
- 1LINUX :标准c库_linux c标准库
- 22024年Palworld/幻兽帕鲁服务器搭建教程,1分钟一键部署成功
- 3基于大数据的智能家居销量数据分析
- 4使用pytorch搭建一个卷积神经网络_torch构建卷积网络代码
- 5nrf52832串口复用问题_52832有几个串口通信
- 6原生蓝牙连接关键类记录_bluetoothpairingcontroller
- 7(附源码)python+mysql+基于协同过滤算法的书籍推荐 毕业设计101555_【项目实战】基于python+django+mysql+协同过滤算法的图书推荐系统项目实战教
- 8vs2008中,调试minidump的设置(转)_minidump 调试要pdb吗
- 9Centos7 设置系统时间_failed to set ntp: cannot send after transport end
- 10Java中常见的服务器
2020美赛C题建模复盘(Ⅰ)—建模思路与资料整理_美赛微波炉,奶嘴,吹风机
赞
踩
引言
2020美赛建模结束了,笔者所带的队伍选做了问题C(“给差评题”),建模当中有许多做的不足的地方,希望通过复盘将当时的遗留问题解决,于是希望写出系列文章,聊做整理。
建模内容(翻译版)
数据财富
在亚马逊创建的在线市场中,亚马逊为客户提供了一个对购买进行评级和评估的机会。个人评级-称为“星级评级”-允许购买者使用1(低评级,低满意度)到5(高评级,高满意度)的等级来表达他们对产品的满意度。此外,客户还可以提交基于文本的消息(称为“评论”),以表达对产品的进一步意见和信息。其他客户可以在这些评论上提交有帮助或没有帮助的评级(称为“帮助性评级”),以帮助他们自己的产品购买决策。公司使用这些数据来深入了解他们参与的市场、参与的时机以及产品设计功能选择的潜在成功。
阳光公司计划在网上市场推出并销售三种新产品:微波炉a microwave oven、婴儿奶嘴a baby pacifier和吹风机a hair dryer。他们已聘请您的团队作为顾问,以确定过去客户提供的与其他竞争产品相关的评级和评论中的关键模式、关系、衡量标准和参数,以告知他们的在线销售战略,确定潜在的重要设计功能,以增强产品的可取性。Sunshine公司过去曾使用数据来指导销售策略,但他们以前从未使用过这种特殊的组合和类型的数据。阳光公司特别感兴趣的是这些数据中基于时间的模式,以及它们是否以有助于公司打造成功产品的方式进行交互。
为了帮助您,Sunshine的数据中心为您提供了三个用于此项目的数据文件:hair_drewer.tsv、microwave.tsv和pacifier.tsv。这些数据代表了亚马逊市场上销售的微波炉、婴儿奶嘴和吹风机在数据所示时间段内的客户提供的评级和评价。还提供了数据标签定义的词汇表。提供的数据文件只包含您应该用于此问题的数据。
要求:
1、 分析所提供的三个产品数据集,以识别、描述和支持数学证据、有意义的定量和/或定性模式、关系、衡量标准和星级评定、评审之间的参数,以及帮助性评级,这将有助于阳光公司在他们的三个新的在线市场产品提供成功。
2、 利用你的分析来解决阳光公司市场总监提出的以下具体问题和要求
a. 一旦阳光公司的三款产品在网络市场上销售,根据对其信息量最大的评级和评论确定数据衡量标准。
b. 识别并讨论每个数据集中基于时间的度量和模式,这些度量和模式可能表明产品在在线市场上的声誉在增加或减少。
c. 确定基于文本的度量值和基于评级的度量值的组合,这些度量值最好地指示潜在的成功或失败产品。
d. 特定的明星收视率会引发更多的评论吗?例如,客户在看到一系列低星级评级后,是否更有可能撰写某种类型的评论?
e. 基于文本的评论的特定质量描述,如“热情”、“失望”和其他,是否与评级水平密切相关?
3、写一封一到两页的信给阳光公司的市场总监,总结你的团队的分析和结果。包括你的团队最自信地向市场总监推荐的结果的具体理由。
你的意见应包括:
一页摘要表
目录
一到两页的信件
你的解决方案不超过20页,最多24页的摘要表、目录和两页的信件。
注意:参考列表和任何附录不计入页面限制,应在完成解决方案后显示。您不应使用未经授权的图片和材料,其使用受到版权法的限制。确保你引用了你的观点的来源和你报告中使用的材料。
术语:
帮助度评分:在决定是否购买某一产品时,对某一特定产品的评价有多大价值的指标。
奶嘴Pacifier::一种橡胶或塑料的抚慰装置,通常是乳头状的,给婴儿吮吸或咬。
评论:对产品的书面评价。
星级评定:在一个允许人们对一个产品进行星级评定的系统中给出的分数。
附件:问题数据集(数据内容与后续的参考资料、代码等读者可移步到笔者的资源中进行下载)
建模思路
拎出数据字段观察分析
| 字段名 | 脑风解析 |
|---|---|
| marketplace | 市场所在地(皆为US) |
| customer_id | 顾客_ID |
| review_id | 评论_ID(该数据集主键) |
| product_id | 产品_ID |
| product_title | 产品名称 |
| product_parent | 生产商 |
| product_category | 产品类别(三种) |
| star_rating | 评论给星 |
| helpful_votes | 评论有效投票(反映评论的影响力) |
| total_votes | 评论总投票 |
| vine | 是否加入vine计划(类似一种打折促销,笔者认为加入vine的评论影响力要更大) |
| verified_purchase | 是否有效(原价)购买 |
| review_headline | 评论的文字标题 |
| review_body | 评论的文字内容 |
| review_date | 评论日期 |
数据预处理
1、数据集的处理
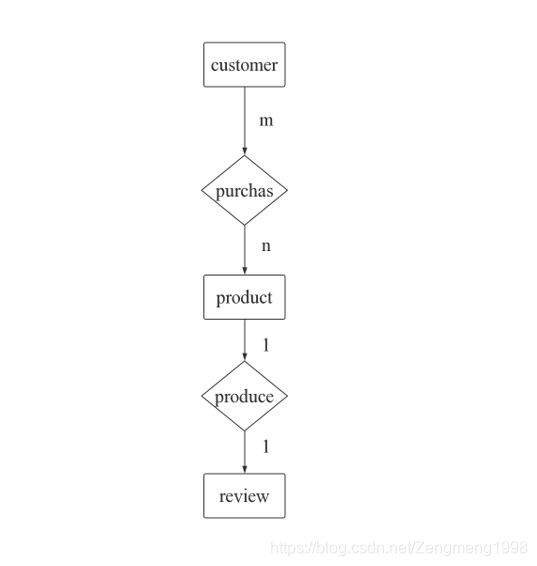
首先需要利用SQL或python等工具对数据做一个简单处理,将消费者与商品作为主体单拎出来作为主体。便于后期的数据分析,与可能需要进行用户或商品的分类。思想如下E-R结构图所示。同时删除无效的乱码、错位的文件。
2、文本数据处理
对于评论的文字内容,粗略看后,笔者表示很无奈,真是林子大了啥鸟都有,有的评论用表情(可能是造成乱码的原因);有的用特殊的符号与数值(怕不是懂密码学)。总而言之相当真实的评论数据,如果想要将这些文本数据用于数值可视化,不做处理是不行的。
这里笔者的思路为:;利用python的第三方自然语言处理库NLTK对文本进行处理,主要处理的内容为:
对评论进行分句、分词、将单词原形化、去除停用词。使得最后的评论只剩些简单有价值的评论词汇。
建模
文本挖掘
首先笔者是对评论文字做一个情感数值的打分使得评论情感数值化,这也是前期处理文本的原因。
如何进行情感赋分?笔者参考资料得到的主要方法:
1、建立一个情感词典,对评论中情感词进行匹配,在利用自行定义情感赋分公式算出该条评论的情感得分。
2、利用BP神经网络对评论进行情感分类进而完成打分。
相关性分析
对评论的文本数据数值化后,就可以进行相关变量间的相关性分析了,发现变量间是否具有一定的相关性。
函数拟合
对于怎样拟合出评价打星与评论情感得分与信誉度等几个变量的关系笔者觉得:
1、使用最简单的最小二乘拟合;
2、利用神经网络算法进行拟合;
最后根据拟合的结果为SUN做出一个合理的营销策略与给出一些合理的建议。

