关系. 具体来说,我们设计了结构多样的超网,在一个统一的框架中管理多个架构和图结构,并与我们提出的软任务协作模块相结合,学习任务之间的可转移性关系。为了进一步改进架构搜索过程,我们开发了任务级课程训练策略,根据不同任务的相对困难来重新权衡不同任务的影响。大量的实验表明,我们提出的MTGC3模型在多任务场景中在多个基线上达到了最先进的性能,证明了它发现有效的架构和捕获多个任务的协作关系的能力。 |
| Conclusion: | MTGC3模型成功地解决了多任务图神经架构搜索的问题,通过结合统一的超网络框架、软任务协作模块以及任务导向的课程训练策略,有效地发现了不同任务的最优架构,并学习了任务间的协作关系。这些成果不仅展示了MTGC3在发现有效架构方面的能力,也显示了其在多任务场景中捕捉协作关系的潜力,为未来的多任务GraphNAS研究提供了新的方向和见解。 |
| Methods: |
|
| Keyresults: |
|
| Code: | None |
15. Evolutionary Neural Architecture Search for Transformer in Knowledge Tracing (NIPS)
| Aim: | 本论文旨在解决知识追踪(KT)任务中Transformer模型的局限性,特别是在处理学生遗忘行为时对远距离记录的单一全局上下文建模的不足。论文的目标是通过增强局部上下文建模能力和自动化输入特征选择,来平衡局部/全局上下文建模,并更有效地捕捉学生的遗忘行为。 |
| Abstract: | ransformer在知识追踪(KT)任务中取得了出色的表现,但它们因手动选择用于融合的输入特征和单一全局上下文建模的缺陷而受到批评,这在直接捕捉学生的遗忘行为时存在问题,尤其是当相关记录与当前记录在时间上相距较远时。为解决这些问题,本文首先考虑在Transformer中添加卷积操作,以增强其局部上下文建模能力,用于捕捉学生的遗忘行为。接着,提出一种进化神经架构搜索方法,以自动化输入特征选择,并自动确定在何处应用哪种操作,以实现局部/全局上下文建模的平衡。在搜索空间设计中,原始包含Transformer中注意力模块的全局路径被替换为全局路径和可能包含不同卷积的局部路径之和,同时也考虑了输入特征的选择。为了找到最佳架构,我们采用了一种有效的进化算法来探索搜索空间,并提出了一种搜索空间缩减策略,以加速算法的收敛。在两个最大且最具挑战性的教育数据集上的实验结果证明了所提方法找到的架构的有效性。 |
| Conclusion: | 本研究提出的方法通过在Transformer中引入卷积操作和进化神经架构搜索,有效地平衡了局部和全局上下文建模,更好地捕捉学生的遗忘行为。实验结果证明了该方法在知识追踪任务上的有效性,表明了其在自动化架构设计和提升模型性能方面的潜力。这一方法为改进Transformer在知识追踪等序列建模任务中的应用提供了新的思路和技术支持。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
None
|
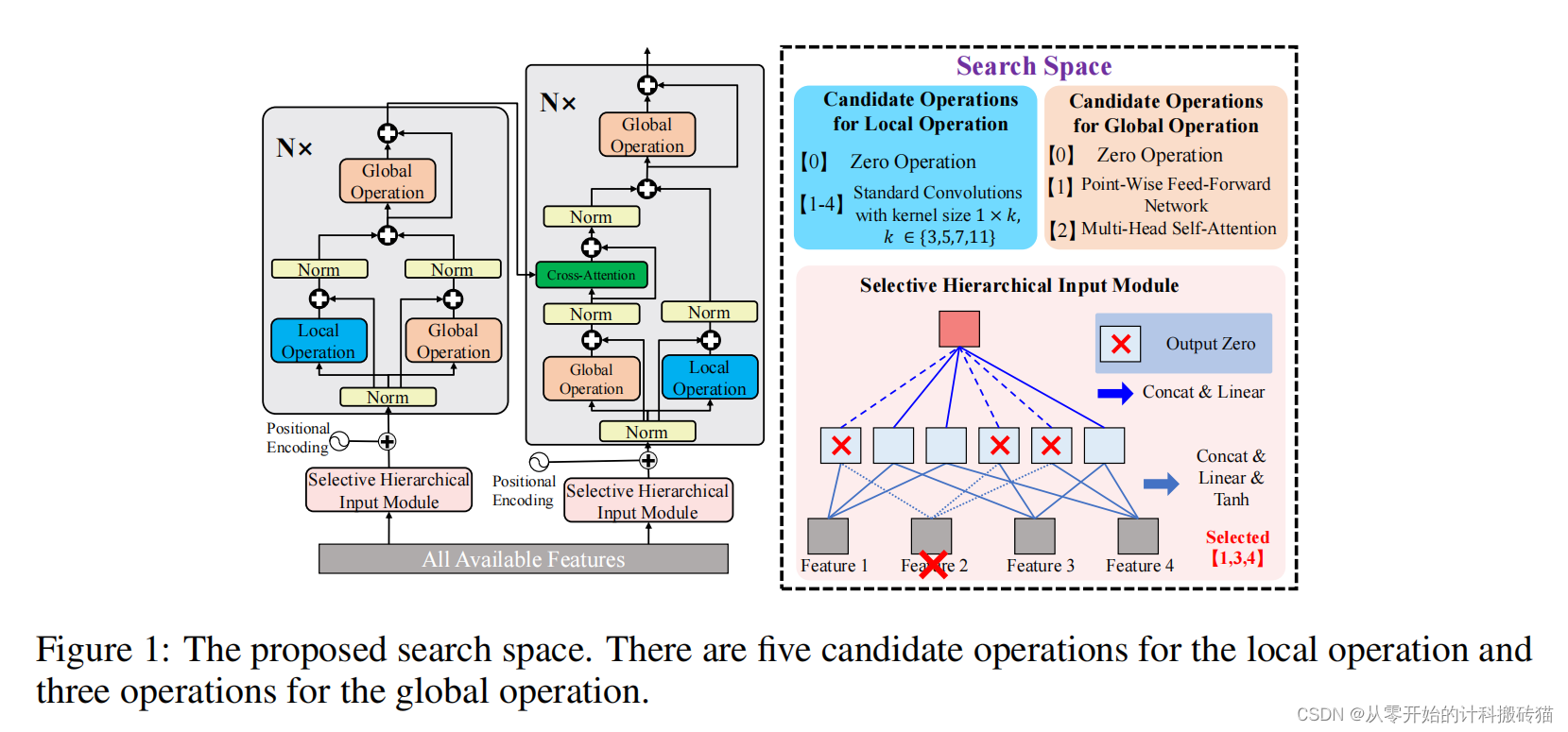
16.GeNAS: Neural Architecture Search with Better Generalization (IJCAI)
| Aim: | 本文旨在探索一种新的神经架构搜索(NAS)度量方法,用于挖掘具有更好泛化能力的网络架构。尽管最近的NAS方法依赖于验证损失或准确度来找到目标数据的优越网络,这项研究着重于评估网络架构的泛化能力。 |
| Abstract: | 本研究证明了损失平面的平坦度可以作为评估神经网络架构泛化能力的有希望的指标。所提出的方法不仅在传统的NAS评估标准上表现出色,而且在数据分布的不同变化和多种任务中显示出极佳的泛化能力。这项研究为评估和挖掘具有优秀泛化能力的网络架构提供了新的视角和工具。 |
| Conclusion: | 本研究证明了损失平面的平坦度可以作为评估神经网络架构泛化能力的有希望的指标。所提出的方法不仅在传统的NAS评估标准上表现出色,而且在数据分布的不同变化和多种任务中显示出极佳的泛化能力。这项研究为评估和挖掘具有优秀泛化能力的网络架构提供了新的视角和工具。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
https://github.com/clovaai/GeNAS
.
|

17. LISSNAS: Locality-based Iterative Search Space Shrinkage for Neural Architecture Search(IJCAI)
| Aim: | 本论文的目的是解决神经架构搜索(NAS)中大型和复杂搜索空间的挑战。虽然这些搜索空间提供了更多发掘有前景架构的机会,但它们对有效探索和利用提出了严峻挑战。论文提出了LISSNAS,一种自动算法,旨在将大型搜索空间缩减为小型但多样化、具有最先进搜索性能的搜索空间。 |
| Abstract: | 搜索空间标志着神经结构搜索(NAS)的进步。大型和复杂的搜索空间具有多功能的建筑运营商和结构,为开发有前途的建筑提供了更多的机会,但却对有效的探索和开发带来了严峻的挑战。随后,几种搜索空间收缩方法通过选择一个包含一些性能良好的网络的单个子区域来进行优化。使用这些方法可以观察到较小的性能和效率的提高,但这些技术为显著提高搜索性能留下了空间,并且在保留架构多样性方面无效。我们提出了一种自动算法,将大空间缩小到一个多样化的、小的搜索空间,具有SOTA搜索性能。我们的方法利用了局部性,即结构相似性和性能相似性之间的关系,来有效地提取出许多性能良好的网络。我们在一个跨越不同大小和数据集的搜索空间数组上展示了我们的方法。我们通过在两个不同的搜索空间中获得最佳的Top-1精度,强调了缩小空间的有效性。我们的方法在移动约束、箱子级肯德尔-tau、架构多样性和搜索空间大小下,在ImageNet中实现了77.6%的SOTA Top-1精度。 |
| Conclusion: | LISSNAS方法有效地将大型NAS搜索空间转化为小型但多样化的搜索空间,同时保持了最先进的搜索性能。通过利用结构和性能的局部性关系,该方法能够高效地发掘表现良好的网络群体。实验结果表明,该方法在不同的搜索空间和数据集上均表现出色,特别是在Top-1准确率、架构多样性和搜索空间大小方面,展现了其优越性和实用性。这一研究为NAS领域提供了一种新的高效搜索空间缩减方法。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
None
|

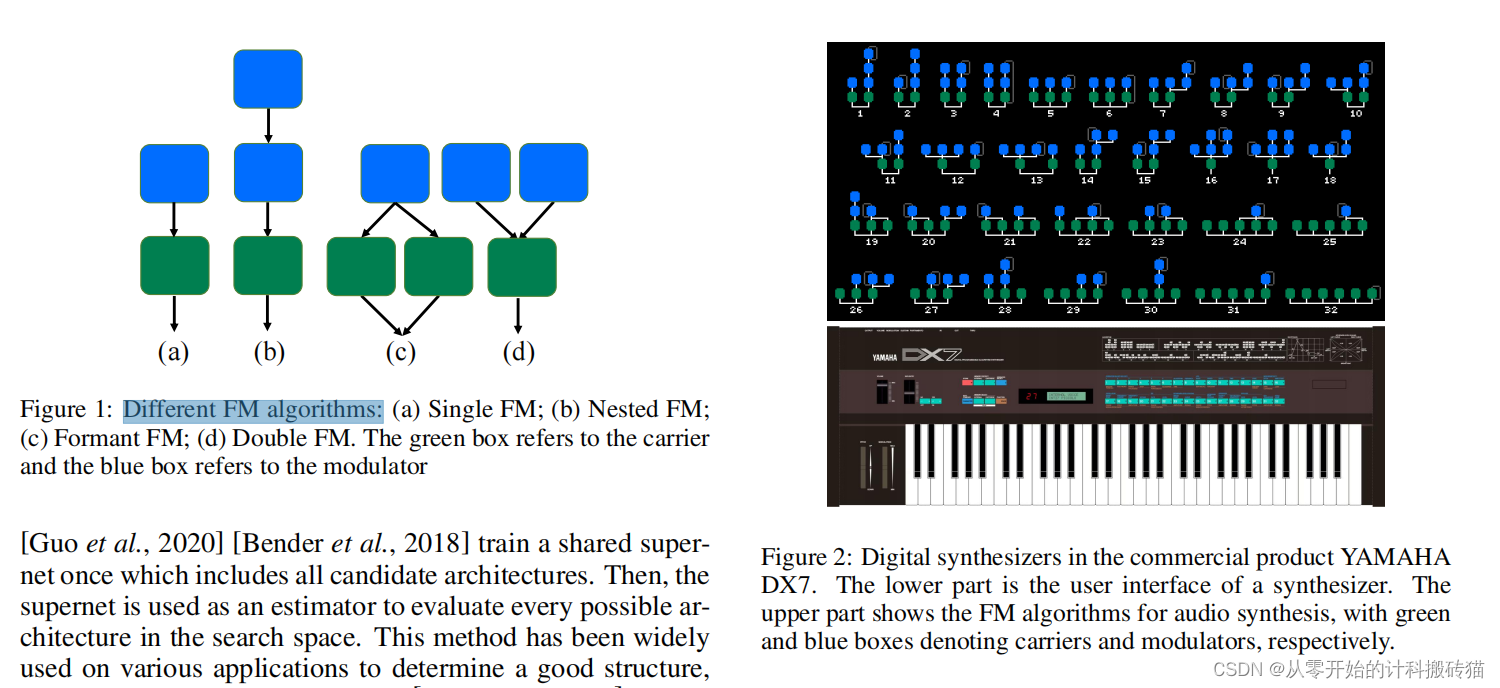
18. NAS-FM: Neural Architecture Search for Tunable and Interpretable Sound Synthesis Based on Frequency Modulation (IJCAI)
| Aim: | 本文旨在解决数字声音合成器开发中的挑战,特别是在没有专家知识和手动操作成本的情况下,快速设计和调整适用于多样化声音的合成器。为此,提出了“NAS-FM”,一种采用神经架构搜索(NAS)来构建可微分频率调制(FM)合成器的方法。 |
| Abstract: | 开发数字声音合成器对音乐产业至关重要,因为它提供了一种低成本的方式来产生丰富的音质和高质量的声音。现有的传统合成器通常需要大量的专业知识来确定合成器的总体框架和子模块的参数。由于专家知识很难获得,它阻碍了快速设计和调谐数字合成器的可行性。在本文中,我们提出了“NAS-FM”,它采用神经结构搜索(NAS)来构建一个可微调频(FM)合成器。具有可解释控制的可调合成器可以从声音自动开发,无需任何事先的专家知识和手动操作成本。详细地说,我们用一个专门设计的搜索空间来训练一个超级网络,包括预测具有不同频率比的载波子和调制器的包络线。然后提出了一种具有自适应振子大小的进化搜索算法,以确定振子与调频频率比之间的最优关系。对不同仪器声音录音的大量实验表明,我们的算法可以完全自动地构建一个合成器,取得比手工合成器更好的效果。 |
| Conclusion: | NAS-FM”提供了一种创新的方法,用于自动开发具有可解释控制的可调合成器,而无需任何先验专家知识和手动操作成本。通过特定设计的搜索空间和进化搜索算法,能够从声音中自动发展出合成器,有效地解决了快速设计和调整多样化声音合成器的挑战。这一方法为数字声音合成器的发展提供了新的技术路径,特别是在音乐产业中具有重要应用潜力。 |
| Methods: |
|
| Keyresults: |
|
| Code: |
Audio samples are
available at https://nas-fm.github.io/.
|