
热门标签
热门文章
- 1【学术精选】NLP可投的顶会信息(近期截稿)_acl会议2023年收稿多少
- 2BERTopic安装最全教程及报错处理_装bertopic报错
- 3华为手机百度云息屏后停止下载_华为智选车载智慧屏评测:像手机一般好用,行车体验更便捷...
- 4python决策树分类鸢尾花_【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类...
- 50.96寸 4针OLED屏模块功能实现(STM32)_0.96寸oled显示屏4针
- 6怎么让ai写代码?三款软件帮你轻松解决
- 7Google谷歌浏览器阻止不安全内容下载_google 老是阻止不安全
- 8VLAN与三层交换机和VRRP实操_思科三层交换机vrrp配置实例
- 9学习JavaScript笔记9_"javascript 无序列表对象调用insertbefore(\"test\")方法会在无序列表
- 10《人工智能》之读书笔记_人工智能读书笔记
当前位置: article > 正文
Python与自然语言处理——文本向量化(一)_向量化 excel
作者:Gausst松鼠会 | 2024-04-02 12:51:30
赞
踩
向量化 excel
Python与自然语言处理——文本向量化
文本向量化(一)
文本向量化概述
- 文本向量化是将文本表示成一系列能够表达文本语义的向量。
- 主要技术
- word2vec
- doc2vec
- str2vec
向量化算法word2vec
词袋模型
- 最早的以词语为基本处理单元的文本向量化方法
- 方法:
- 基于出现的词语构建词典(唯一索引)
- 统计每个单词出现的词频构成向量
- 存在的问题
- 维度灾难
- 无法保留语序信息
- 存在语义鸿沟的问题
神经网络语言模型(NNLM)
- 特点
与传统方法估算 P ( w i ∣ w i − ( n − 1 ) , ⋯   , w i − 1 ) P\left( { {w_i}\left| { {w_{i - \left( {n - 1} \right)}}, \cdots ,{w_{i - 1}}} \right.} \right) P(wi∣∣wi−(n−1),⋯,wi−1)不同,NNLM直接通过一个神经网络结构对 n n n元条件概率进行估计。 - 基本结构
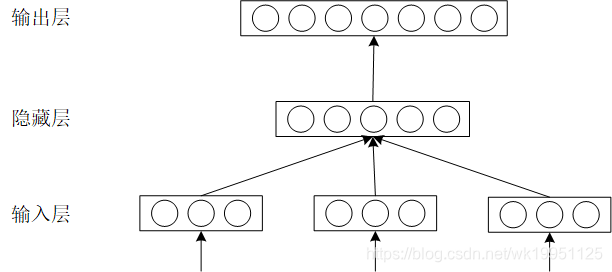
- 大致操作
从语料库中搜集一系列长度为 n n n的文本序列 w i − ( n − 1 ) , ⋯   , w i − 1 , w i { {w_{i - \left( {n - 1} \right)}}, \cdots ,{w_{i - 1}},{w_i}} wi−(n−1),⋯,wi−1,wi,假设这些长度为 n n n的文本序列组成的集合为 D D D,那么NNLM的目标函数为:
∑ D P ( w i ∣ w i − ( n − 1 ) , ⋯   , w i − 1 ) \sum\nolimits_D {P\left( { {w_i}\left| { {w_{i - \left( {n - 1} \right)}}, \cdots ,{w_{i - 1}}} \right.} \right)} ∑DP(wi∣∣wi−(n−1),⋯,wi−1<
推荐阅读
相关标签

