
- 1理解Android编译命令_msm8916系统编译
- 2java中String xx xx_Java中常用String方法
- 3TCP原理和三次握手和四次挥手过程_tcpip的三次握手的原理和过程
- 4android通过包名打开指定应用程序,android 通过包名启动其他app并打开指定的页面...
- 5YOLO Nano:一种高度紧凑的只看一次的卷积神经网络用于目标检测
- 6软件开发技术文档编写规范_软件使用手册编写规范
- 7Python实现学生信息管理系统_利用python语言中的组合数据类型对学号和姓名进行存储,并实现利用学号访问姓名和
- 8Linux进程间通信有哪些方式,优缺点如何_比较linux系统中pipe、clone、shm和msg四种高级通讯方法的优缺点以及各自适应的环
- 9全球最大的 ChatGPT 开源替代品来了,支持 35 种语言,网友:不用费心买 ChatGPT Plus了!_海外openai chatgpt的替代品
- 10C实现WebSocket服务端与订阅端以及HTML5的WebSocket_ccgi websocket
【分布式】分布式共识算法 --- RAFT_分布式共识的定理
赞
踩
2.CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
It states, that though its desirable to have Consistency, High-Availability and Partition-tolerance in every system, unfortunately no system can achieve all three at the same time.
在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值,即写操作之后的读操作,必须返回该值。(分为弱一致性、强一致性和最终一致性)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择
要满足CAP理论,而分布式共识算法解决的就是CAP理论中的一致性问题。整个一致性问题分为三种问题:
- 顺序一致性
- 线性一致性
- 因果一致性
其中线性一致性要求所有线程的操作按照一个绝对的时钟顺序执行,这意味着线性一致性是限制并发的,否则这种顺序性就无法保证。由于在真实环境中很难保证绝对时钟同步,因此线性一致性是一种理论。
实现线性一致性的代价也最高,但是实战中可以弱化部分线性一致性:只保证有因果关系的事件的顺序,没有因果关系的事件可以并发执行,其指的是假设有两个事件:A事件和B事件,如果A发生在B后面,那么就称A和B具有因果关系。
Paxos和Raft这些分布式共识算法就是用来多个节点之间达成共识的,其可以解决一定的一致性问题。其中raft对于分布式的入门者来说最好理解,因此,我们选择raft作为我们的讲解目标。
2. 共识算法RAFT
2.1 数据处理流程
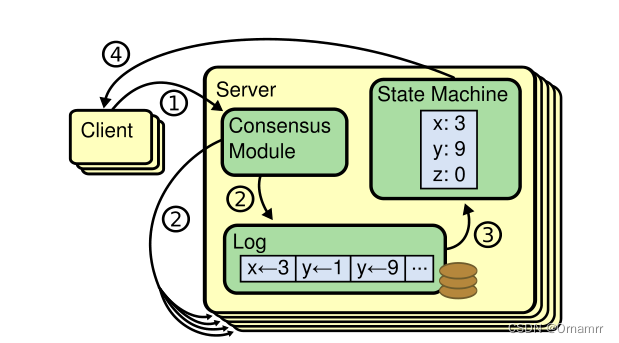
在深入了解raft的实现之前,我们需要先对拥有raft的分布式集群有一个宏观了解。
当我们向集群中的每一台主机中加入一致性协议之后,我们数据的存储会发生什么变化?
根据上图我们可以大致推断:
- 客户端发出命令,被集群中的一台机器接收,不直接提交到状态机(State Machine)进行持久化,而是先提交到 共识协议层(Consensus Moudle)
- 共识协议层(Consensus Moudle)将客户端命令持久化到本地日志中,同时分发到其他机器上
- 当其他机器会收到含有命令的日志,并持久化,最后从日志中取出命令,应用到状态机
2.2 RAFT 详解
2.2.1 RAFT 状态机
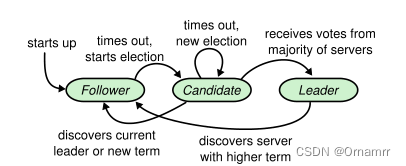
遵循Raft算法的分布式集群中每个节点扮演以下三种角色之一:
leader:领导者,其负责和客户端通信,接收来自客户端的命令并将其转发给follower
follower:跟随者,其一丝不苟的执行来自leader的命令
candidate:候选者,当follower长时间没收到 leader的消息就会揭竿而起成为候选者,抢夺成为leader的资格
2.2.2 节点数据结构定义

其中各个字段分为需要持久化的与不需要持久化的(易失的):
持久化状态
| 参数 | 解释 |
|---|---|
| currentTerm | 服务器最新任期,可理解为逻辑时钟 |
| voteFor | 当前term内自己给候选人投票的候选人Id,未投票则为-1 |
| log[] | 日志条目,单条日志包括 客户端操作,leader接收到该条目时的term,以及日志索引(初始为1,如图) |
currentTerm 参数raft集群内的逻辑时钟值,全局递增,准确来说时Lamport Timestamp的变体。
Lamport Timestamp算法
该算法十分简单,当一个集群内的多台机器需要维护一个全局时间,可以这样做:
- 每个进程本地存储一份全局时间副本
- 某进程内时间发送,递增自身时间副本
- 发送消息时附加上时间副本值
- 收到消息,比较消息中与自己的时间副本值,选择较大的时间值加1,并更新自身时间
易失性状态
| 参数 | 解释 | 初始值 |
|---|---|---|
| commitIndex | 已知提交的最高的日志条目的索引 | 0 |
| lastApplied | 已知被应用到状态机的最高的日志条目的索引 | 0 |
除此之外,Leader还维护了两个数组:
Leader易失性状态
| 参数 | 解释 | 初始值 |
|---|---|---|
| nextIdx [] | 对于i号节点,发送到该节点的下一跳日志的索引 | Leader最后日志条目索引+1 |
| matchIdx[] | 对于i号节点,已知的已经复制到该节点的最高日志条目的索引 | 0,单调递增 |
2.2.3 节点 RPC 操作
2.2.3.1 请求投票(RequestVote)
候选人发起选举投票RPC到集群内的其他节点
- 请求参数 (RequestVoteArgs)
| 参数 | 解释 |
|---|---|
| term | 候选人任期号 |
| candidateId | 候选人Id |
| lastLogIndex | 候选人最后的日志条目的索引 |
| lastLogTerm | 候选人最后日志条目的term |
- 响应参数 (RequestVoteReply)
| 参数 | 解释 |
|---|---|
| term | 当前任期号,帮助候选者更新自身任期号 |
| voteGranded | 候选人是否赢得此张选票 |
-
选举逻辑
- 节点为Canaditate
选举准备操作
- 自增当前的term,
- 给自己投一票
- 重置选举超时计时器
发送RPC投票请求到其他server
选举中操作
- 接收到超过半数节点的选票,变为Leader
- 接收到到来自Leader的日志追加RPC,变回Follower
- 选举超时前未发生2或3,再次发起选举
- 节点为 Follower
状态变更准则:
如果在自身选举超时时间超时前未收到Leader的心跳或者日志追加,也没有给某个Candiate投票,那么自己变成候选人
投票准则:
- 如果候选人term小于currentTerm ,拒绝投票,并且返回currentTerm让候选人更新
- 如果voteFor为-1或者恰好等于Candidate,则将候选人的最后一条日志与自己的最后一条日志term进行对比,大于自己则投票,小于自己则拒绝,相等则比较索引
练习: 根据教程结合RAFT论文,实现raft的选举机制
2.2.3.2 心跳通知与日志追加(AppendEntires)
请求参数(AppendEntriesArgs)
| 参数 | 解释 |
|---|---|
| term | Leader任期号 |
| leaderId | LeaderId |
| prevLogIndex | 新日志之前的那条日志索引 |
| prevLogTerm | 新日志之前的那条日志任期 |
| entries | 需要被追加与保存的日志条目列表(做心跳时日志条目为空) |
| leaderCommit | Leader已知的已经提交的最高的日志条目索引 |
响应参数(AppendEntriesReply)
| 参数 | 解释 |
|---|---|
| term | 当前任期 |
| success | 结果为真,则说明follower的所有日志与prevLogIndex,preLogTerm匹配 |
- 具体逻辑
前置逻辑
- 如果接收到的RPC请求或请求中,term >currentTerm,那么更新currentTerm = term,并变更状态为follower. 这一点体现了term的逻辑时钟的作用
- 如果commitIndex > LastApplied,那么LastApplied++,将索引为LastApplied的日志应用到状态机
节点为Leader
- 选举成功成为领导人之后,立即发送心跳(空日志)到其他节点,按照一定时间间隔不断发送,避免其他节点超时触发选举
- 接收到client的请求,先附加日志条目到本地日志中,在条目被引用到状态机后响应client
- 对于一个follower,如果最后一条日志的索引大于等于nextIndex,则发送从nextIndex开始的所有日志条目
追加成功: 更新nextIndex和matchIndex中follower对于的值
追加失败: 发送日志冲突,Leader减少nextIndex进行重发尝试
当半数节点已经收到某条日志,即存在一个数N 满足N>commitIndex,且大多数的matchIndex[i]>=N成立,且log[N].term == currentTerm成立,那么更新commitindex为N
节点为follower
- 如果Leader的term小于 自身的term ,返回false
- 在接收者的日志中,如果能够找到一个日志条目的prevLogIndex以及prevLogTerm与请求中的相同,那么继续执行,否则返回false
- 如果一个已经存在的条目和待追加日志条目发送冲突,即index相同,term不相同,那么删除该已经存在的日志以及其之后的所有日志,保证Leader的绝对权威
- 追加日志中不存在的所有新日志
如果leadcommit > commitIndex,即领导者的已知提交到最高日志索引大于接收者的已知的最高的日志索引,则把commitIndex重置为 min(leadercommit,最新日志的索引)

