
热门标签
热门文章
- 1Win10优化:禁用必要的服务_wind10禁止不必要的进程可能会影响系统的正常运行
- 2《移动安全》(6)使用drozer检测四大组件(下)_检查安装程序中的是否调用四大组件
- 3C/C++四种方法实现加法操作_艾孜尔江撰_c++加法代码
- 4安卓玩机----展讯芯片机型解锁 读写分区工具 操作步骤解析_高通读写工具
- 5langchain快速入门
- 6【亲为】yoloV8收集数据->数据标注->数据集训练->模型验证_在配置yolov8的mydata.yaml
- 7数据库字段加解密插件,保障数据的安全,支持Mybatis框架与MybatisPlus框架,数据入库加密,出库解密_mysql入库加密.出库解密
- 8ubuntu 16.04 tightvncserver VNC 安装配置,安装xrdp,x11vnc、Ubuntu 18.04
- 9《手把手教你》系列基础篇之(一)-java+ selenium自动化测试-环境搭建(上)(详细教程)_java+selenium
- 10是面试官放水,还是公司实在是太缺人?这都没挂,华为原来这么容易进..._华为测评 遇到困难怎么处理
当前位置: article > 正文
深度学习 对比两张图片的差异_深度学习模型不确定性方法对比
作者:Gausst松鼠会 | 2024-03-22 11:16:14
赞
踩
图像比对深度学习模型

©PaperWeekly 原创 · 作者|崔克楠
学校|上海交通大学博士生
研究方向|异构信息网络、推荐系统
本文以 NeurIPS 2019 的 Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift 论文为主线,回顾近年顶级机器学习会议对于 dataset shift 和 out-of-distribution dataset 问题相关的论文,包括了 Temperature scaling [1] ,DeepEnsemble [2] ,Monte-Carlo Dropout [3] 等方法。而 [4] 在统一的数据集上对上述一系列方法,测试了他们在 data shift 和 out-of-distribution 问题上的 accuracy 和 calibration。

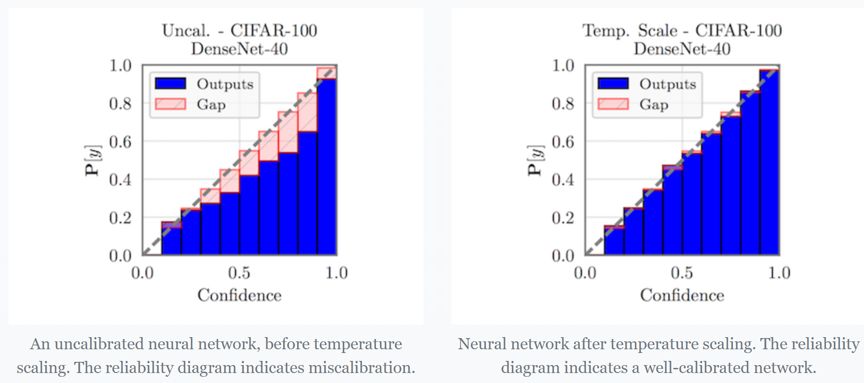
 Temperature Scaling [1] 在介绍 temperature scaling 之前,首先需要了解什么叫做 calibrated? 神经网络在分类时会输出“置信度”分数和预测结果。理想情况下,这些分数应该与真实正确性的可能性相匹配。例如,如果我们将 80% 的置信度分配给 100 个样本,那么我们就会期望 80% 样本的预测实际上是正确的。如果是这样,我们说模型是经过校准的。 而 Temperature scaling 则是一个非常简单的后处理步骤,能够帮助模型进行校准。一种可视化校准的简单方法是将精度作为置信度的函数绘制(reliability diagram)。下边左边的可靠性图表中,我们可以看到一个在 CIFAR-100 上训练的 DenseNet 是极度自信的。然而,使用 Temperature scaling,模型就得到了校准。
Temperature Scaling [1] 在介绍 temperature scaling 之前,首先需要了解什么叫做 calibrated? 神经网络在分类时会输出“置信度”分数和预测结果。理想情况下,这些分数应该与真实正确性的可能性相匹配。例如,如果我们将 80% 的置信度分配给 100 个样本,那么我们就会期望 80% 样本的预测实际上是正确的。如果是这样,我们说模型是经过校准的。 而 Temperature scaling 则是一个非常简单的后处理步骤,能够帮助模型进行校准。一种可视化校准的简单方法是将精度作为置信度的函数绘制(reliability diagram)。下边左边的可靠性图表中,我们可以看到一个在 CIFAR-100 上训练的 DenseNet 是极度自信的。然而,使用 Temperature scaling,模型就得到了校准。
具体怎么做 temperature scaling 呢,对于分类问题,网络最后一层往往会输出 logits,而 logits 进一步传给 softmax 函数来得到各个类别的概率,而 temperature scaling 对这一步骤修改为:
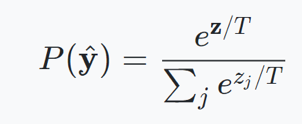
实现层面也很简单,在 PyTorch 的实现如下:
class Model(torch.nn.Module): def __init__(self): # ...声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/287711
推荐阅读
相关标签

