
- 1Android 开机自动加载新wifi模块驱动_手机wifi驱动
- 2『uni-app』实现上拉加载,下拉刷新_uniapp 上拉加载
- 3【嵌入式培训】第一天——用CubeMX与MDK实现点灯操作_mdk cubemx
- 4python qt5自定义无标题栏、窗口拖动、关闭、最小化_pyqt 无标题 拖拽
- 5记录基于Vue.js的移动端Tree树形组件_treeselect组件
- 6Kotlin协程实现原理:CoroutineScope,看完不懂你砍我!墙裂建议收藏。_kotlin coroutinescope
- 7Android开发:Android Studio工具遇到的坑,以及解决办法_error retrieving capabilities from the device
- 8简单工厂模式(Simple Factory)_海信工厂模式菜单详解
- 9关于Android Studio AIDL 无法自动生成Java文件_android studio aidl无法自动生成java
- 10TCP连接的“三次握手”与“4次挥手”_tcp连接中的三次握手和四次挥手
【论文阅读】《Unifying Large Language Models and Knowledge Graphs: A Roadmap》
赞
踩
Unifying Large Language Models and Knowledge Graphs: A Roadmap
• Shirui Pan is with the School of Information and Communication Technology and Institute for Integrated and Intelligent Systems (IIIS), Griffith University, Queensland, Australia. Email: s.pan@griffith.edu.au;
• Linhao Luo and Yufei Wang are with the Department of Data Science and AI, Monash University, Melbourne, Australia. E-mail:linhao.luo@monash.edu, garyyufei@gmail.com.
• Chen Chen is with the Nanyang Technological University, Singapore. E-mail: s190009@ntu.edu.sg.
• Jiapu Wang is with the Faculty of Information Technology, Beijing University of Technology, Beijing, China. E-mail:jpwang@emails.bjut.edu.cn.
• Xindong Wu is with the Key Laboratory of Knowledge Engineering with Big Data (the Ministry of Education of China), Hefei University of
Technology, Hefei, China; He is also affiliated with the Research Center for Knowledge Engineering, Zhejiang Lab, Hangzhou, China. Email:xwu@hfut.edu.cn.
• Shirui Pan and Linhao Luo contributed equally to this work.
• Corresponding Author: Xindong Wu.
• 潘石瑞就职于澳⼤利亚昆⼠兰州格⾥菲斯⼤学信息与通信技术学院和集成与智能系统研究所 (IIIS)。电⼦邮件:s.pan@griffith.edu.au;
• 罗林浩和王玉飞来⾃澳⼤利亚墨尔本莫纳什⼤学数据科学与⼈⼯智能系。电⼦邮箱:lin hao.luo@monash.edu、garyyufei@gmail.com。
• 陈晨来⾃新加坡南洋理⼯⼤学。电⼦邮件:s190009@ntu.edu.sg。
• 王家普在中国北京北京⼯业⼤学信息技术学院⼯作。电⼦邮箱:jpwang@emails.bjut.edu.cn。
•吴新东,合肥⼯业⼤学⼤数据知识⼯程重点实验室(中国教育部),中国合肥;他还⾪属于中国杭州浙江实验室知识⼯程研究中⼼。邮箱:xwu@hfut.edu.cn。
• 潘石瑞和罗林浩对这项⼯作做出了同等贡献。
•通讯作者:吴新东
Abstract—Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and generalizability. However, LLMs are black-box models, which often fall short of capturing and accessing factual knowledge. In contrast, Knowledge Graphs (KGs), Wikipedia and Huapu for example,are structured knowledge models that explicitly store rich factual knowledge. KGs can enhance LLMs by providing external knowledge for inference and interpretability. Meanwhile, KGs are difficult to construct and evolving by nature, which challenges the existing methods in KGs to generate new facts and represent unseen knowledge. Therefore, it is complementary to unify LLMs and KGs together and simultaneously leverage their advantages. In this article, we present a forward-looking roadmap for the unification of LLMs and KGs. Our roadmap consists of three general frameworks, namely, 1) KG-enhanced LLMs, which incorporate KGs during the pre-training and inference phases of LLMs, or for the purpose of enhancing understanding of the knowledge learned by LLMs; 2) LLM-augmented KGs, that leverage LLMs for different KG tasks such as embedding, completion, construction, graph-to-text generation, and question answering; and 3) Synergized LLMs + KGs, in which LLMs and KGs play equal roles and work in a mutually beneficial way to enhance both LLMs and KGs for bidirectional reasoning driven by both data and knowledge. We review and summarize existing efforts within these three frameworks in our roadmap and pinpoint their future research directions.
摘要——大型语言模型(LLM) 如ChaGPT和GPT4,由于其涌现能力和可推广性正在自然语言处理和人工智能领域掀起新的浪潮。然而,LLM是黑匣子模型,通常无法捕捉和获取事实知识。相反,知识图(KGs) ,例如维基百科和华谱是明确存储丰富事实知识的结构化知识模型。KGs可以通过为推理和可解释性提供外部知识来增强LLM。同时KGs在本质上很难构建和进化,这对KGs中现有的生成新事实和表示未知知识的方法提出了挑战。因此,将LLM和KGs统一在一起并同时利用它们的优势是相辅相成的。在本文中,我们提出了LLM和KGs统一的前瞻性路钱图。我们的路线图由三个通用框架姐成,即:1 )KG增强LLM,它在LLM的预训练和推理阶段结合了KG,或者是为了增强对LLM所学知识的理解;2)LLM增强的KG,利用LLM执行不同的KG任务,如嵌入、完成、构建、图到文本生成和问答;以及3)协同LLIA+KGs,其中LLM和KGs扮演着平等的角色,并以互利的方式工作,以增强LLM和KG,实现由数据和知识驱动的双向推理。我们在路线图中回顾和总结了这三个框架内的现有努力,并确定了它们未来的研究方向。
Index Terms—Natural Language Processing, Large Language Models, Generative Pre-Training, Knowledge Graphs, Roadmap,Bidirectional Reasoning.
索引术语——⾃然语⾔处理、⼤型语⾔模型、⽣成预训练、知识图、路线图、双向推理。
1 INTRODUCTION
1 简介
Large language models (LLMs)
1
^1
1(e.g., BERT [1], RoBERTA[2], and T5 [3]), pre-trained on the large-scale corpus,have shown great performance in various natural language processing (NLP) tasks, such as question answering [4],machine translation [5], and text generation [6]. Recently,the dramatically increasing model size further enables the LLMs with the emergent ability [7], paving the road for applying LLMs as Artificial General Intelligence (AGI).Advanced LLMs like ChatGPT
2
^2
2and PaLM2
3
^3
3, with billions of parameters, exhibit great potential in many complex practical tasks, such as education [8], code generation [9] and recommendation [10].
在大规模语料库上进行预训练的大型语模型(LLM)
1
^1
1(例如,BERT[1]、ROBERTA[2]和T5[3])在各种自然语言处理(NLP)任务中表现出了良好的性能,例如问答[4]机器翻译[5]和文本生成[6]。最近,模型大小的急剧增加进一步使LLM具有了涌现能力[7],为LLM作为人工通用智能(AGI)的应用铺平了道路。ChatGPT
2
^2
2和PaLM2
3
^3
3等具有数十亿参数的高级LLM在许多复杂的实际任务中表现出巨大的潜力,如教育[8]、代码生成[9]和推荐[10]。
- LLMs are also known as pre-trained language models (PLMs).
1.LLM也称为预训练语言模型(PLM) - https://openai.com/blog/chatgpt
- https://ai.google/discover/palm2
Despite their success in many applications, LLMs have been criticized for their lack of factual knowledge. Specifically, LLMs memorize facts and knowledge contained in the training corpus [14]. However, further studies reveal that LLMs are not able to recall facts and often experience hallucinations by generating statements that are factually incorrect [15], [28]. For example, LLMs might say “Einstein discovered gravity in 1687” when asked, “When did Einstein discover gravity?”, which contradicts the fact that Isaac Newton formulated the gravitational theory. This issue severely impairs the trustworthiness of LLMs.
尽管 LLM 已有许多成功应用,但由于缺乏事实知识,它们还是备受诟病。具体来说,LLM 会记忆训练语料库中包含的事实和知识[14]。但是,进一步的研究表明,LLM 无法回忆出事实,而且往往还会出现幻觉问题,即生成具有错误事实的表述 [15], [28]。举个例子,如果向 LLM 提问:“爱因斯坦在什么时候发现了引力?”它可能会说:“爱因斯坦在 1687 年发现了引力。”但事实上,提出引力理论的人是艾萨克・牛顿。这种问题会严重损害 LLM 的可信度。
As black-box models, LLMs are also criticized for their lack of interpretability. LLMs represent knowledge implicitly in their parameters. It is difficult to interpret or validate the knowledge obtained by LLMs. Moreover, LLMs perform reasoning by a probability model, which is an indecisive process [16]. The specific patterns and functions LLMs used to arrive at predictions or decisions are not directly accessible or explainable to humans [17]. Even though some LLMs are equipped to explain their predictions by applying chain-of-thought [29], their reasoning explanations also suffer from the hallucination issue [30]. This severely impairs the application of LLMs in high-stakes scenarios, such as medical diagnosis and legal judgment. For instance, in a medical diagnosis scenario, LLMs may incorrectly diagnose a disease and provide explanations that contradict medical commonsense. This raises another issue that LLMs trained on general corpus might not be able to generalize well to specific domains or new knowledge due to the lack of domain-specific knowledge or new training data [18].
作为黑盒模型,LLM也因其缺乏可解释性而受到批评。LLM 通过参数隐含地表示知识。因此,我们难以解释和验证 LLM 获得的知识。此外,LLM通过概率模型进行推理,而这是一个非决断性的过程[16]。对于 LLM 用以得出预测结果和决策的具体模式和功能,人类难以直接获得详情和解释[17]。尽管通过使用思维链(chain-of-thought)[29],某些 LLM 具备解释自身预测结果的功能,但它们推理出的解释依然存在幻觉问题[30]。这会严重影响 LLM 在事关重大的场景中的应用,如医疗诊断和法律评判。举个例子,在医疗诊断场景中,LLM 可能误诊并提供与医疗常识相悖的解释。这就引出了另一个问题:在一般语料库上训练的 LLM 由于缺乏特定领域的知识或新训练数据,可能无法很好地泛化到特定领域或新知识上[18]。
To address the above issues, a potential solution is to incorporate knowledge graphs (KGs) into LLMs. Knowledge graphs (KGs), storing enormous facts in the way of triples,i.e., (head entity, relation, tail entity), are a structured and decisive manner of knowledge representation (e.g., Wikidata [20], YAGO [31], and NELL [32]). KGs are crucial for various applications as they offer accurate explicit knowledge [19]. Besides, they are renowned for their symbolic reasoning ability [22], which generates interpretable results. KGs can also actively evolve with new knowledge continuously added in [24]. Additionally, experts can construct domain-specific KGs to provide precise and dependable domain-specific knowledge [23].
为了解决上述问题,一个潜在的解决方案是将知识图谱(KG)整合进 LLM 中。知识图谱能以三元组的形式存储巨量事实,即 (头实体、关系、尾实体),因此知识图谱是一种结构化和决断性的知识表征形式,(例如,Wikidata[20]、YAGO[31]、和NELL[32])。知识图谱对多种应用而言都至关重要,因为其能提供准确、明确的知识[19]。此外,此外,众所周知它们还具有很棒的符号推理能力22],这能生成可解释的结果。知识图谱还能随着新知识的持续输入而积极演进[24]。此外,通过让专家来构建特定领域的知识图谱,就能具备提供精确可靠的特定领域知识的能力[23]。
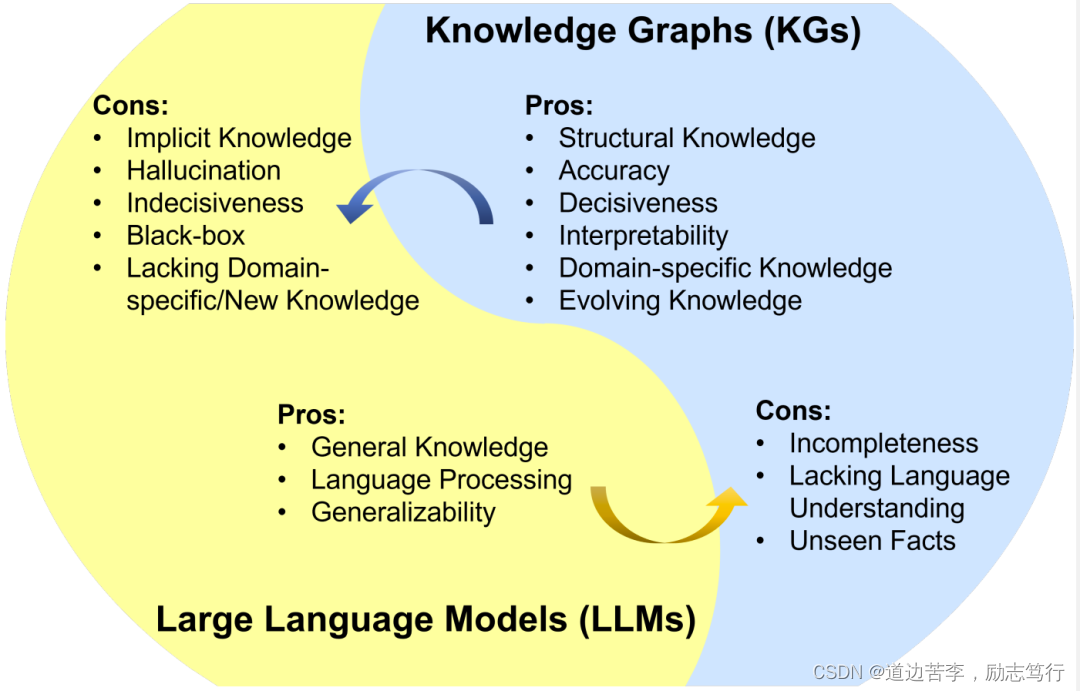
Nevertheless, KGs are difficult to construct [33], and current approaches in KGs [25], [27], [34] are inadequate in handling the incomplete and dynamically changing nature of real-world KGs. These approaches fail to effectively model unseen entities and represent new facts. In addition, they often ignore the abundant textual information in KGs.Moreover, existing methods in KGs are often customized for specific KGs or tasks, which are not generalizable enough.Therefore, it is also necessary to utilize LLMs to address the challenges faced in KGs. We summarize the pros and cons of LLMs and KGs in Fig. 1, respectively.
然而,知识图谱很难构建[33],并且由于真实世界知识图谱[25]、[27]、[34]往往是不完备的,还会动态变化,因此当前的知识图谱方法难以应对。这些方法无法有效建模未见过的实体以及表征新知识。此外,知识图谱中丰富的文本信息往往会被忽视。不仅如此,知识图谱的现有方法往往是针对特定知识图谱或任务定制的,泛化能力不足。因此,有必要使用 LLM 来解决知识图谱面临的挑战。图 1 总结了 LLM 和知识图谱的优缺点。
Recently, the possibility of unifying LLMs with KGs has attracted increasing attention from researchers and practitioners. LLMs and KGs are inherently interconnected and can mutually enhance each other. In KG-enhanced LLMs,KGs can not only be incorporated into the pre-training and inference stages of LLMs to provide external knowledge[35]–[37], but also used for analyzing LLMs and providing interpretability [14], [38], [39]. In LLM-augmented KGs,LLMs have been used in various KG-related tasks, e.g., KG embedding [40], KG completion [26], KG construction [41], KG-to-text generation [42], and KGQA [43], to improve the performance and facilitate the application of KGs. In Synergized LLM + KG, researchers marries the merits of LLMs and KGs to mutually enhance performance in knowledge representation [44] and reasoning [45], [46]. Although there are some surveys on knowledge-enhanced LLMs [47]–[49],which mainly focus on using KGs as an external knowledge to enhance LLMs, they ignore other possibilities of integrating KGs for LLMs and the potential role of LLMs in KG applications.
近段时间,将 LLM 和知识图谱联合起来的可能性受到了越来越多研究者和从业者关注。LLM 和知识图谱本质上是互相关联的,并且能彼此互相强化。如果用知识图谱增强 LLM,那么知识图谱不仅能被集成到 LLM 的预训练和推理阶段,从而用来提供外部知识[35]–[37],还能被用来分析 LLM 以提供可解释性 [14], [38], [39]。而在用 LLM 来增强知识图谱方面,LLM 已被用于多种与知识图谱相关的应用,比如知识图谱嵌入 [40]、知识图谱补全[26]、知识图谱构建[41]、知识图谱到文本的生成[42]、知识图谱问答 [43],LLM 能够提升知识图谱的性能并助益其应用。在 LLM 与知识图谱协同的相关研究中,研究者将 LLM 和知识图谱的优点融合,让它们在知识表征 [44] 和推理[45], [46]方面的能力得以互相促进。 尽管有⼀些关于知识增强LLM的调查[47]-[49],主要集中于使⽤知识图谱作为外部知识来增强LLM,但他们忽略了LLM集成知识图谱的其他可能性以及LLM在知识图谱应用中的潜在作⽤。
In this article, we present a forward-looking roadmap for unifying both LLMs and KGs, to leverage their respective strengths and overcome the limitations of each approach,for various downstream tasks. We propose detailed categorization, conduct comprehensive reviews, and pinpoint emerging directions in these fast-growing fields. Our main contributions are summarized as follows:
在这篇文章中,将在联合 LLM 与知识图谱方面提出一个前瞻性的路线图,针对不同的下游任务,以利用它们各自的优势并克服各自的局限。我们提出详细的分类和全面的总结,并指出了这些快速发展的领域的新兴方向。我们的主要贡献总结如下:
-
Roadmap. We present a forward-looking roadmap for integrating LLMs and KGs. Our roadmap,consisting of three general frameworks to unify LLMs and KGs, namely, KG-enhanced LLMs, LLM-augmented KGs, and Synergized LLMs + KGs, provides guidelines for the unification of these two distinct but complementary technologies.
1)路线图:我们提出了一份 LLM 和知识图谱整合方面的前瞻性路线图。这份路线图包含联合 LLM 与知识图谱的三个概括性框架:用知识图谱增强 LLM、用 LLM 增强知识图谱、LLM 与知识图谱协同。可为联合这两种截然不同但互补的技术提供指导方针。 -
Categorization and review. For each integration framework of our roadmap, we present a detailed categorization and novel taxonomies of research on unifying LLMs and KGs. In each category, we review the research from the perspectives of different integration strategies and tasks, which provides more insights into each framework.
2)分类和总结评估:对于该路线图中的每种整合模式,文中都提供了详细的分类和全新的分类法。对于每种类别,我们从不同整合策略和任务角度总结评估了相关研究工作,从而能为每种框架提供更多见解。 -
Coverage of emerging advances. We cover the advanced techniques in both LLMs and KGs. We include the discussion of state-of-the-art LLMs like ChatGPT and GPT-4 as well as the novel KGs e.g.,multi-modal knowledge graphs.
3)涵盖了新进展:我们覆盖了 LLM 和知识图谱的先进技术。其中讨论了 ChatGPT 和 GPT-4 等当前最先进的 LLM 以及多模态知识图谱等知识图谱新技术。 -
Summary of challenges and future directions. We highlight the challenges in existing research and present several promising future research directions.
4)挑战和未来方向:我们也给出当前研究面临的挑战并给出一些有潜力的未来研究方向。
The rest of this article is organized as follows. Section 2 first explains the background of LLMs and KGs. Section 3 introduces the roadmap and the overall categorization of this article. Section 4 presents the different KGs-enhanced LLM approaches. Section 5 describes the possible LLM-augmented KG methods. Section 6 shows the approaches of synergizing LLMs and KGs. Section 7 discusses the challenges and future research directions. Finally, Section 8 concludes this paper.
本⽂的其余部分组织如下。第 2 节⾸先解释了 LLM 和 KG 的背景。第 3 节介绍了本⽂的路线图和总体分类。第 4 节介绍了不同的 KG 增强 LLM ⽅法。第 5 节描述了可能的 LLM 增强 KG ⽅法。第 6 节展⽰了LLM 和 KG 协同作⽤的⽅法。第 7 节讨论了挑战和未来的研究⽅向。最后,第 8 节总结了本⽂。
2 BACKGROUND
2 背景
In this section, we will first briefly introduce a few representative large language models (LLMs) and discuss the prompt engineering that efficiently uses LLMs for varieties of applications. Then, we illustrate the concept of knowledge graphs (KGs) and present different categories of KGs.
在本节中,我们将⾸先简要介绍⼀些有代表性的⼤语⾔模型(LLM),并讨论如何高效地使用 LLM 进行各种应用的提示工程。然后,我们阐述了知识图谱(KGs)的概念,并介绍了不同类型的知识图谱。
2.1 Large Language models (LLMs)
2.1 大型语言模型(LLM)
Large language modes (LLMs) pre-trained on large-scale corpus have shown great potential in various NLP tasks [13]. As shown in Fig. 3, most LLMs derive from the Transformer design [50], which contains the encoder and decoder modules empowered by a self-attention mechanism. Based on the architecture structure, LLMs can be categorized into three groups: 1) encoder-only LLMs, 2) encoder-decoder LLMs, and 3) decoder-only LLMs. As shown in Fig. 2, we summarize several representative LLMs with different model architectures, model sizes, and open-source availabilities.
在大规模语料库上预训练的 LLM ,在各种自然语言处理任务中显示出巨大的潜力 [13]。如图 3 所示,大多数 LLM 都源于 Transformer 设计 [50],其中包含编码器和解码器模块,并采用了自注意力机制。LLM 可以根据架构不同而分为三大类别:1)仅编码器 LLM,2)编码器-解码器 LLM,3)仅解码器 LLM。如图 2 所示,我们对具有不同模型架构、模型大小和开源可用性的几个具有代表性的 LLM 进行了总结。


2.1.1 Encoder-only LLMs.
2.1.1 仅编码器LLM
Encoder-only large language models only use the encoder to encode the sentence and understand the relationships between words. The common training paradigm for these model is to predict the mask words in an input sentence.This method is unsupervised and can be trained on the large-scale corpus. Encoder-only LLMs like BERT [1], ALBERT [51], RoBERTa [2], and ELECTRA [52] require adding an extra prediction head to resolve downstream tasks. These models are most effective for tasks that require understanding the entire sentence, such as text classification [53] and named entity recognition [54].
仅编码器⼤型语⾔模型仅使⽤编码器对句⼦进⾏编码并理解单词之间的关系。这些模型的常⻅训练范式是预测输⼊句⼦中的掩码词。该⽅法是⽆监督的,可以在⼤规模语料库上进⾏训练。仅编码器的LLM,如 BERT [1]、AL BERT [51]、RoBERTa [2] 和 ELECTRA[52] 需要添加额外的预测头来解决下游任务。这些模型对于需要理解整个句子的任务(如文本分类 [53] 和命名实体识别 [54])最为有效。
2.1.2 Encoder-decoder LLMs.
2.1.2 编码器-解码器LLM
Encoder-decoder large language models adopt both the encoder and decoder module. The encoder module is responsible for encoding the input sentence into a hiddenspace, and the decoder is used to generate the target output text. The training strategies in encoder-decoder LLMs can be more flexible. For example, T5 [3] is pre-trained by masking and predicting spans of masking words. UL2 [55] unifies several training targets such as different masking spans and masking frequencies. Encoder-decoder LLMs (e.g., T0 [56],ST-MoE [57], and GLM-130B [58]) are able to directly resolve tasks that generate sentences based on some context, such as summariaztion, translation, and question answering [59].
编码器-解码器⼤语⾔模型同时采⽤编码器和解码器模块。编码器模块负责将输⼊句⼦编码到隐藏空间,解码器⽤于⽣成⽬标输出⽂本。编码器-解码器 LLM 中的训练策略可以更加灵活。例如,T5 [3]是通过掩蔽和预测掩蔽词的跨度来预训练的。 UL2[55]统⼀了多个训练⽬标,例如不同的掩蔽跨度和掩蔽频率。编码器-解码器 LLM(例如 T0 [56]、ST-MoE [57] 和 GLM-130B [58])能够直接解决基于某些上下⽂⽣成句⼦的任务,例如摘要、翻译和问答[59]。
2.1.3 Decoder-only LLMs.
2.1.3 仅解码器LLM
Decoder-only large language models only adopt the decoder module to generate target output text. The training paradigm for these models is to predict the next word in the sentence. Large-scale decoder-only LLMs can generally perform downstream tasks from a few examples or simple instructions, without adding prediction heads or finetuning [60]. Many state-of-the-art LLMs (e.g., Chat-GPT [61] and GPT-4
4
^4
4) follow the decoder-only architecture. However,since these models are closed-source, it is challenging for academic researchers to conduct further research. Recently,Alpaca
5
^5
5 and Vicuna
6
^6
6 are released as open-source decoder-only LLMs. These models are finetuned based on LLaMA [62] and achieve comparable performance with ChatGPT and GPT-4.
仅解码器⼤型语⾔模型仅采⽤解码器模块来⽣成⽬标输出⽂本。这些模型的训练范式是预测句⼦中的下⼀个单词。⼤规模仅解码器的LLM 通常可以通过⼏个⽰例或简单指令执⾏下游任务,⽽⽆需添加预测头或微调 [60]。许多最先进的 LLM(例如 Chat-GPT [61] 和GPT-4
4
^4
4 )都遵循仅解码器架构。然⽽,由于这些模型是闭源的,学术研究⼈员很难进⾏进⼀步的研究。最近,Alpaca
5
^5
5和 Vicuna
6
^6
6作为仅限开源解码器的LLM发布。这些模型基于 LLaMA [62] 进⾏了微调,并实现了与 ChatGPT和 GPT-4 相当的性能。
- https://openai.com/product/gpt-4
- https://github.com/tatsu-lab/stanford_alpaca
- https://lmsys.org/blog/2023-03-30-vicuna/
2.2 Prompt Engineering
2.2 提示工程
Prompt engineering is a novel field that focuses on creating and refining prompts to maximize the effectiveness of large language models (LLMs) across various applications and research areas [63]. As shown in Fig. 4, a prompt is a sequence of natural language inputs for LLMs that are specified for the task, such as sentiment classification. A prompt could contain several elements, i.e., 1) Instruction, 2) Context, and 3) Input Text. Instruction is a short sentence that instructs the model to perform a specific task. Context provides the context for the input text or few-shot examples. Input Text is the text that needs to be processed by the model.
提⽰⼯程是⼀个全新的领域,专注于创建和完善提⽰,以最⼤限度地提⾼跨各种应⽤和研究领域的⼤型语⾔模型(LLM)的有效性[63]。如图 4 所⽰, 是 LLM 的自然语言输入序列,需要针对具体任务(如情绪分类)创建。提⽰可以包含
多个元素,即 1) 指示、2) 背景信息和 3) 输⼊⽂本。指示是告知模型执行某特定任务的短句。背景信息为输入文本或少样本学习提供相关的信息。输入文本是需要模型处理的文本。

Prompt engineering seeks to improve the capacity of large large language models (e.g.,ChatGPT) in diverse complex tasks such as question answering, sentiment classification, and common sense reasoning. Chain-of-thought (CoT) prompt [64] enables complex reasoning capabilities through intermediate reasoning steps. Liu et al. [65] incorporate external knowledge to design better knowledge-enhanced prompts. Automatic prompt engineer (APE) proposes an automatic prompt generation method to improve the performance of LLMs [66]. Prompt offers a simple way to utilize the potential of LLMs without finetuning. Proficiency in prompt engineering leads to a better understanding of the strengths and weaknesses of LLMs.
提示⼯程旨在提⾼⼤型语⾔模型(例如,ChatGPT)在各种复杂任务中的能⼒,例如问答、情感分类和常识推理。思想链(CoT)提⽰[64]通过中间推理步骤实现复杂的推理能⼒。刘等⼈。 [65]另一种方法则是通过整合外部知识来设计更好的知识增强型 prompt。自动化 prompt 工程(APE)则是一种可以提升 LLM 性能的 prompt 自动生成方法[66]。 prompt 提供了⼀种⽆需微调即可发挥LLM潜⼒的简单⽅法。熟练掌握提示工程设计能让人更好地理解 LLM 的优劣之处。
2.3 Knowledge Graphs (KGs)
2.3 知识图谱(KG)
Knowledge graphs (KGs) store structured knowledge as a collection of triples KG = {(h, r, t) ⊆ E × R × E}, where E and R respectively denote the set of entities and relations.Existing knowledge graphs (KGs) can be classified into four groups based on the stored information: 1) encyclopedic KGs,2) commonsense KGs, 3) domain-specific KGs, and 4) multimodal KGs. We illustrate the examples of KGs of different categories in Fig. 5.
知识图谱则是以 (实体、关系、实体) 三元组集合的方式来存储结构化知识。根据所存储信息的不同,现有的知识图谱可分为四大类:1) 百科知识型知识图谱、2) 常识型知识图谱、3)特定领域型知识图谱、4) 多模态知识图谱。图 5 展示了不同类别知识图谱的例子。

2.3.1 Encyclopedic Knowledge Graphs.
2.3.1 百科知识图谱。
Encyclopedic knowledge graphs are the most ubiquitous KGs, which represent the general knowledge in real-world.Encyclopedic knowledge graphs are often constructed by integrating information from diverse and extensive sources,including human experts, encyclopedias, and databases.Wikidata [20] is one of the most widely used encyclopedic knowledge graphs, which incorporates varieties of knowledge extracted from articles on Wikipedia. Other typical encyclopedic knowledge graphs, like Freebase [67], Dbpedia[68], and YAGO [31] are also derived from Wikipedia. In addition, NELL [32] is a continuously improving encyclopedic knowledge graph, which automatically extracts knowledge from the web, and uses that knowledge to improve its performance over time. There are several encyclopedic knowledge graphs available in languages other than English such as CN-DBpedia [69] and Vikidia [70]. The largest knowledge graph, named Knowledge Occean (KO)
7
^7
7, currently contains 4,8784,3636 entities and 17,3115,8349 relations in both English and Chinese.
百科知识图谱是最普遍的知识图谱,它代表了现实世界中的通用知识。百科知识图谱通常是通过整合来自多种广泛来源的信息来构建的,包括⼈类专家、百科全书和数据库。维基数据[20]是使⽤最⼴泛的百科知识图谱之⼀,它包含了从维基百科⽂章中提取的各种知识。其他典型的百科全书知识图谱,如Freebase [67]、Dbpedia [68] 和 YAGO [31] 也源⾃维基百科。此外,NELL [32] 是⼀个不断完善的百科知识图谱,它能够自动从网络上提取知识,并利用这些知识随着时间的推移提高其性能。除了英语之外,还有⼏种百科知识图谱可⽤,例如 CN-DBpedia [69] 和 Vikidia [70]。最⼤的知识图谱,名为知识海洋(KO)
7
^7
7,包含了 4,8784,3636 个实体和 17,3115,8349 个中英文关系。
2.3.2 Commonsense Knowledge Graphs.
2.3.2 常识知识图谱。
Commonsense knowledge graphs formulate the knowledge about daily concepts, e.g., objects, and events, as well as their relationships [71]. Compared with encyclopedic knowledge graphs, commonsense knowledge graphs often model the tacit knowledge extracted from text such as (Car,UsedFor, Drive). ConceptNet [72] contains a wide range of commonsense concepts and relations, which can help computers understand the meanings of words people use.ATOMIC [73], [74] and ASER [75] focus on the causal effects between events, which can be used for commonsense reasoning. Some other commonsense knowledge graphs, such as TransOMCS [76] and CausalBanK [77] are automatically constructed to provide commonsense knowledge.
常识知识图谱表示了关于日常概念,例如,对象、事件以及它们之间的关系[71]。与百科知识图谱相比,常识知识图谱通常从文本中提取的隐性知识进行建模,例如(汽车,用途,驾驶)。ConceptNet[72] 包含了大量常识概念和关系,这有助于计算机理解人们使用的单词的含义。ATOMIC[73]、[74] 和 ASER[75] 关注于事件之间的因果关系,这可以用于常识推理。还有一些其他的常识知识图谱,如 TransOMCS[76] 和 CausalBanK[77],它们被自动构建以提供常识知识。
2.3.3 Domain-specific Knowledge Graphs.
2.3.3 特定领域知识图谱。
Domain-specific knowledge graphs are often constructed to represent knowledge in a specific domain, e.g., medical, biology, and finance [23]. Compared with encyclopedic knowledge graphs, domain-specific knowledge graphs are often smaller in size, but more accurate and reliable. For example, UMLS [78] is a domain-specific knowledge graph in the medical domain, which contains biomedical concepts and their relationships. In addition, there are some domainspecific knowledge graphs in other domains, such as finance[79], geology [80], biology [81], chemistry [82] and genealogy [83].
领域特定知识图谱通常用于表示特定领域的知识,例如医学、生物学和金融等领域[23]。与百科知识图谱相比,特定领域知识图谱的规模通常较小,但更加精确和可靠。例如,UMLS[78] 是医学领域的一个领域特定知识图谱,其中包含生物医学概念及其关系。此外,还有其他领域的一些领域特定知识图谱,如金融 [79]、地质学 [80]、生物学 [81]、化学 [82] 和家谱学 [83] 等。
2.3.4 Multi-modal Knowledge Graphs.
2.3.4 多模态知识图谱。
Unlike conventional knowledge graphs that only contain textual information, multi-modal knowledge graphs represent facts in multiple modalities such as images, sounds, and videos [84]. For example, IMGpedia [85], MMKG [86], and Richpedia [87] incorporate both the text and image information into the knowledge graphs. These knowledge graphs can be used for various multi-modal tasks such as image-text matching [88], visual question answering [89],and recommendation [90].
与传统的仅包含文本信息的知识图谱不同,多模态知识图谱通过多种模态(如图像、声音和视频)来表示事实 [84]。例如,IMGpedia [85]、MMKG [86] 和 Richpedia [87] 将文本和图像信息都整合到了知识图谱中。这些知识图谱可用于各种多模态任务,如图像 -文本匹配 [88]、视觉问答 [89] 和推荐 [90]。
2.4 Applications
2.4 应用
LLMs as KGs have been widely applied in various real-world applications. We summarize some representative applications of using LLMs and KGs in Table 1. ChatGPT/GPT-4 are LLM-based chatbots that can communicate with humans in a natural dialogue format. To improve knowledge awareness of LLMs, ERNIE 3.0 and Bard incorporate KGs into their chatbot applications. Instead of Chatbot. Firefly develops a photo editing application that allows users to edit photos by using natural language descriptions. Copilot, New Bing, and Shop.ai adopt LLMs to empower their applications in the areas of coding assistant, web search, and recommendation, respectively. Wikidata and KO are two representative knowledge graph applications that are used to provide external knowledge. OpenBG[91] is a knowledge graph designed for recommendation.Doctor.ai develops a health care assistant that incorporatesLLMs and KGs to provide medical advice.
大型语言模型(LLMs)作为知识图谱(KGs)已广泛应用于各种实际应用场景。我们在表 1 中总结了一些使用 LLMS 和 KGs 的代表性应用。ChatGPT/GPT-4 是基于大型语言模型的聊天机器人,可以以自然对话的形式与人类进行交流。为了提高大型语言模型的知识意识,ERNIE 3.0 和 Bard 将知识图谱融入其聊天机器人应用中。而 Firefly 则开发了一款照片编辑应用,用户可以通过自然语言描述来编辑照片。Copilot、New Bing 和 Shop.ai 分别采用大型语言模型来加强其在编程助手、网络搜索和推荐领域的应用。Wikidata 和 KO 是两个代表性的知识图谱应用,用于提供外部知识。OpenBG[91] 是一个为推荐而设计的知识图谱。Doctor.ai 开发了一款医疗助手,通过结合大型语言模型和知识图谱来提供医疗建议。

3 ROADMAP & CATEGORIZATION
3 路线图与分类
In this section, We first present a road map of explicit frameworks that unify LLMs and KGs. Then, we present the categorization of research on unifying LLMs and KGs.
在本节中,我们首先呈现一个将 LLM 和 KG 联合的显式框架路线图。然后,我们介绍联合 LLM 和 KG 的研究分类。
3.1 Roadmap
3.1 路线图
The roadmap of unifying KGs and LLMs is illustrated in Fig. 6. In the roadmap, we identify three frameworks for the unification of LLMs and KGs, including KG-enhanced LLMs, LLM-augmented KGs, and Synergized LLMs + KGs.
图 6 展示了将 LLM 和知识图谱联合起来的路线图。这份路线图包含联合 LLM 与知识图谱的三个框架:用知识图谱增强 LLM、用 LLM 增强知识图谱、LLM 与知识图谱协同。
3.1.1 KG-enhanced LLMs
3.1.1 KG增强LLM
LLMs are renowned for their ability to learn knowledge from large-scale corpus and achieve state-of-the-art performance in various NLP tasks. However, LLMs are often criticized for their hallucination issues [15], and lacking of interpretability. To address these issues, researchers have proposed to enhance LLMs with knowledge graphs (KGs).
LLM以其从大规模语料库中学习知识的能力以及在各种自然语言处理任务中取得的最先进性能而闻名。然而,LLM 常常因幻觉问题 [15] 和缺乏解释性而受到批评。为了解决这些问题,研究人员提议通过知识图谱(KG)来增强 LLM。
KGs store enormous knowledge in an explicit and structured way, which can be used to enhance the knowledge awareness of LLMs. Some researchers have proposed to incorporate KGs into LLMs during the pre-training stage,which can help LLMs learn knowledge from KGs [92], [93].Other researchers have proposed to incorporate KGs into LLMs during the inference stage. By retrieving knowledge from KGs, it can significantly improve the performance of LLMs in accessing domain-specific knowledge [94]. To improve the interpretability of LLMs, researchers also utilize KGs to interpret the facts [14] and the reasoning process of LLMs [95].
知识图谱以明确和结构化的方式存储海量知识,这可以用来提高 LLM 的知识感知能力。一些研究人员提议在 LLM 的预训练阶段将知识图谱融入其中,这可以帮助 LLM 从知识图谱中学习知识 [92]、[93]。其他研究人员则提议在 LLM 的推理阶段将知识图谱融入其中。通过从知识图谱中检索知识,可以显著提高 LLM 在访问特定领域知识方面的能力[94]。为了提高 LLM 的可解释性,研究人员还利用知识图谱来解释 LLM 的事实 [14] 和推理过程 [95]。
3.1.2 LLM-augmented KGs
3.1.2 LLM增强KG
KGs store structure knowledge playing an essential role in many real-word applications [19]. Existing methods in KGs fall short of handling incomplete KGs [25] and processing text corpus to construct KGs [96]. With the generalizability of LLMs, many researchers are trying to harness the power of LLMs for addressing KG-related tasks.
知识图谱(KG)存储结构知识,在许多实际应用中发挥着关键作用 [19]。现有的知识图谱方法在处理不完整的知识图谱 [25] 和处理文本语料库以构建知识图谱 [96] 方面存在不足。随着预训练语言模型(LLM)的泛化能力,许多研究人员正试图利用 LLMs 的力量来解决与知识图谱相关的任务。
The most straightforward way to apply LLMs as text encoders for KG-related tasks. Researchers take advantage of LLMs to process the textual corpus in the KGs and then use the representations of the text to enrich KGs representation [97]. Some studies also use LLMs to process the original corpus and extract relations and entities for KG construction[98]. Recent studies try to design a KG prompt that can effectively convert structural KGs into a format that can be comprehended by LLMs. In this way, LLMs can be directly applied to KG-related tasks, e.g., KG completion [99] and KG reasoning [100].
将 LLM 直接应用于知识图谱(KG)相关任务的最直接方法是将其作为文本编码器。研究人员利用 LLM 处理 KG 中的文本语料库,然后使用文本表示来丰富 KG 的表现形式 [97]。一些研究还使用 LLM 处理原始语料库,以提取用于 KG 构建的关系和实体 [98]。最近的研究试图设计一个 KG 提示,可以将结构化的 KGs 有效地转换为 LLM 可理解的格式。这样,LLM 就可以直接应用于 KG 相关任务,例如,KG 补全 [99] 和 KG 推理 [100]。
3.1.3 Synergized LLMs + KGs
3.1.3 应用
The synergy of LLMs and KGs has attracted increasing attention from researchers these years [40], [42]. LLMs and KGs are two inherently complementary techniques, which should be unified into a general framework to mutually enhance each other.
近年来,研究人员对 LLMs 和 KGs 的协同作用越来越关注 [40],[42]。LLMs 和 KGs 是两种固有互补的技术,应该将它们统一到一个通用框架中,以相互增强。LLMs和KGs的协同引起了研究人员的越来越多的关注[40],[42]。LLMs和KGs是两种本质上互补的技术,应该统一到一个通用框架中以相互增强。
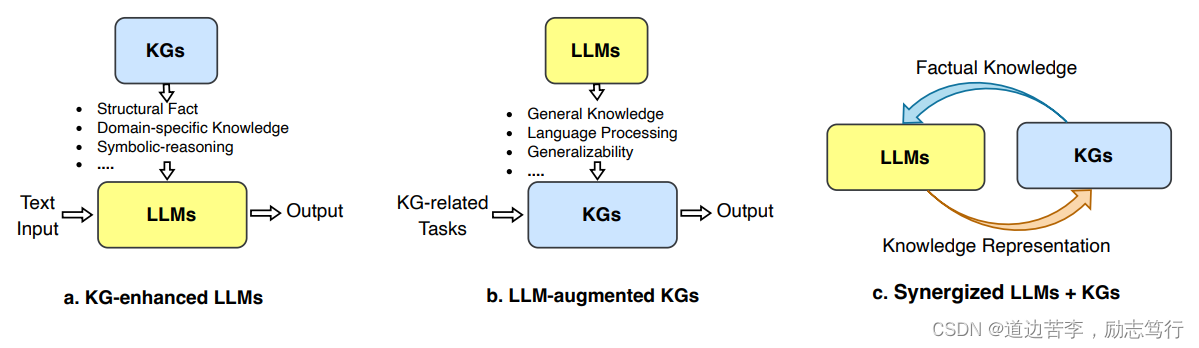
To further explore the unification, we propose a unified framework of the synergized LLMs + KGs in Fig. 7. The unified framework contains four layers: 1) Data, 2) Synergized Model, 3) Technique, and 4) Application. In the Data layer, LLMs and KGs are used to process the textual and structural data, respectively. With the development of multi-modal LLMs [101] and KGs [102], this framework can be extended to process multi-modal data, such as video, audio, and images. In the Synergized Model layer, LLMs and KGs could synergize with each other to improve their capabilities. In Technique layer, related techniques that have been used in LLMs and KGs can be incorporated into this framework to further enhance the performance. In the Application layer, LLMs and KGs can be integrated to address various realworld applications, such as search engines [103], recommender systems [10], and AI assistants [104].
为了进一步探索统一LLM + KG的方法,我们提出了一个统一的框架,如图7所示。这个统一框架包含四个层次:1)数据层,2)协同模型层,3)技术层,4)应用层。在数据层,LLM 和 KG 分别用于处理文本和结构化数据。随着多模态 LLM[101] 和 KG[102] 的发展,这个框架可以扩展到处理多模态数据,如图像、音频和视频。在协同模型层,LLM 和 KG 可以相互协同以提高其能力。在技术层,LLM 和 KG 中使用过的相关技术可以纳入这个框架,以进一步提高性能。在应用层,LLM 和 KG 可以集成起来,解决各种实际应用问题,如搜索引擎 [103],推荐系统 [10],和 AI 助手 [104]。

3.2 Categorization
3.2 分类
To better understand the research on unifying LLMs and KGs, we further provide a fine-grained categorization for each framework in the roadmap. Specifically, we focus on different ways of integrating KGs and LLMs, i.e., KG-enhanced LLMs, KG-augmented LLMs, and Synergized LLMs + KGs. The fine-grained categorization of the research is illustrated in Fig. 8.
为了更好地了解联合LLM和KG的研究,我们进一步为路线图中的每个框架提供了细粒度的分类。具体而言,我们关注不同的KG和LLM集成方式,即KG增强的LLM,LLM增强的KG和协同LLM + KG。研究的细粒度分类如图8所示。
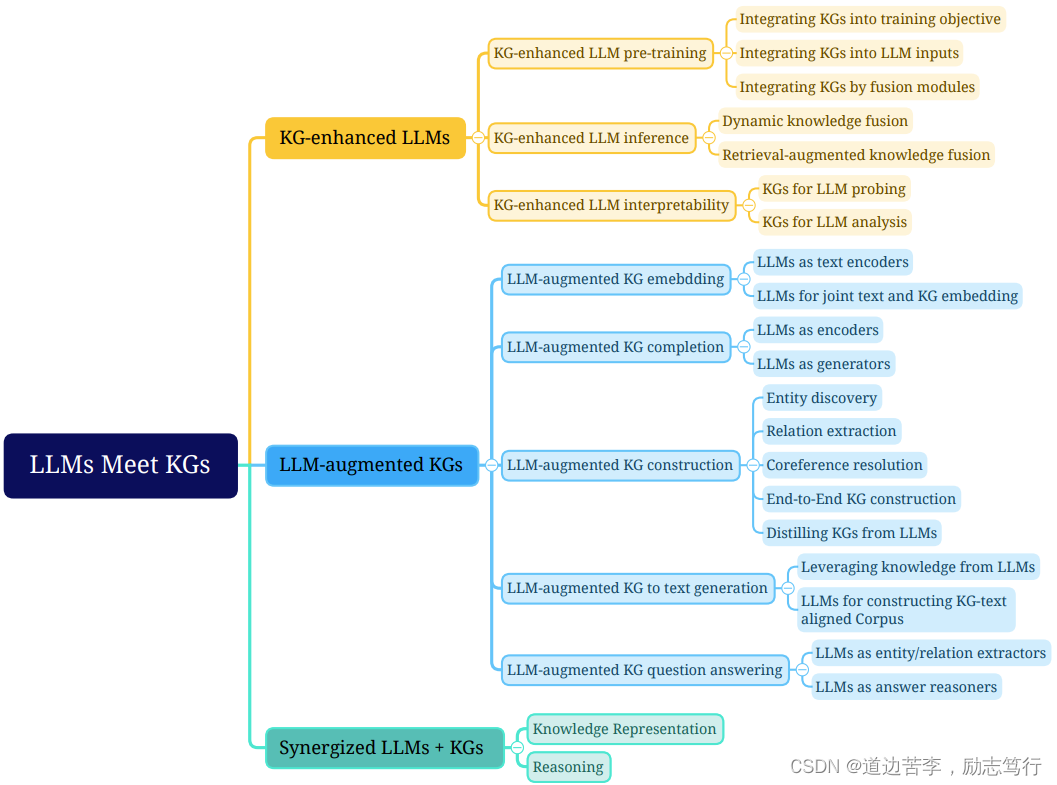
KG-enhanced LLMs. Integrating KGs can enhance the performance and interpretability of LLMs in various downstream tasks. We categorize the research on KG-enhanced LLMs into three groups:
KG增强LLM。集成KG可以增强LLM在各种下游任务中的性能和可解释性。我们将KG增强的LLM的研究分为三组:
1)KG-enhanced LLM pre-training includes works that apply KGs during the pre-training stage and improve the knowledge expression of LLMs.
1)KG增强的LLM预训练:包括在预训练阶段应用KG的,以改善LLM的知识表达能力。
2)KG-enhanced LLM inference includes research that utilizes KGs during the inference stage of LLMs,which enables LLMs to access the latest knowledge without retraining.
2)KG增强的LLM推理:包括在LLM的推理阶段使用KG的研究,使LLM能够在无需重新训练的情况下访问最新的知识。
3)KG-enhanced LLM interpretability includes works that use KGs to understand the knowledge learned by LLMs and interpret the reasoning process of LLMs.
3)KG增强的LLM可解释性:包括使用KG来理解LLM学到的知识以及解释LLM的推理过程的工作。
LLM-augmented KGs. LLMs can be applied to augment various KG-related tasks. We categorize the research on LLM-augmented KGs into five groups based on the task types:
LLM增强KG。LLM可以用于增强各种与KG相关的任务。我们根据任务类型将LLM增强的KG的研究分为五组:
1)LLM-augmented KG embedding includes studies that apply LLMs to enrich representations of KGs by encoding the textual descriptions of entities and relations.
1)LLM增强的KG嵌入:包括将LLM应用于通过编码实体和关系的文本描述来丰富KG表示的研究。
2)LLM-augmented KG completion includes papers that utilize LLMs to encode text or generate facts for better KGC performance.
2)LLM增强的KG补全:包括利用LLM对文本进行编码或生成事实,以提高KG完成任务的性能的论文。
3)LLM-augmented KG construction includes works that apply LLMs to address the entity discovery, coreference resolution, and relation extraction tasks for KG construction.
3)LLM增强的KG构建:包括利用LLMs来处理实体发现、共指消解和关系提取等任务,用于KG构建的研究。
4)LLM-augmented KG-to-text Generation includes research that utilizes LLMs to generate natural language that describes the facts from KGs.
4)LLM增强的KG到文本生成:包括利用LLM生成描述KG事实的自然语言的研究。
5)LLM-augmented KG question answering includes studies that apply LLMs to bridge the gap between natural language questions and retrieve answers from KGs.
5)LLM增强的KG问答:包括将LLM应用于连接自然语言问题并从KG中检索答案的研究。
Synergized LLMs + KGs. The synergy of LLMs and KGs aims to integrate LLMs and KGs into a unified framework to mutually enhance each other. In this categorization, we review the recent attempts of Synergized LLMs + KGs from the perspectives of knowledge representation and reasoning.
协同LLM + KG。LLM和KG的协同旨在将LLM和KG统一到一个框架中,以相互增强。在这个分类中,我们从知识表示和推理的角度回顾了最近的协同LLM + KG的尝试。
In the following sections (Sec 4, 5, and 6), we will provide details on these categorizations.
在接下来的章节(第4、5和6节)中,我们将详细介绍这些分类。
4 KG-ENHANCED LLMS
4 KG增强LLM
Large language models (LLMs) achieve promising results in many natural language processing tasks. However, LLMs have been criticized for their lack of practical knowledge and tendency to generate factual errors during inference.To address this issue, researchers have proposed integrating knowledge graphs (KGs) to enhance LLMs. In this section, we first introduce the KG-enhanced LLM pre-training,which aims to inject knowledge into LLMs during the pretraining stage. Then, we introduce the KG-enhanced LLM inference, which enables LLMs to consider the latest knowledge while generating sentences. Finally, we introduce the KG-enhanced LLM interpretability, which aims to improve the interpretability of LLMs by using KGs. Table 2 summarizes the typical methods that integrate KGs for LLMs.
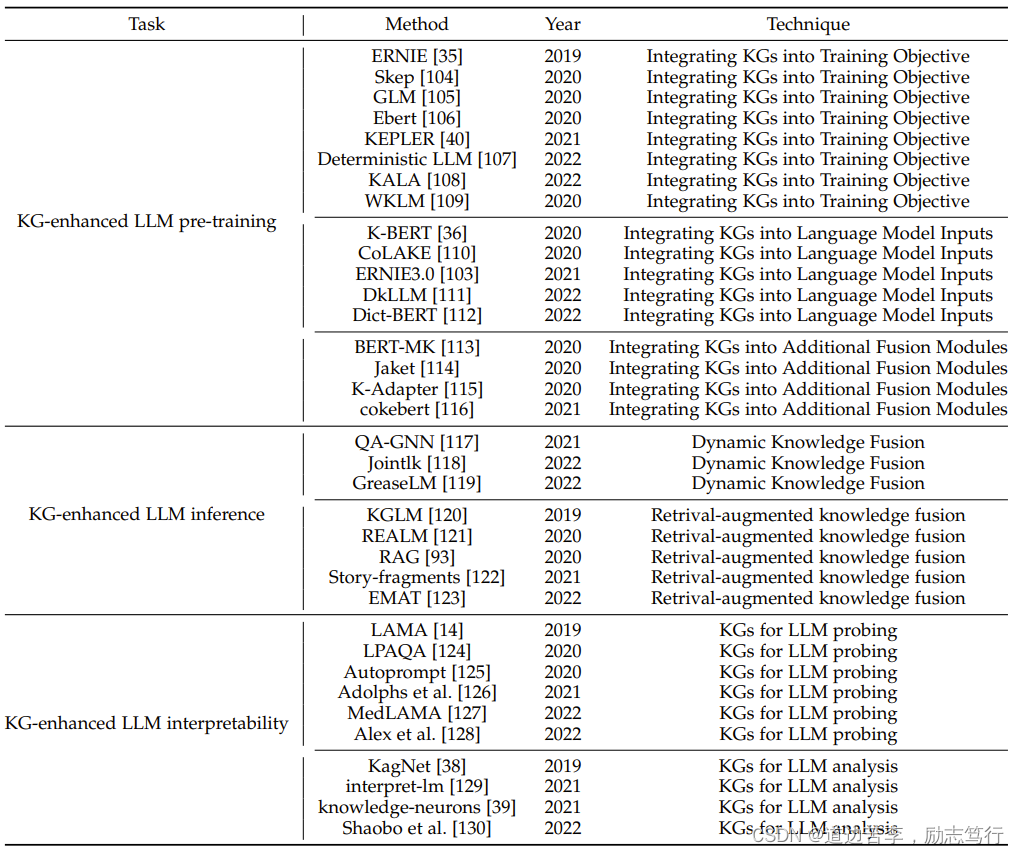
大型语言模型(LLM)在许多自然语言处理任务中取得了有希望的结果。然而,LLM因缺乏实际知识并在推理过程中产生事实错误而受到批评。为了解决这个问题,研究人员提出了将知识图谱(KG)集成到LLM中以增强其性能。在本节中,我们首先介绍KG增强的LLM预训练,旨在在预训练阶段将知识注入到LLM中。然后,我们介绍KG增强的LLM推理,使LLM在生成句子时考虑到最新的知识。最后,我们介绍KG增强的LLM可解释性,旨在通过使用KG来提高LLM的可解释性。表2总结了将KG集成到LLM中的典型方法。
4.1 KG-enhanced LLM Pre-training
4.1 KG增强的LLM预训练
Existing large language models mostly rely on unsupervised training on the large-scale corpus. While these models may exhibit impressive performance on downstream tasks, they often lack practical knowledge relevant to the real world. Previous works that integrate KGs into large language models can be categorized into three parts: 1) Integrating KGs into training objective, 2) Integrating KGs into LLM inputs and 3) Integrating KGs into additional fusion modules.
现有的大型语言模型主要依赖于对大规模语料库进行无监督训练。尽管这些模型在下游任务中可能表现出色,但它们通常缺乏与现实世界相关的实际知识。之前的研究将知识图谱集成到大型语言模型中可分为三部分:1)将知识图谱集成到训练目标中,2)将知识图谱集成到LLM的输入中,3)将知识图谱集成到额外的融合模块中。
4.1.1 Integrating KGs into Training Objective
4.1.1 将知识图谱集成到训练目标中
The research efforts in this category focus on designing novel knowledge-aware training objectives. An intuitive idea is to expose more knowledge entities in the pre-training objective. GLM [106] leverages the knowledge graph structure to assign a masking probability. Specifically, entities that can be reached within a certain number of hops are considered to be the most important entities for learning,and they are given a higher masking probability during pre-training. Furthermore, E-BERT [107] further controls the balance between the token-level and entity-level training losses. The training loss values are used as indications of the learning process for token and entity, which dynamically determines their ratio for the next training epochs. SKEP [105] also follows a similar fusion to inject sentiment knowledge during LLMs pre-training. SKEP first determines words with positive and negative sentiment by utilizing PMI along with a predefined set of seed sentiment words. Then, it assigns a higher masking probability to those identified sentiment words in the word masking objective.
这个类别的研究工作侧重于设计新颖的知识感知训练目标。一种直观的想法是在预训练目标中暴露更多的知识实体。GLM [106]利用知识图谱的结构为掩码概率分配权重。具体而言,对于可以通过一定数量跳跃到达的实体,被认为是学习的最重要实体,并且在预训练过程中给予更高的掩码概率。此外,E-BERT [107]进一步控制了标记级和实体级训练损失之间的平衡。训练损失的值被用作标记和实体的学习过程的指示,动态确定它们在下一次训练周期中的比例。SKEP [105]在LLM的预训练过程中也采用了类似的融合方式来注入情感知识。SKEP首先通过利用PMI和预定义的种子情感词识别具有积极和消极情感的单词。然后,它在词掩码目标中对这些被识别为情感词的单词分配更高的掩码概率。
The other line of work explicitly leverages the connections with knowledge and input text. As shown in Figure 9,ERNIE [92] proposes a novel word-entity alignment training objective as a pre-training objective. Specifically, ERNIE feeds both sentences and corresponding entities mentioned in the text into LLMs, and then trains the LLMs to predict alignment links between textual tokens and entities in knowledge graphs. Similarly, KALM [93] enhances the input tokens by incorporating entity embeddings and includes an entity prediction pre-training task in addition to the token-only pre-training objective. This approach aims to improve the ability of LLMs to capture knowledge related to entities. Finally, KEPLER [132] directly employs both knowledge graph embedding training objective and Masked token pre-training objective into a shared transformer-based encoder. Deterministic LLM [108] focuses on pre-training language models to capture deterministic factual knowledge. It only masks the span that has a deterministic entity as the question and introduces additional clue contrast learning and clue classification objective. WKLM [110] first replaces entities in the text with other same-type entities and then feeds them into LLMs. The model is further pre-trained to distinguish whether the entities have been replaced or not.
另一方面,还有一些研究明确利用与知识和输入文本之间的连接。如图9所示,ERNIE [92]提出了一种新颖的单词-实体对齐训练目标作为预训练目标。具体而言,ERNIE将句子和文本中提到的相应实体输入到LLM中,然后训练LLM来预测文本标记和知识图谱中实体之间的对齐链接。类似地,KALM [93]通过合并实体嵌入将实体相关的信息融入到输入标记中,并在仅有标记的预训练目标之外引入了实体预测的预训练任务。这种方法旨在提高LLM捕捉与实体相关的知识的能力。最后,KEPLER [132]将知识图谱嵌入训练目标和掩码标记预训练目标直接应用于共享的基于Transformer的编码器中。Deterministic LLM [108]的重点是预训练语言模型以捕捉确定性的事实知识。它只对具有确定性实体作为问题的范围的部分进行掩码,并引入了额外的线索对比学习和线索分类目标。WKLM [110]首先将文本中的实体替换为同类型的其他实体,然后将其输入到LLM中。模型进一步进行预训练以区分实体是否已被替换。

4.1.2 Integrating KGs into LLM Inputs
4.1.2 将知识图谱集成到LLM的输入中
As shown in Fig. 10, this kind of research focus on introducing relevant knowledge sub-graph into the inputs of LLMs. Given a knowledge graph triple and the corresponding sentences, ERNIE 3.0 [104] represents the triple as a sequence of tokens and directly concatenates them with the sentences. It further randomly masks either the relation token in the triple or tokens in the sentences to better combine knowledge with textual representations. However, such direct knowledge triple concatenation method allows the tokens in the sentence to intensively interact with the tokens in the knowledge sub-graph, which could result in Knowledge Noise [36]. To solve this issue, K-BERT [36] takes the first step to inject the knowledge triple into the sentence via a visible matrix where only the knowledge entities have access to the knowledge triple information, while the tokens in the sentences can only see each other in the self-attention module. To further reduce Knowledge Noise, Colake [111] proposes a unified word-knowledge graph (shown in Fig. 10) where the tokens in the input sentences form a fully connected word graph where tokens aligned with knowledge entities are connected with their neighboring entities.
如图10所示,这类研究工作侧重于将相关的知识子图引入到LLMs的输入中。给定一个知识图谱三元组和相应的句子,ERNIE 3.0 [104]将三元组表示为一个标记序列,并将其直接与句子拼接在一起。它进一步随机掩盖三元组中的关系标记或句子中的标记,以更好地将知识与文本表示相结合。然而,这种直接知识三元组拼接的方法使得句子中的标记与知识子图中的标记密集地相互作用,可能导致知识噪声。为了解决这个问题,K-BERT [36]通过可见矩阵将知识三元组注入到句子中,只有知识实体可以访问知识三元组信息,而句子中的标记只能在自注意力模块中相互作用。为了进一步减少知识噪声,Colake [111]提出了一个统一的词-知识图谱(如图10所示),其中输入句子中的标记形成一个全连接的词图,与知识实体对齐的标记与其相邻实体连接在一起。上述方法确实能够向LLMs注入大量的知识。然而,它们主要关注热门实体,忽视了低频和长尾实体。DkLLM [112]旨在改进LLMs对这些实体的表示。DkLLM首先提出一种确定长尾实体的新方法,然后用伪标记嵌入将这些选定的实体替换为文本中的实体,作为大型语言模型的新输入。此外,Dict-BERT [113]提出利用外部字典来解决这个问题。具体而言,Dict-BERT通过将字典中的定义附加到输入文本的末尾来改善稀有单词的表示质量,并训练语言模型来在输入句子和字典定义之间进行局部对齐,并区分输入文本和定义是否正确映射。

The above methods can indeed inject a large amount of knowledge into LLMs. However, they mostly focus on popular entities and overlook the low-frequent and longtail ones. DkLLM [112] aims to improve the LLMs representations towards those entities. DkLLM first proposes a novel measurement to determine long-tail entities and then replaces these selected entities in the text with pseudo token embedding as new input to the large language models.Furthermore, Dict-BERT [113] proposes to leverage external dictionaries to solve this issue. Specifically, Dict-BERT improves the representation quality of rare words by appending their definitions from the dictionary at the end of input text and trains the language model to locally align rare words representations in input sentences and dictionary definitions as well as to discriminate whether the input text and definition are correctly mapped.
上述方法确实能够向LLMs注入大量的知识。然而,它们主要关注热门实体,忽视了低频和长尾实体。DkLLM [112]旨在改进LLMs对这些实体的表示。DkLLM首先提出一种确定长尾实体的新方法,然后用伪标记嵌入将这些选定的实体替换为文本中的实体,作为大型语言模型的新输入。此外,Dict-BERT [113]提出利用外部字典来解决这个问题。具体而言,Dict-BERT通过将字典中的定义附加到输入文本的末尾来改善稀有单词的表示质量,并训练语言模型来在输入句子和字典定义之间进行局部对齐,并区分输入文本和定义是否正确映射
4.1.3 Integrating KGs by Additional Fusion Modules
4.1.3 通过额外的融合模块集成KG
By introducing additional fusion modules into LLMs, the information from KGs can be separately processed and fused into LLMs. As shown in Fig. 11, ERNIE [92] proposes a textual-knowledge dual encoder architecture where a Tencoder first encodes the input sentences, then a K-encoder processes knowledge graphs which are fused them with the textual representation from the T-encoder. BERT-MK [114] employs a similar dual-encoder architecture but it introduces additional information of neighboring entities in the knowledge encoder component during the pre-training of LLMs. However, some of the neighboring entities in KGs may not be relevant to the input text, resulting in extra redundancy and noise. CokeBERT [117] focuses on this issue and proposes a GNN-based module to filter out irrelevant KG entities using the input text. JAKET [115] proposes to fuse the entity information in the middle of the large language model. The first half of the model processes the input text and knowledge entity sequence separately. Then, the outputs of text and entities are combined together. Specifically, the entity representations are added to their corresponding position of text representations, which are further processed by the second half of the model. K-adapters [116] fuses linguistic and factual knowledge via adapters which only adds trainable multi-layer perception in the middle of the transformer layer while the existing parameters of large language models remain frozen during the knowledge pretraining stage. Such adapters are independent of each other and can be trained in parallel.
通过将额外的融合模块引入LLM中,可以单独处理并将知识图谱中的信息融入到LLM中。如图11所示,ERNIE [92]提出了一种文本-知识双编码器架构,其中T-编码器首先对输入句子进行编码,然后K-编码器处理知识图谱,并将其与T-编码器中的文本表示融合。BERT-MK [114]采用了类似的双编码器架构,但在LLM的预训练过程中引入了知识编码器组件中相邻实体的附加信息。然而,知识图谱中的某些相邻实体可能与输入文本无关,导致额外的冗余和噪声。CokeBERT [117]关注这个问题,并提出了一个基于GNN的模块,通过使用输入文本来过滤掉无关的KG实体。JAKET [115]提出在大型语言模型的中间融合实体信息。模型的前半部分分别处理输入文本和实体序列。然后,文本和实体的输出被组合在一起。具体而言,实体表示被添加到其对应位置的文本表示中,然后由模型的后半部分进一步处理。K-adapters [116]通过适配器来融合语言和事实知识,适配器只在变压器层的中间添加可训练的多层感知器,而大型语言模型的现有参数在知识预训练阶段保持冻结状态。这样的适配器彼此独立,并且可以并行训练。

4.2 KG-enhanced LLM Inference
4.2 KG增强的LLM推理
The above methods could effectively fuse knowledge with the textual representations in the large language models. However, real-world knowledge is subject to change and the limitation of these approaches is that they do not permit updates to the incorporated knowledge without retraining the model. As a result, they may not generalize well to the unseen knowledge during inference [133]. Therefore, considerable research has been devoted to keeping the knowledge space and text space separate and injecting the knowledge while inference. These methods mostly focus on the Question Answering (QA) tasks, because QA requires
the model to capture both textual semantic meanings and up-to-date real-world knowledge.
上述方法可以有效地将知识与大型语言模型中的文本表示进行融合。然而,现实世界的知识是不断变化的,这些方法的局限性在于它们不允许在不重新训练模型的情况下更新已整合的知识。因此,在推理过程中它们可能无法很好地推广到未见过的知识[133]。因此,人们对将知识空间和文本空间分离并在推理过程中注入知识进行了大量研究。这些方法主要集中在问答(QA)任务上,因为QA要求模型能够捕捉到文本语义含义和最新的现实世界知识。
4.2.1 Dynamic Knowledge Fusion
4.2.1 动态知识融合
A straightforward method is to leverage a two-tower architecture where one separated module processes the text inputs and the other one processes the relevant knowledge graph inputs [134]. However, this method lacks interaction between text and knowledge. Thus, KagNet [95] proposes to first encode the input KG, and then augment the input textual representation. In contrast, MHGRN [135] uses the final LLM outputs of the input text to guide the reasoning process on the KGs. Yet, both of them only design a singledirection interaction between the text and KGs. To tackle this issue, QA-GNN [118] proposes to use a GNN-based model to jointly reason over input context and KG information via message passing. Specifically, QA-GNN represents the input textual information as a special node via a pooling operation and connects this node with other entities in KG. However, the textual inputs are only pooled into a single dense vector, limiting the information fusion performance. JointLK [119] then proposes a framework with fine-grained interaction between any tokens in the textual inputs and any KG entities through LM-to-KG and KG-to-LM bi-directional attention mechanism. As shown in Fig. 12, pairwise dotproduct scores are calculated over all textual tokens and KG entities, the bi-directional attentive scores are computed separately. In addition, at each jointLK layer, the KGs are also dynamically pruned based on the attention score to allow later layers to focus on more important sub-KG structures. Despite being effective, in JointLK, the fusion process between the input text and KG still uses the final LLM outputs as the input text representations. GreaseLM [120] designs deep and rich interaction between the input text tokens and KG entities at each layer of the LLMs. The architecture and fusion approach are mostly similar to ERNIE [92] discussed in Section 4.1.3, except that GreaseLM does not use the textonly T-encoder to handle input text.
一种直接的方法是利用双塔架构,其中一个独立模块处理文本输入,另一个处理相关的知识图谱输入[134]。然而,这种方法缺乏文本和知识之间的交互。因此,KagNet [95]提出首先编码输入的知识图谱,然后增强输入的文本表示。相反,MHGRN [135]使用输入文本的最终LLM输出来指导对知识图谱的推理过程。然而,它们都只设计了文本和知识之间的单向交互。为了解决这个问题,QA-GNN [118]提出使用基于GNN的模型通过消息传递来共同推理输入上下文和知识图谱信息。具体而言,QA-GNN通过池化操作将输入的文本信息表示为一个特殊节点,并将该节点与知识图谱中的其他实体连接起来。然而,文本输入只被池化为一个单一的密集向量,限制了信息融合的性能。JointLK [119]随后提出了一个框架,通过LM-to-KG和KG-to-LM双向注意机制,在文本输入的任何标记和知识图谱实体之间实现细粒度的交互。如图12所示,计算了所有文本标记和知识图谱实体之间的成对点积分数,并单独计算了双向注意分数。此外,在每个JointLK层中,根据注意分数动态修剪了知识图谱,以便后续层能够集中在更重要的子知识图结构上。尽管JointLK有效,但其中输入文本和知识图谱之间的融合过程仍然使用最终的LLM输出作为输入文本表示。GreaseLM [120]在LLMs的每一层中为输入文本标记和知识图谱实体设计了深入和丰富的交互。架构和融合方法在很大程度上类似于在第4.1.3节中讨论的ERNIE [92],只是GreaseLM不使用单独的文本T-编码器来处理输入文本。
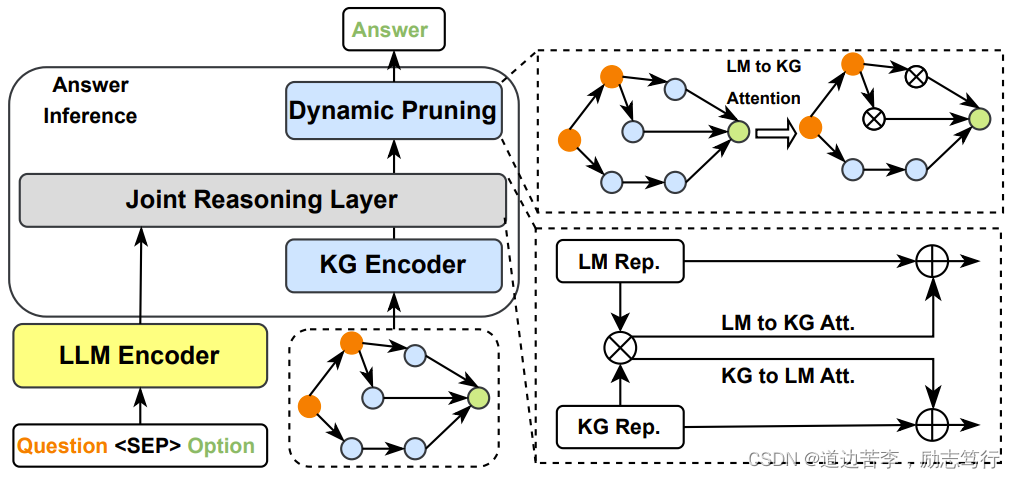
4.2.2 Retrieval-Augmented Knowledge Fusion
4.2.2 检索增强的知识融合
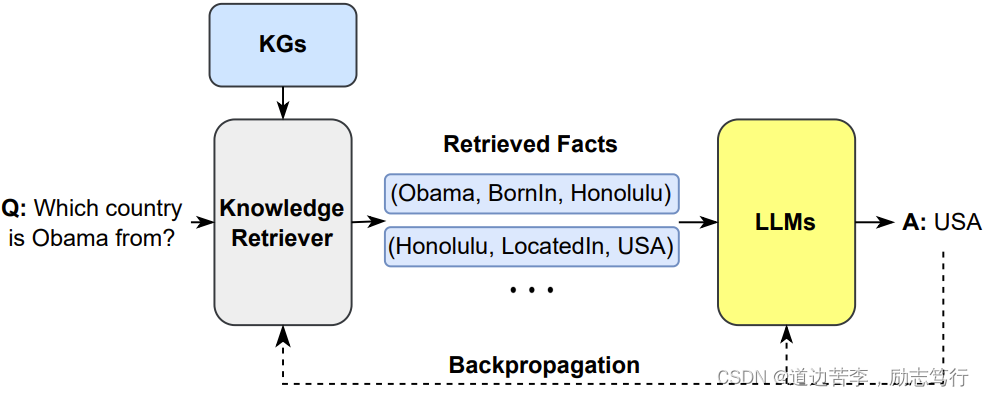
Different from the above methods that store all knowledge in parameters, as shown in Figure 13, RAG [94] proposes to combine non-parametric and parametric modules to handle the external knowledge. Given the input text, RAG first searches for relevant KG in the non-parametric module via MIPS to obtain several documents. RAG then treats these documents as hidden variables z and feeds them into the output generator, empowered by Seq2Seq LLMs, as additional context information. The research indicates that using different retrieved documents as conditions at different generation steps performs better than only using a single document to guide the whole generation process. The experimental results show that RAG outperforms other parametric-only and non-parametric-only baseline models in open-domain QA. RAG can also generate more specific, diverse, and factual text than other parameter-only baselines. Story-fragments [123] further improves architecture by adding an additional module to determine salient knowledge entities and fuse them into the generator to improve the quality of generated long stories. EMAT [124] further improves the efficiency of such a system by encoding external knowledge into a key-value memory and exploiting the fast maximum inner product search for memory querying. REALM [122] proposes a novel knowledge retriever to help the model to retrieve and attend over documents from a large corpus during the pre-training stage and successfully improves the performance of open-domain question answering. KGLM [121] selects the facts from a knowledge graph using the current context to generate factual sentences. With the help of an external knowledge graph, KGLM could describe facts using out-of-domain words or phrases.
与将所有知识存储在参数中的上述方法不同,如图13所示,RAG [94]提出了将非参数模块和参数模块结合起来处理外部知识的方法。给定输入文本,RAG首先通过最近邻搜索在非参数模块中搜索相关的知识图谱,以获取几个文档。然后,RAG将这些文档视为隐藏变量z,并将它们作为附加上下文信息馈送到由Seq2Seq LLM支持的输出生成器中。研究表明,在生成过程中使用不同的检索文档作为条件比仅使用单个文档来引导整个生成过程效果更好。实验结果表明,与只使用参数模块或非参数模块的基准模型相比,RAG在开放域QA中表现更好。RAG还能够生成更具体、多样和真实的文本,而不仅仅是基于参数的基线模型。Story-fragments [123]通过添加额外模块来确定重要的知识实体并将它们融入生成器中,以提高生成的长篇故事的质量。EMAT [124]通过将外部知识编码为键值内存,并利用快速最大内积搜索进行内存查询,进一步提高了这种系统的效率。REALM [122]提出了一种新颖的知识检索器,帮助模型在预训练阶段从大型语料库中检索并关注文档,并成功提高了开放域问答的性能。KGLM [121]根据当前上下文从知识图谱中选择事实以生成事实性句子。借助外部知识图谱的帮助,KGLM可以使用领域外的词汇描述事实。
4.3 KG-enhanced LLM Interpretability
4.3 KG增强的LLM可解释性
Although LLMs have achieved remarkable success in many NLP tasks, they are still criticized for their lack of interpretability. The large language model (LLM) interpretability refers to the understanding and explanation of the inner workings and decision-making processes of a large language model [17]. This can improve the trustworthiness of LLMs and facilitate their applications in high-stakes scenarios such as medical diagnosis and legal judgment. Knowledge graphs (KGs) represent the knowledge structurally and can provide good interpretability for the reasoning results.Therefore, researchers try to utilize KGs to improve the interpretability of LLMs, which can be roughly grouped into two categories: 1) KGs for language model probing, and 2) KGs for language model analysis.
尽管LLM在许多自然语言处理任务上都表现不凡,但由于缺乏可解释性,依然备受诟病。大型语言模型(LLM)可解释性是指理解和解释大型语言模型的内部工作方式和决策过程[17]。这可以提高LLM的置信度,并促进它们在医学诊断和法律判断等高风险场景中的应用。由于知识图谱是以结构化的方式表示知识,因此可为推理结果提供优良的可解释性。因此,研究人员尝试利用知识图谱来提高LLM的可解释性,这可以大致分为两类:1)用于语言模型探测的知识图谱,和2)用于语言模型分析的知识图谱。
4.3.1 KGs for LLM Probing
4.3.1 用于LLM探测的知识图谱
The large language model (LLM) probing aims to understand the knowledge stored in LLMs. LLMs, trained on large-scale corpus, are often known as containing enormous knowledge. However, LLMs store the knowledge in a hidden way, making it hard to figure out the stored knowledge. Moreover, LLMs suffer from the hallucination problem [15], which results in generating statements that contradict facts. This issue significantly affects the reliability of LLMs. Therefore, it is necessary to probe and verify the knowledge stored in LLMs.
大型语言模型(LLM)探测旨在了解存储在LLM中的知识。LLM经过大规模语料库的训练,通常被认为包含了大量的知识。然而,LLM以一种隐藏的方式存储知识,使得很难确定存储的知识。此外,LLM存在幻觉问题[15],导致生成与事实相矛盾的陈述。这个问题严重影响了LLM的可靠性。因此,有必要对存储在LLMs中的知识进行探测和验证。
LAMA [14] is the first work to probe the knowledge in LLMs by using KGs. As shown in Fig. 14, LAMA first
converts the facts in KGs into cloze statements by a predefined prompt template and then uses LLMs to predict the missing entity. The prediction results are used to evaluate the knowledge stored in LLMs. For example, we try to probe whether LLMs know the fact (Obama, profession, president). We first convert the fact triple into a cloze question “Obama’s profession is .” with the object masked. Then, we test if the LLMs can predict the object “president” correctly.
LAMA [14]是首个使用知识图谱探测LLM中知识的工作。如图14所示,LAMA首先通过预定义的提示模板将知识图谱中的事实转化为填空陈述,然后使用LLM预测缺失的实体。预测结果用于评估LLM中存储的知识。例如,我们尝试探测LLM是否知道事实(奥巴马,职业,总统)。我们首先将事实三元组转换为带有对象被屏蔽的填空问题“奥巴马的职业是什么?”然后,我们测试LLM能否正确预测出“总统”这个对象。

However, LAMA ignores the fact that the prompts are inappropriate. For example, the prompt “Obama worked as a ” may be more favorable to the prediction of the blank by the language models than “Obama is a by profession”. Thus, LPAQA [125] proposes a mining and paraphrasing-based method to automatically generate high-quality and diverse prompts for a more accurate assessment of the knowledge contained in the language model. Moreover, Adolphs et al.[127] attempt to use examples to make the language model understand the query, and experiments obtain substantial improvements for BERT-large on the T-REx data. Unlike using manually defined prompt templates, Autoprompt[126] proposes an automated method, which is based on the gradient-guided search to create prompts.
然而,LAMA忽略了提示不恰当的事实。例如,“奥巴马的职业是。”可能对语言模型的填空预测比“奥巴马是一位职业。”更有利。因此,LPAQA [125]提出了一种基于挖掘和改写的方法,自动生成高质量和多样化的提示,以更准确地评估语言模型中包含的知识。此外,Adolphs等人[127]尝试使用示例使语言模型理解查询,实验证明对T-REx数据的BERT-large模型取得了显著的改进。与使用手动定义的提示模板不同,Autoprompt [126]提出了一种基于梯度引导搜索的自动化方法来创建提示。
Instead of probing the general knowledge by using the encyclopedic and commonsense knowledge graphs, BioLAMA [136] and MedLAMA [128] probe the medical knowledge in LLMs by using medical knowledge graphs. Alex et al. [129] investigate the capacity of LLMs to retain less popular factual knowledge. They select unpopular facts from Wikidata knowledge graphs which have lowfrequency clicked entities. These facts are then used for the evaluation, where the results indicate that LLMs encounter difficulties with such knowledge, and that scaling fails to appreciably improve memorization of factual knowledge in the tail.
与使用百科和常识知识图谱来探测一般知识不同,BioLAMA [136]和MedLAMA [128]使用医学知识图谱来探测LLMs中的医学知识。Alex等人[129]研究LLMs保留不太流行的事实的能力。他们从Wikidata知识图谱中选择了低频点击实体的不太流行的事实。然后将这些事实用于评估,结果表明LLMs在处理此类知识时遇到困难,并且在尾部的事实性知识的记忆方面,扩大规模并不能显著提高。
4.3.2 KGs for LLM Analysis
4.3.2 用于LLM分析的知识图谱
Knowledge graphs (KGs) for pre-train language models (LLMs) analysis aims to answer the following questions such as “how do LLMs generate the results?”, and “how do the function and structure work in LLMs?”. To analyze the inference process of LLMs, as shown in Fig. 15, KagNet [38] and QA-GNN [118] make the results generated by LLMs at each reasoning step grounded by knowledge graphs. In this way, the reasoning process of LLMs can be explained by extracting the graph structure from KGs. Shaobo et al. [131] investigate how LLMs generate the results correctly. They adopt the causal-inspired analysis from facts extracted from KGs. This analysis quantitatively measures the word patterns that LLMs depend on to generate the results. The results show that LLMs generate the missing factual more by the positionally closed words rather than the knowledge-dependent words. Thus, they claim that LLMs are inadequate to memorize factual knowledge because of the inaccurate dependence. To interpret the training of LLMs, Swamy et al. [130] adopt the language model during pre-training to generate knowledge graphs. The knowledge acquired by LLMs during training can be unveiled by the facts in KGs explicitly. To explore how implicit knowledge is stored in parameters of LLMs, Dai et al. [39] propose the concept of knowledge neurons. Specifically, activation of the identified knowledge neurons is highly correlated with knowledge expression. Thus, they explore the knowledge and facts represented by each neuron by suppressing and amplifying knowledge neurons.
知识图谱(KG)用于预训练语言模型(LLM)分析旨在回答以下问题:“LLM是如何生成结果的?”和“LLM的功能和结构如何工作?”为了分析LLM的推理过程,如图15所示,KagNet [38]和QA-GNN [118]通过知识图谱将LLM在每个推理步骤生成的结果进行了基于图的支撑。通过从KG中提取图结构,可以解释LLM的推理过程。Shaobo等人[131]研究LLM如何正确生成结果。他们采用了从KG中提取的事实的因果性分析。该分析定量地衡量LLM在生成结果时所依赖的词汇模式。结果表明,LLM更多地依赖于位置相关的词汇模式而不是知识相关的词汇模式来生成缺失的事实。因此,他们声称LLM不适合记忆事实性知识,因为依赖关系不准确。为了解释LLM的训练,Swamy等人[130]采用语言模型在预训练期间生成知识图谱。LLM在训练过程中获得的知识可以通过KG中的事实来揭示。为了探索LLM中的隐式知识是如何存储在参数中的,Dai等人[39]提出了知识神经元的概念。具体而言,被识别的知识神经元的激活与知识表达高度相关。因此,他们通过抑制和放大知识神经元来探索每个神经元表示的知识和事实。

5 LLM-AUGMENTED FOR KGS
5.基于LLM的知识图谱增强
Knowledge graphs are famous for representing knowledge in a structural manner. They have been applied in many downstream tasks such as question answering, recommendation, and web search. However, the conventional KGs are often incomplete and existing methods often lack considering textual information. To address these issues, recent research has explored integrating LLMs to augment KGs to consider the textual information and improve the performance in downstream tasks. In this section, we will introduce the recent research on LLM-augmented KGs. Representative works are summarized in Table 3. We will introduce the methods that integrate LLMs for KG embedding, KG completion, KG construction, KG-to-text generation, and KG question answering, respectively.
知识图谱以结构化的方式表示知识,并已应用于许多下游任务,如问答、推荐和网络搜索。然而,传统的知识图谱通常不完整,现有方法往往缺乏考虑文本信息的能力。为了解决这些问题,最近的研究探索了将LLM整合到知识图谱中以考虑文本信息并提高下游任务性能。在本节中,我们将介绍关于LLM增强的知识图谱的最新研究。代表性的工作总结在表3中。我们将分别介绍整合LLM进行知识图谱嵌入、知识图谱补全、知识图谱构建、知识图谱到文本生成和知识图谱问答的方法。

5.1 LLM-augmented KG Embedding
5.1 基于LLM的知识图谱嵌入
Knowledge graph embedding (KGE) aims to map each entity and relation into a low-dimensional vector (embedding) space. These embeddings contain both semantic and structural information of KGs, which can be utilized for various tasks such as question answering [182], reasoning [38], and recommendation [183]. Conventional knowledge graph embedding methods mainly rely on the structural information of KGs to optimize a scoring function defined on embeddings (e.g., TransE [25], and DisMult [184]).However, these approaches often fall short in representing unseen entities and long-tailed relations due to their limited structural connectivity [185], [186]. To address this issue, as shown in Fig. 16, recent research adopt LLMs to enrich representations of KGs by encoding the textual descriptions of entities and relations [40], [97].
知识图谱嵌入(KGE)的目标是将每个实体和关系映射到低维的向量(嵌入)空间。这些嵌入包含知识图谱的语义和结构信息,可用于多种不同的任务,如问答、推理和推荐。传统的知识图谱嵌入方法主要依靠知识图谱的结构信息来优化一个定义在嵌入上的评分函数(如 TransE 和 DisMult)。但是,这些方法由于结构连接性有限,因此难以表示未曾见过的实体和长尾的关系。图 16 展示了近期的一项研究:为了解决这一问题,该方法使用 LLM 来编码实体和关系的文本描述,从而丰富知识图谱的表征。

5.1.1 LLMs as Text Encoders
5.1.1 LLM作为文本编码器
Pretrain-KGE [97] is a representative method that follows the framework shown in Fig. 16. Given a triple
(
h
,
r
,
t
)
(h, r, t)
(h,r,t) from KGs, it firsts uses a LLM encoder to encode the textual descriptions of entities
h
,
t
,
h, t,
h,t, and relations
r
r
r into representations as
e
h
=
L
L
M
(
T
e
x
t
h
)
,
e
t
=
L
L
M
(
T
e
x
t
t
)
,
e
r
=
L
L
M
(
T
e
x
t
r
)
,
(1)
e_h=LLM(Text_h),e_t = LLM(Text_t),e_r = LLM(Text_r) ,\tag{1}
eh=LLM(Texth),et=LLM(Textt),er=LLM(Textr),(1)
where
e
h
e_h
eh,
e
r
e_r
er, and
e
t
e_t
et denotes the initial embeddings of entities
h
,
t
,
h, t,
h,t, and relations
r
,
r,
r, respectively. Pretrain-KGE uses the BERT as the LLM encoder in experiments. Then, the initial embeddings are fed into a KGE model to generate the final embeddings
v
h
,
v
r
,
v_h, v_r,
vh,vr, and
v
t
v_t
vt. During the KGE training phase, they optimize the KGE model by following the standard KGE loss function as
L
=
[
γ
+
f
(
v
h
,
v
r
,
v
t
)
−
f
(
v
h
′
,
v
r
′
,
v
t
′
)
]
,
(2)
\mathcal{L}= [γ + f(v_h,v_r,v_t) - f(v'_h,v'_r,v'_t)], \tag{2}
L=[γ+f(vh,vr,vt)−f(vh′,vr′,vt′)],(2)
where
f
f
f is the KGE scoring function,
γ
γ
γ is a margin hyperparameter, and
v
h
′
,
v
r
′
,
v'_h, v'_r,
vh′,vr′, and
v
t
′
v'_t
vt′ are the negative samples. In this way, the KGE model could learn adequate structure information, while reserving partial knowledge from LLM enabling better knowledge graph embedding. KEPLER [40] offers a unified model for knowledge embedding and pre-trained language representation. This model not only generates effective text-enhanced knowledge embedding using powerful LLMs but also seamlessly integrates factual knowledge into LLMs. Nayyeri et al. [137] use LLMs to generate the world-level, sentence-level, and document-level representations. They are integrated with graph structure embeddings into a unified vector by Dihedron and Quaternion representations of 4D hypercomplex numbers. Huang et al. [138] combine LLMs with other vision and graph encoders to learn multi-modal knowledge graph embedding that enhances the performance of downstream tasks. CoDEx [139] presents a novel loss function empowered by LLMs that guides the KGE models in measuring the likelihood of triples by considering the textual information. The proposed loss function is agnostic to model structure that can be incorporated with any KGE model.
Pretrain-KGE [97]是一个典型的方法,遵循图16所示的框架。给定知识图谱中的三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t),它首先使用LLM编码器将实体
h
、
t
h、t
h、t和关系
r
r
r的文本描述编码为表示:
e
h
=
L
L
M
(
T
e
x
t
h
)
,
e
t
=
L
L
M
(
T
e
x
t
t
)
,
e
r
=
L
L
M
(
T
e
x
t
r
)
,
(1)
e_h=LLM(Text_h),e_t = LLM(Text_t),e_r = LLM(Text_r) ,\tag{1}
eh=LLM(Texth),et=LLM(Textt),er=LLM(Textr),(1)
其中
e
h
、
e
r
e_h、e_r
eh、er和
e
t
e_t
et分别表示实体
h
、
t
h、t
h、t和关系
r
r
r的初始嵌入。Pretrain-KGE在实验中使用BERT作为LLM编码器。然后,将初始嵌入馈送到KGE模型中生成最终的嵌入
v
h
、
v
r
v_h、v_r
vh、vr和
v
t
v_t
vt。在KGE训练阶段,通过遵循标准KGE损失函数优化KGE模型:
L
=
[
γ
+
f
(
v
h
,
v
r
,
v
t
)
−
f
(
v
h
′
,
v
r
′
,
v
t
′
)
]
,
(2)
\mathcal{L}= [γ + f(v_h,v_r,v_t) - f(v'_h,v'_r,v'_t)], \tag{2}
L=[γ+f(vh,vr,vt)−f(vh′,vr′,vt′)],(2)
其中
f
f
f是KGE评分函数,
γ
γ
γ是边界超参数,
v
′
h
、
v
′
r
v′_h、v′_r
v′h、v′r和
v
′
t
v′_t
v′t是负样本。通过这种方式,KGE模型可以学习充分的结构信息,同时保留LLM中的部分知识,从而实现更好的知识图谱嵌入。KEPLER [40]提供了一个统一的模型用于知识嵌入和预训练的语言表示。该模型不仅使用强大的LLM生成有效的文本增强的知识嵌入,还无缝地将事实知识集成到LLM中。Nayyeri等人[137]使用LLM生成世界级、句子级和文档级表示。它们通过四维超复数的Dihedron和Quaternion表示将其与图结构嵌入统一为一个向量。Huang等人[138]将LLM与其他视觉和图形编码器结合起来,学习多模态的知识图谱嵌入,提高下游任务的性能。CoDEx[139]提出了一种由LLM赋能的新型损失函数,通过考虑文本信息来指导KGE模型测量三元组的可能性。所提出的损失函数与模型结构无关,可以与任何KGE模型结合使用。
5.1.2 LLMs for Joint Text and KG Embedding
5.1.2 用于联合文本和知识图谱嵌入的LLM
Instead of using KGE model to consider graph structure,another line of methods directly employs LLMs to incorporate both the graph structure and textual information into the embedding space simultaneously. As shown in Fig. 17,kNN-KGE [141] treats the entities and relations as special tokens in the LLM. During training, it transfers each triple
(
h
,
r
,
t
)
(h, r, t)
(h,r,t) and corresponding text descriptions into a sentence
x
x
x as
x
=
[
C
L
S
]
h
T
e
x
t
h
[
S
E
P
]
r
[
S
E
P
]
[
M
A
S
K
]
T
e
x
t
t
[
S
E
P
]
,
(3)
x = [CLS] h Text_h [SEP] r [SEP] [MASK] Text_t [SEP], \tag{3}
x=[CLS]hTexth[SEP]r[SEP][MASK]Textt[SEP],(3)
where the tailed entities are replaced by [MASK]. The sentence is fed into a LLM, which then finetunes the model to predict the masked entity, formulated as
P
L
L
M
(
t
∣
h
,
r
)
=
P
(
[
M
A
S
K
]
=
t
∣
x
,
Θ
)
,
(4)
P_{LLM}(t|h, r) = P([MASK]=t|x, Θ), \tag{4}
PLLM(t∣h,r)=P([MASK]=t∣x,Θ),(4)
where
Θ
Θ
Θ denotes the parameters of the LLM. The LLM is optimized to maximize the probability of the correct entity
t
t
t. After training, the corresponding token representations in LLMs are used as embeddings for entities and relations. Similarly, LMKE [140] proposes a contrastive learning method to improve the learning of embeddings generated by LLMs for KGE. Meanwhile, to better capture graph structure, LambdaKG [142] samples 1-hop neighbor entities and concatenates their tokens with the triple as a sentence feeding into LLMs.
另一类方法直接使用LLM将图结构和文本信息同时纳入嵌入空间,而不是使用KGE模型考虑图结构。如图17所示,kNN-KGE [141]将实体和关系作为LLM中的特殊标记处理。在训练过程中,它将每个三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t)及其相应的文本描述转化为句子
x
x
x:
x
=
[
C
L
S
]
h
T
e
x
t
h
[
S
E
P
]
r
[
S
E
P
]
[
M
A
S
K
]
T
e
x
t
t
[
S
E
P
]
,
(3)
x = [CLS] h Text_h [SEP] r [SEP] [MASK] Text_t [SEP], \tag{3}
x=[CLS]hTexth[SEP]r[SEP][MASK]Textt[SEP],(3)
其中尾部实体被[MASK]替换。将句子馈送到LLM中,然后微调模型来预测被遮蔽的实体,公式化为
P
L
L
M
(
t
∣
h
,
r
)
=
P
(
[
M
A
S
K
]
=
t
∣
x
,
Θ
)
,
(4)
P_{LLM}(t|h, r) = P([MASK]=t|x, Θ), \tag{4}
PLLM(t∣h,r)=P([MASK]=t∣x,Θ),(4)
其中
Θ
Θ
Θ表示LLM的参数。LLM被优化以最大化正确实体t的概率。训练后,LLM中相应的标记表示用作实体和关系的嵌入。类似地,LMKE [140]提出了一种对比学习方法,改进了LLM生成的用于KGE的嵌入的学习。此外,为了更好地捕捉图结构,LambdaKG [142]采样1-hop邻居实体,并将它们的标记与三元组连接为一个句子,然后馈送到LLMs中。

5.2 LLM-augmented KG Completion
5.2 基于LLM的知识图谱补全
Knowledge Graph Completion (KGC) refers to the task of inferring missing facts in a given knowledge graph. Similar to KGE, conventional KGC methods mainly focused on the structure of the KG, without considering the extensive textual information. However, the recent integration of LLMs enables KGC methods to encode text or generate facts for better KGC performance. These methods fall into two distinct categories based on their utilization styles: 1) LLM as Encoders (PaE), and 2) LLM as Generators (PaG).
知识图谱补全(KGC)是指在给定知识图谱中推断缺失的事实的任务。与KGE类似,传统的KGC方法主要关注知识图谱的结构,而没有考虑广泛的文本信息。然而,LLM的最新整合使得KGC方法能够编码文本或生成事实,以提高KGC的性能。根据它们的使用方式,这些方法分为两个不同的类别:1) LLM作为编码器(PaE),2) LLM作为生成器(PaG)。
5.2.1 LLM as Encoders (PaE).
5.2.1 LLM作为编码器(PaE)
As shown in Fig. 18 (a), (b), and (c ), This line of work first uses encoder-only LLMs to encode textual information as well as KG facts. Then, they predict the plausibility of the triples by feeding the encoded representation into a prediction head, which could be a simple MLP or conventional KG score function (e.g., TransE [25] and TransR [187]).
如图18(a)、(b)和(c )所示,这一系列的方法首先使用仅编码器LLM对文本信息和知识图谱事实进行编码。然后,它们通过将编码表示输入到预测头部(可以是简单的MLP或传统的知识图谱评分函数,如TransE [25]和TransR [187])中来预测三元组的可信度。

Joint Encoding. Since the encoder-only LLMs (e.g., Bert [1]) are well at encoding text sequences, KG-BERT [26] represents a triple (h, r, t) as a text sequence and encodes it with LLM Fig. 18(a).
x
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
T
e
x
t
t
[
S
E
P
]
,
(5)
x = [CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP], \tag{5}
x=[CLS]Texth[SEP]Textr[SEP]Textt[SEP],(5)
The final hidden state of the
[
C
L
S
]
[CLS]
[CLS] token is fed into a classifier to predict the possibility of the triple, formulated as
s
=
σ
(
M
L
P
(
e
[
C
L
S
]
)
)
,
(6)
s = σ(MLP(e_{[CLS]})), \tag{6}
s=σ(MLP(e[CLS])),(6)
where
σ
(
⋅
)
σ(·)
σ(⋅)denotes the sigmoid function and
e
[
C
L
S
]
e_{[CLS]}
e[CLS] denotes the representation encoded by LLMs. To improve the efficacy of KG-BERT, MTL-KGC [143] proposed a MultiTask Learning for the KGC framework which incorporates additional auxiliary tasks into the model’s training, i.e. prediction (RP) and relevance ranking (RR). PKGC [144] assesses the validity of a triplet
(
h
,
r
,
t
)
(h, r, t)
(h,r,t) by transforming the triple and its supporting information into natural language sentences with pre-defined templates. These sentences are then processed by LLMs for binary classification. The supporting information of the triplet is derived from the attributes of
h
h
h and
t
t
t with a verbalizing function. For instance, if the triple is (Lebron James, member of sports team, Lakers), the information regarding Lebron James is verbalized as ”Lebron James: American basketball player”. LASS [145] observes that language semantics and graph structures are equally vital to KGC. As a result, LASS is proposed to jointly learn two types of embeddings: semantic embedding and structure embedding. In this method, the full text of a triple is forwarded to the LLM, and the mean pooling of the corresponding LLM outputs for
h
,
r
,
h, r,
h,r,and
t
t
t are separately calculated. These embeddings are then passed to a graphbased method, i.e. TransE, to reconstruct the KG structures.
联合编码。由于仅编码器LLM(如BERT [1])在编码文本序列方面表现出色,KG-BERT [26]将三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t)表示为一个文本序列,并使用LLM对其进行编码(图18(a))。
x
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
T
e
x
t
t
[
S
E
P
]
,
(5)
x = [CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP], \tag{5}
x=[CLS]Texth[SEP]Textr[SEP]Textt[SEP],(5)
将
[
C
L
S
]
[CLS]
[CLS]标记的最终隐藏状态馈送到分类器中,预测三元组的可能性,公式化为
s
=
σ
(
M
L
P
(
e
[
C
L
S
]
)
)
,
(6)
s = σ(MLP(e_{[CLS]})), \tag{6}
s=σ(MLP(e[CLS])),(6)
其中
σ
(
⋅
)
σ(·)
σ(⋅)表示Sigmoid函数,
e
[
C
L
S
]
e_{[CLS]}
e[CLS]表示LLM编码的表示。为了提高KG-BERT的效果,MTL-KGC [143]提出了一种用于KGC框架的多任务学习,将额外的辅助任务(如预测和相关性排序)融入模型的训练中。PKGC [144]通过使用预定义模板将三元组及其支持信息转化为自然语言句子,评估三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t)的有效性。这些句子然后通过LLMs进行二分类处理。三元组的支持信息是根据
h
h
h和
t
t
t的属性使用语言化函数推导出来的。例如,如果三元组是(Lebron James,member of sports team,Lakers),则关于Lebron James的信息被语言化为“Lebron James:American basketball player”。LASS [145]观察到语言语义和图结构对KGC同样重要。因此,提出了LASS来联合学习两种类型的嵌入:语义嵌入和结构嵌入。在这种方法中,将三元组的完整文本转发给LLM,然后分别计算
h
、
r
h、r
h、r和
t
t
t的对应LLMs输出的平均池化。然后,将这些嵌入传递给图结构方法(如TransE)以重构知识图谱结构。
MLM Encoding. Instead of encoding the full text of a triple, many works introduce the concept of Masked Language Model (MLM) to encode KG text (Fig. 18(b)). MEM-KGC [146] uses Masked Entity Model (MEM) classification mechanism to predict the masked entities of the triple. The input text is in the form of
x
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
[
M
A
S
K
]
[
S
E
P
]
,
(7)
x = [CLS] Text_h [SEP] Text_r [SEP] [MASK] [SEP],\tag{7}
x=[CLS]Texth[SEP]Textr[SEP][MASK][SEP],(7)
Similar to Eq. 4, it tries to maximize the probability that the masked entity is the correct entity t. Additionally, to enable the model to learn unseen entities, MEM-KGC integrates multitask learning for entities and super-class prediction based on the text description of entities:
x
=
[
C
L
S
]
[
M
A
S
K
]
[
S
E
P
]
T
e
x
t
h
[
S
E
P
]
.
(8)
x = [CLS] [MASK] [SEP] Text_h [SEP]. \tag{8}
x=[CLS][MASK][SEP]Texth[SEP].(8)
OpenWorld KGC [147] expands the MEM-KGC model to address the challenges of open-world KGC with a pipeline framework, where two sequential MLM-based modules are defined: Entity Description Prediction (EDP), an auxiliary module that predicts a corresponding entity with a given textual description; Incomplete Triple Prediction (ITP), the target module that predicts a plausible entity for a given incomplete triple
(
h
,
r
,
?
)
(h, r, ?)
(h,r,?). EDP first encodes the triple with Eq. 8 and generates the final hidden state, which is then forwarded into ITP as an embedding of the head entity in Eq. 7 to predict target entities.
MLM编码。许多工作不是编码三元组的完整文本,而是引入了遮蔽语言模型(MLM)的概念来编码知识图谱的文本信息(图18(b))。MEM-KGC [146]使用遮蔽实体模型(MEM)分类机制来预测三元组中的遮蔽实体。输入文本的形式为
x
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
[
M
A
S
K
]
[
S
E
P
]
,
(7)
x = [CLS] Text_h [SEP] Text_r [SEP] [MASK] [SEP],\tag{7}
x=[CLS]Texth[SEP]Textr[SEP][MASK][SEP],(7)
类似于公式4,它试图最大化遮蔽实体是正确实体
t
t
t的概率。此外,为了使模型学习未见实体,MEM-KGC还结合了基于实体文本描述的实体和超类预测的多任务学习:
x
=
[
C
L
S
]
[
M
A
S
K
]
[
S
E
P
]
T
e
x
t
h
[
S
E
P
]
.
(8)
x = [CLS] [MASK] [SEP] Text_h [SEP]. \tag{8}
x=[CLS][MASK][SEP]Texth[SEP].(8)
OpenWorld KGC [147]将MEM-KGC模型扩展到处理开放世界KGC的挑战,采用了一个流水线框架,在其中定义了两个串行的基于MLM的模块:实体描述预测(EDP)和不完整三元组预测(ITP)。EDP首先使用公式8对三元组进行编码,并生成最终的隐藏状态,然后将其作为公式7中头实体的嵌入传递给ITP,以预测目标实体。
Separated Encoding. As shown in Fig. 18( c), these methods involve partitioning a triple
(
h
,
r
,
t
)
(h, r, t)
(h,r,t) into two distinct parts, i.e.
(
h
,
r
)
(h, r)
(h,r) and
t
t
t, which can be expressed as
x
(
h
,
r
)
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
,
(9)
x_{(h,r)} = [CLS] Text_h [SEP] Text_r [SEP], \tag{9}
x(h,r)=[CLS]Texth[SEP]Textr[SEP],(9)
x
t
=
[
C
L
S
]
T
e
x
t
t
[
S
E
P
]
.
(10)
x_t = [CLS] Text_t [SEP]. \tag{10}
xt=[CLS]Textt[SEP].(10)
Then the two parts are encoded separately by LLMs, and the final hidden states of the
[
C
L
S
]
[CLS]
[CLS] tokens are used as the representations of
(
h
,
r
)
(h, r)
(h,r) and
t
t
t, respectively. The representations are then fed into a scoring function to predict the possibility of the triple, formulated as
s
=
f
s
c
o
r
e
(
e
(
h
,
r
)
,
e
t
)
,
(11)
s = f_{score}(e_{(h,r)}, e_t), \tag{11}
s=fscore(e(h,r),et),(11)
where
f
s
c
o
r
e
f_{score}
fscore denotes the score function like TransE.
分离编码。如图18( c)所示,这些方法将三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t)分为两个不同的部分,即
(
h
,
r
)
(h,r)
(h,r)和
t
t
t,可以表示为
x
(
h
,
r
)
=
[
C
L
S
]
T
e
x
t
h
[
S
E
P
]
T
e
x
t
r
[
S
E
P
]
,
(9)
x_{(h,r)} = [CLS] Text_h [SEP] Text_r [SEP], \tag{9}
x(h,r)=[CLS]Texth[SEP]Textr[SEP],(9)
x
t
=
[
C
L
S
]
T
e
x
t
t
[
S
E
P
]
.
(10)
x_t = [CLS] Text_t [SEP]. \tag{10}
xt=[CLS]Textt[SEP].(10)
然后,这两部分分别由LLM进行编码,然后使用
[
C
L
S
[CLS
[CLS]标记的最终隐藏状态作为
(
h
,
r
)
(h,r)
(h,r)和
t
t
t的表示。然后将这些表示输入到评分函数中,预测三元组的可能性,公式化为
s
=
f
s
c
o
r
e
(
e
(
h
,
r
)
,
e
t
)
,
(11)
s = f_{score}(e_{(h,r)}, e_t), \tag{11}
s=fscore(e(h,r),et),(11)
其中
f
s
c
o
r
e
f_{score}
fscore表示像TransE这样的评分函数。
StAR [148] applies Siamese-style textual encoders on their text, encoding them into separate contextualized representations. To avoid the combinatorial explosion of textual encoding approaches, e.g., KG-BERT, StAR employs a scoring module that involves both deterministic classifier and spatial measurement for representation and structure learning respectively, which also enhances structured knowledge by exploring the spatial characteristics. SimKGC [149] is another instance of leveraging a Siamese textual encoder to encode textual representations. Following the encoding process, SimKGC applies contrastive learning techniques to these representations. This process involves computing the similarity between the encoded representations of a given triple and its positive and negative samples. In particular, the similarity between the encoded representation of the triple and the positive sample is maximized, while the similarity between the encoded representation of the triple and the negative sample is minimized. This enables SimKGC to learn a representation space that separates plausible and implausible triples. To avoid overfitting textural information, CSPromp-KG [188] employs parameter-efficient prompt learning for KGC.
StAR [148]在其文本上应用了Siamese风格的文本编码器,将其编码为单独的上下文表示。为了避免文本编码方法的组合爆炸,例如KG-BERT,StAR使用了一个包含确定性分类器和用于表示和结构学习的空间度量的评分模块,这也通过探索空间特性增强了结构化知识。SimKGC [149]是另一个利用Siamese文本编码器对文本表示进行编码的实例。在编码过程之后,SimKGC对这些表示应用对比学习技术。这个过程涉及计算给定三元组及其正负样本之间的相似性。特别地,最大化三元组的编码表示与正样本的相似性,同时最小化三元组的编码表示与负样本的相似性。这使得SimKGC能够学习一个将可信和不可信三元组分开的表示空间。为了避免过度拟合文本信息,CSPromp-KG [188]采用了用于KGC的参数高效提示学习。
LP-BERT [150] is a hybrid KGC method that combines both MLM Encoding and Separated Encoding. This approach consists of two stages, namely pre-training and fine-tuning. During pre-training, the method utilizes the standard MLM mechanism to pre-train a LLM with KGC data. During the fine-tuning stage, the LLM encodes both parts and is optimized using a contrastive learning strategy(similar to SimKGC [149]).
LP-BERT [150]是一种混合KGC方法,将MLM编码和分离编码相结合。这种方法包括两个阶段:预训练和微调。在预训练阶段,该方法使用标准的MLM机制对KGC数据进行预训练LLMs。在微调阶段,LLMs对两个部分进行编码,并使用对比学习策略进行优化(类似于SimKGC [149])。
5.2.2 LLM as Generators (PaG).
5.2.2 LLM作为生成器(PaG)
Recent works use LLMs as sequence-to-sequence generators in KGC. As presented in Fig. 19 (a) and (b), these approaches involve encoder-decoder or decoder-only LLMs. The LLMs receive a sequence text input of the query triple
(
h
,
r
,
?
)
(h, r, ?)
(h,r,?), and generate the text of tail entity
t
t
t directly.
最近的研究在知识图谱构建(KGC)中将大型语言模型(LLMs)用作序列到序列的生成器。如图19(a)和(b)所示,这些方法涉及编码器-解码器或仅解码器LLM。LLM接收查询三元组(h,r,?)的文本输入序列,并直接生成尾实体t的文本。

GenKGC [99] uses the large language model BART [5] as the backbone model. Inspired by the in-context learning approach used in GPT-3 [60], where the model concatenates relevant samples to learn correct output answers, GenKGC proposes a relation-guided demonstration technique that includes triples with the same relation to facilitating the model’s learning process. In addition, during generation, an entity-aware hierarchical decoding method is proposed to reduce the time complexity. KGT5 [151] introduces a novel KGC model that fulfils four key requirements of such models: scalability, quality, versatility, and simplicity.To address these objectives, the proposed model employs a straightforward T5 small architecture. The model is distinct from previous KGC methods, in which it is randomly initialized rather than using pre-trained models. KG-S2S [152] is a comprehensive framework that can be applied to various types of KGC tasks, including Static KGC, Temporal KGC, and Few-shot KGC. To achieve this objective, KG-S2S reformulates the standard triple KG fact by introducing an additional element, forming a quadruple
(
h
,
r
,
t
,
m
)
(h, r, t, m)
(h,r,t,m), where
m
m
m represents the additional ”condition” element. Although different KGC tasks may refer to different conditions, they typically have a similar textual format, which enables unification across different KGC tasks. The KG-S2S approach incorporates various techniques such as entity description,soft prompt, and Seq2Seq Dropout to improve the model’s performance. In addition, it utilizes constrained decoding to ensure the generated entities are valid. For closed-source LLMs (e.g., ChatGPT and GPT-4), AutoKG adopts prompt engineering to design customized prompts [96]. As shown in Fig. 20, these prompts contain the task description, few-shot examples, and test input, which instruct LLMs to predict the tail entity for KG completion.
GenKGC [99] 以大型语言模型 BART [5] 作为基础模型。借鉴 GPT-3 [60] 中使用的上下文学习方法,其中模型连接相关样本以学习正确输出答案,GenKGC 提出了一种关系引导的示例技术,包括具有相同关系的三元组,以促进模型的学习过程。此外,在生成过程中,提出了一种实体感知的分层解码方法以降低时间复杂度。KGT5 [151] 引入了一种新颖的 KGC 模型,满足了这类模型的四个关键要求:可扩展性、质量、多样性和简单性。为了实现这些目标,所提出的模型采用了简单的 T5 小型架构。该模型与以前的 KGC 方法不同,因为它是随机初始化的,而不是使用预训练模型。KG-S2S [152] 是一个综合框架,可应用于各种类型的 KGC 任务,包括静态 KGC、时间 KGC 和小样本 KGC。为实现这一目标,KG-S2S 通过引入一个额外的元素,将标准的三元组 KG 事实重塑为四元组
(
h
,
r
,
t
,
m
)
(h,r,t,m)
(h,r,t,m),其中
m
m
m 代表额外的“条件”元素。虽然不同的 KGC 任务可能涉及不同的条件,但它们通常具有类似的文本格式,这使得在不同的 KGC 任务之间实现统一。KG-S2S 方法结合了各种技术,如实体描述、软提示和 Seq2Seq Dropout,以提高模型的性能。此外,它还利用约束解码确保生成的实体是有效的。对于闭源 LLM(例如 ChatGPT 和 GPT-4),AutoKG 采用提示工程来设计定制提示 [96]。如图 20 所示,这些提示包含任务描述、小样本示例和测试输入,指导 LLM 预测 KG 完成的尾实体。

5.2.3 Comparison between PaE and PaG
5.2.3 PaE和PaG之间的比较
LLMs as Encoders (PaE) applies an additional prediction head on the top of the representation encoded by LLMs.Therefore, the PaE framework is much easier to finetune since we can only optimize the prediction heads and freeze the LLMs. Moreover, the output of the prediction can be easily specified and integrated with existing KGC functions for different KGC tasks. However, during the inference stage, the PaE requires to compute a score for every candidate in KGs, which could be computationally expensive. Besides,they cannot generalize to unseen entities. Furthermore, the PaE requires the representation output of the LLMs, whereas some state-of-the-art LLMs (e.g. GPT-4
1
^1
1) are closed sources and do not grant access to the representation output.
大型语言模型作为编码器(PaE)在 LLM 编码的表示上方添加了一个额外的预测头。因此,PaE 框架更容易进行微调,因为我们只需要优化预测头并冻结 LLM。此外,预测结果可以轻松地指定并与现有 KGC 函数集成,用于不同的 KGC 任务。然而,在推理阶段,PaE 需要为 KG 中的每个候选者计算一个分数,这可能计算开销较大。此外,它们无法推广到未见过的实体。此外,PaE 需要 LLM 的表示输出,而一些最先进的 LLM(例如 GPT-4
1
^1
1)是闭源的,并不允许访问表示输出。
LLMs as Generators (PaG), on the other hand, which does not need the prediction head, can be used without finetuning or access to representations. Therefore, the framework of PaG is suitable for all kinds of LLMs. In addition, PaG directly generates the tail entity, making it efficient in inference without ranking all the candidates and easily generalizing to unseen entities. But, the challenge of PaG is that the generated entities could be diverse and not lie in KGs. What is more, the time of a single inference is longer due to the auto regressive generation. Last, how to design a powerful prompt that feeds KGs into LLMs is still an open question. Consequently, while PaG has demonstrated promising results for KGC tasks, the trade-off between model complexity and computational efficiency must be carefully considered when selecting an appropriate LLM-based KGC framework.
大型语言模型作为生成器(PaG)则不需要预测头,因此无需进行微调或访问表示即可使用。因此,PaG 框架适用于各种类型的 LLM。此外,PaG 直接生成尾实体,使得在无需对所有候选者进行排名的情况下进行推理变得高效,并且容易推广到未见过的实体。但是,PaG 的挑战在于生成的实体可能多样且不在 KG 中。更重要的是,由于自回归生成,单次推理的时间更长。最后,如何设计一个强大的提示,将 KG输入 LLM 仍然是一个开放性问题。因此,尽管 PaG 在 KGC 任务中已经展示了很有前景的结果,但在选择适当的 LLM-based KGC 框架时,必须仔细考虑模型复杂性和计算效率之间的权衡。
5.2.4 Model Analysis
5.2.4 模型分析
Justin et al. [189] provide a comprehensive analysis of KGC methods integrated with LLMs. Their research investigates the quality of LLM embeddings and finds that they are suboptimal for effective entity ranking. In response, they propose several techniques for processing embeddings to improve their suitability for candidate retrieval. The study also compares different model selection dimensions, such as Embedding Extraction, Query Entity Extraction, and Language Model Selection. Lastly, the authors propose a framework that effectively adapts LLM for knowledge graph completion.
Justin等人[189]对LLMs与KGC方法进行了全面的分析。他们的研究调查了LLMs嵌入的质量,并发现它们对于有效的实体排序来说不够理想。为此,他们提出了一些处理嵌入表示以改善其适用性于候选检索的技术。该研究还比较了不同的模型选择维度,例如嵌入提取、查询实体提取和语言模型选择。最后,作者提出了一个有效地将LLMs适应于知识图谱补全的框架。
5.3 LLM-augmented KG Construction
5.3 LLM增强的知识图谱构建
Knowledge graph construction involves creating a structured representation of knowledge within a specific domain.This includes identifying entities and their relationships with each other. The process of knowledge graph construction typically involves multiple stages, including 1) entity discovery, 2) coreference resolution, and 3) relation extraction. Fig 21 presents the general framework of applying LLMs for each stage in KG construction. More recent approaches have explored 4) end-to-end knowledge graph construction, which involves constructing a complete knowledge graph in one step or directly 5) distilling knowledge graphs from LLMs.
知识图谱构建涉及到为特定领域内的知识创建结构化的表示。这包括识别实体以及实体之间的关系。知识图谱构建过程通常涉及多个阶段,包括:实体发现、共指消解和关系提取。图 21 展示了将 LLM 用于知识图谱构建各个阶段的一般框架。近期还有研究探索了端到端知识图谱构建(一步构建出完整的知识图谱)以及直接从 LLM 中蒸馏出知识图谱。

5.3.1 Entity Discovery
5.3.1 实体发现
Entity discovery in KG construction refers to the process of identifying and extracting entities from unstructured data sources, such as text documents, web pages, or social media posts, and incorporating them to construct knowledge graphs.
知识图谱构建中的实体发现是指从非结构化数据源(如文本文档、网页或社交媒体帖子)中识别和提取实体,并将它们纳入构建知识图谱的过程中。
Named Entity Recognition (NER) involves identifying and tagging named entities in text data with their positions and classifications. The named entities include people, organizations, locations, and other types of entities. The state-of-the-art NER methods usually employ LLMs to leverage their contextual understanding and linguistic knowledge for accurate entity recognition and classification. There are three NER sub-tasks based on the types of NER spans identified, i.e., flat NER, nested NER, and discontinuous NER. 1) Flat NER is to identify non-overlapping named entities from input text. It is usually conceptualized as a sequence labelling problem where each token in the text is assigned a unique label based on its position in the sequence [1], [190]-[192]. 2) Nested NER considers complex scenarios which allow a token to belong to multiple entities. The span-based method [193]–[197] is a popular branch of nested NER which involves enumerating all candidate spans and classifying them into entity types (including a non-entity type). Parsing-based methods [198]–[200] reveal similarities between nested NER and constituency parsing tasks (predicting nested and nonoverlapping spans), and propose to integrate the insights of constituency parsing into nested NER. 3) Discontinuous NER identifies named entities that may not be contiguous in the text. To address this challenge, [201] uses the LLM output to identify entity fragments and determine whether they are overlapped or in succession.
命名实体识别(NER)涉及在文本数据中识别和标记命名实体,并确定它们的位置和分类。命名实体包括人物、组织、地点和其他类型的实体。最先进的NER方法通常利用LLM的上下文理解和语言知识来进行准确的实体识别和分类。根据所识别NER跨度的类型,有三种NER子任务,即平坦NER、嵌套NER和不连续NER。1)平坦NER是从输入文本中识别不重叠的命名实体。它通常被概念化为一个序列标注问题,其中文本中的每个标记根据其在序列中的位置被分配一个唯一的标签 [1],[190]–[192]。2)嵌套NER考虑允许一个标记属于多个实体的复杂情况。基于跨度的方法[193]–[197]是嵌套NER的一个流行分支,它涉及枚举所有候选跨度并将它们分类为实体类型(包括非实体类型)。基于解析的方法[198]–[200]揭示了嵌套NER与组成句法分析任务(预测嵌套和不重叠跨度)之间的相似性,并提出将组成句法分析的见解整合到嵌套NER中。3)不连续NER识别在文本中可能不连续的命名实体。为了应对这个挑战,[201]使用LLM输出来识别实体片段,并确定它们是否重叠还是连续的。
Unlike the task-specific methods, GenerativeNER [202] uses a sequence-to-sequence LLM with a pointer mechanism to generate an entity sequence, which is capable of solving all three types of NER sub-tasks.
与特定任务的方法不同,GenerativeNER [202]使用具有指针机制的序列到序列LLM生成实体序列,能够解决这三种类型的NER子任务。
Entity Typing (ET) aims to provide fine-grained and ultra-grained type information for a given entity mentioned in context. These methods usually utilize LLM to encode mentions, context and types. LDET [153] applies pretrained ELMo embeddings [190] for word representation and adopts LSTM as its sentence and mention encoders.BOX4Types [154] recognizes the importance of type dependency and uses BERT to represent the hidden vector and each type in a hyperrectangular (box) space. LRN [155] considers extrinsic and intrinsic dependencies between labels. It encodes the context and entity with BERT and employs these output embeddings to conduct deductive and inductive reasoning. MLMET [203] uses predefined patterns to construct input samples for the BERT MLM and employs [MASK] to predict context-dependent hypernyms of the mention, which can be viewed as type labels. PL [204] and DFET [205] utilize prompt learning for entity typing. LITE [206] formulates entity typing as textual inference and uses RoBERTa-large-MNLI as the backbone network.
实体类型化(ET) 旨在为上下文中给定的实体提供细粒度和超精细的类型信息。这些方法通常利用LLM对提及、上下文和类型进行编码。LDET [153]采用预训练的ELMo嵌入 [190]作为单词表示,并采用LSTM作为句子和提及编码器。BOX4Types [154]认识到类型依赖的重要性,并使用BERT来表示隐藏向量和超矩形(盒状)空间中的每种类型。LRN [155]考虑了标签之间的外在和内在依赖关系。它使用BERT对上下文和实体进行编码,并利用这些输出嵌入进行演绎和归纳推理。MLMET [203]使用预定义的模式构建BERT MLM的输入样本,并使用[MASK]来预测提及的上下文相关的上位词,可以视为类型标签。PL [204]和DFET [205]利用提示学习进行实体类型化。LITE [206]将实体类型化形式化为文本推理,并使用RoBERTa-large-MNLI作为主干网络。
Entity Linking (EL), as known as entity disambiguation, involves linking entity mentions appearing in the text to their corresponding entities in a knowledge graph. [207] proposed BERT-based end-to-end EL systems that jointly discover and link entities. ELQ [208] employs a fast biencoder architecture to jointly perform mention detection and linking in one pass for downstream question answering systems. Unlike previous models that frame EL as matching in vector space, GENRE [209] formulates it as a sequence-tosequence problem, autoregressively generating a version of the input markup-annotated with the unique identifiers of an entity expressed in natural language. GENRE is extended to its multilingual version mGENRE [210]. Considering the efficiency challenges of generative EL approaches, [211] parallelizes autoregressive linking across all potential mentions and relies on a shallow and efficient decoder. ReFinED [212] proposes an efficient zero-shot-capable EL approach by taking advantage of fine-grained entity types and entity descriptions which are processed by a LLM-based encoder.
实体链接(EL),也称为实体消岐,涉及将文本中出现的实体提及链接到知识图谱中的相应实体。[207]提出了基于BERT的端到端EL系统,共同发现和链接实体。ELQ [208]采用快速双编码器架构,在一次通过中同时执行提及检测和链接,用于下游的问答系统。与将EL框架为向量空间匹配的先前模型不同,GENRE [209]将其构建为一个序列到序列问题,自动地生成一个标记了实体在自然语言中的唯一标识的输入标记。GENRE被扩展为多语言版本mGENRE [210]。考虑到生成EL方法的效率挑战,[211]将自回归链接并行化到所有潜在提及中,并依赖一个浅层和高效的解码器。ReFinED [212]提出了一种高效的零样本EL方法,利用细粒度实体类型和实体描述,通过基于LLM的编码器进行处理。
5.3.2 Coreference Resolution (CR)
5.3.2 共指消解(CR)
Coreference resolution is to find all expressions (i.e., mentions) that refer to the same entity or event in a text.
共指消解是在文本中查找所有指称(即提及),这些指称指代同一实体或事件的过程。
Within-document CR refers to the CR sub-task where all these mentions are in a single document. Mandar et al. [157] initialize LLM-based coreferences resolution by replacing the previous LSTM encoder [213] with BERT. This work is
followed by the introduction of SpanBERT [158] which is pre-trained on BERT architecture with a span-based masked language model (MLM). Inspired by these works, Tuan Manh et al. [214] present a strong baseline by incorporating the SpanBERT encoder into a non-LLM approach e2e-coref [213]. CorefBERT leverages Mention Reference Prediction (MRP) task which masks one or several mentions and requires the model to predict the masked mention’s corresponding referents. CorefQA [215] formulates coreference resolution as a question answering task, where contextual queries are generated for each candidate mention and the coreferent spans are extracted from the document using the queries. Tuan Manh et al. [216] introduce a gating mechanism and a noisy training method to extract information from event mentions using the SpanBERT encoder.
文档内共指消解指的是所有这些指称都在单个文档中的CR子任务。Mandar等人 [157]通过将之前的LSTM编码器 [213]替换为BERT来初始化LLM的共指消解。这项工作之后出现了SpanBERT [158],它是在BERT架构上进行预训练的,采用了基于跨度的屏蔽语言模型(MLM)。受到这些工作的启发,Tuan Manh等人 [214]通过将SpanBERT编码器纳入非LLM方法e2e-coref [213]中,提出了一个强大的基准模型。CorefBERT利用提及参考预测(MRP)任务,对一个或多个提及进行掩码,并要求模型预测被屏蔽提及的对应指代。CorefQA [215]将共指消解形式化为一个问答任务,为每个候选提及生成上下文查询,并使用查询从文档中提取出共指跨度。Tuan Manh等人 [216]引入了一个门控机制和一个噪声训练方法,利用SpanBERT编码器从事件提及中提取信息。
In order to reduce the large memory footprint faced by large LLM-based NER models, Yuval et al. [217] and Raghuveer el al. [218] proposed start-to-end and approximation models, respectively, both utilizing bilinear functions to calculate mention and antecedent scores with reduced reliance on span-level representations.
为了减少大型LLM-based NER模型面临的大内存开销,Yuval等人 [217]和Raghuveer等人 [218]分别提出了端到端和近似模型,两者都利用双线性函数计算提及和先行指代得分,并减少对跨度级表示的依赖。
Cross-document CR refers to the sub-task where the mentions refer to the same entity or event might be across multiple documents. CDML [159] proposes a cross document language modeling method which pre-trains a Longformer [219] encoder on concatenated related documents and employs an MLP for binary classification to determine whether a pair of mentions is coreferent or not. CrossCR [160] utilizes an end-to-end model for cross-document coreference resolution which pre-trained the mention scorer on gold mention spans and uses a pairwise scorer to compare mentions with all spans across all documents. CR-RL [161] proposes an actor-critic deep reinforcement learning-based coreference resolver for cross-document CR.
跨文档共指消解是指涉及跨多个文档的提及指代同一实体或事件的子任务。CDML [159]提出了一种跨文档语言建模方法,该方法在相关文档上预训练了一个Longformer [219]编码器,并使用MLP进行二元分类,以确定一对提及是否是共指的。CrossCR [160]利用端到端模型进行跨文档共指消解,该模型在黄金提及跨度上进行预训练,使用成对的评分器比较跨所有文档的所有跨度与提及。CR-RL [161]提出了一种基于演员-评论家深度强化学习的跨文档共指消解方法。
5.3.3 Relation Extraction (RE)
5.3.3 关系抽取(RE)
Relation extraction involves identifying semantic relationships between entities mentioned in natural language text.There are two types of relation extraction methods, i.e. sentence-level RE and document-level RE, according to the scope of the text analyzed.
关系抽取涉及识别自然语言文本中提及的实体之间的语义关系。根据分析的文本范围,关系抽取方法分为两种类型:句子级关系抽取和文档级关系抽取。
Sentence-level RE focuses on identifying relations between entities within a single sentence. Peng et al. [162] and TRE [220] introduce LLM to improve the performance of relation extraction models. BERT-MTB [221] learns relation representations based on BERT by performing the matching-the-blanks task and incorporating designed objectives for
relation extraction. Curriculum-RE [163] utilizes curriculum learning to improve relation extraction models by gradually increasing the difficulty of the data during training. RECENT [222] introduces SpanBERT and exploits entity type restriction to reduce the noisy candidate relation types.Jiewen [223] extends RECENT by combining both the entity information and the label information into sentence-level embeddings, which enables the embedding to be entity-label aware.
句子级关系抽取专注于识别单个句子内实体之间的关系。Peng等人 [162]和TRE [220]引入LLM来提高关系抽取模型的性能。BERT-MTB [221]通过执行匹配空白任务并结合为关系抽取设计的目标,在BERT的基础上学习关系表示。Curriculum-RE [163]利用课程学习来改进关系抽取模型,在训练过程中逐渐增加数据的难度。RECENT [222]引入了SpanBERT,并利用实体类型限制来减少噪声候选关系类型。Jiewen [223]通过将实体信息和标签信息合并到句子级嵌入中,扩展了RECENT,使得嵌入能够意识到实体和标签。
Document-level RE (DocRE) aims to extract relations between entities across multiple sentences within a document. Hong et al. [224] propose a strong baseline for DocRE by replacing the BiLSTM backbone with LLMs. HIN [225] use LLM to encode and aggregate entity representation at different levels, including entity, sentence, and document levels. GLRE [226] is a global-to-local network, which uses LLM to encode the document information in terms of entity global and local representations as well as context relation representations. SIRE [227] uses two LLM-based encoders to extract intra-sentence and inter-sentence relations. LSR [228] and GAIN [229] propose graph-based approaches which induce graph structures on top of LLM to better extract relations. DocuNet [230] formulates DocRE as a semantic segmentation task and introduces a U-Net [231] on the LLM encoder to capture local and global dependencies between entities. ATLOP [232] focuses on the multi-label problems in DocRE, which could be handled with two techniques,i.e., adaptive thresholding for classifier and localized context pooling for LLM. DREEAM [164] further extends and improves ATLOP by incorporating evidence information.
文档级关系抽取(DocRE) 旨在提取文档内多个句子之间实体之间的关系。Hong等人 [224]通过将BiLSTM主干替换为LLM,提出了DocRE的一个强大基准模型。HIN [225]使用LLM对实体在不同级别(包括实体、句子和文档级别)上的表示进行编码和聚合。GLRE [226]是一个全局到局部网络,使用LLM对文档信息进行编码,以实体的全局和局部表示以及上下文关系表示的形式。SIRE [227]使用两个基于LLM的编码器来提取句内和句间关系。LSR [228]和GAIN [229]提出了基于图的方法,在LLM上引入图结构,以更好地提取关系。DocuNet [230]将DocRE定义为一个语义分割任务,并在LLM编码器上引入U-Net [231],以捕捉实体之间的局部和全局依赖关系。ATLOP [232]关注DocRE中的多标签问题,可以通过两种技术处理,即用于分类器的自适应阈值和用于LLM的局部上下文汇集。DREEAM [164]通过引入证据信息进一步扩展和改进了ATLOP。
5.3.4 End-to-End KG Construction
5.3.4 端到端的知识图谱构建
Currently, researchers are exploring the use of LLMs for end-to-end KG construction. Kumar et al. [98] propose a unified approach to build KGs from raw text, which contains two LLMs powered components. They first finetune a LLM on named entity recognition tasks to make it capable of recognizing entities in raw text. Then, they propose another “2-model BERT” for solving the relation extraction task, which contains two BERT-based classifiers. The first classifier learns the relation class whereas the second binary classifier learns the direction of the relations between the two entities. The predicted triples and relations are then used to construct the KG. Guo et al. [165] propose an end-to-end knowledge extraction model based on BERT, which can be applied to construct KGs from Classical Chinese text. Grapher [41] presents a novel end-to-end multi-stage system. It first utilizes LLMs to generate KG entities, followed by a simple relation construction head, enabling efficient KG construction from the textual description. PiVE [166] proposes a prompting with an iterative verification framework that utilizes a smaller LLM like T5 to correct the errors in KGs generated by a larger LLM (e.g., ChatGPT). To further explore advanced LLMs, AutoKG design several prompts for different KG construction tasks (e.g., entity typing, entity linking, and relation extraction). Then, it adopts the prompt to perform KG construction using ChatGPT and GPT-4.
目前,研究人员正在探索使用LLM进行端到端的知识图谱构建。Kumar等人 [98]提出了一种从原始文本构建知识图谱的统一方法,该方法包含两个由LLM驱动的组件。他们首先在命名实体识别任务上微调LLM,使其能够识别原始文本中的实体。然后,他们提出了另一个用于解决关系抽取任务的“2模型BERT”,其中包含两个基于BERT的分类器。第一个分类器学习关系类别,而第二个二元分类器学习两个实体之间关系的方向。预测的三元组和关系用于构建知识图谱。Guo等人 [165]提出了一种基于BERT的端到端知识抽取模型,可用于从古代汉语文本中构建知识图谱。Grapher [41]提出了一种新颖的端到端多阶段系统。它首先利用LLM生成知识图谱实体,然后使用简单的关系构建头部,从文本描述中有效地构建知识图谱。PiVE [166]提出了一个使用小型LLM(例如T5)进行提示和迭代验证的框架,用于纠正由更大的LLM(如ChatGPT)生成的知识图谱中的错误。为了进一步探索先进的LLM,AutoKG为不同的知识图谱构建任务(如实体类型化、实体链接和关系抽取)设计了几个提示,并使用ChatGPT和GPT-4执行知识图谱构建。
5.3.5 Distilling Knowledge Graphs from LLMs
5.3.5 从LLM中提炼知识图谱
LLMs have been shown to implicitly encode massive knowledge [14]. As shown in Fig. 22, some research aims to distill knowledge from LLMs to construct KGs. COMET [167] proposes a commonsense transformer model that constructs
commonsense KGs by using existing tuples as a seed set of knowledge on which to train. Using this seed set, a LLM learns to adapt its learned representations to knowledge generation, and produces novel tuples that are high quality. Experimental results reveal that implicit knowledge from LLMs is transferred to generate explicit knowledge in commonsense KGs. BertNet [168] proposes a novel framework for automatic KG construction empowered by LLMs. It requires only the minimal definition of relations as inputs and automatically generates diverse prompts, and performs an efficient knowledge search within a given LLM for consistent outputs. The constructed KGs show competitive quality,diversity, and novelty with a richer set of new and complex relations, which cannot be extracted by previous methods.West et al. [169] propose a symbolic knowledge distillation framework that distills symbolic knowledge from LLMs.They first finetune a small student LLM by distilling commonsense facts from a large LLM like GPT-3. Then, the student LLM is utilized to generate commonsense KGs.
已经证明,LLM可以隐式地编码大量的知识 [14]。如图22所示,一些研究旨在从LLM中提取知识以构建知识图谱。COMET [167]提出了一种常识变换器模型,通过使用现有元组作为知识的种子集进行训练,构建常识知识图谱。使用这个种子集,LLM学习将其学习到的表示适应于知识生成,并产生高质量的新元组。实验结果表明,LLM中的隐式知识转移到常识知识图谱中生成显式知识。BertNet [168]提出了一种基于LLM的自动知识图谱构建框架。它仅需要关系的最小定义作为输入,并自动生成多样的提示,在给定的LLM中进行有效的知识搜索,以获得一致的输出。构建的知识图谱具有竞争力的质量、多样性和新颖性,具有更丰富的新的复杂关系集合,这些关系无法通过先前的方法提取。West等人 [169]提出了一种从LLM中提取符号知识的符号知识蒸馏框架。他们首先通过从像GPT-3这样的大型LLM中提取常识事实,来微调一个较小的学生LLM。然后,利用学生LLM生成常识知识图谱。

5.4 LLM-augmented KG-to-text Generation
5.4 LLM增强的知识图谱生成文本
The goal of Knowledge-graph-to-text (KG-to-text) generation is to generate high-quality texts that accurately and consistently describe the input knowledge graph information [233]. KG-to-text generation connects knowledge graphs and texts, significantly improving the applicability of KG in more realistic NLG scenarios, including storytelling [234] and knowledge-grounded dialogue [235]. However, it is challenging and costly to collect large amounts of graph-text parallel data, resulting in insufficient training and poor generation quality. Thus, many research efforts resort to either: 1) leverage knowledge from LLMs or 2) construct large-scale weakly-supervised KG-text corpus to solve this issue.
知识图谱到文本(KG-to-text)生成的目标是生成高质量的文本,准确且一致地描述输入的知识图谱信息 [233]。KG-to-text 生成将知识图谱和文本联系起来,显著提高了知识图谱在更具实际意义的自然语言生成(NLG)场景中的适用性,包括故事讲述 [234] 和基于知识的对话 [235]。然而,收集大量的图谱 - 文本平行数据是具有挑战性和成本高的,导致训练不足和生成质量差。因此,许多研究工作采取以下两种方法之一:1)利用 LLM 中的知识;2)构建大规模弱监督 KG-text 语料库来解决这个问题。
5.4.1 Leveraging Knowledge from LLMs
5.4.1 利用LLM的知识
As pioneering research efforts in using LLMs for KG-to-Text generation, Ribeiro et al. [170] and Kale and Rastogi [236] directly fine-tune various LLMs, including BART and T5,with the goal of transferring LLMs knowledge for this task. As shown in Fig. 23, both works simply represent the input graph as a linear traversal and find that such a naive approach successfully outperforms many existing state-of-the-art KG-to-text generation systems. Interestingly,Ribeiro et al. [170] also find that continue pre-training could further improve model performance. However, these methods are unable to explicitly incorporate rich graph semantics in KGs. To enhance LLMs with KG structure information,JointGT [42] proposes to inject KG structure-preserving representations into the Seq2Seq large language models.Given input sub-KGs and corresponding text, JointGT first represents the KG entities and their relations as a sequence of tokens, then concatenate them with the textual tokens which are fed into LLM. After the standard self-attention module, JointGT then uses a pooling layer to obtain the contextual semantic representations of knowledge entities and relations. Finally, these pooled KG representations are then aggregated in another structure-aware self-attention layer. JointGT also deploys additional pre-training objectives, including KG and text reconstruction tasks given masked inputs, to improve the alignment between text and graph information. Li et al. [171] focus on the few-shot scenario. It first employs a novel breadth-first search (BFS) strategy to better traverse the input KG structure and feed the enhanced linearized graph representations into LLMs for high-quality generated outputs, then aligns the GCN-based and LLM-based KG entity representation. Colas et al. [172] first transform the graph into its appropriate representation before linearizing the graph. Next, each KG node is encoded via a global attention mechanism, followed by a graph-aware attention module, ultimately being decoded into a sequence of tokens. Different from these works, KG-BART [37] keeps the structure of KGs and leverages the graph attention to aggregate the rich concept semantics in the sub-KG, which enhances the model generalization on unseen concept sets.
作为在KG-to-Text生成中使用LLM的开创性研究工作,Ribeiro等人[170]和Kale和Rastogi [236]直接对多种LLM进行微调,包括BART和T5,目的是将LLM的知识转移到这个任务上。如图23所示,这两项工作将输入的图形简单表示为线性遍历,并发现这种简单的方法成功地超过了许多现有的最先进的KG-to-text生成系统。有趣的是,Ribeiro等人[170]还发现继续预训练可以进一步提高模型的性能。然而,这些方法无法明确地将丰富的图形语义纳入到KG中。为了增强LLM的KG结构信息,JointGT [42]提出在Seq2Seq大型语言模型中注入保持KG结构的表示。给定输入的子KG和相应的文本,JointGT首先将KG实体和它们的关系表示为一系列标记,然后将它们与输入LLM的文本标记连接在一起。在标准的自注意模块之后,JointGT使用汇聚层获得知识实体和关系的上下文语义表示。最后,这些汇聚的KG表示在另一个结构感知的自注意层中进行聚合。JointGT还使用额外的预训练目标,包括在给定掩码输入的情况下进行KG和文本重构任务,以改善文本和图形信息之间的对齐。李等人[171]专注于少样本场景。它首先采用一种新颖的广度优先搜索(BFS)策略来更好地遍历输入的KG结构,并将增强的线性化图形表示馈送到LLM中以生成高质量的输出,然后对齐基于GCN和LLM的KG实体表示。Colas等人[172]首先将图形转换为适当的表示形式,然后对每个KG节点进行全局注意机制的编码,接着是图形感知注意模块,最后解码为标记序列。与这些工作不同,KG-BART [37]保留了KG的结构,并利用图形注意力来聚合子KG中丰富的概念语义,增强了模型在未见过的概念集上的泛化能力。

5.4.2 Constructing large weakly KG-text aligned Corpus
5.4.2 构建大规模弱监督KG-text对齐语料库
Although LLMs have achieved remarkable empirical success, their unsupervised pre-training objectives are not necessarily aligned well with the task of KG-to-text generation, motivating researchers to develop large-scale KG-text aligned corpus. Jin et al. [173] propose a 1.3M unsupervised KG-to-graph training data from Wikipedia. Specifically, they first detect the entities appearing in the text via hyperlinks and named entity detectors, and then only add text that shares a common set of entities with the corresponding knowledge graph, similar to the idea of distance supervision in the relation extraction task [237]. They also provide a 1,000+ human annotated KG-to-Text test data to verify the effectiveness of the pre-trained KG-to-Text models. Similarly, Chen et al. [174] also propose a KG-grounded text corpus collected from the English Wikidump. To ensure the connection between KG and text, they only extract sentences with at least two Wikipedia anchor links. Then, they use the entities from those links to query their surrounding neighbors in WikiData and calculate the lexical overlapping between these neighbors and the original sentences. Finally, only highly overlapped pairs are selected. The authors explore both graph-based and sequence-based encoders and identify their advantages in various different tasks and settings.
尽管LLM在实证方面取得了显著的成功,但它们的无监督预训练目标未必与KG-to-text生成任务很好地对齐,这促使研究人员开发大规模的KG-text对齐语料库。Jin等人[173]提出了一个从维基百科中无监督获取的130万个KG-to-graph训练数据。具体而言,他们首先通过超链接和命名实体检测器检测出文本中出现的实体,然后只添加与相应知识图谱共享一组实体的文本,类似于关系抽取任务中的距离监督思想[237]。他们还提供了1000多个人工注释的KG-to-Text测试数据,以验证预训练的KG-to-Text模型的有效性。类似地,Chen等人[174]还提出了从英文维基转储中收集的KG驱动文本语料库。为了确保KG和文本之间的关联,他们仅提取至少包含两个维基百科锚文本链接的句子。然后,他们使用这些链接中的实体在WikiData中查询它们周围的邻居,并计算这些邻居与原始句子之间的词汇重叠。最后,只有高度重叠的配对被选中。作者探索了基于图形和序列的编码器,并确定它们在不同任务和设置中的优势。
5.5 LLM-augmented KG Question Answering
5.5 LLM增强的KG问答
Knowledge graph question answering (KGQA) aims to find answers to natural language questions based on the structured facts stored in knowledge graphs [238], [239]. The inevitable challenge in KGQA is to retrieve related facts and extend the reasoning advantage of KGs to QA. Therefore,recent studies adopt LLMs to bridge the gap between natural language questions and structured knowledge graphs[177], [178], [240]. The general framework of applying LLMs for KGQA is illustrated in Fig. 24, where LLMs can be used as 1) entity/relation extractors, and 2) answer reasoners.
知识图谱问答(KGQA)的目标是根据知识图谱中存储的结构化事实,找到自然语言问题的答案[238],[239]。KGQA的不可避免的挑战是检索相关事实并将KG的推理优势扩展到问答中。因此,最近的研究采用LLM来弥合自然语言问题和结构化知识图谱之间的差距[177],[178],[240]。应用LLM进行KGQA的通用框架如图24所示,LLM可以用作1) 实体/关系提取器和2) 答案推理器。

5.5.1 LLMs as Entity/relation Extractors
5.5.1 LLM作为实体/关系提取器
Entity/relation extractors are designed to identify entities and relationships mentioned in natural language questions and retrieve related facts in KGs. Given the proficiency in language comprehension, LLMs can be effectively utilized for this purpose. Lukovnikov et al. [176] are the first to utilize LLMs as classifiers for relation prediction, resulting in a notable improvement in performance compared to shallow neural networks. Nan et al. [177] introduce two LLM-based KGQA frameworks that adopt LLMs to detect mentioned entities and relations. Then, they query the answer in KGs using the extracted entity-relation pairs. QA-GNN [118] uses LLMs to encode the question and candidate answer pairs, which are adopted to estimate the importance of relative KG entities. The entities are retrieved to form a subgraph, where an answer reasoning is conducted by a graph neural network. Luo et al. [175] use LLMs to calculate the similarities between relations and questions to retrieve related facts, formulated as
s
(
r
,
q
)
=
L
L
M
(
r
)
⊤
L
L
M
(
q
)
,
(12)
s(r, q) = LLM(r)^⊤LLM(q), \tag{12}
s(r,q)=LLM(r)⊤LLM(q),(12)
where
q
q
q denotes the question,
r
r
r denotes the relation, and
L
L
M
(
⋅
)
LLM(·)
LLM(⋅) would generate representation for
q
q
q and
r
r
r, respectively. Furthermore, Zhang et al. [241] propose a LLM-based path retriever to retrieve question-related relations hop-by-hop and construct several paths. The probability of each path can be calculated as
P
(
p
∣
q
)
=
∏
t
=
1
∣
p
∣
s
(
r
t
,
q
)
,
(13)
P(p|q) = \prod^{|p|}_{t=1}s(r_t, q), \tag{13}
P(p∣q)=t=1∏∣p∣s(rt,q),(13)
where
p
p
p denotes the path, and
r
t
r_t
rt denotes the relation at the
t
t
t-th hop of
p
p
p. The retrieved relations and paths can be used as context knowledge to improve the performance of answer reasoners as
P
(
a
∣
q
)
=
∑
p
∈
P
P
(
a
∣
p
)
P
(
p
∣
q
)
,
(14)
P(a|q) = \sum_{p∈P} P(a|p)P(p|q), \tag{14}
P(a∣q)=p∈P∑P(a∣p)P(p∣q),(14)
where
P
P
P denotes retrieved paths and a denotes the answer.
实体/关系提取器旨在识别自然语言问题中提及的实体和关系,并检索与之相关的事实。鉴于LLM在语言理解方面的熟练度,可以有效地利用LLM来实现这一目的。Lukovnikov等人[176]是第一个将LLM用作关系预测分类器的研究,与浅层神经网络相比,性能有了显著提高。Nan等人[177]介绍了两个基于LLM的KGQA框架,采用LLM来检测提及的实体和关系,然后使用提取的实体-关系对在KG中查询答案。QA-GNN [118]使用LLM对问题和候选答案对进行编码,以估计相关KG实体的重要性。检索到的实体用于构建子图,在此基础上,图神经网络进行答案推理。Luo等人[175]使用LLM计算关系和问题之间的相似度,以检索相关事实,形式化为
s
(
r
,
q
)
=
L
L
M
(
r
)
⊤
L
L
M
(
q
)
,
(12)
s(r, q) = LLM(r)^⊤LLM(q), \tag{12}
s(r,q)=LLM(r)⊤LLM(q),(12)
其中
q
q
q表示问题,
r
r
r表示关系,
L
L
M
(
⋅
)
LLM(·)
LLM(⋅)分别为
q
q
q和
r
r
r生成表示。此外,Zhang等人[241]提出了一种基于LLM的路径检索器,逐跳检索与问题相关的关系,并构建多条路径。每条路径的概率可以计算为
P
(
p
∣
q
)
=
∏
t
=
1
∣
p
∣
s
(
r
t
,
q
)
,
(13)
P(p|q) = \prod^{|p|}_{t=1}s(r_t, q), \tag{13}
P(p∣q)=t=1∏∣p∣s(rt,q),(13)
其中
p
p
p表示路径,
r
t
r_t
rt表示路径的第
t
t
t跳关系。检索到的关系和路径可以用作上下文知识,以改善答案推理器的性能,如下所示
P
(
a
∣
q
)
=
∑
p
∈
P
P
(
a
∣
p
)
P
(
p
∣
q
)
,
(14)
P(a|q) = \sum_{p∈P} P(a|p)P(p|q), \tag{14}
P(a∣q)=p∈P∑P(a∣p)P(p∣q),(14)
其中
P
P
P表示检索到的路径,
a
a
a表示答案。
5.5.2 LLMs as Answer Reasoners
5.5.2 LLM作为答案推理器
Answer reasoners are designed to reason over the retrieved facts and generate answers. LLMs can be used as answer reasoners to generate answers directly. For example, as shown in Fig. 3 24, DEKCOR [178] concatenates the retrieved facts with questions and candidate answers as
x
=
[
C
L
S
]
q
[
S
E
P
]
R
e
l
a
t
e
d
F
a
c
t
s
[
S
E
P
]
a
[
S
E
P
]
,
(15)
x = [CLS]\ \ q\ \ [SEP]\ \ Related\ \ Facts\ \ [SEP]\ \ a\ \ [SEP], \tag{15}
x=[CLS] q [SEP] Related Facts [SEP] a [SEP],(15)
where
a
a
a denotes candidate answers. Then, it feeds them into LLMs to predict answer scores. After utilizing LLMs to generate the representation of
x
x
x as QA context, DRLK [179] proposes a Dynamic Hierarchical Reasoner to capture the interactions between QA context and answers for answer prediction. Yan et al. [240] propose a LLM-based KGQA framework consisting of two stages: (1) retrieve related facts from KGs and (2) generate answers based on the retrieved facts. The first stage is similar to the entity/relation
extractors. Given a candidate answer entity a, it extracts a series of paths
p
1
,
.
.
.
,
p
n
p_1, . . . , p_n
p1,...,pn from KGs. But the second stage is a LLM-based answer reasoner. It first verbalizes the paths by using the entity names and relation names in KGs. Then, it concatenates the question
q
q
q and all paths
p
1
,
.
.
.
,
p
n
p_1, . . . , p_n
p1,...,pn to make an input sample as
x
=
[
C
L
S
]
q
[
S
E
P
]
p
1
[
S
E
P
]
⋅
⋅
⋅
[
S
E
P
]
p
n
[
S
E
P
]
.
(16)
x = [CLS]\ \ q\ \ [SEP]\ \ p_1\ \ [SEP]\ \ · · ·\ \ [SEP]\ \ p_n\ \ [SEP]. \tag{16}
x=[CLS] q [SEP] p1 [SEP] ⋅⋅⋅ [SEP] pn [SEP].(16)
These paths are regarded as the related facts for the candidate answer
a
a
a. Finally, it uses LLMs to predict whether the hypothesis: “
a
a
a is the answer of
q
q
q” is supported by those facts, which is formulated as
e
[
C
L
S
]
=
L
L
M
(
x
)
,
(17)
e_{[CLS]} = LLM(x), \tag{17}
e[CLS]=LLM(x),(17)
s
=
σ
(
M
L
P
(
e
[
C
L
S
]
)
)
,
(18)
s = σ(MLP(e_{[CLS]})), \tag{18}
s=σ(MLP(e[CLS])),(18)
where it encodes
x
x
x using a LLM and feeds representation corresponding to
[
C
L
S
]
[CLS]
[CLS] token for binary classification, and
σ
(
⋅
)
σ(·)
σ(⋅) denotes the sigmoid function.
答案推理器旨在对检索到的事实进行推理并生成答案。LLM可以作为答案推理器直接生成答案。例如,如图24所示,DEKCOR [178]将检索到的事实与问题和候选答案连接起来,形成如下输入
x
=
[
C
L
S
]
q
[
S
E
P
]
R
e
l
a
t
e
d
F
a
c
t
s
[
S
E
P
]
a
[
S
E
P
]
,
(15)
x = [CLS]\ \ q\ \ [SEP]\ \ Related\ \ Facts\ \ [SEP]\ \ a\ \ [SEP], \tag{15}
x=[CLS] q [SEP] Related Facts [SEP] a [SEP],(15)
其中
a
a
a表示候选答案。然后将它们输入LLM进行答案得分的预测。在使用LLM生成
x
x
x的QA上下文表示后,DRLK [179]提出了一个动态分层推理器来捕捉QA上下文和答案之间的交互,以进行答案预测。Yan等人[240]提出了一个基于LLM的KGQA框架,包括两个阶段:(1)从KG中检索相关事实,(2)根据检索到的事实生成答案。第一阶段类似于实体/关系提取器。给定一个候选答案实体
a
a
a,它从KG中提取一系列路径
p
1
,
.
.
.
,
p
n
p_1,...,p_n
p1,...,pn。但是第二阶段是基于LLM的答案推理器。它首先使用KG中的实体名称和关系名称来表达路径。然后,它将问题
q
q
q和所有路径
p
1
,
.
.
.
,
p
n
p_1,...,p_n
p1,...,pn连接在一起,形成输入样本
x
=
[
C
L
S
]
q
[
S
E
P
]
p
1
[
S
E
P
]
⋅
⋅
⋅
[
S
E
P
]
p
n
[
S
E
P
]
.
(16)
x = [CLS]\ \ q\ \ [SEP]\ \ p_1\ \ [SEP]\ \ · · ·\ \ [SEP]\ \ p_n\ \ [SEP]. \tag{16}
x=[CLS] q [SEP] p1 [SEP] ⋅⋅⋅ [SEP] pn [SEP].(16)
这些路径被视为候选答案
a
a
a的相关事实。最后,它使用LLM预测假设:“
a
a
a是
q
q
q的答案”的支持度,即
e
[
C
L
S
]
=
L
L
M
(
x
)
,
(17)
e_{[CLS]} = LLM(x), \tag{17}
e[CLS]=LLM(x),(17)
s
=
σ
(
M
L
P
(
e
[
C
L
S
]
)
)
,
(18)
s = σ(MLP(e_{[CLS]})), \tag{18}
s=σ(MLP(e[CLS])),(18)
其中LLM对
x
x
x进行编码,并将与
[
C
L
S
]
[CLS]
[CLS]标记对应的表示输入进行二元分类,
σ
(
⋅
)
σ(·)
σ(⋅)表示sigmoid函数。
To better guide LLMs reason through KGs, OreoLM [180] proposes a Knowledge Interaction Layer (KIL) which is inserted amid LLM layers. KIL interacts with a KG reasoning module, where it discovers different reasoning paths, and then the reasoning module can reason over the paths to generate answers. GreaseLM [120] fuses the representations from LLMs and graph neural networks to effectively reason over KG facts and language context. UniKGQA [43] unifies the facts retrieval and reasoning into a unified framework.UniKGQA consists of two modules. The first module is a semantic matching module that uses a LLM to match questions with their corresponding relations semantically.The second module is a matching information propagation module, which propagates the matching information along directed edges on KGs for answer reasoning. Similarly, ReLMKG [181] performs joint reasoning on a large language model and the associated knowledge graph. The question and verbalized paths are encoded by the language model, and different layers of the language model produce outputs that guide a graph neural network to perform message passing. This process utilizes the explicit knowledge contained in the structured knowledge graph for reasoning purposes.StructGPT [242] adopts a customized interface to allow large language models (e.g., ChatGPT) directly reasoning on KGs to perform multi-step question answering.
为了更好地引导LLM在KG上进行推理,OreoLM [180]提出了一个知识交互层(KIL),插入在LLM层之间。KIL与KG推理模块交互,它发现不同的推理路径,然后推理模块可以在路径上进行推理以生成答案。GreaseLM [120]将LLM和图神经网络的表示融合起来,以有效地在KG事实和语言上下文中进行推理。UniKGQA [43]将事实检索和推理统一到一个框架中。UniKGQA由两个模块组成。第一个模块是语义匹配模块,使用LLM在语义上匹配问题和相应的关系。第二个模块是匹配信息传播模块,它在KG上沿着有向边传播匹配信息,用于答案推理。类似地,ReLMKG [181]在大型语言模型和相关知识图谱上进行联合推理。语言模型对问题和语言路径进行编码,语言模型的不同层产生的输出指导图神经网络进行消息传递。这个过程利用结构化知识图谱中包含的显式知识进行推理。StructGPT [242]采用定制的接口,允许大型语言模型(如ChatGPT)直接在KG上进行推理,进行多步问题回答。
6 SYNERGIZED LLMS + KGS
6 LLM与KG的协同
The synergy of LLMs and KGs has attracted increasing attention these years, which marries the merits of LLMs and KGs to mutually enhance performance in various downstream applications. For example, LLMs can be used to understand natural language, while KGs are treated as a knowledge base, which provides factual knowledge. The unification of LLMs and KGs could result in a powerful model for knowledge representation and reasoning. In this section, we will discuss the Synergized LLMs + KGs from two perspectives: 1) knowledge representation, and 2) reasoning. We have summarized the representative works in Table 4.
LLM 与知识图谱协同近年来赢得了不少关注,该方法能将 LLM 和知识图谱的优点融合,从而更好地应对各种下游任务。举个例子,LLM 可用于理解自然语言,同时知识图谱可作为提供事实知识的知识库。将 LLM 和知识图谱联合起来可以造就执行知识表征和推理的强大模型。这里从两个方面关注了 LLM 与知识图谱协同:知识表征、推理。表 4 总结了代表性的研究工作。

6.1 Knowledge Representation
6.1 知识表示
Text corpus and knowledge graphs both contain enormous knowledge. However, the knowledge in the text corpus is usually implicit and unstructured, while the knowledge in KGs is explicit and structured. Therefore, it is necessary to align the knowledge in the text corpus and KGs to represent them in a unified way. The general framework of unifying LLMs and KGs for knowledge representation is shown in Fig. 25.
文本语料库和知识图谱都包含了大量的知识。然而,文本语料库中的知识通常是隐含且无结构的,而知识图谱中的知识则是显式且有结构的。因此,有必要将文本语料库和知识图谱中的知识进行对齐,以统一地表示它们。将LLM和KG统一起来进行知识表示的一般框架如图25所示。

KEPLER [40] presents a unified model for knowledge embedding and pre-trained language representation. In KEPLER, they encode textual entity descriptions with a LLM as their embeddings, and then jointly optimize the knowledge embedding and language modeling objectives. JointGT [42] proposes a graph-text joint representation learning model, which proposes three pre-training tasks to align representations of graph and text. DRAGON [44] presents a self-supervised method to pre-train a joint language-knowledge foundation model from text and KG. It takes text segments and relevant KG subgraphs as input and bidirectionally fuses information from both modalities. Then, DRAGON utilizes two self-supervised reasoning tasks, i.e., masked language modeling and KG link prediction to optimize the model parameters. HKLM [243] introduces a unified LLM which incorporates KGs to learn representations of domain-specific knowledge.
KEPLER 是一种用于知识嵌入和预训练语言表示的统一模型。KEPLER 会使用 LLM 将文本实体描述编码成它们的嵌入,然后对知识嵌入和语言建模目标进行联合优化。JointGT 提出了一种知识图谱 - 文本联合表示学习模型,其中提出了三个预训练任务来对齐知识图谱和文本的表示。DRAGON 则给出了一种自监督方法,可以基于文本和知识图谱来预训练一个语言 - 知识的联合基础模型。其输入是文本片段和相关的知识图谱子图,并会双向融合来自这两种模式的信息。然后,DRAGON 会利用两个自监督推理任务(掩码语言建模和知识图谱链接预测)来优化该模型的参数。HKLM 则引入了一种联合 LLM,其整合了知识图谱来学习特定领域知识的表示。
6.2 Reasoning
6.2 推理
To take advantage of both LLMs and KGs, researchers synergize LLMs and KGs to perform reasoning on various applications. In the question answering task, QA-GNN [118] first utilizes LLMs to process the text question and guide the reasoning step on the KGs. In this way, it can bridge the gap between text and structural information, which provides interpretability for the reasoning process. In the knowledge graph reasoning task, LARK [45] proposes a LLM-guided logical reasoning method. It first transforms the conventional logical rules into a language sequence and then asks LLMs to reason the final outputs. Moreover, Siyuan et al. [46] unify structure reasoning and language mode pre-training in a unified framework. Given a text input, they adopt LLMs to generate the logical query, which is executed on the KGs to obtain structural context. Last, the structural context is fused with textual information to generate the final output. RecInDial [244] combines the knowledge graphs and LLMs to provide personalized recommendations in the dialogue system. KnowledgeDA [245] proposes a unified domain language model development pipline to enhance the task-specific training procedure with domain knowledge graphs.
为了充分利用LLM和KG的优势,研究人员将LLM和KG相互协同,进行各种应用的推理。在问答任务中,QA-GNN [118]首先利用LLM处理文本问题,并引导KG上的推理步骤。通过这种方式,它可以弥合文本和结构信息之间的差距,为推理过程提供可解释性。在知识图推理任务中,LARK [45]提出了一种以LLM为指导的逻辑推理方法。它首先将传统的逻辑规则转换为语言序列,然后要求LLM对最终输出进行推理。此外,Siyuan等人[46]在统一框架中统一了结构推理和语言模式预训练。给定一个文本输入,他们采用LLM生成逻辑查询,并在KG上执行以获得结构上下文。然后,将结构上下文与文本信息融合起来生成最终的输出。RecInDial [244]将知识图谱和LLM结合起来,在对话系统中提供个性化推荐。KnowledgeDA [245]提出了一个统一的领域语言模型开发流程,利用领域知识图谱增强任务特定的训练过程。
7 FUTURE DIRECTIONS
7 未来方向
In the previous sections, we have reviewed the recent advances in unifying KGs and LLMs, but here are still many challenges and open problems that need to be addressed. In this section, we discuss the future directions of this research area.
在前面的章节中,我们回顾了统一KG和LLM的最新进展,但仍然存在许多需要解决的挑战和开放问题。在本节中,我们讨论了这个研究领域的未来方向。
7.1 KGs for Hallucination Detection in LLMs
7.1 KG用于LLM中的幻觉检测
The hallucination problem in LLMs [246], which generates factually incorrect content, significantly hinders the reliability of LLMs. As discussed in Section 4, existing studies try to utilize KGs to obtain more reliable LLMs through pre-training or KG-enhanced inference. Despite the efforts, the issue of hallucination may continue to persist in the realm of LLMs for the foreseeable future. Consequently, in order to gain the public’s trust and border applications, it is imperative to detect and assess instances of hallucination within LLMs and other forms of AI-generated content (AIGC). Existing methods strive to detect hallucination by training a neural classifier on a small set of documents [247], which are neither robust nor powerful to handle ever-growing LLMs.Recently, researchers try to use KGs as an external source to validate LLMs [248]. Further studies combine LLMs and KGs to achieve a generalized fact-checking model that can detect hallucinations across domains [249]. Therefore, it opens a new door to utilizing KGs for hallucination detection.
LLM中的幻觉问题[246],即生成不准确的事实内容,显著影响了LLM的可靠性。正如在第4节中讨论的那样,现有研究尝试利用KG通过预训练或增强推理来获得更可靠的LLM。尽管有这些努力,幻觉问题在LLM领域可能在可预见的未来仍然存在。因此,为了赢得公众的信任和拓宽应用领域,检测和评估LLM和其他形式的AI生成内容(AIGC)中的幻觉实例至关重要。现有方法努力通过在一小组文档上训练神经分类器来检测幻觉[247],但这些方法既不稳健也不强大,无法处理不断增长的LLM。最近,研究人员尝试使用KG作为外部来源验证LLM[248]。进一步的研究将LLM和KG结合起来,实现一个可以跨领域检测幻觉的广义事实核查模型[249]。因此,KG为幻觉检测打开了一扇新的大门。
7.2 KGs for Editing Knowledge in LLMs
7.2 KG用于编辑LLM中的知识
Although LLMs are capable of storing massive real-world knowledge, they cannot quickly update their internal knowledge updated as real-world situations change. There are some research efforts proposed for editing knowledge in LLMs [250], [251] without re-training the whole LLMs. Yet, such solutions still suffer from poor performance or computational overhead. Existing studies [252], [253] also propose solutions to edit knowledge in LLMs, but only limit themselves to handling simple tuple-based knowledge in KGs. In addition, there are still challenges, such as catastrophic forgetting and incorrect knowledge editing [254],leaving much room for further research.
尽管LLM能够存储大量的现实世界知识,但在现实世界情况变化时,它们不能快速更新其内部知识。已经提出了一些用于编辑LLM中知识的研究方法[250],[251],而无需重新训练整个LLM。然而,这些解决方案仍然存在性能不佳或计算开销大的问题。现有研究[252],[253]也提出了在LLM中编辑知识的解决方案,但只限于处理KG中基于简单元组的知识。此外,仍然存在诸如灾难性遗忘和错误知识编辑等挑战,需要进一步研究。
7.3 KGs for Black-box LLMs Knowledge Injection
7.3 KG用于黑盒LLM的知识注入
Although pre-training and knowledge editing could update LLMs to catch up with the latest knowledge, they still need to access the internal structures and parameters of LLMs.However, many state-of-the-art large LLMs (e.g., ChatGPT) only provide APIs for users and developers to access, making themselves black-box to the public. Consequently, it is impossible to follow conventional KG injection approaches described [95], [134] that change LLM structure by adding additional knowledge fusion modules. Converting various types of knowledge into different text prompts seems to be a feasible solution. However, it is unclear whether these prompts can generalize well to new LLMs. Moreover, the prompt-based approach is limited to the length of input tokens of LLMs. Therefore, how to enable effective knowledge injection for black-box LLMs is still an open question for us to explore [255], [256].
尽管预训练和知识编辑可以更新LLM以跟上最新的知识,但它们仍然需要访问LLM的内部结构和参数。然而,许多最先进的大型LLM(如ChatGPT)只为用户和开发者提供API,对于公众来说它们是黑盒的。因此,无法采用传统的KG注入方法[95],[134]来改变LLM的结构,添加额外的知识融合模块。将各种类型的知识转化为不同的文本提示似乎是一种可行的解决方案。然而,这些提示是否能够很好地推广到新的LLM仍然不清楚。此外,基于提示的方法仅限于LLM的输入令牌长度。因此,如何对黑盒LLM进行有效的知识注入仍然是一个需要探索的开放问题。
7.4 Multi-Modal LLMs for KGs
7.4 KG用于多模态LLM
Current knowledge graphs typically rely on textual and graph structure to handle KG-related applications. However, real-world knowledge graphs are often constructed by data from diverse modalities [102], [257], [258]. Therefore,effectively leveraging representations from multiple modalities would be a significant challenge for future research in KGs. One potential solution is to develop methods that can accurately encode and align entities across different modalities [259]. Recently, with the development of multimodal LLMs [101], [260], leveraging LLMs for modality alignment holds promise in this regard. But, bridging the gap between multi-modal LLMs and KG structure remains a crucial challenge in this field, demanding further investigation and advancements.
当前的知识图谱通常依赖于文本和图形结构来处理与KG相关的应用。然而,现实世界的知识图谱通常是通过多种模态的数据构建的。因此,有效地利用多种模态的表示将成为未来KG研究的重要挑战。一个潜在的解决方案是开发能够准确编码和对齐不同模态实体的方法。最近,随着多模态LLM的发展,利用LLM进行模态对齐在这方面具有潜力。然而,将多模态LLM和KG结构之间的差距缩小仍然是这个领域的一个重要挑战,需要进一步的研究和进展。
7.5 LLMs for Understanding KG Structure
7.5 LLM用于理解KG结构
Conventional LLMs trained on plain text data are not designed to understand structured data like knowledge graphs. Thus, LLMs might not fully grasp or understand the information conveyed by the KG structure. A straightforward way is to linearize the structured data into a sentence that LLMs can understand. However, the scale of the KGs makes it impossible to linearize the whole KGs as input. Moreover, the linearization process may lose some underlying information in KGs. Therefore, it is necessary to develop LLMs that can directly understand the KG structure and reason over it [242].
传统上,仅在纯文本数据上训练的LLM并不具备理解结构化数据(如知识图谱)的能力。因此,LLM可能无法完全理解知识图谱结构所传达的信息。一种直接的方法是将结构化数据线性化为LLM可以理解的句子。然而,由于KG的规模,将整个KG线性化为输入是不可能的。此外,线性化过程可能会丢失KG中的一些基本信息。因此,有必要开发可以直接理解KG结构并在其上进行推理的LLM。
7.6 Synergized LLMs and KGs for Birectional Reasoning
7.6 协同LLM和KG进行双向推理
KGs and LLMs are two complementary technologies that can synergize each other. However, the synergy of LLMs and KGs is less explored by existing researchers. A desired synergy of LLMs and KGs would involve leveraging the strengths of both technologies to overcome their individual limitations. LLMs, such as ChatGPT, excel in generating human-like text and understanding natural language, while KGs are structured databases that capture and represent knowledge in a structured manner. By combining their capabilities, we can create a powerful system that benefits from the contextual understanding of LLMs and the structured knowledge representation of KGs. To better unify LLMs and KGs, many advanced techniques need to be incorporated, such as multi-modal learning [261], graph neural network [262], and continuous learning [263]. Last, the synergy of LLMs and KGs can be applied to many real-world applications, such as search engines [103], recommender systems [10], [90], and drug discovery.
KG和LLM是两种互补的技术,它们可以相互协同。然而,现有研究对LLM和KG的协同应用尚未深入探索。LLM(如ChatGPT)在生成类人文本和理解自然语言方面表现出色,而KG是以结构化方式捕获和表示知识的结构化数据库。通过结合它们的能力,我们可以创建一个强大的系统,既能从LLM的上下文理解中受益,又能从KG的结构化知识表示中受益。为了更好地统一LLM和KG,需要结合许多先进的技术,如多模态学习[261]、图神经网络[262]和持续学习[263]。最后,LLM和KG的协同应用可以应用于许多现实世界的应用,如搜索引擎[103]、推荐系统[10]、药物发现等。
With a given application problem, we can apply a KG to perform a knowledge-driven search for potential goals and unseen data, and simultaneously start with LLMs to perform a data/text-driven inference to see what new data/goal items can be derived. When the knowledge-based search is combined with data/text-driven inference, they can mutually validate each other, resulting in efficient and effective solutions powered by dual-driving wheels. Therefore, we can anticipate increasing attention to unlock the potential of integrating KGs and LLMs for diverse downstream applications with both generative and reasoning capabilities in the near future.
有了给定的应用问题,我们可以应用KG进行基于知识的搜索,寻找潜在的目标和未见过的数据,并同时使用LLM进行基于数据/文本的推理,看看能够得出哪些新的数据/目标项。当基于知识的搜索与基于数据/文本的推理相结合时,它们可以相互验证,从而产生由双驱动轮驱动的高效和有效的解决方案。因此,我们可以预见在不久的将来,集成KG和LLM的潜力将在各种具备生成和推理能力的下游应用中得到充分的关注。
8 CONCLUSION
8 结论
Unifying large language models (LLMs) and knowledge graphs (KGs) is an active research direction that has attracted increasing attention from both academia and industry. In this article, we provide a thorough overview of the recent research in this field. We first introduce different manners that integrate KGs to enhance LLMs. Then, we introduce existing methods that apply LLMs for KGs and establish taxonomy based on varieties of KG tasks. Finally, we discuss the challenges and future directions in this field. We hope this article can provide a comprehensive understanding of this field and advance future research.
将大型语言模型(LLM)和知识图谱(KG)统一起来是一个活跃的研究方向,引起了学术界和工业界的广泛关注。在本文中,我们对该领域的最新研究进行了全面的概述。我们首先介绍了不同的方式来整合KG以增强LLM。然后,我们介绍了应用LLM进行KG的现有方法,并根据各种KG任务建立了分类体系。最后,我们讨论了这个领域的挑战和未来方向。我们希望本文能够提供对这个领域的全面了解,并推动未来的研究进展。

