
- 1Python导入csv数据画对比柱状图_python导入csv数据画柱状图
- 2使用YouTube API V3视频的完整描述- Google YouTube API V3 - Get Video Durations
- 3Redis的持久化
- 4机器学习笔记(3)—多变量线性回归
- 5sed,n,N,d,D,p,P,h,H,g,G,x,解析_linux sed h;n;x;h;x
- 6git使用中的常见操作_git上的reply
- 7qt添加资源文件_qt怎么将resource files中的图像资源设置为图标
- 8全国媒体公关服务资源分析,媒体邀约资源包括哪些?
- 9C语言 第十章 指针_#include
int main(){ float x,y,opr(float - 10H3C FAT AP、AC+FIT AP案例
【Python自然语言处理】文本向量化的六种常见模型讲解(独热编码、词袋模型、词频-逆文档频率模型、N元模型、单词-向量模型、文档-向量模型)_向量化模型
赞
踩
觉得有帮助请点赞关注收藏~~~
一、文本向量化
文本向量化:将文本信息表示成能够表达文本语义的向量,是用数值向量来表示文本的语义。 词嵌入(Word Embedding):一种将文本中的词转换成数字向量的方法,属于文本向量化处理的范畴。 向量嵌入操作面临的挑战包括:
(1)信息丢失:向量表达需要保留信息结构和节点间的联系。
(2)可扩展性:嵌入方法应具有可扩展性,能够处理可变长文本信息。
(3)维数优化:高维数会提高精度,但时间和空间复杂性也被放大。低维度虽然时间、空间复杂度低,但以损失原始信息为代价,因此需要权衡最佳维度的选择。
常见的文本向量和词嵌入方法包括独热模型(One Hot Model),词袋模型(Bag of Words Model)、词频-逆文档频率(TF-IDF)、N元模型(N-Gram)、单词-向量模型(Word2vec)、文档-向量模型(Doc2vec)
二、独热编码
One-hot编码采用N位状态寄存器来对N个状态进行编码,是分类变量作为二进制向量的表述。
首先根据提供的文本构建词典,其中的数字可以视作对应词语的标签信息或者事物的分类信息
然后基于独热编码表达法,构造一个N维向量,该向量的维度与词典的长度一直,对于给定词语进行向量表达时,其在词典中出现的响应位置的寄存器赋值为1,其余为0 示例如下
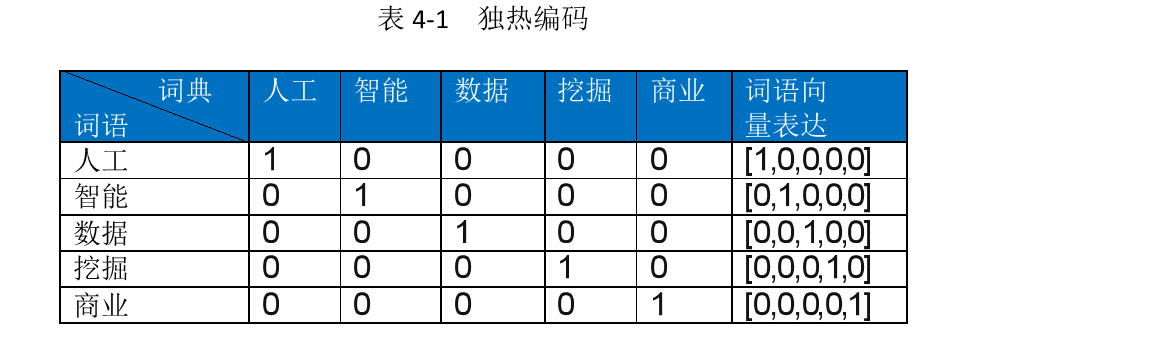
三、词袋模型
词袋模型(Bag-of-words model:BOW)假定对于给定文本,忽略单词出现的顺序和语法等因素,将其视为词汇的简单集合,文档中每个单词的出现属于独立关系,不依赖于其它单词。先将句子向量化,句子维度和字典维度一致,第 i 维上的数字代表 ID 为 i 的词语在该句子里出现的频率。

四、词频-逆文档频率模型
TF-IDF(term frequency-inverse document frequency)是数据信息挖掘的常用统计技术。TF(Term Frequency)中文含义是词频,IDF(Inverse Document Frequency)中文含义是逆文本频率指数。
词频统计的是词语在特定文档中出现的频率,而逆文档频率统计的是词语在其他文章中出现的频率,其处理基本逻辑是词语的重要性随着其在特定文档中出现的次数呈现递增趋势,但同时会随着其在语料库中其他文档中出现的频率递减下降 数学表达式如下
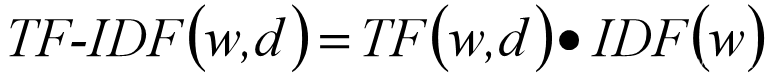
五、N元模型
N-Gram语言模型基本思路是基于给定文本信息,预测下一个最可能出现的词语。N=1称为unigram,表示下一词的出现不依赖于前面的任何词;N=2称为bigram,表示下一词仅依赖前面紧邻的一个词语,依次类推。
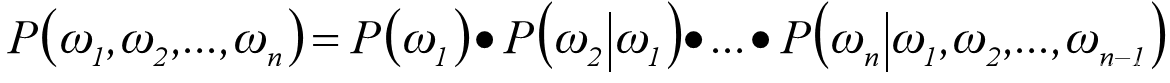
六、单词-向量模型
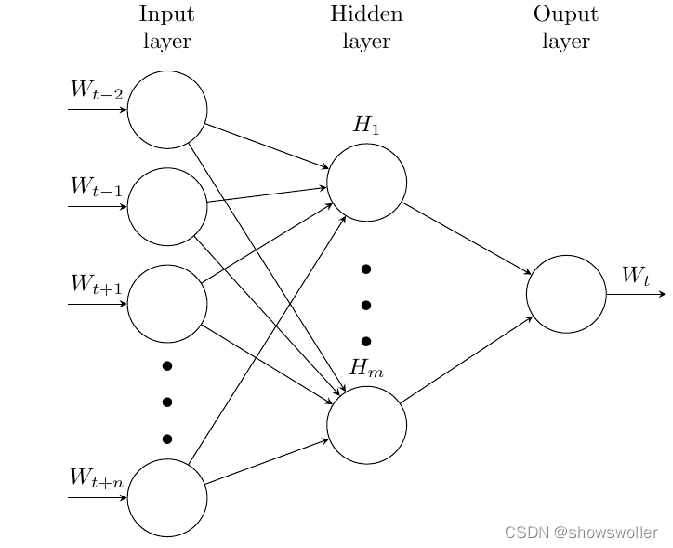
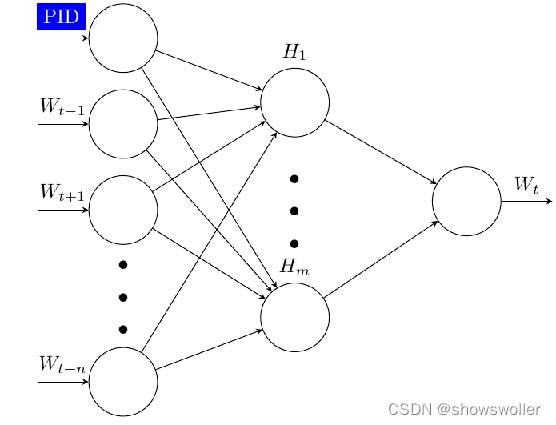
将不可计算、非结构化的词语转化为可计算、结构化的向量。word2vec模型假设不关注词的出现顺序。Word2Vec包含连续词袋模型CBOW(Continues Bag of Words)和Skip-gram模型两种网络结构。训练完成之后,模型可以针对词语和向量建立映射关系,因此可用来表示词语跟词语之间的关系
CBOW模型如下
Skip-gram模型如下
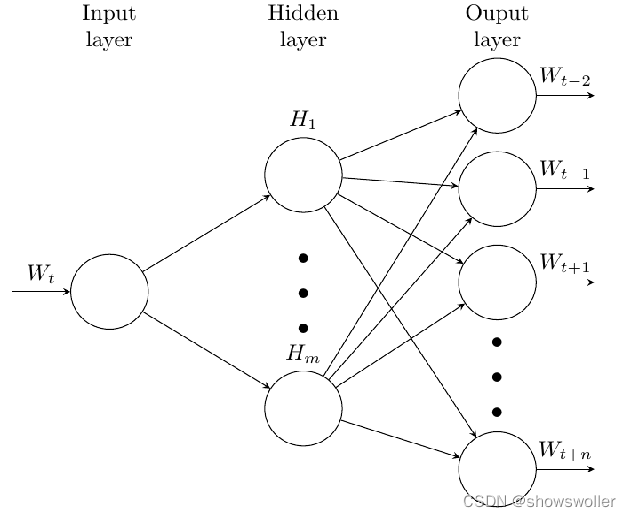
七、文档-向量模型
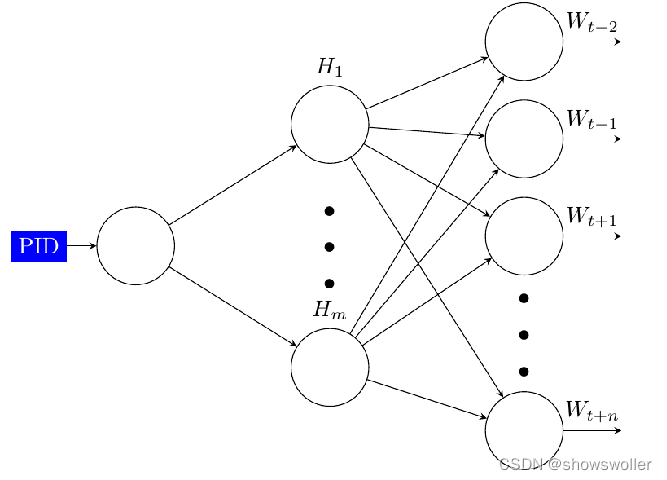
它包含两种,一种是基于段向量的分布式内存模型(PV-DM),另一个是基于段向量的分布式词袋模型(PV-DBOW),处理逻辑分别与单词-向量中的连续词袋模型和略元模型对应
DM模型如下
DBOW模型如下
创作不易 觉得有帮助请点赞关注收藏~~~


