
- 1通信及信号处理领域期刊影响因子、分区及期刊推荐-2024版_信号处理顶刊
- 2request对象的常用方法_列举request对象的常用方法并解释其作用,至少5个。
- 3用单库自增键来生成id了,后期怎么分库?哎,这个坑大!_自增id后期分表分库怎么处理
- 4基于WinForm的c#上位机制作_基于c#上位机制作(winform控件) | 程序员灯塔
- 5微信小程序自动回复用户消息_微信小程序客服自动回复源码
- 6Python快速无限制使用接口实现AI小说续写:API详解与代码示例_小说网站api
- 7LSTM实现时间序列预测(PyTorch版)_pytorch lstm预测时间序列实战-准备数据
- 8GNN图神经网络的Python实现_gnn python
- 9【uniapp】【微信小程序】微信小程序报错集锦(一)_hidetabbar:fail not tabbar page
- 10springboot中的restTemplate访问get,post请求的各种方式_springboot resttemplate post
基于时频域统计特征提取的自然环境声音识别方法_有什么软件能识别声音的不同来源类型
赞
踩
Description
基于时频域统计特征提取的自然环境声音识别方法
技术领域
[0001] 本发明属于声音信号识别技术领域,尤其涉及一种基于时频域统计特征提取的自 然环境声音识别方法。
背景技术
[0002] 近年来自然环境声音的识别取得了广泛的关注,自然环境中充满了多种声音,如 车辆行驶中的发动机声和汽车喇叭声,建筑工地上的施工声音,人的说话声,鸟虫鸣叫声, 风雨声等。自然环境声音的识别是机器监控的一个重要部分,对建设智慧城市和发展智能 家居也有重要的作用。
[0003]目前的自然环境声音识别技术,在特征提取方面使用的技术大多借鉴于语音识别 算法,包括:线性预测倒谱系数(LPCC)、梅尔频率倒谱系数(MFCC)、过零率(ZCR)等。但此类 特征用于语音信号的识别,是以语音的短时平稳性为基础的,自然环境中的声音却并非都 具有短时平稳性。同时,由于声音信号在传播中的的衰减效应,单一的时域特征如LPCC、ZCR 或者单一的频域特征如MFCC,都不能够准确的描述不同距离下的自然环境声音信号。因此, 语音识别的特征提取方法,在对自然环境声音的识别方面并不能完全适用。
发明内容
[0004]针对目前存在如以上所述的技术问题,本发明提供了一种基于时频域统计特征提 取的自然环境声音识别方法。针对不同声音信号如发动机声、汽车喇叭声、建筑施工声、说 话声等,根据其能量随时间变化程度的区别和频谱能量分布上的区别,对各类自然环境中 的声音进行识别,判断目标声音所属的类别。
[0005]为了实现上述目的,本发明采用技术方案包括如下步骤:
[0006]步骤1、采集各类自然环境声音,建立声音样本库;
[0007]步骤2、声音样本信号的加窗分帧处理;
[0008]步骤3、提取所有帧信号在时域上的统计特征:平均帧能量变化系数、能量冲击型 帧信号占比、平均能量脉冲宽度、脉冲宽度离散程度、平均脉冲间隔宽度、间隔宽度离散程 度和脉冲个数,以及在频谱分布上的特征:频带能量分量占比、频带帧能量分布离散程度和 总频带帧能量分布离散程度,组成特征向量;
[0009]步骤4、标记特征向量所属声音来源的种类,建立样本特征库;
[0010] 步骤5、利用支持向量机训练特征向量,建立训练模型;
[0011] 步骤6,提取目标声音的特征向量;
[0012] 步骤7、利用支持向量机对目标声音的特征向量进行匹配分类;
[0013] 步骤8、提供识别结果。
[0014] 所述步骤1的建立声音样本库:将声音采集装置放置在户外施工现场,按照不同的 距离采集自然环境声音,并给声音标定其所属自然环境声音的种类后作为声音样本库。自 然环境声音包括:发动机声、汽车喇BA声、建筑施工声、说话声和现场风噪声。
[0015]所述步骤2的声音样本信号的加窗分帧处理:首先对声音进行滤波处理,使用高通 滤波器滤除50Hz以下的低频干扰信号;再将声音分为一秒钟每段,对每一段声音加Hamming 窗做分帧处理,每帧选取256个采样点,为了保持帧信号间的连续性,帧移选取为128个采样 点。
[0016]所述步骤3的所有帧信号在时域上的统计特征提取过程如下:
[0017]3-1.设匕为采样频率,每秒的连续声音信号s(t)经过采样后离散化为s[n],设对 每秒信号进行分帧处理的帧长为N,帧移为总帧数为NF。则第i帧信号Sl(n)的短时帧能量 计算公式为:
[0018]

[0019] 3-2 •对所有帧能量中位值以下的帧能量取平均值,记为Emed-ave,则:
[0020]
[0021]其中Emediar^所有帧能量的中位值,而Niciwer为能量在中位值以下的帧的个数,Ei表 示中位值以下的帧能量。
[0022] 3-3.对信号s[n]做傅里叶变换,得到频谱分布信息,短时傅里叶变换的公式为:
[0023]
[0024]其中,Si(k)是第i帧信号si(n)的STFT。
[0025]3-4.根据不同种类的自然环境声音在每帧时域能量和频谱分布上的特点,取其统 计值作为每段声音的特征。每帧信号时域能量帧能量变化系数公式表示为i^,它反映的 是帧信号的能量冲击程度。为使各类自然环境声音之间具有区别性,滤除低于帧能量平均 值的帧后,取所有帧信号的平均帧能量变化系数作为特征I,即:
其 中,
为所有帧能量的平均值,mean(•)为对集合中的元素求平均值。
[0026]3-5.根据不同声音信号的特点,设定一个帧能量冲击系数的阈值T,将信号分为能 量冲击型帧信号和非冲击型帧信号,滤除低于帧能量平均值的帧后,统计一段自然环境声 音的冲击型能量帧信号所占比例,作为特征II,即
[0027]
[0028]其中,Eave5表示所有帧能量的平均值,crad(•)表示求集合中元素的个数。
[0029]由于不同的声音信号能量波形具有不同的脉冲特性,利用平均帧能量截取信号的 能量波形,即高于平均能量的帧用平均能量替代,截取后的帧能量公式为:
[0030]
[0031] 3-6.对将被截断的各帧的序号存入一个向量a,a中的数值是递增的,即a (k)〈a (k+ 1)。计算(1£1(1〇=3(1^+1)-3(1〇,1^=1,~,1(-1,其中,1(是被截断的帧的总个数。根据定义,将(1 £1 表不为《^ = [1%…MiAi…1¾]7",其中,:1丨;=[_1 _1…;L]为Ii维向量,表不有Ii个1,而 A i>l是截断能量帧的不连续点,i = l,•••〗是l-vector的数量,即这段信号的脉冲数量。因 此脉冲的宽度TMda二{以 =2,..,/-1,脉冲之间的间隔宽度^^#_ = {^:+._〖1^=2/>%7.-1。 [0032] 3-7.计算所有脉冲的宽度均值作为特征III,即Hiean(TER da);计算所有脉冲之间的 间隔宽度的平均值作为特征IV,即mean(I〇Pda);计算所有脉冲的宽度变异系数作为特征V, 即
计算所有脉冲间隔宽度的变异系数作为特征VI,即

t算所有 脉冲的个数作为特征VII,即I。
[0033] 由于不同声音信号的频谱分布不同,其能量集中在不同的频带上,因此将每帧信 号按照频率划分为三个频带,分别记为[1^,1«]、[1«,1^]、[1^,1«],整段信号 8(11)在第1^频带 的能量公式为:
[0034]

[0035] 其中
为短时傅里叶变换后,第i帧信号在第k频带的能 量分量。信号s(n)在所有频带的总能量为:
[0036]

[0037]因此能够计算第一个频带的能量占总频带比重,作为一段声音信号的特征VIII, 即^;计算第二个频带能量占总能量的比重作为特征IX,即计算第三个频带能量 tQliEaH 占总能量的比重作为特征乂,即^。 EaU
[0038]由于不同声音信号频谱特性,一段声音信号中,如说话声,建筑施工声的帧能量之 间有高低间隔的情况出现,而发动机的帧能量近似平均,即不同声音信号帧能量的离散程 度不同,且在不同频带有区别。因此,为了反映各类声音的在不同帧信号之间的各频带和总 能量上分布的离散程度,计算总频带所有帧能量的变异系数作为特征XI,即

计算第一个频带所有帧能量的变异系数作为特征XII,即
计算第二个频带所有帧能量的变异系数作为特征XIII,gp

计算第三个频带所有帧能量的变异系数作为特征XIV,即

[0039]将以上14个特征组成一个14维向量,作为一段声音信号的特征向量。
[0040]步骤4的建立样本特征库:从声音样本库中提取每一类自然环境声音样本的特征, 并给每类声音的特征标定其所属种类。
[0041]所述步骤5的建立训练模型:是利用支持向量机对样本特征库进行训练,得到训练 模型。
[0042]所述步骤6的提取目标声音特征向量:目标声音的特征提取和使用和样本声音特 征提取完全相同的过程。
[0043]所述步骤7的匹配分类:利用支持向量机对目标声音的特征向量与训练模型进行 模式匹配,给出判断结果。
[0044]本发明的有益效果如下:
[0045] 本发明的基于时频域统计特征提取的自然环境声音识别方法,由声音的特性入 手,在短时帧分析的基础上,提取帧信号在时域和频谱上的特征,弥补了传统的声音LPCC和 MFCC特征提取方法在时频结合方面的不足,满足自然环境声音的识别要求。利用本发明的 基于时频域统计特征提取的自然环境声音识别方法能够提高识别效果。
附图说明
[0046]图1为本发明方法流程图;
[0047]图2为本发明方法中的特征提取流程图;
具体实施方式
[0048]下面结合的具体实施方式对本发明作详细说明,以下描述仅作为示范和解释,并 不对本发明作任何形式上的限制。
[0049]如图1和2所示,基于时频域统计特征提取的自然环境声音(如:发动机声,汽车喇 叭声,建筑施工声,说话声)识别方法具体实施方式的步骤如下:
[0050] 步骤1、将采样频率为fs的声音采集装置放置在距离声源点不同距离处,多次采集 每类自然环境的声音,标定声音所属类型后作为声音样本库。
[0051] 步骤2、将声音样本进行预处理,通过高通滤波器,滤除50Hz以下的低频干扰信号, 再将声音分帧为分为一秒钟每段,并对每段信号加Hamming窗做分帧处理,每帧选取256个 采样点,帧移选取为128个采样点。
[0052]步骤3、组成样本特征向量步骤,分析每帧信号在时域及频谱上的特性,选取分析 结果的统计值作为特征组成特征向量,具体分步操作如下:
[0053] (1)每秒的连续声音信号s(t)经过采样后离散化为s[n],对每秒信号进行分帧处 理的帧长为N,帧移为f,总帧数为N F。第i帧信号Sl(n)的短时帧能量为玛二Egfl1 Si2Ox),对所有 帧能量中位值以下的帧能量取平均值,记丨
其 中Eme5diar^所有帧能量的中位值,而Ni_r为能量在中位值以下的帧的个数,Ei表示中位值以 下的帧能量。对信号做短时傅里叶变孩
it = 0,... ZV - 1, 其中,S1QO是第i帧信号Sl(n)的STFT,得到信号频谱分布信息。
[0054] (2)计算每帧的能量变化系数:
作为特征量II;
[0056] (4)取所有帧能量的平均值£ave5,用Eave^取帧能量波形,得到截取的帧能量:

|等被截断的各帧的序号存入一个向量8,计算(1£1(1〇=3(1^+1)-3(1〇,1^ = 1,…,K-I,其中,K是被截断的帧的总个数。将da表示为这种形式:4 = [Ii1A1 ... 1% ... 其中,

^Jli维向量,表示有Ii个1,而A i>l是截断能量帧的不连续点,i =1,…〗是1-vector的数量,即这段信号的脉冲数量。因此截取脉冲的宽度
截取脉冲之间的间隔宽度

[0057] 计算所有脉冲的宽度均值:,作为特征III;计算所有脉冲之间的间隔 宽度的平均值_0«()<>%),作为特征IV;计算所有脉冲宽度的变异系数

作 为特征V;计算所有脉冲间隔宽度的变异系数

作为特征VI;计算所有脉冲的个 数:I,作为特征VII。
[0058] (5)计算短时傅里叶变换后,第i帧信号在第k频带的能量分量:Eg(k) = ISiWI2 X^ 信号s(n)在所有频带的总能量:

将信号划分为[1^,1«]、[1«,1^]、
[k5,k6]三个频带,计算整段信号s(n)在第k频带的能量:

[0059] 计算第一个频带的能量占总频带比重:^,作为一段自然环境声音信号的特征 t'all VIII;计算第二个频带能量占总能量的比重,作为特征IX;计算第三个频带能量占总 ^all 能量的比重作为特征X。
[0060] 计算总频带所有帧能量的变异系数

作为特征XI; 计算第一个频带所有帧能量的变异系数

乍为特征XII;计 算第二个频带所有帧能量的变异系数:

作为特征XIII;计算 第三个频带所有帧能量的变异系数
作为特征XIV。
[0061] 将以上14个特征组成14维向量,作为一段声音信号的特征向量。
[0062] 步骤4、提取所有类型声音的特征向量,标定所属种类,建立样本声音的特征向量 库;
[0063] 步骤5、利用支持向量机对样本特征库进行分类训练,建立训练模型;
[0064] 步骤6、使用与样本声音同样的采集装置采集目标声音,按照与声音样本同样的步 骤提取目标声音的特征向量;
[0065]步骤7、利用支持向量机将目标声音的特征向量与已建立的训练模型做匹配,提供 分类结果;
[0066]步骤8、目标声音识别结果步骤,根据支持向量机提供的分类结果判断目标声音所 属的来源种类。
Claims (8)
Hide Dependent
1. 基于时频域统计特征提取的自然环境声音识别方法,其特征在于需要提取所有帧信 号在时域上的统计特征:平均帧能量变化系数、能量冲击型帧信号占比、平均能量脉冲宽 度、脉冲宽度离散程度、平均脉冲间隔宽度、间隔宽度离散程度和脉冲个数,以及在频谱分 布上的特征:频带能量分量占比、频带帧能量分布离散程度和总频带帧能量分布离散程度, 组成特征向量。
2. 根据权利要求1所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于在提取所有帧信号在时域上的统计特征前,对声音样本信号的加窗分帧处理:首先对 声音进行滤波处理,使用高通滤波器滤除50Hz以下的低频干扰信号;再将声音分为一秒钟 每段,对每一段声音加 Hamming窗做分帧处理,每帧选取256个米样点,为了保持帧信号间的 连续性,帧移选取为128个采样点。
3. 根据权利要求2所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于声音样本信号来源于声音样本库,将声音采集装置放置在户外施工现场,按照不同的 距离采集自然环境声音,并给声音标定其所属自然环境声音的种类后作为声音样本库。
4. 根据权利要求3所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于所述步骤3的所有帧信号在时域上的统计特征提取过程如下: 3-1.设fs为采样频率,每秒的连续声音信号s(t)经过采样后离散化为s[n],设对每秒信 号进行分帧处理的帧长为N,帧移为总帧数为NF;则第i帧信号Sl(n)的短时帧能量计算公 式为:

3-2.对所有帧能量中位值以下的帧能量取平均值,记为Emed-_,则:

其中所有帧能量的中位值,而Ni_r为能量在中位值以下的帧的个数,Ει表示中 位值以下的帧能量; 3-3.对信号s[n]做傅里叶变换,得到频谱分布信息,短时傅里叶变换的公式为:

其中,Si(k)是第i帧信号Si(n)的STFT; 3-4.根据不同的自然环境声音在每帧时域能量和频谱分布上的特点,取其统计值作为 每段声音的特征;每帧信号时域能量帧能量变化系数公式表示为
•用于反映帧信号 的能量冲击程度;在滤除低于帧能量平均值的帧后,取所有帧信号的平均帧能量变化系数 作为特征I,即
为所有帧能量的 平均值,mean( ·)为对集合中的元素求平均值; 3-5.根据不同自然环境的特点,设定一个帧能量冲击系数的阈值T,将信号分为能量冲 击型帧信号和非冲击型帧信号,滤除低于帧能量平均值的帧后,统计一段自然环境声音的 冲击型能量帧信号所占比例,作为特征II,即
其中,Ε_表示所有帧能量的平均值,crad( ·)表示求集合中元素的个数; 由于不同的声音信号帧能量波形具有不同的脉冲特性,利用平均帧能量截取信号的能 量波形,即高于平均能量的帧用平均能量替代,截取后的帧能量公式为:

3-6.对将被截断的各帧的序号存入一个向量a,a中的数值是递增的,即a(k)〈a(k+l); Sda(k)=a(k+l)-a(k),k=l,···,K-1,其中,K是被截断的帧的总个数;根据定义,将d a表示 为、
为li维向量,表示有li个1,而 Δ i>l是截断能量帧的不连续点,i = l,···Ι是l-vector的数量,即这段信号的脉冲数量;因 此脉冲的宽度

脉冲之间的间隔宽度

3-7.计算所有脉冲的宽度均值作为特征III,即mea.77.^T£7?d(J;计算所有脉冲之间的 间隔宽度的平均值作为特征IV,即mean(/oPdiJ;计算所有脉冲的宽度变异系数作为特征 V,即
计算所 有脉冲的个数作为特征VII,即I; 3-8.由于不同声音信号的频谱分布不同,其能量集中在不同的频带上,因此将每帧信 号按照频率划分为三个频带,分别记为[1^,1«]、[1«,1^]、[1^,1«],整段信号8(11)在第1^频带 的能量公式为:
其中

为短时傅里叶变换后,第i帧信号在第k频带的能量分 量;信号s(n)在所有频带的总能量为:

因此能够计算第一个频带的能量占总频带比重,作为一段自然环境声音信号的特征 VIII,SP

计算第二个频带能量占总能量的比重作为特征IX,即

计算第三个频带 能量占总能量的比重作为特征X,艮I
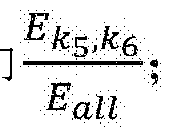
由于不同声音信号的频谱特性,为了反映自然环境声音在不同帧信号之间的各频带和 总能量上分布的离散程度,计算总频带所有帧能量的变异系数作为特征XI,即

:计算第一个频带所有帧能量的变异系数作为特征XII,即

计算第二个频带所有帧能量的变异系数作为特征ΧΠI,gp

计算第三个频带所有帧能量的变异系数作为特征XIV,即

将以上14个特征组成一个14维向量,作为一段声音信号的特征向量。
5. 根据权利要求4所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于从声音样本库中提取每一类自然环境声音样本的特征,并给每类声音的特征标定其所 属种类,形成样本特征库。
6. 根据权利要求4所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于利用支持向量机对样本特征库进行训练,得到训练模型。
7. 根据权利要求4所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于提取目标声音特征向量,目标声音的特征提取和使用和样本声音特征提取完全相同的 过程。
8. 根据权利要求4所述的基于时频域统计特征提取的自然环境声音识别方法,其特征 在于利用支持向量机对目标声音的特征向量与训练模型进行模式匹配,给出判断结果。
Patent Citations (7)
Publication numberPriority datePublication dateAssigneeTitle
EP1100073A2 *1999-11-112001-05-16Sony CorporationClassifying audio signals for later data retrieval
CN101599271A *2009-07-072009-12-09华中科技大学一种数字音乐情感的识别方法
CN102254552A *2011-07-142011-11-23杭州电子科技大学一种语义增强型交通车辆声信息融合方法
CN102708861A *2012-06-152012-10-03天格科技(杭州)有限公司基于支持向量机的不良语音识别方法
EP2860706A2 *2013-09-242015-04-15Agnitio S.L.Anti-spoofing
CN105118516A *2015-09-292015-12-02浙江图维电力科技有限公司基于声音线性预测倒谱系数的工程机械的识别方法
CN105139852A *2015-07-302015-12-09浙江图维电力科技有限公司一种基于改进的mfcc声音特征的工程机械识别方法及识别装置
Family To Family Citations
* Cited by examiner, † Cited by third party
Cited By (2)
Publication numberPriority datePublication dateAssigneeTitle
CN106950544A *2017-03-062017-07-14哈尔滨工程大学一种基于dsp实现的大时宽信号分段识别的方法
CN108650745A *2018-06-282018-10-12重庆工业职业技术学院一种灯光智能控制系统
Family To Family Citations
* Cited by examiner, † Cited by third party, ‡ Family to family citation
Similar Documents
PublicationPublication DateTitle
EP1083541A22001-03-14A method and apparatus for speech detection
Drugman et al.2009Glottal closure and opening instant detection from speech signals
Wen et al.2008Blind estimation of reverberation time based on the distribution of signal decay rates
Virtanen2006Speech recognition using factorial hidden Markov models for separation in the feature space
Cai et al.2007Sensor network for the monitoring of ecosystem: Bird species recognition
CN101599271B2011-09-14一种数字音乐情感的识别方法
Deshmukh et al.2005Use of temporal information: Detection of periodicity, aperiodicity, and pitch in speech
Evangelopoulos et al.2006Multiband modulation energy tracking for noisy speech detection
Rafii et al.2011A simple music/voice separation method based on the extraction of the repeating musical structure
Brookes et al.2006A quantitative assessment of group delay methods for identifying glottal closures in voiced speech
CN103236260A2013-08-07语音识别系统
KR100930584B12009-12-09인간 음성의 유성음 특징을 이용한 음성 판별 방법 및 장치
Dean et al.2010The QUT-NOISE-TIMIT corpus for the evaluation of voice activity detection algorithms
Brandes2008Feature vector selection and use with hidden Markov models to identify frequency-modulated bioacoustic signals amidst noise
US8036884B22011-10-11Identification of the presence of speech in digital audio data
CN1141696C2004-03-10基于语音识别专用芯片的非特定人语音识别、语音提示方法
CN1342968A2002-04-03用于语音识别的高精度高分辨率基频提取方法
Jančovič et al.2011Automatic detection and recognition of tonal bird sounds in noisy environments
Rossignol et al.1998Feature extraction and temporal segmentation of acoustic signals
US9093056B22015-07-28Audio separation system and method
Hosseinzadeh et al.2007Combining vocal source and MFCC features for enhanced speaker recognition performance using GMMs
CN102682765B2013-09-18高速公路音频车辆检测装置及其方法
CN104200804B2017-05-17一种面向人机交互的多类信息耦合的情感识别方法
CN1268732A2000-10-04基于语音识别专用芯片的特定人语音识别、语音回放方法
CN100505040C2009-06-24基于决策树和说话人改变检测的音频分割方法
Priority And Related Applications
Priority Applications (1)
ApplicationPriority dateFiling dateTitle
CN201610634966.XA2016-08-042016-08-04基于时频域统计特征提取的自然环境声音识别方法
Applications Claiming Priority (1)
ApplicationFiling dateTitle
CN201610634966.XA2016-08-04基于时频域统计特征提取的自然环境声音识别方法
Legal Events
DateCodeTitleDescription
2017-01-04C06Publication
2017-02-01C10Entry into substantive examination

