
- 1docker-compose部署Springboot_docker-compose 部署springboot项目
- 2限流算法及 RateLimiter 的使用和代码解读_rate must be positive
- 3红旗linux分区方案有,红旗Linux分区全攻略
- 4Linux命令汇总_pciconf 命令手册
- 5微信小程序 【笔记003】小程序的事件处理_detail object
- 6failed to start daemon: Error initializing network controller: Error creating default “bridge“ netw
- 7Android Studio MQTT功能_android setautomaticreconnect
- 8ajax没拿到data的值_PythonDjango+JS+Ajax实现网页采集并动态显示PLC变量
- 9DevExpress WinForms甘特图组件 - 轻松集成项目管理功能到应用_winform甘特图控件有哪些
- 10Android——在线计算器完整代码_安卓计算器代码
10种实用的Prompt技巧图解
赞
踩
收集整理了prompt engineering的10种实用技巧,以图解的方式解释了它们的主要原理。
本文追求以极简风格逼近这些方法的第一性原理,把黑话翻译成人话,并使用图片范例进行说明。
同时也加入了一些自己的理解,如有出入欢迎指正。

一,Structured Prompt (结构化提示词)
可以按照 prompt = 角色 + 任务 + 要求 + 提示 的结构设计清晰明了的提示词。
简单地说,这个结构就是要告诉chatgpt: 你是谁?你要做什么?要做成什么样?要如何做?
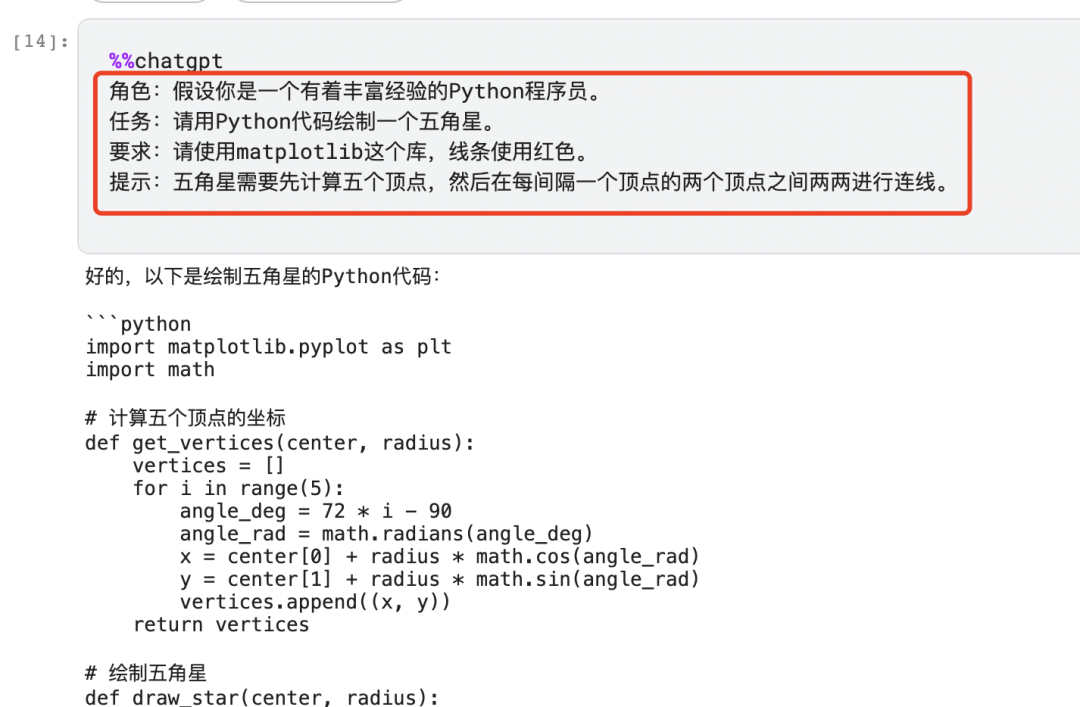
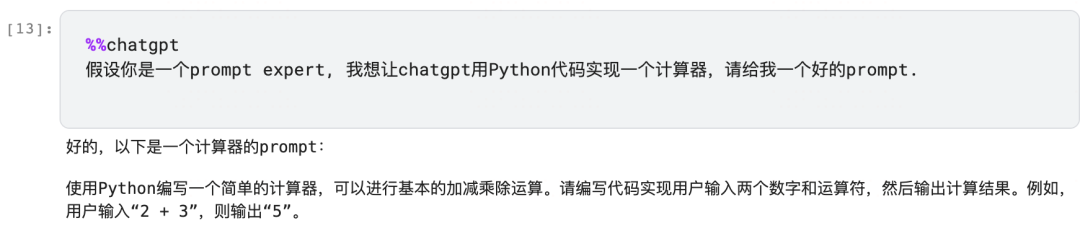
二,Prompt Creator (提示词生成器)
简单地说,就是让ChatGPT扮演一个提示词生成专家,帮助你完成/完善/改进 你的prompt。
三,One/Few Shot Prompt (单样本/少样本提示)
没有范例:zero shot;给1个范例 one shot;几个范例:few shot;
如果有许许多多的范例,可以尝试finetune模型权重。

四,COT(Chain of Thought,思维链)
在few shot prompt的范例中给出思维链,让模型学习不仅输出结果还要给出思考过程。可以显著提升LLM的表现。
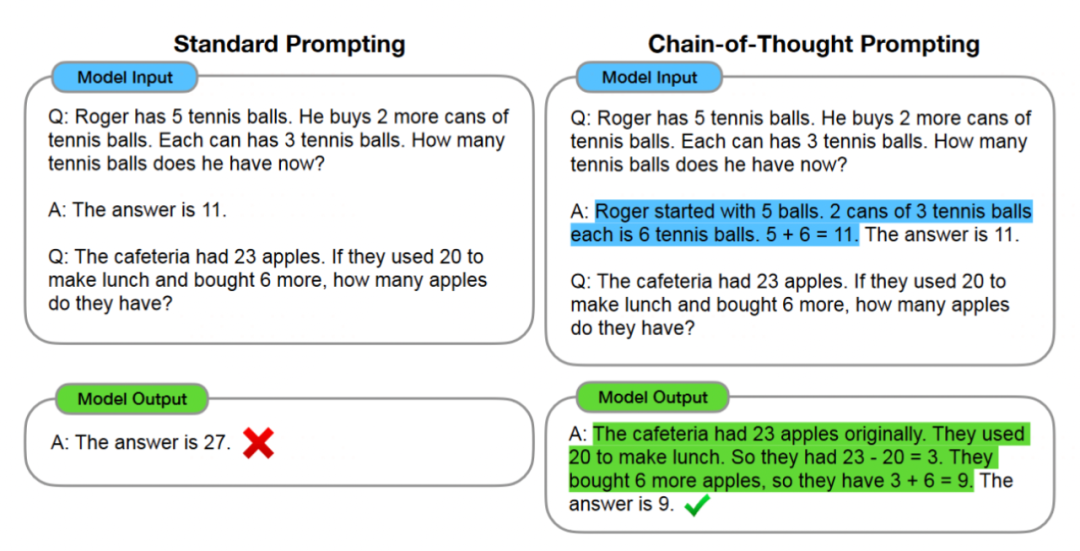
五,Self-Consistency COT (一致性思维链)
把temprature 调成大于0,如0.4. 然后让模型多回答几次,对回答结果进行投票,可以显著改善 COT。
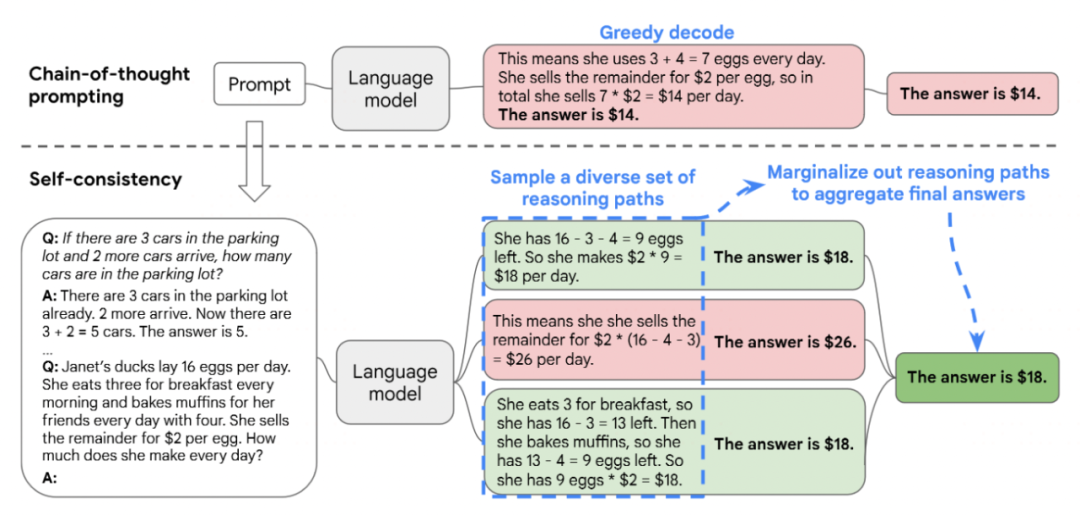
六,Zero-Shot COT (零样本思维链)
不提供范例,只在prompt的结尾加入"Let's think step by step (让我们一步步思考)“ 能够取得接近 COT的效果。
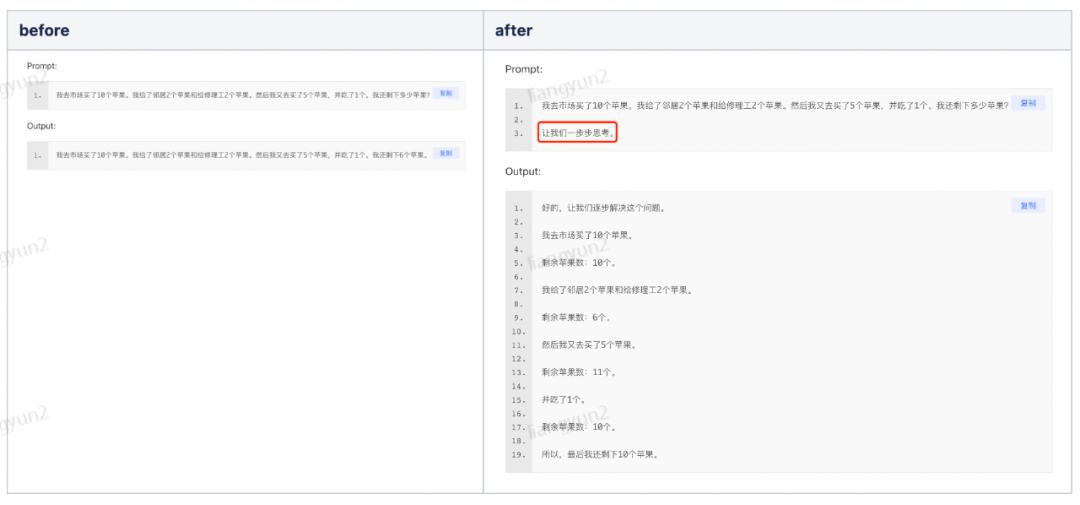
也可以试试: Let's work this out in a step by step way to be sure we have the right answer. 让我们逐步解决这个问题,以确保我们得到正确的答案。
根据测试这个 咒语效果更好。

七,Self-ask Prompt (自我提问)
在prompt范例中引导LLM将一个复杂的问题拆分为简单的子问题,逐个回答,然后汇总成为答案。
和COT思维链效果有些类似,但同时要求LLM提出子问题并给出答案,对生成内容的约束更大,有时候效果更好。

八,ReACT(Reaon+Act 协同思考和动作 )
按照 think(思考)->act(行动)->observation(观察)->think→act→observation...的模式来解决问题。
ReACT是以强化学习这种范式实现的,需要定义一个可以交互的环境env。
智能体agent就是LLM。act就是和环境交互(如查询互联网,调用工具,执行代码等)。

AutoGPT也是这种强化学习范式prompt的产物,AutoGPT设计的主要prompt模式如下:
Thoughts(当前的思考)->Reasoning(推理过程->Plan(后续计划)->Criticism(自我批判审视)->Next action(下一步行动)
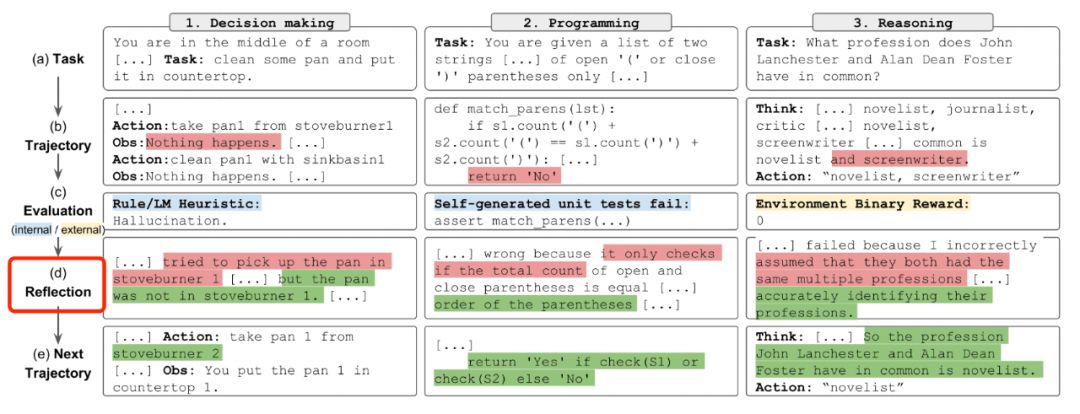
九,Reflexion (失败后自我反思)
按照 任务->尝试->评估->如果失败则反思(Reflection)失败原因->再次尝试→...的模式来解决问题。
加了Reflection步骤可以明显提升成功率。作者认为反思步骤可以帮助LLM建立长期记忆或者经验。
Reflection也是以强化学习范式实现的,需要定义一个可以交互的环境env,和ReACT出自同一批作者。
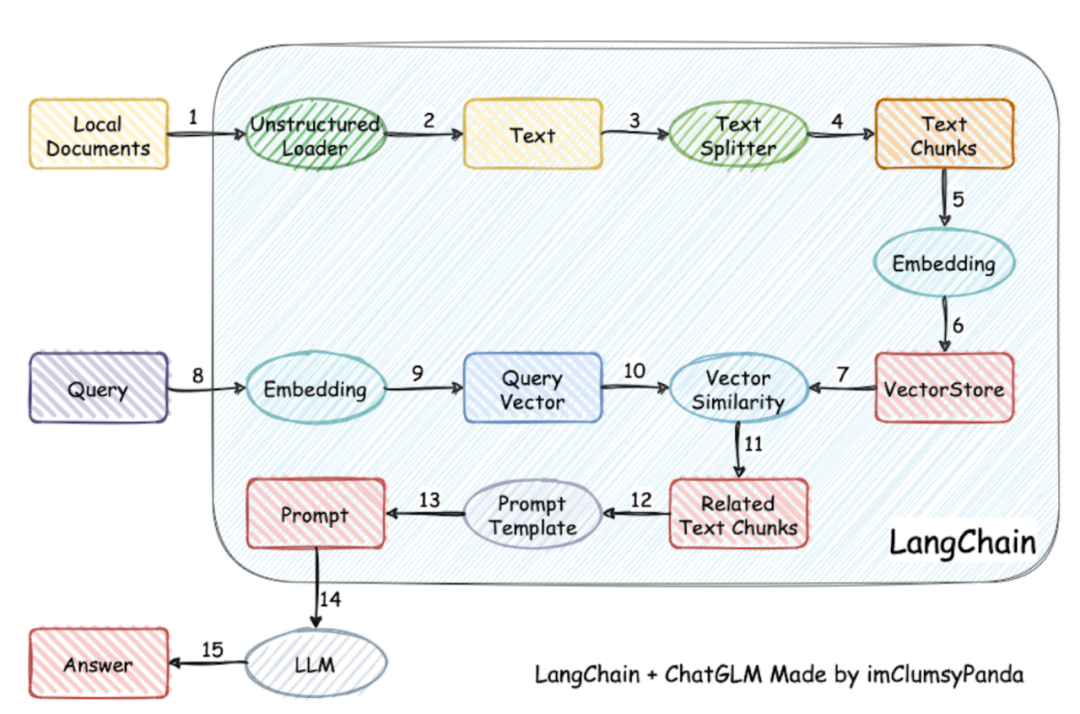
十,Langchain
将本地文档做成知识库,根据Query问题按照文本emedding向量相似度查询到最相关的知识内容,按照模版拼接到Prompt中。
核心技术是Embedding算法,以及向量数据库查询。
公众号算法美食屋后台回复关键词:chatgpt,获取本文notebook源码以及吃货更多chatgpt相关prompt技巧分享~

