
热门标签
热门文章
- 1Tuxera NTFS2022Mac如何安装以及怎么激活NTFS?_tuxera ntfs激活版 csdn
- 2Linux安装Anaconda和虚拟环境配置_env.yaml文件 linux 使用
- 3简单实现gcc/g++更换版本_gcc版本切换
- 4华为云IOT Android应用开发详细教程_android iot 文档
- 5Substance Designer(基础一)Blend节点的混合模式(未完)_节点类型 混合
- 6在Win11电脑上安装安装APP详细过程_安装amazon出现错误,请稍后重试
- 7素描令牌:一个中层的学习轮廓和目标检测的表征Sketch Tokens: A Learned Mid-level Representation for Contour and Object Detec
- 8华为的鸿蒙系统是安卓吗,华为鸿蒙,一个本属于2025年的产品
- 9源自国家电网,可用于新能源发电预测的高质量数据集_发电预测数据集如何划分
- 10adb 常用命令_pm compile -m speed
当前位置: article > 正文
DelightfulTTS
作者:Gausst松鼠会 | 2024-03-21 04:07:14
赞
踩
delightfultts
文章目录
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
- liuyangqing, tanxu,helei
- Blizzard 2021的比赛
abstract
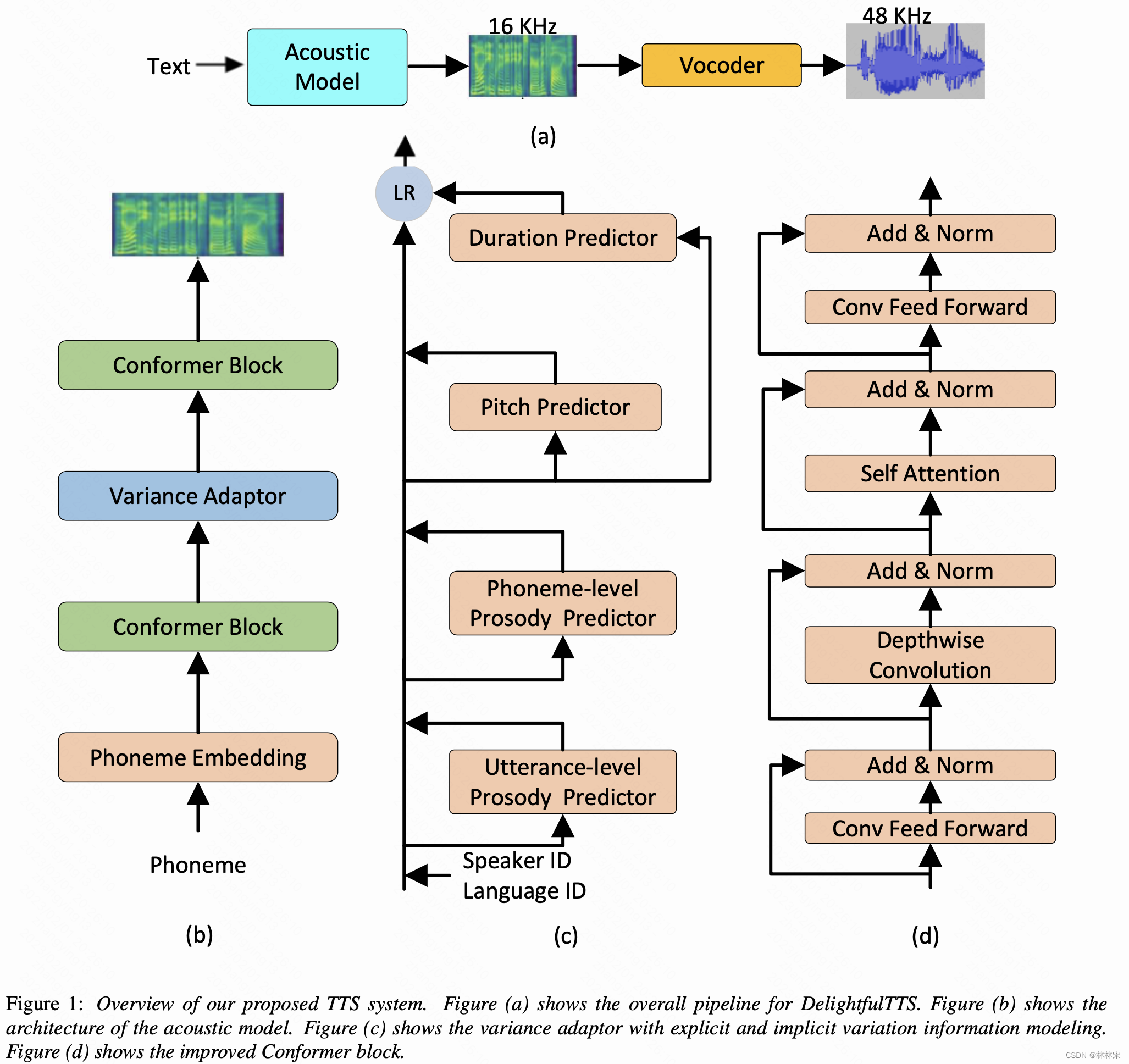
- 提出一种高效有用的高质量语音生成系统:生成48KHz语音,本文使用声学模型生成16khz的,然后HiFiNet将16K的mel-spec再升采样为48k语音,在训练效率,模型稳定度、语音质量上求得折中。
- 建模变量:输入的特征:(1)说话人id,语言id,pitch, duration,前两个都使用look up table;(2)utterance-level prosody , phn-level prosody;reference encoder编码;
- 使用优化后的Conformer结构,实现更好的local & global建模。
intro
- 声学模型建模的压力比较大:(1)text到mel的跨域映射;(2)TTS自身的one-to-many的问题;
- vocoder 从mel重建回采样点,基本只需要预测相位信息;如果从16khz重建48k语音,vocoder主要负责相位的预测和上采样。
- 因此,为了降低声学模型的建模难度,只预测16k mel-spec。
method
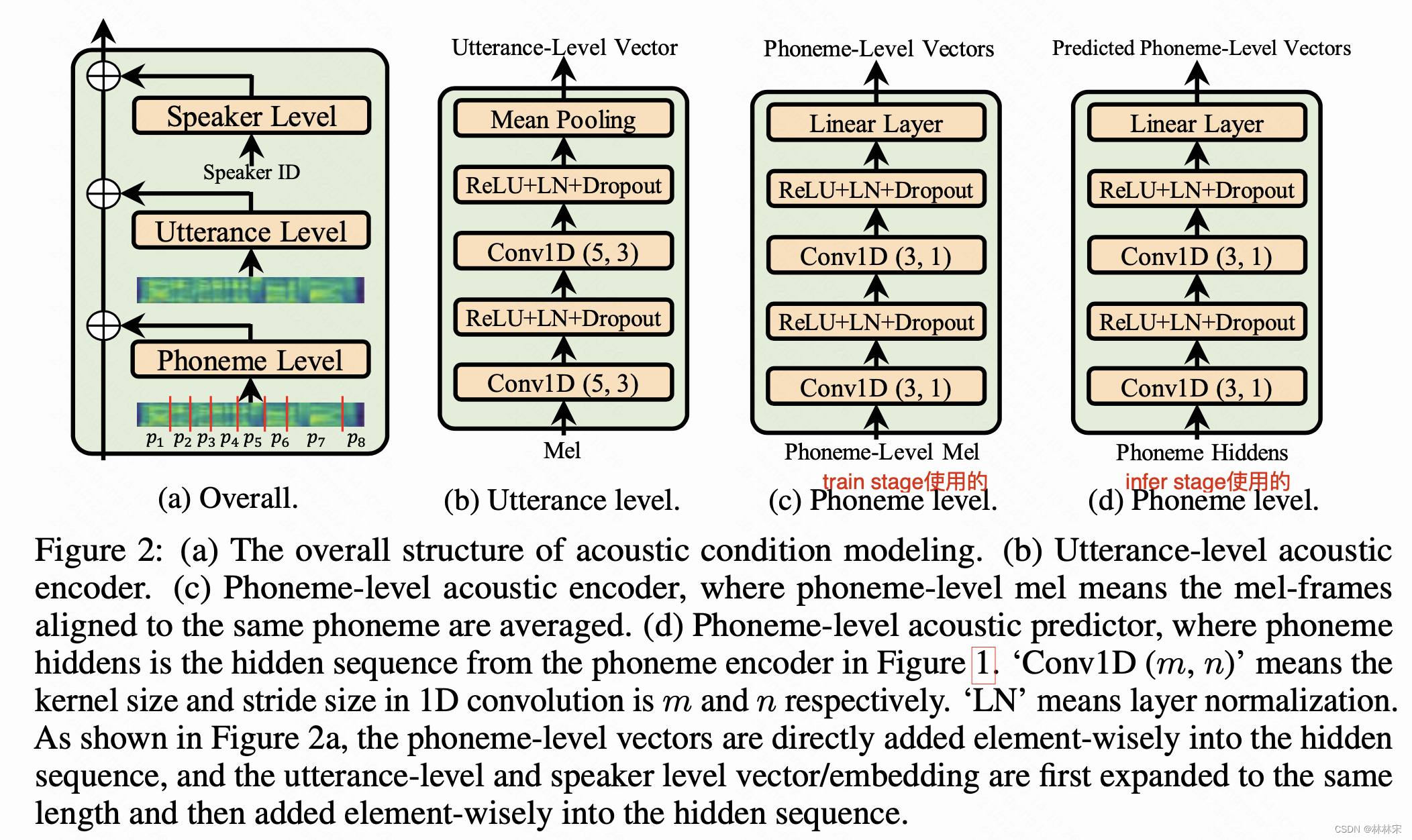
Variation Information Modelling
- utterance level prosody predictor:参考GST的设计;
- phn-level prosody predictor:设计参考了adaspeech的设计(如下图)。adaspeech是根据对齐,对frame-mel进行求平均,得到phn-level的长度,然后编码成phn-level vectors。
- 本文phn-level predictor的设计:Phoneme-level prosody vectors are obtained by using the outputs of phoneme encoder (phoneme- level) as query to attend to the outputs of mel-spectrogram reference encoder (frame-level). we directly use the latent representation as phoneme-level vector for training stability
Conformer in Acoustic Model
- Conformer 背景:transformer的变种,首先应用于ASR,将transformer-XL的location sensitive position encoding加入进来。slf-attn负责建模global的信息,conv层负责建模local得信息,这两者对于TTS都是很重要的。
- 针对性改进:(1)Swish激活函数替换为RLU,长句子的泛化性更好;(2)先depthwise conv,后slf-attn(顺序换了一下),加快收敛速度;(3)feed-forward结构中的linear替换为conv,获得更好的韵律和音频保真度。
- 本文的conformer block:feed-forward module, depthwise conv, slf-atten module,second feed-forward module
experiment
- 5h 得西班牙语数据 + 微软自己的40h 欧洲西班牙语数据&40h 墨西哥西班牙语数据
- 声学模型和vocoder都在全量数据上训练,然后再目标人数据上finetune
- encoder/decoder 6x conformer block;depthwise conv-kernel=7
Training Strategy
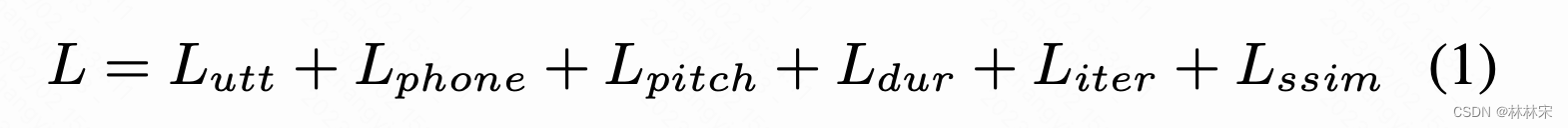
- L u t t L_{utt} Lutt, utterance predictor predictor输出结果和utt-level reference encoder的L1 loss
- L p h n L_{phn} Lphn,phn-prosody predictor predictor输出结果和phn-level reference encoder的L1 loss
- L p i t c h L_{pitch} Lpitch和 L d u r L_{dur} Ldur是pitch/duration 预测值和真实值的L1 loss
- L i t e r L_{iter} Liter是conformer-decoder每一层decoder输出和真实mel-spech求loss的和;
- L S S I M L_{SSIM} LSSIM是最后一层decoder输出的mel-spec和真实值的Structural SIMilarity误差;
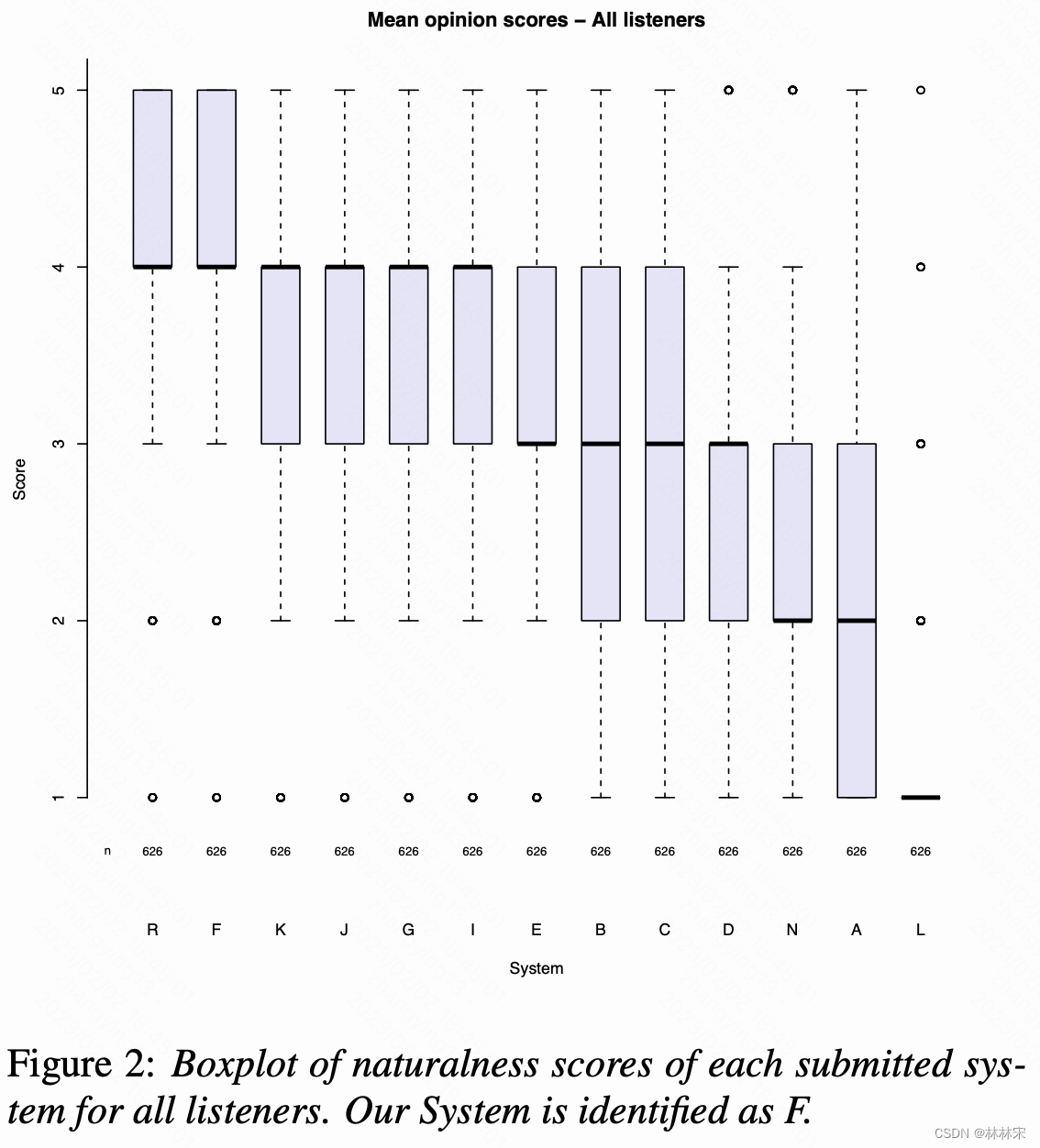
result
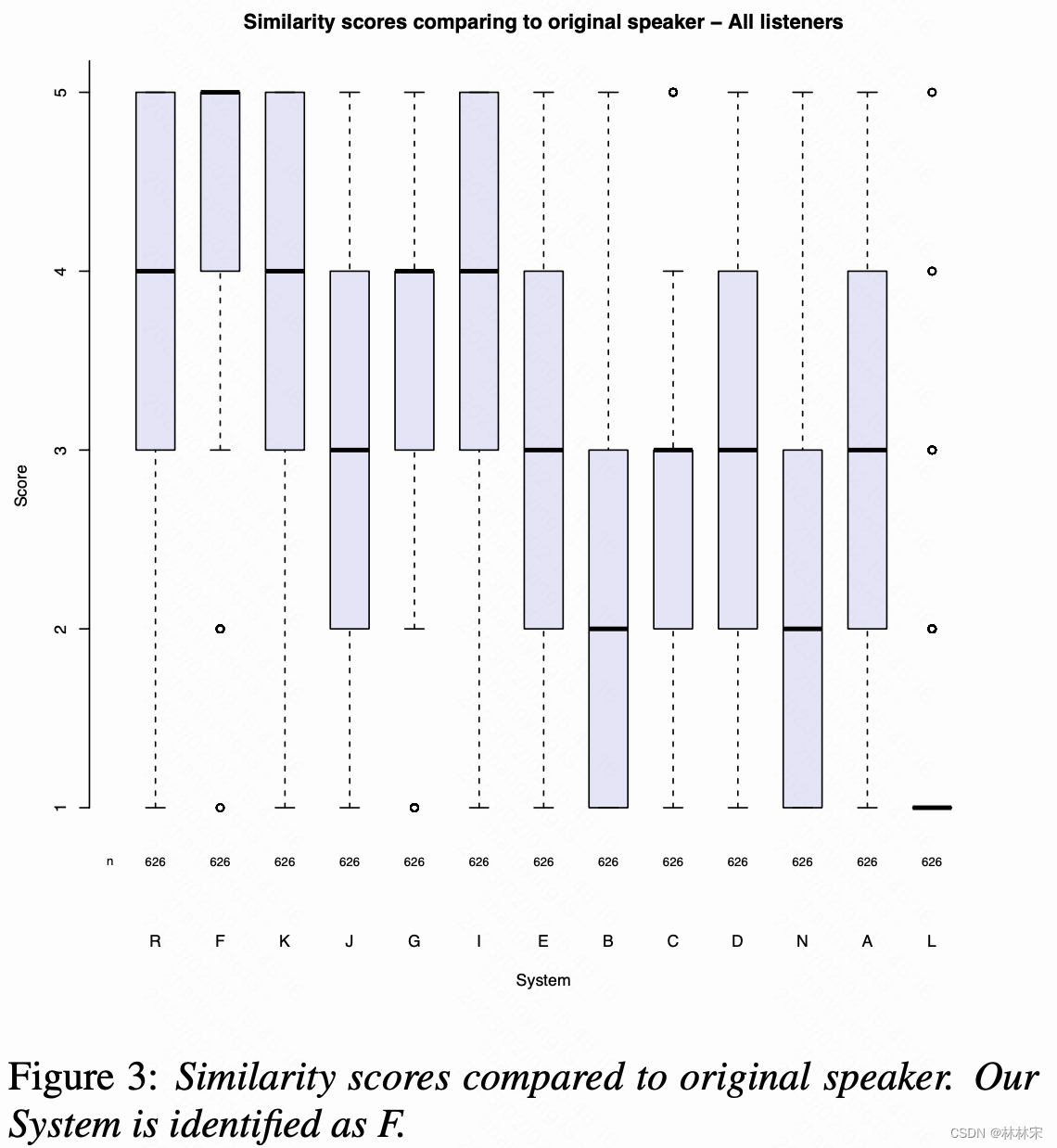
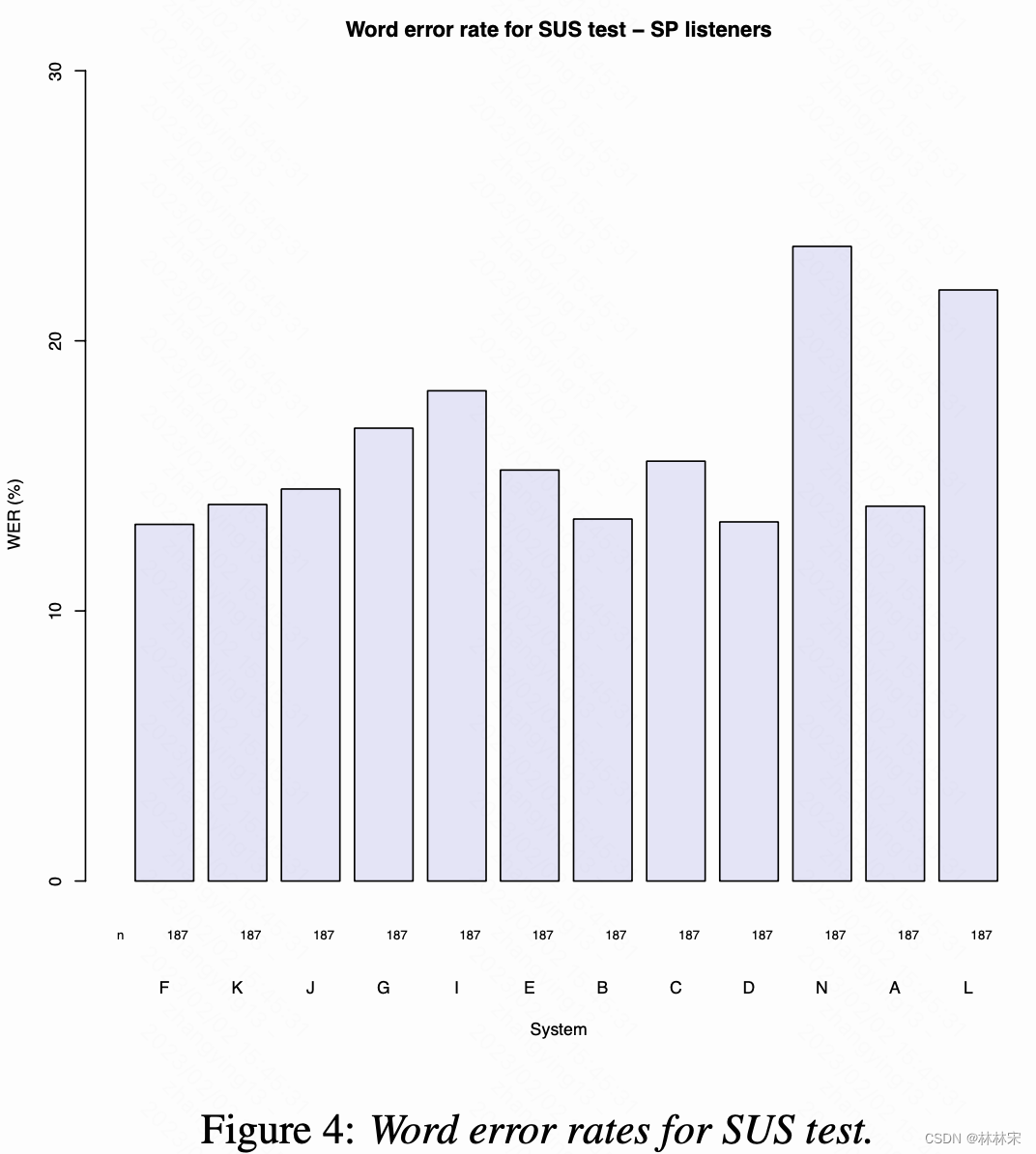
- F是微软做的系统
DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
- 2022 interspeech
- Yanqing Liu, tanxu, zhaosheng
abstract
- 级联系统的问题:(1)声学模型和vocoder单独优化,会造成级联误差;(2)声学模型的输出mel-spec丢失了相位信息,属于sub-optimal问题。
- 提出end2end TTS系统:(1)使用基于VQ-GAN的codec提取中间声学特征(frame-level)代替mel-spec。(2)联合优化声学模型(DelightfulTTS)和vocoder(VQ-GAN的decoder),声学模型的输出添加额外的loss。
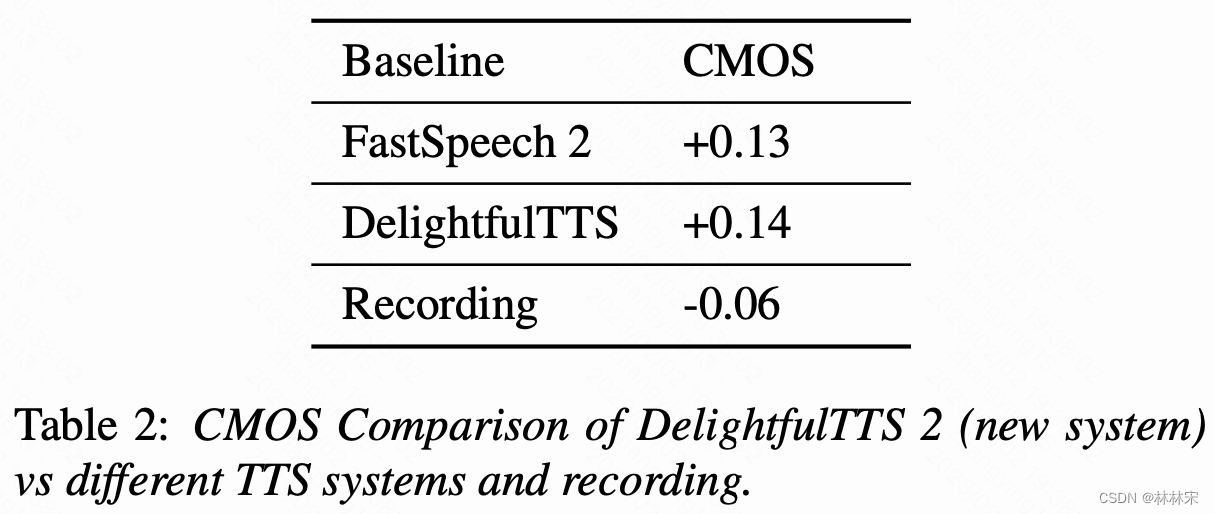
- 结果:CMOS相比于DelightfulTTS提升0.14
intro
现有端到端TTS方案的缺点:(1)相比于级联系统没有明显的性能提升,比如FastSpeech 2s, EATS,WAVE-TACOTRON;(2)自回归生成导致的infer速度变慢,比如WAVE-TACOTRON;(3)训练复杂度提升,比如VITS,Clar- iNet ;(4)依赖信号变换之后的声学特征,比如FastSpeech 2s依赖mel-spec,VITS依赖linear-spec,尽管这些特征是语音的简要表示,但是仍然有信息的丢失。
本文提出:
- VQ-GAN作为codec对语音进行编码,自主的学习到帧级别的中间层表示;并把学习到的representation通过多级量化器量化,然后送入到VQ-GAN的decoder中进行波形重建。
- VQ-GAN训练完成以后,将声学模型(DelightfulTTS)和VQ-GAN的decoder级联,声学模型预测VQ-GAN的encoder编码结构,并用loss约束。
method
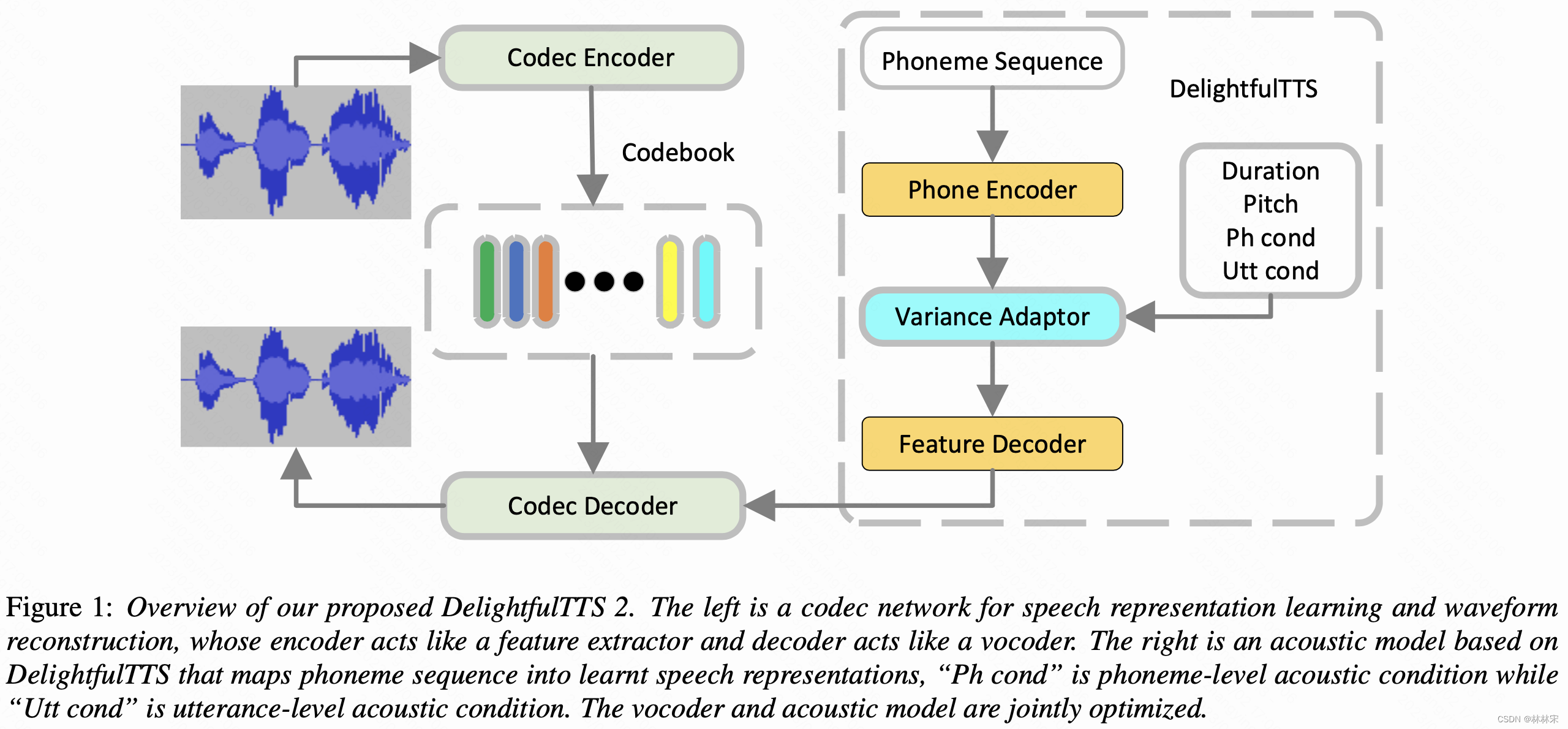
Speech Representation Learning with VQ-GAN
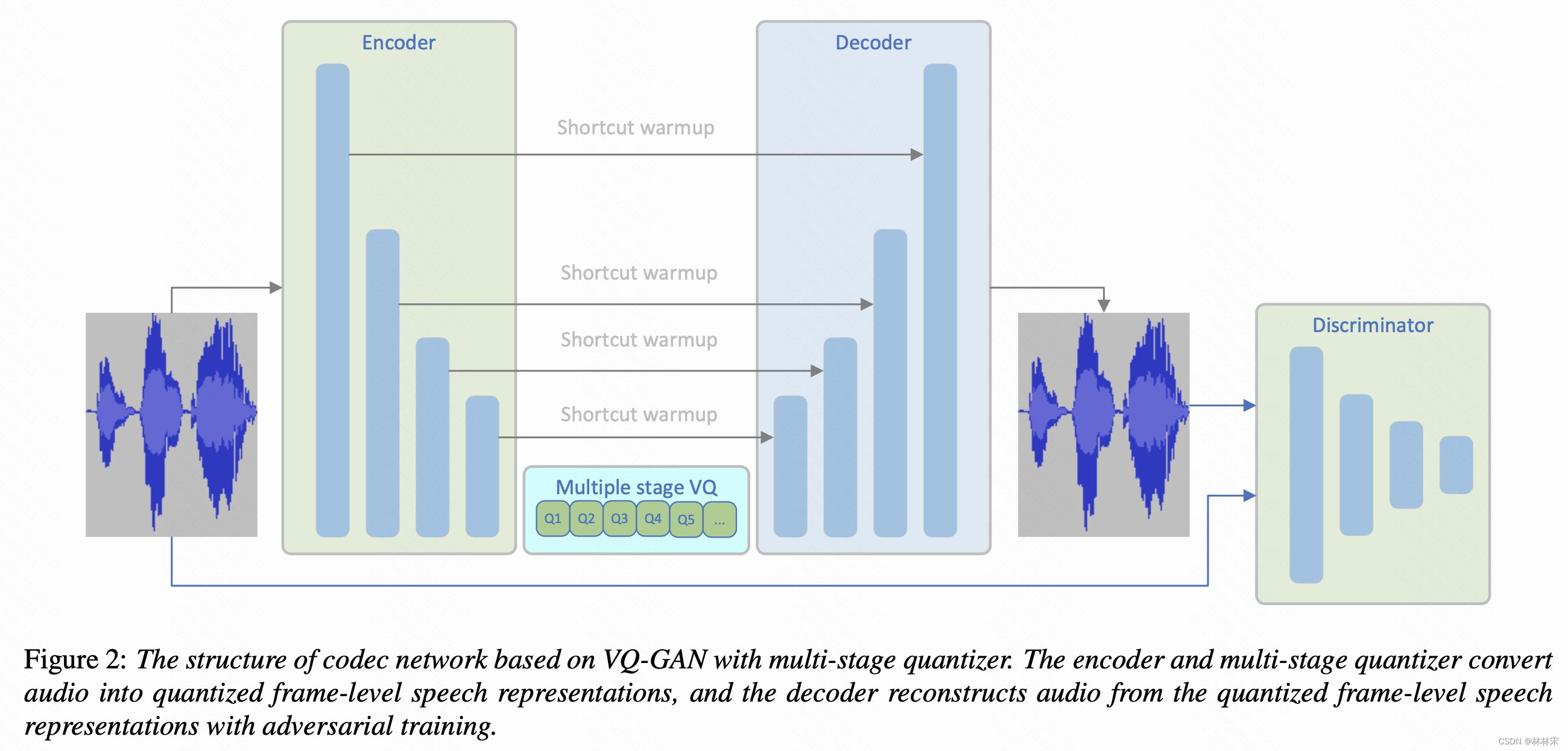
- 结构:(1)decoder是HiFiGan的结构,上采样过程中添加bidirectional Long Expressive Memory (LEM) layer用以长时建模的稳定性;encoder是decoder的镜像;(2)skip-connection 在encoder和decoder之间的对应层(文本写first three encoder layer,但是画图不是),对于模型收敛和级联训练稳定很重要;(3)encoder每一个block的输出进行量化。
- 对抗训练:参考HiFiGan和MelGan的设计,(1)三个一样的判别器作用于不同分别率的采样点输出,original,2x , 4x downsampe。(2)DWT(离散小波变换)代替判别器中的average sampling,重新生成高频成分。
Acoustic Model
- 模型结果和DelightfulTTS一样。预测mel变成预测quantized speech representation,而且会对quantized speech representation进行random segmentation process。训练声学模型过程中,会有真实的pitch , utterance-level acoustic condition和phone-level acoustic condition作为输入,为了避免train和infer过程的mismatch,上述特征通过schedule sampling mechanism送入,逐步降低真实值的比例。
Training Objectives
-
Discriminator Loss : 判别器中的下采样方法由average pooling操作替换成discrete wavelet transform ,分成多个频率子带,有助于高频建模;
-
Codec Decoder Loss
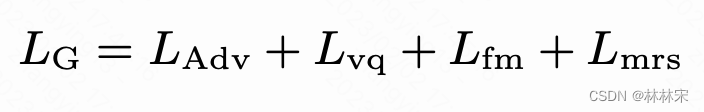
- L v q L_{vq} Lvq:vector quantization loss
- L m r s L_{mrs} Lmrs:multi-resolution spectrogram loss
-
Acoustic Model Loss
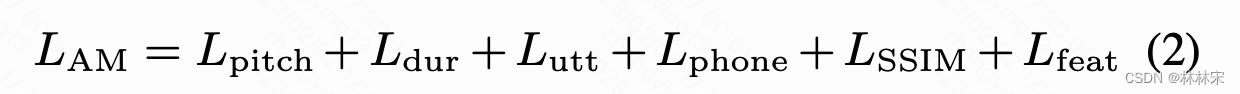
- L u t t L_{utt} Lutt/ L p h o n e L_{phone} Lphone:对应的predictor预测的vector和对应的reference encoder预测的vector之间的L1 loss
- L p i t c h L_{pitch} Lpitch/ L d u r L_{dur} Ldur:预测的帧级别pitch,phone对应的duration和真实的pitch/duration之间的L1 loss
- L S S I M L_{SSIM} LSSIM:声学模型预测的quantized speech representation和VQ-GAN encodec编码的quantized speech representation之间的SSIM损失,提升语音保真度
- L f e a t L_{feat} Lfeat:预测的quantized speech representation和VQ-GAN encodec编码的quantized speech representation之间的L1 loss
-
joint loss
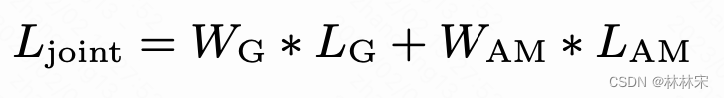
experiment
- 40h的内部英文数据集,frame-level的特征从16khz语音中提取,codec训练使用的是24khz语音
- 声学模型参数量65.3M,vocoder 3.3M
- 单个V100卡的推理速度RTF=0.008,和DelightfulTTS持平;
results
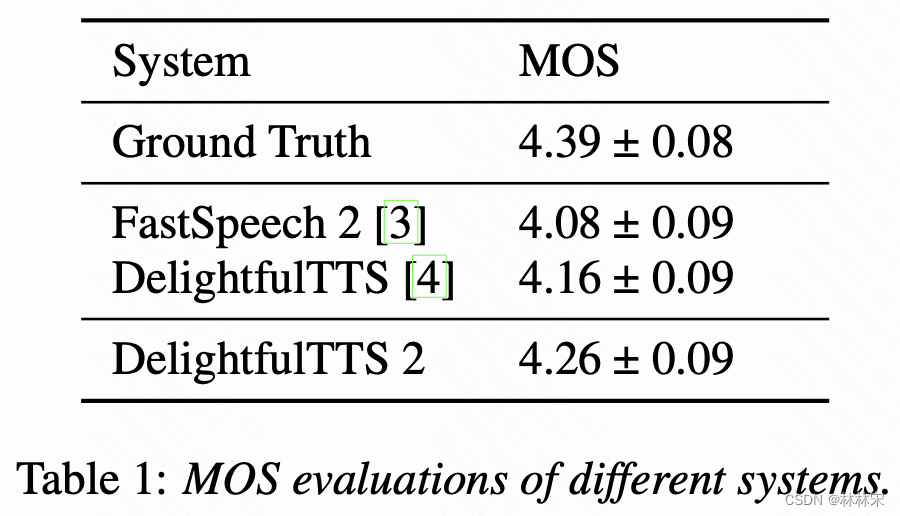
Analyses on Codec Network
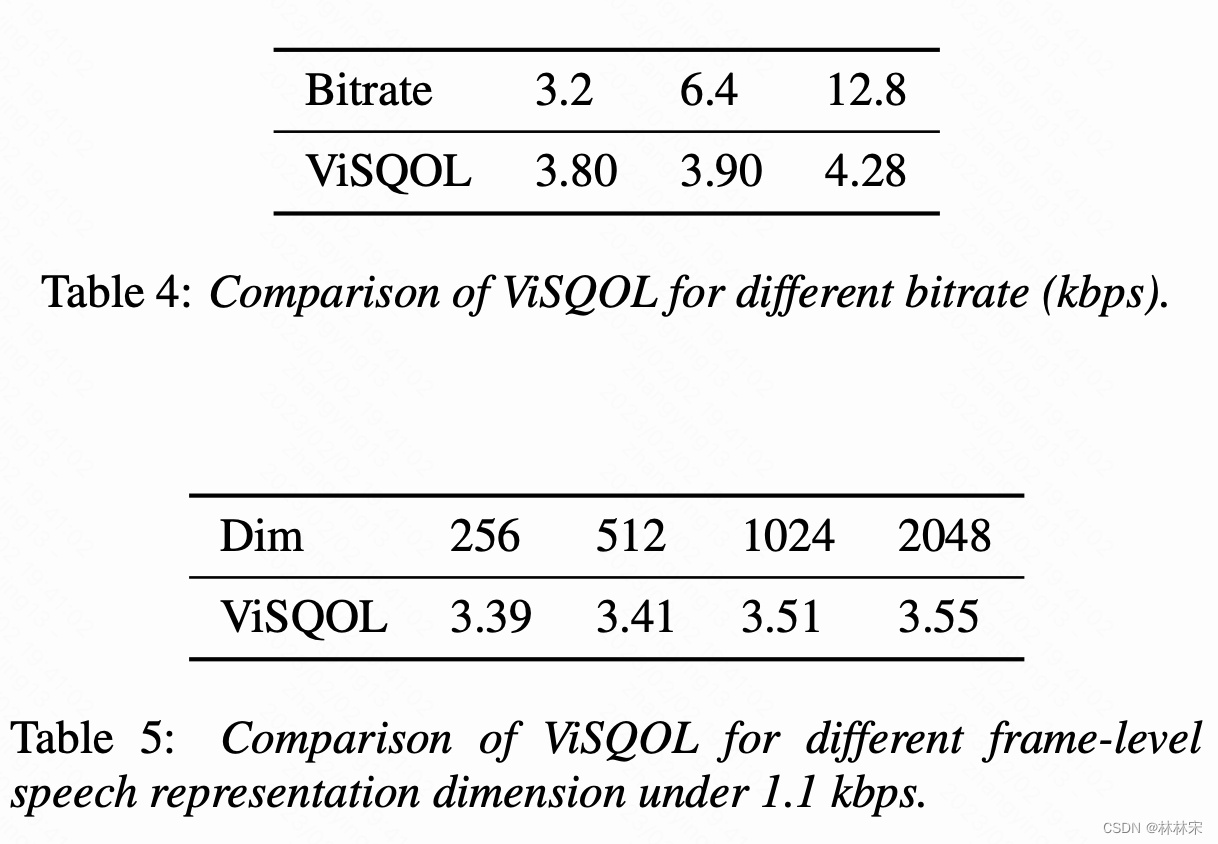
- ViSQOL语音质量客观评价的工具
- 表4:量化的bitrate越低,声学模型建模难度越低,实时率越高,但是语音的语音质量会差一些。
- 表5:不同的量化帧长对生成质量的影响,帧长增大,语音质量会有一点提升。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/278314
推荐阅读


相关标签

