
- 1【VScode技巧】:platformio部署ESP32Cam开发板_esp32 cam platformio
- 22022.03.30华为前端、后端算法第二题_给定一个m*n的整数矩阵作为地图,矩阵数值为地形高度,中庸行者选择其中任意一
- 3【HarmonyOS NEXT】使用router.pushNamedRoute方法,传递options参数时报语法错误_arkts-no-obj-literals-as-types
- 4docker安装nginx_docker 安装 nginx
- 5Arraylist、LinkedList和Vector三者区别_3、arraylist、linkedlist、vector有什么区别?
- 6android studio 镜像配置_android studio配置国内镜像
- 7用于目标检测的细粒度动态头_细粒度目标检测
- 8Android使用WebView加载网页及数据_安卓webview 挂载数据
- 9关于使用C#调用Win32API,抓取第三方句柄,模拟鼠标点击,键盘发送事件(C2Prog.exe)_win32api取得鼠标按键
- 10华为emui11鸿蒙,鸿蒙2.0系统回退EMUI11工具下载
SRGAN超分辨率网络
赞
踩
1、SRGAN是第一篇将GAN引入超分领域的论文,旨在提升画面的真实性。
2、SRGAN是一个超分辨网络,利用生成对抗网络的方法实现图片的超分辨。
目录
前言
论文:http://arxiv.org/abs/1609.04802
一、SRGAN主要介绍
1、超分辨率问题
由低清图像恢复的高清图像采用的是MSE(Mean Square Error)作为损失函数,该损失函数会造成恢复出来的图像高频信息不足,视觉感知不佳。
使用MSE训练的网络恢复出的图像高频信息不足,整体图像趋于模糊。基于此问题,SRGAN提出使用GAN将恢复的图像拟合到真实数据集的分布上。
论文中有一幅图很好的解释了区别:

超分辨率是一个病态问题(ill-posed),一个低清图像块可以对应多个高清图像块。而MSE得到的结果就像是这多个高清图像块(红色框框的图像块)的一个平均,这样所得图像很模糊,不符合真实高清图像(有高中低频信息)的分布,而GAN可以将其拉向真实高清图像的分布(黄色框框的图像块)。
2、解决问题的方法
1、网络层面:使用更深的网络去拟合更复杂的映射关系,论文找你采用4x采样,退化更加明显,从低清到高清的映射更加复杂。
2、损失层面:加入perceptual loss. perceptual loss = content loss + adversarial loss
3、评价指标层面:使用更符合人眼感知的MOS分(mean-opinion-score)评价生成结果。
二、SRGAN主要内容
研究背景:单图像超分辨率(SISR)的准确性和速度取得了突破性进展,但仍然存在一个问题:当我们在大的放大因子下进行超分辨率时,如何恢复更细腻的纹理细节。
研究目的:提出一种生成对抗网络(GAN)用于图像超分辨率(SR),它能够推断出4倍放大因子下的照片级自然图像。为了实现这一目标,作者提出了一种感知损失函数,它由对抗损失和内容损失组成。
1、三个解决问题的方法层面论述
(1)网络层面
因为采用GAN的方式,所以有生成器和判别器。
生成器就是SR通常使用的网络。判别器同样是一个网络结构,其目的是为了判别生成的图像和真实的高清图像。通常判别器的输出一个是一个概率值,表示输入是真实图像的概率。一个好的判别器可以将生成的图像判别为假,真实的高清图像判别为真。
生成器和判别器交替训练。
小tip:为什么判别器要交替训练,为什么不能直接训练一个分类器,然后它有良好的分类性能,直接用这个分类损失做监督不就好了么?
答:不可以,因为并不知道真实的SR的结果是什么,也就是我们没有真实负样本的分布,所以要交替训练。直到判别器判别不出生成图像和真实图像,此时表示生成图像的分布拟合了真实高清图像的分布。
SRGAN由于要解决4x退化的问题,从低清到高清图像有更复杂的映射。所以它采用更深的网络来拟合这种映射。但是更深的网络有一个问题:不容易训练。
针对该问题,论文采用了两个方法缓解:1)添加BN层(Batch Normalization);2)建立跳跃链接(skip-connection) + residual block.
生成器的网络结构:
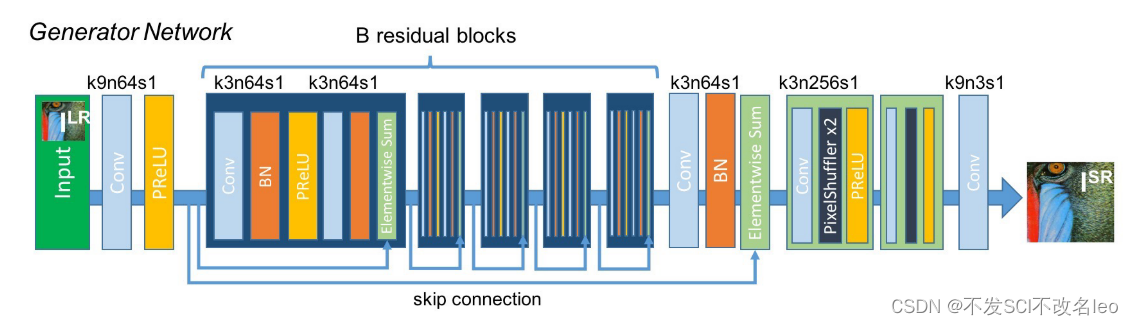
每一个block有Conv-BN-PReLU-Conv-BN-Sum的结构。
跳跃连接有两个地方:1)在block内部有skip-connection; 2) 多个block也由skip-connection进行连接。
生成器一共有16个blocks。
判别器的网络结构:
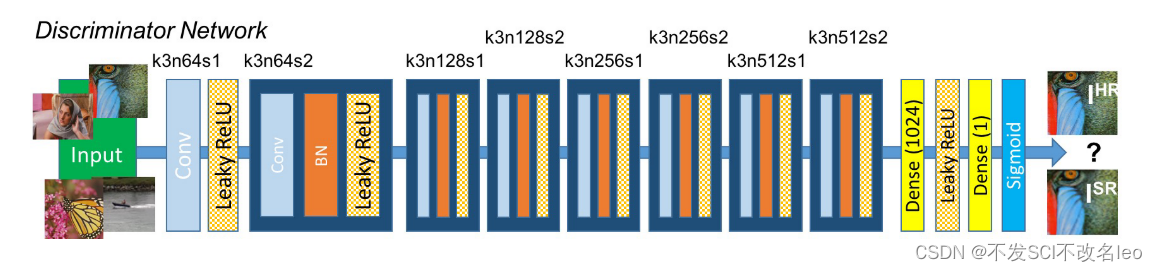
判别器含有8个卷积层,从第2个卷积层开始,每一个卷积层后面加一个BN层来归一化中间层feature map的分布。判别器采用stride=2来降低分辨率。
注:BN层的引入可加速网络的训练,但是BN层测试时采用的是训练集数据均值和方差的统计量。当测试数据和训练数据分布不一致时,结果会产生artifacts(所以ESRGAN的时候作者去掉了BN层)。
(2)损失层面
使用perceptual loss来提升图像真实度。
perceptual loss= content loss + adversarial loss
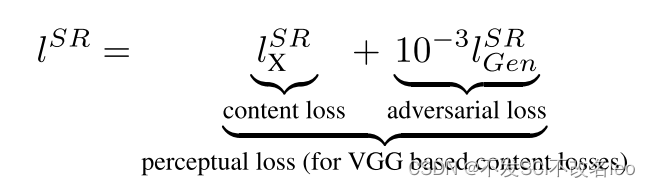
问:前面说到在像素层面计算损失容易使图像模糊,缺乏高频信息。那在特征层面进行损失计算呢?
答:比像素层面好。特征层面会各种结构化信息,例如边缘、形状等,当在特征层面约束生成图像和真实图像一致可以避免生成的图像模糊,提升视觉感知。
content loss便采用VGG19网络进行特征提取,在特征层面对生成图像和真实图像进行约束。
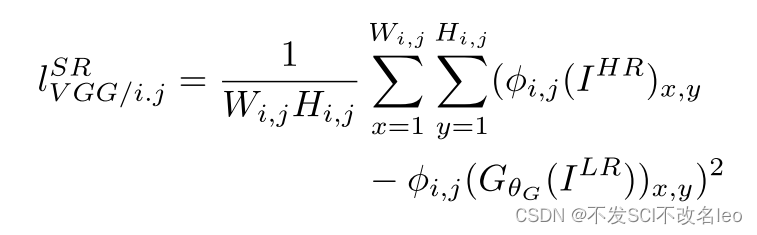
其中, φi,j表示第i个max-pooling层前的第j个卷积并经过激活层后的feature map.
论文发现:vgg损失所计算的feature map越由高层网络得到,网络越生成更好的纹理细节
adversarial loss采用公式如下:

其中, , DθD(GθG(ILR))表示的是判别器认为生成图像为真的概率。对抗损失没有采用原生GAN的loss,而是使用−logDθD(GθG(ILR))是为了给生成器提供更好的梯度。
(3)评价指标方面
评价指标不单纯使用PSNR,还使用了MOS分。
PSNR(Peak Signal to Noise Ratio):峰值信噪比
峰值信噪比经常用作图像压缩等领域中信号重建质量的测量方法,它常简单地通过均方差(MSE)进行定义。两个m×n单色图像I和K,如果一个为另外一个的噪声近似,那么它们的的均方差定义为:
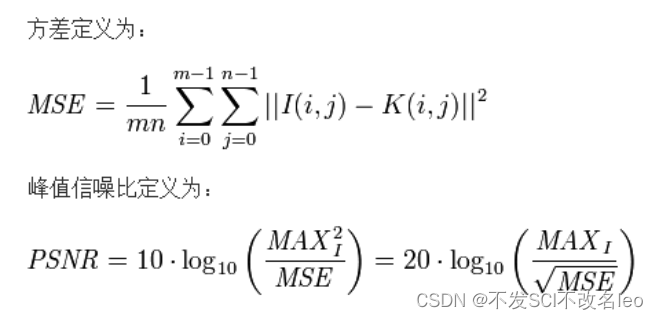
MOS分则是让用户看图像并从1-5进行打分,1为最差,5为最好,然后统计分值。该评价指标所得结果可以说明人的视觉感知。当MOS分高时表示图像符合人的视觉感知,否则不符合。

从上图可观察道HR MOS分最高,因为其本身就是高清图像;SRGAN其次,说明了SRGAN在提升图像真实度上是可信的。
三、结论
我们已经描述了深度残差网络SRResNet,当使用广泛使用的PSNR度量进行评估时,该深度残差网络SRResNet在公共基准数据集上设置了新的技术状态。我们已经强调了这种PSNR聚焦图像超分辨率的一些限制,并引入了SRGAN,它通过训练GAN来增强具有对抗性损失的内容损失函数。使用广泛的MOS测试,我们已经证实,SRGAN重建的大放大因子(4×),通过相当大的余量,比用现有技术的参考方法获得的重建更照片逼真。

