
- 1无法连接到安全检查代理服务器 本地ip地址非法_无法连接到安全检查代理服务器,本地ip地址非法
- 2Qt的信号槽机制
- 3什么是人工智能、机器学习和深度学习,三者之间又有什么差异?_硬编码脚本和人工智能的区别
- 4Javaee学习笔记(一)_javaee是中间件吗
- 5如何生成git密钥私钥SSH key_git private key file: passphrase
- 6基于Java+SpringBoot+Vue的在线教育系统的设计与开发(源码+lw+部署文档+讲解等)_开源在线教育系统多语言
- 7[译] Swift 5 强制独占性原则
- 8【Java书笔记】:《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》第2部分-自动内存管理,第3部分-虚拟机执行子系统,第5部分-高效并发_java本机序列化允许由有效负载利用易受攻击的库和类执行未经验证的字节码引起的远
- 909 OpenCV图像的形态学运算
- 10R语言七天入门教程三:学习基本结构_r 教程
人工智能------>第一天,人工智能简介,机器学习简介,Numpy_人工智能三起两落,两落的原因是什么?
赞
踩
人工智能简介
人工智能就是由计算机来表示和执行人类的智能活动。——《人工智能的研究目标》
人工智能(AI, Artificial Intelligence)
->相关学课
->数学
->计算机
->统计学
->脑神经科学
->神经网络学
->遗传学
->信息论
->控制论
->仿生学
...
->学习的对象
->数学
->统计学
->计算机
->算法
->人工智能的发展:
三次高潮两次低谷:
第一次高潮:1947-1959
产生的原因:计算机的诞生
标志:
图灵测试
AI概念的提出
特点:
1.简单的专家系统
2.定理的证明
第一次低谷:1960-1979
走向低谷的原因:
机器翻译的失败
该阶段计算机技术发展:
1.操作系统的诞生
2.数据库技术的诞生
3.计算机网络的诞生
4.PC机的产生
第二次高潮:1980-1995
产生的原因:计算机网络的诞生
标志:
BP神经网络的出现
专家系统的出现(例如搜索引擎)
Web技术的出现(万维网的出现)
Deep Bule主机上运行的一款国际象棋游戏(可以PK掉美国一个州的州冠军)
特点:
1.专家系统无法自主学习
2.无法处理非结构化数据(非关系型数据)
3.计算机的CPU处理速度达到了瓶颈,无法支持神经网络的实现
第二次低谷:1995-2006
原因见第二次高潮的特点
该阶段技术发展:
1.非关系型数据库的诞生
2.多媒体文件编码的发展
3.多核CPU的诞生
第三次高潮:2006 -
产生的原因:
1.CPU集成度限制打破了
2.非结构化的存储技术成熟
标志:
1.辛顿提出深度学习
2.辛顿的学生在ImageNet大赛上通过卷积神经网络让计算机识别猫
3.2015-2017三代Alpha Go
4.人脸识别技术的商业化
5.语音助手,自动翻译、推荐系统等的出现
->人工智能发展前景
->新技术出现疲软
->投资不在狂热化,陷入内卷
->AI+物联网(智能制造2025)
->目前研究的主流:
无人驾驶
天气预测
航空航天
基因研究
新能源研究
智能制造(AI+物联网)
->影响人工智能发展的因素
->大数据
->基础平台+算法
->计算力
->人工智能的知识体系结构
行业应用(农业应用、工业应用、服务员业、家居行业)
产品 应用 平台
无人驾驶的拖拉机 美团 京东AI平台
刷脸的门禁 抖音 科大讯飞的AI平台
语音助手 百度AI平台
同声传译设备 小米AI平台
基础应用技术
语音处理 图像处理 自然语言分析 ...
语音识别 图像分类 翻译
语音合成 图像识别 写文章
图像高级处理
AI软件框架
训练的框架 推断的框架
学习的过程 使用的过程
TensorFLow TensorFLow Lite
PaddlePaddle Paddle Mobile
Caffe Tensor RT
Pytorch CoreML
AI编译器
LLVM
AI芯片(将AI中的基本运算集成在CPU中)
大型机器使用 移动端使用
CPU ASIC(消费类移动端cpu设计)
GPU FPGA
->人工智能中常见名词以及之间的关系
人工智能
机器学习
深度学习
机器学习
什么是机器学习:
是一门人工智能的学课,研究对象是如何自动提高算法效率(自动算法优化)
是通过以往的数据/经验来提高算法性能
机器学习的流程
机器学习本身是一个求最优解的问题,即求最优模型的问题。
通过反复使用不同算法进行训练,比较不同算法得出的模型的准确率,找出最优模型的过程。
机器学习的流程大致分为两个部分
训练
测试
由于这两个过程都需要数据,所有需要测试数据和训练数据
测试集:测试模型的数据
训练集:训练模型的数据
数据集:测试集+训练集+其他数据
流程:
1.提出问题,并分析是否适合机器学习
2.收集数据集(收集哪些数据)
3.数据的转换,采样
4.数据的拆分
5.使用某种算法对训练集进行训练
6.得到训练结果(模型)
7.使用测试集对模型进行测试,得到误差
8.设计误差函数(损失函数)
9.如果误差太大,重新设计(前面步骤,重新训练),即迭代上述过程
10.当模型的损失率在自己设计范围内时,结束迭代过程,得到目前最优模型
11.使用模型(分类,预测,对抗)
机器学习的研究主要分为两类研究方向:
第一类是传统机器学习的研究。
该类研究主要是研究学习机制,注重探索模拟人的学习机制;

第二类是大数据环境下机器学习的研究。
该类研究主要是研究如何有效利用信息,注重从巨量数据中获取隐藏的、有效的、可理解的知识。
机器学习的分类:
基于学习方式的分类:
监督学习:
数据集带标签
无监督学习:
数据集不带标签
强化学习:
有奖惩机制
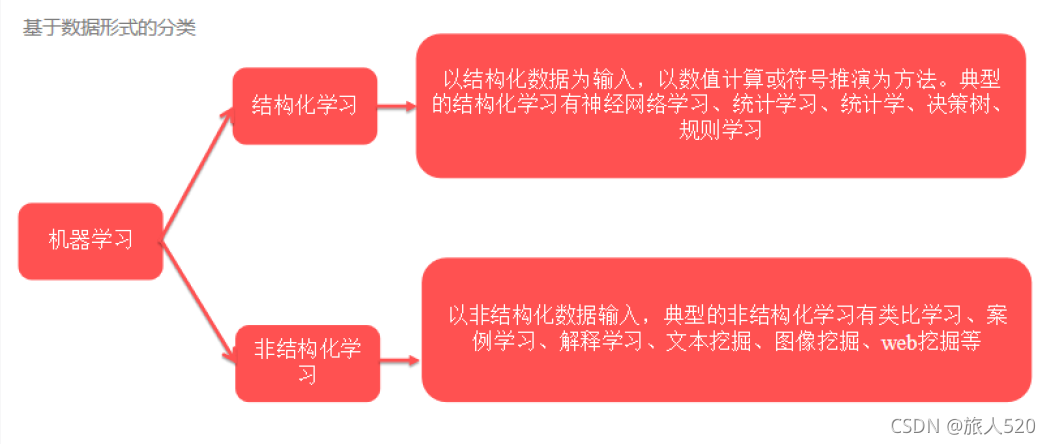
基于数据形式的分类:
结构化学习:
数据集是结构化数据(使用关系型数据库能够存储的数据)
非结构化学习
数据集是非结构化数据(音频、视频、图片等)
Numpy
Numpy是一个张量运算库
安装:
pip install numpy -i https://mirrors.aliyun.com/pypi/simple/
-i后面跟的是软件源:
豆瓣 :https://pypi.douban.com/simple/
阿里 :https://mirrors.aliyun.com/pypi/simple/
中国科学技术大学:https://pypi.mirrors.ustc.edu.cn/simple
清华:https://pypi.tuna.tsinghua.edu.cn/simple
NumPy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅里叶变换、基本线性代数,基本统计运算和随机模拟等等。
NumPy包的核心是ndarray对象。它封装了python原生的同数据类型的n维数组,为了保证其性能优良,其中有许多操作都是代码在本地进行编译后执行的。
NumPy数组和原生Python Array(之间)有什么重要的区别:
>NumPy数组在创建时具有固定的大小,与Python的原生数组对象(可以动态增长)不同。更改ndarry的大小将创建一个新数组,并删除原来的数组。(这里的python数组代指list)
>NumPy数组中的元素都需要具有相同的数据类型,因此在内存中的大小相同。例外情况:Python的原生数组里包含了NumPy的对象的时候,这种情况下就允许不同大小元素的数组。
>NumPy数组有助于对大量数据进行高级数学和其他类型的操作。通常,这些操作的执行效率更高,比使用Python原生数组的代码更少。
>越来越多基于Python的科学和数学软件包使用NumPy数组;虽然这些工具通常支持Python的原生数组作为参数,但它们在处理之前还时会将输入的数组转换为NumPy的数组,而且也通常输出为NumPy数组。换句话说,为了高效地使用当今科学/数学基于Python的工具(大部分的科学计算工具),你只知道如何使用Python的原生数组类型是不够的,还需要知道如何使用NumPy数组。
张量(Tensor)概念是矢量概念的推广
例如要将一维数组的每一个元素与相同长度的另一个序列中的相应元素相乘:
python的代码如下:
- c = []
- for i in range(len(a)):
- c.append(a[i]*b[i])
当a和b每一个都包含数以万计的数字,我们的效率会非常低下
使用C语言的代码:(忽略变量定义、初始化)
- for(i = 0; i < rows; i++)
- {
- c[i] = a[i] * b[i];
- }
如果是二维数组:
- for(i = 0; i < rows; i++)
- {
- for(j = 0; j < columns; j++)
- {
- c[i][j] = a[i][j] * b[i][j];
- }
- }
Numpy为我们提供了一个两全其美的办法,当涉及到ndarray时,逐个元素的操作是"默认式",但逐个元素的操作由预编译的C代码快速执行。在NumPy中:
c = a * bNumPy的语法更为简单,最后一个例子说明了NumPy的两个特征,它们是NumPy的大部分功能的基础:矢量化和广播(遍历)
NumPy的优点:
>矢量化代码更简洁,更易于阅读
>更少的代码行通常意味着更少的错误
>代码更接近于标准的数学符号(通常,更容易正确编码数学结构)
>矢量化导致产生更多"Pythonic"代码,如果没有矢量化,我们的代码就会被低效率且难以阅读的for循环所困扰。
>默认逐元素操作就是所谓的广播操作->Numpy的使用
1.构造numpy数组
- import numpy as np
-
- #使用array方法,构造一个ndarray的实例
- a = np.array([4,5,6,7,8])
- print(a)
- print(type(a))
-
- print(a*2)
-
- #当前张量数组的元素个数
- print(a.size)
- #张量数组的轴(数组的维度)
- print(a.ndim)
- #张量数组的形状
- print(a.shape)
- #张量数组元素所占字节数
- print(a.itemsize)
- #张量数字元素类型名
- print(a.dtype.name)
- #存储元素的内存首地址
- print(a.data)
-
- print(a[:2])

2.构造numpy数组
- import numpy as np
-
- mylist = [
- [
- [1,2,3],
- [4,5,6]
- ],
- [
- [7,8,9],
- [10,11,12]
- ],
- [
- [13,14,15],
- [16,17,18]
- ],
- ]
-
- b = np.array(mylist)
-
- #print(b)
- print(b.ndim)
- print(b.shape)
- print(b.size)
-
- s = b.shape
- for i in range(0,s[0]):
- for j in range(0,s[1]):
- for k in range(0,s[2]):
- print(b[i][j][k],end=" ")
- print("",end=",")
- print("")
ndim:数组的维度,也叫轴
shape:数组的形状,shape的元素个数就是ndim
size:数组的元素个数,即shape所有元素的乘积
依然可以截取
访问成员可以使用[下标]
函数zeros创建一个由0组成的数组
函数ones创建一个完整的数组
函数empty创建一个数组,其初始内容是随机的,取决于内存的状态
函数random.random创建一个数组,其初始内容是随机的,取决于random
默认情况下,创建的数组的dtype是float64类型的
arange
random.normal:产生一个正太分布的值
- import numpy as np
-
- '''
- zero:按照指定的shape创建数组,默认填0,且元素类型默认为float64
- '''
- a = np.zeros((3,3))
- print(a)
-
- print(a.dtype.name)
-
-
- '''
- 可以通过dtype指定元素类型
- '''
- b = np.zeros((2,4), dtype=np.int)
- print(b,b.dtype.name)
-
- '''
- 初始化为1
- '''
- c = np.ones((3,4))
- print(c)
-
- '''
- 随机值,取决于内存状态
- '''
- d = np.empty((5,))
- print(d)
-
- '''
- random.random产生n个数的随机数(0~1之间),
- 通过reshape方法来更改数组形状
- '''
- e = np.random.random(20).reshape(4,5)
- print(e)
-
- '''
- arange类似于python中的range方法
- '''
- f = np.arange(0,20,2).reshape(2,5)
- print(f,f.size)

