
- 1实用 通用Adb无线调试开发Android应用程序_无线调试怎么使用配对码配对设备
- 2测试时间不够,项目要如期发布该怎么办?_如果有一个需求下星期要上线,但是开发说最快要半个月,怎么解决
- 3uniapp消息推送超详细(从开通uniPush到测试成功)
- 4华为鸿蒙系统HarmonyOS学习之九:鸿蒙HarmonyOS发展史与未来_华为鸿蒙系统的未来发展展望
- 5HarmonyOS应用开发系列课(进阶篇) (中级考试)_在基于 harmo nyos开发应用的过程中,为了尽量避免申请 与用户需求功能无关的
- 6成为Java单元测试大师:7个技巧让你编写更优秀的测试用例!_java 测试用例怎么写
- 7【bearpi物联网应用笔记】hi3861通过mqtt连接onenet_hi3861使用mqtt协议连接中移动onenet云
- 8【网安AIGC专题10.19】论文3代码生成:ChatGPT+自协作代码生成+角色扮演(分析员、程序员、测试员)+消融实验、用于MBPP+HumanEval数据集_mbpp数据集
- 9python爬取 ----批量爬图片,并存储到数据库_python批量爬取图片并保存
- 10【超详细】使用模拟器连接appium_appium连接模拟器
Django优化:如何避免内存泄漏
赞
踩
点击上方“程序员大咖”,选择“置顶公众号”
关键时刻,第一时间送达!

在初创科技公司工作就像在救火队,需要对抗不时出现的火情(如果你迭代速度越快,则会越频繁)。每一次扑灭能换来几个月的平静,但你心底特别清楚,这事儿没完。因此如何彻底赢得这场战斗变得很重要。
手头的问题
首先,一些背景 -- 我们每天晚上都会运行一个Celery任务,执行一些重要而且耗时的计算,以保持数据库中某个表的“新鲜度”。它是我们代码库的关键组件之一,确保每天都能成功完成该项任务相当重要。由于它涉及的数据量相对较大,早期就带来了一些麻烦,现在已经在该任务上使用了不止一种优化。该任务最近完全停止执行,而且为解决其他问题而查看生产环境上的日志时还发现了段错误信息。
思考该任务代码的一个超简化版本 -:
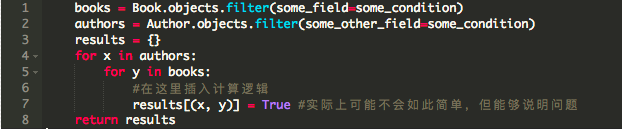
`books`和`authors`都是Django查询结果集,当然不能完全代表我们的实际模型。在我撰写本文时后者有2012个对象,前者约有17k个对象。自从这个任务开始以来,这个双层for循环一直能够很好地如期工作。后来,我们去年遇到了第一次内存故障,以及最近的段错误。我决定将代码剥离为基本要素,类似于上面所示的代码的样子,并使用htop命令运行一些测试。下图的gif动图是我在测试机器上调查该问题时情形,测试机器有4G内存,生产机器上是10G内存

(每次增加约200M内存)
(按照简化代码)内存使用率增加得相当快,蹭蹭地达到了机器上4G的上限。如果我要用空间复杂度来度量,那么这就是OMN),其中M和N都是(近似的)线性函数,它跟踪两个查询集随时间的增长。M明显比N慢。
批量处理查询集(Queryset)
然后,我重新使用了一年前采用的第一个优化 -- 批量处理查询集。在我们的脚本中有两个主要的消耗内存的地方,第一个地方是Python数据库连接(在本例中是Python MySQL DB连接),它的任务是执行SQL查询并返回结果,第二个是查询集缓存。查询集批量处理是首选方法。
以下是使用了查询集批处理的第二个版本的代码 - :
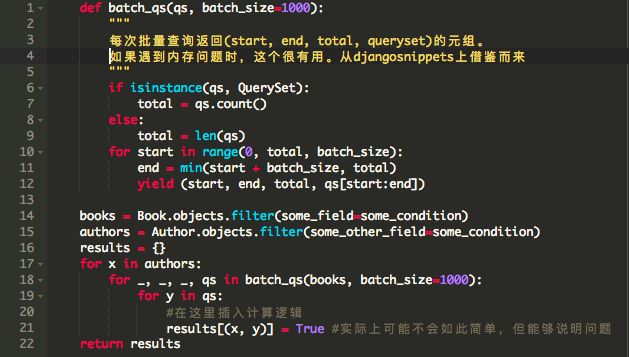
我们再次执行这个任务,并查看htop。

(增长放缓了,但终究还是会达到上限)
嗯。内存使用率增长的速度比上次更慢,但它不可避免地会达到了上限或出现段错误。这能够说得通,因为queryset批处理不会减少从数据库中获取的结果的数量。只是通过配置批量的大小,每次尽可能少地将指定内容保留内存中。这最终导致了我们当前遇到的困境,因此有了第二次优化的需求。
查询集(Queryset)的本质
据说Django的查询集具有延迟加载和缓存的机制。延迟加载意味着,除非对查询集执行了某些操作(例如遍历它),否则将不会事先执行那些数据库查询。缓存意味着如果您重新使用相同的查询集,则不会重复执行多次相同的数据库查询。
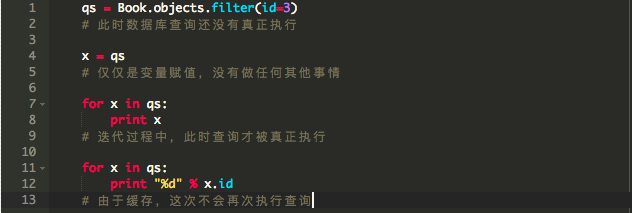
缓存在这里如何起作用?事实证明,由于缓存机制,我们不能“扔掉”(垃圾收集)已经使用的批量结果。在我们的例子中,我们只需要使用一次批量结果,缓存它们是浪费内存。直到函数结束缓存才会被清除。为了解决这个问题,我们在查询结果集上使用iterator()函数。

让我们再来试一下。按道理内存使用量增长速度应该减慢。

(似乎还是不对)
但实际上没有...
破釜沉舟,背水一战
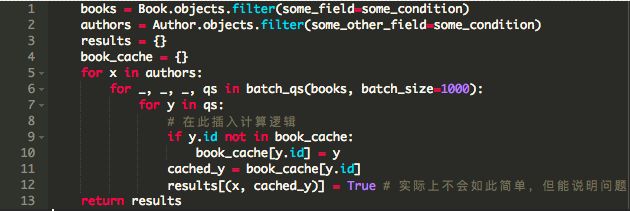
不管怎么样,尽管使用了迭代器,我们仍将某些东西存储在内存中。让我们仔细看看代码。是否存在可能阻止垃圾回收器回收内存的对象引用?发现真有一个地方 -- 字典使用元组作为键来存储对象。

我运行了一个简单的测试就是将这一行注释掉,看看这个任务需要多少内存。内存使用不再疯狂攀升,而是停止在一个特定的值上。
对于来自外层循环的author,我们在内部循环中遍历book不同“拷贝”。对于两个不同的author A1和A2,由于使用迭代器,元组(A1,B)和(A2,B)指向内存中B的不同副本。因此,我们必须按照特定规则重新引入缓存。

(不再快速增长了)
再次运行测试。内存使用量增长缓慢,在某些值附近徘徊,并在一段时间后显着下降(图中并未显示出来)。book_cache的目的是遍历一次所有book对象后将所有book对象保存起来,以便在随后的多次遍历中重新使用。y在随后的遍历中所指向的对象会被垃圾回收,之后便会使用缓存的版本。现在,对于(A1,B)和(A2,B),两个B都指向内存中的同一个对象。最后,iterator()允许我们控制我们如何使用我们的空闲内存。这个最终代码的空间复杂度为O(M + N),因为我们在内存中只保留了每个book对象的一个副本
请注意,这仅仅解决了我们眼前的问题。随着数据库规模的扩大,会出现更多导致离线问题。这意味着代码并不完美,但是,目标永远不会是“完美代码”,而是“优化当前代码”。
顺便说一句:为了回复一些评论中的建议 - 我确实可以将对象的ID(ID和对象组合)作为关键字进行存储。这是理想的解决方案。但是在这种情况下这对我并不适用,因为上面的代码是较大工作流程实际案例的一小部分

译者:DengFeng Mao
https://mp.weixin.qq.com/s/QlT_qVKu2SCVCsoaoZuzIA
程序员大咖整理发布,转载请联系作者获得授权



