
- 1java+springboot的大学生心理健康测试测评系统vue_大学生心理健康测评系统研究意义
- 2Kubernetes(k8s):部署、使用 metrics-server
- 3如何在尽量不损害画质的前提下降低视频占内存大小?视频格式科普及无损压缩软件推荐
- 4用python实现入门级NLP_sent_tokenize
- 5Midjourney 提示词工具(10 个国内外最好最推荐的)_midjourney prompt helper
- 6视觉理解论文系列(三)VL-BERT: PRE-TRAINING OF GENERIC VISUALLINGUISTIC REPRESENTATIONS_vl-bert: pre-training of generic visual-linguistic
- 7毕设项目分享 基于深度学习的图像修复算法 DCGAN
- 8轻量化网络总结[1]--SqueezeNet,Xception,MobileNetv1~v3_bottleneck结构的改进
- 9Android————一个简单的新闻面板_安卓实现一个新闻页面
- 10程序员请收好:10个非常实用的 VS Code 插件
大语言模型Prompt工程_大语言模型的prompt
赞
踩
原文链接:https://zhuanlan.zhihu.com/p/653956781
目录
6 增强语言模型(Augmented Language Models)
1 摘要
Prompt Engineer 又称为 In-Context Prompt,利用模型的ICL能力,代理传统Bert类模型的微调训练的方式,使用更为高效的Prompt来指导LLM,使其产生出期望的结果,而无需改变模型的权重。本文主要梳理构建常见的几种Prompt的方法和原理。
2 基础prompt方法
1.1 Zero-shot
Zero-shot:简单地将任务文本提供给模型并要求得到结果。
The term “zero-shot” in the context of LLMs usually refers to using the pre-trained LLMs without fine-tuning(LLMs语境下的"零样本学习"通常是指使用未经微调的预训练LLMs)[1]
这种情况下,模型仅通过任务描述或问题来推断出应该如何回应。如:
判断以下句子的情绪类别
优点:灵活性极高,因为你不需要为每一个新任务重新训练模型。
缺点:模型可能无法准确地把握任务的细微差别或特定要求。
[1]Yuan H 0, Jiaoyan C, Hang D 0, Ian H 0, et al. Exploring Large Language Models for Ontology Alignment.[J], CoRR, 2023, abs/2309.07172
1.2 Few-shot
Few-shot 学习是通过提供少量的标注样本(即示例)来帮助模型理解任务。这些示例通常包括输入和预期输出,以便模型能够更准确地把握任务的性质和要求。
对目标任务,由于该模型首先看到的是好的例子,它可以更好地理解人类的意图和需要什么类型的答案的标准。因此,Few-shot 学习往往比 zero-shot 学习有更好的性能。
代价:
- 消耗更多的token;
- 当输入和输出文本较长时,可能会达到上下文长度限制。
如:
以下是一些示例句子及其情绪类别,请根据这些示例句子的情绪类别,判断下面句子的情绪类别。
示例1:这部电影太令人难过了。情绪类别:负面情绪
示例2:我非常兴奋明天的聚会。情绪类别:正面情绪
示例3:今天的天气真是美妙。情绪类别:正面情绪
示例4:我感到非常生气,因为他没有履行承诺。情绪类别:负面情绪
请判断下面句子的情绪类别:
句子1:这个好笑的视频让我笑了很久。
句子2:我非常失望他没有来参加我的生日派对。
句子3:这个好消息真是让我高兴。
句子4:我感到非常焦虑,因为明天有一场重要的面试。
3 Instruct Prompt
指令提示,few-shot通过举例让LLM来理解具体的任务是什么?相当于给LLM进行示范,让他按照上述的模板来进行词语接龙,那为什么不能直接用语言来对我们想要的任务进行描述,让模型来理解我们想要做的事情是什么呢?况且这样的方法在多数场合中会更加有效,减少context的长度,降低模型推理的成本。
chatgpt对于之前的模型的很大的改进工作是体现在这一步,具体的工作是RLHF,基于人类反馈的强化学习。通过一些高质量的问答对和对于答案的回复的排序来训练一个人类偏好的奖励模型,通过这个奖励模型来近一步反馈指导大语言模型的输出的回答的质量。
在chatgpt时代一般的提问方式如下所示:
请为这段话的情绪做一个分类,是正向积极的还是消极的。
将Few shot和 Instruct 结合起来的方式就是给出几个示例,并且示例是描述具体的任务,而不是一步步来做具体的分析演示。这个方法称为 in-context instruction learning,该方法可以近一步提高LLM对于任务的理解能力,提问方式如下所示:
定义:确定对话的说话人,“代理人”或“客户”。 输入:我已经成功地为您订了票。 输出:代理人。
定义:确定问题所要求的类别,“数量”或“位置”。 参赛作品:美国最古老的建筑是什么? 输出:位置。
定义:将电影评论的情绪分类为“积极的”或“消极的”。 我敢打赌,这个视频游戏比电影有趣多了。 输出:
4 一些高级的Prompt 用法
4.1 Self-Consistent Sampling
我们在使用语言模型(LLM)时,经常会遇到两个关键参数:温度(Temperature)和 Top_K。这两个参数对模型输出的结果有着重要的影响。
温度(Temperature)
温度是一个介于 0 和 1 之间的数值。这个参数用于控制模型输出的多样性。当温度设置为 0 时,模型会输出最有可能的答案;当温度设置为 1 时,模型会输出更多样化,但可能不那么精确的答案。如:
- 温度为 0:LLM 可能会输出“苹果是一种水果。”
- 温度为 1:LLM 可能会输出“苹果是一种多汁、美味的水果,常用于制作各种美食。”
Top_K
Top_K 是一个整数,用于限制模型在生成每个单词时考虑的候选单词数量。例如,如果 Top_K 设置为 50,模型在生成下一个单词时只会考虑概率最高的前 50 个选项。
举例:
- Top_K 为 10:模型输出可能更加一致和准确。
- Top_K 为 100:模型输出可能更加多样,但准确性可能会下降。
很自然的想法对于同一个回答,LLM会输出不一样的答案,特别是针对一些数学题或逻辑问答题目,有一个标准答案,当LLM的temperature设置大于0时,我们可以通过对同一个问题询问好几次,然后统计 LLM 回复的答案,通过服从多数的原则来输出答案的内容。
4.2 Chain of Thought
思考下人类面对一个复杂问题的动作,我们常常会对大问题来拆解,通过将一个问题拆分为一个个小问题,然后再逐一解决,比如说如果你要组织一个大型的生日聚会,你可能会先考虑地点、食物、娱乐等各个方面。你不会一下子就解决所有问题,而是会先找个合适的场地,再去考虑食物,然后是娱乐活动等等。
因此 Chain of Thought(思维链)很自然地就从人类的思维逻辑过程迁移至大模型的prompt(提示)上,常见于逻辑推理的任务。以下是一个Chain of Thought的示例:
假设你要用一个语言模型来解决一个法律问题,你可能会先问:“什么是这个问题的法律背景?”
得到答案后,你可能会进一步问:“在这个背景下,有哪些相关的法律条款或案例?”
再之后,你可能会问:“这些法律条款或案例如何应用于我的具体问题?”
最后,你可能会问:“根据这些信息,最可能的解决方案是什么?”
通过这一系列的问题和答案,你就能更全面、更准确地解决你面临的复杂问题。
这样的Chain of Thought不仅能帮助模型更好地理解问题,还能帮助使用者更清晰地看到问题解决的全过程,就像我们人类解决问题时会做的那样。
第一步:了解背景
Prompt: "请简要描述这个法律问题的背景和主要矛盾点。"
第二步:相关法律和案例
Prompt: "在这个法律背景下,有哪些相关的法律条款或先例案例?"
第三步:应用法律到具体问题
Prompt: "这些法律条款或案例如何应用于我的具体问题?有没有可能的解释或者争议点?"
第四步:可能的解决方案
Prompt: "根据以上的信息,最可能的解决方案或建议是什么
4.3 Tree of Thought
对于Chain of Thought的升级,就是思维树,Chain of thought 的基本思想是在一个思路上不断深挖,来得到答案的内容,而 Tree of Thought的思想有点类似于头脑风暴,从多个角度思考这个问题,通过多个角度的思考过程的展示和梳理,最终回溯出一条解决问题的路径。总的来说 ToT 使语言模型通过多种不同的推理的路径并自我评估来选择决定下一步行动,并且在必要的时候进行前瞻或回溯以做出全局选择。
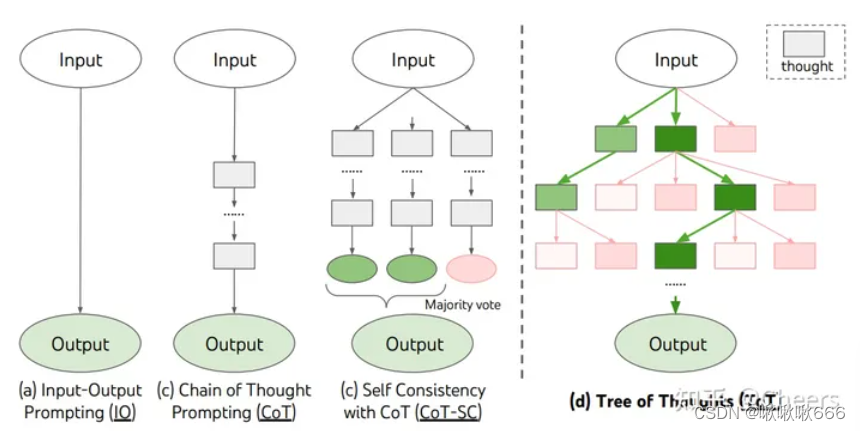
TOT
以下是论文在玩24点游戏过程中的推理思路的重现和展示
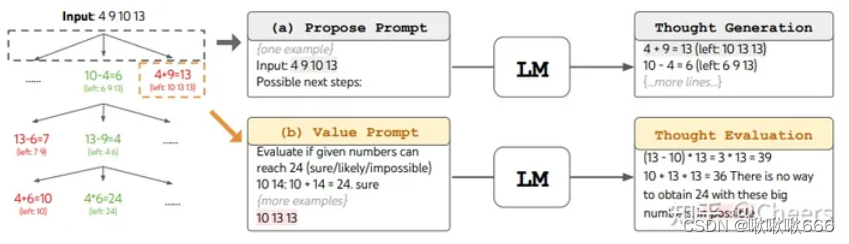
TOT2
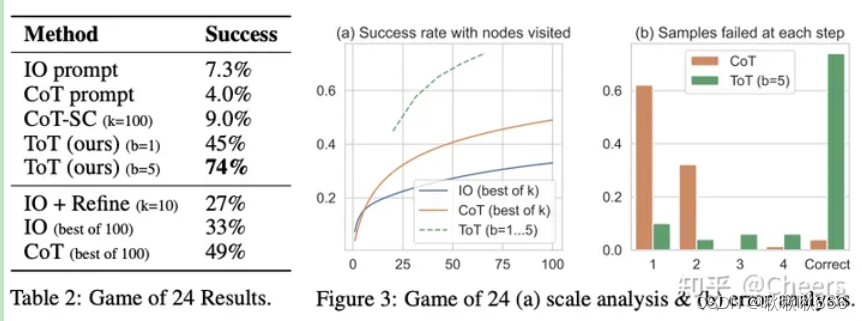
TOT3
ToT 在需要非平凡规划或搜索的三个新任务上显著提高了语言模型的解决问题能力:24 点游戏、创意写作和迷你填字游戏。例如,在 24 点游戏中,使用 Chain of Thought 提示的 GPT-4 只解决了 4% 的任务,而ToT的方法成功率达到了 74%。上述b=5,意味着每个步骤中最好的b=5个候选项被保留。
以下是ToT一个Prompt的示例过程,该参数b=3。
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...
总之,ToT 框架在需要探索、策略性前瞻或初始决策起到关键作用的任务中具有广泛的应用前景。
5 自动prompt 设计
自动提示设计(Automatic Prompt Design)是一种用于创建能够从语言模型中引出所需响应的提示的过程。编写结构良好的提示是确保语言模型提供准确、高质量响应的重要部分。
有几种方法可以实现自动提示设计,包括:
- AutoPrompt:提出了一种基于梯度引导搜索自动创建多种任务提示的方法。
- 前缀调整(Prefix Tuning):一种轻量级的微调替代方案,用于为自然语言生成任务添加可训练的连续前缀
- 提示调整(Prompt Tuning):提出了一种通过反向传播学习软提示的机制
- 自动提示工程师(Automatic Prompt Engineer, APE):提出了一个用于自动生成和选择指令的框架。它将指令生成问题框定为自然语言合成问题,并使用大型语言模型作为推理模型,通过生成和搜索候选解决方案来解决黑盒优化问题
6 增强语言模型(Augmented Language Models)
语言模型(LM)与推理技能和使用工具的能力相结合的工作。这种增强的 LM 可以使用各种可能是非参数的外部模块来扩展它们的上下文处理能力,从而偏离了纯语言建模范式。因此,我们把它们称为增强语言模型(AR)。一篇有关增强语言模型的综述如下所示https://arxiv.org/abs/2302.07842
6.1 检索器retrieval
LLM经过训练之后,对于最新的知识和信息就不再能够获取,另外对于内部的一些信息和知识有可能会产生幻觉,通过retrieval的方法能够很好的规避这个问题。
思想非常简单,就是通过对query的编码,然后将其与外部文档进行一个检索,将检索的内容加入至外部文档中,根据最新的检索的内容和query的问题,重新组合传入大语言模型中。
这里的核心目标是根据问题找出文档中和问题最相关的片段,文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化(通过语言模型,如bert等),然后存到向量数据库(如Annoy、 FAISS、hnswlib等)里边,来了一个问题之后,也对问题语句进行向量化,以余弦相似度或点积等指标,计算在向量数据库中和问题向量最相似的top k个文档片段,作为上文输入到大模型中。向量数据库都支持近似搜索功能。
另外有研究表示,即使不针对外部的知识,仅仅使用模型内部检索,对于问题的问答也是有用的,常用的Prompt如下所示:
Generate some knowledge about the input. Examples:
Input: What type of water formation is formed by clouds?
Knowledge: Clouds are made of water vapor.
Input: {question} Knowledge:
后续将产生的知识和问题prompt一并输入至大语言模型中。
对于retrieval,使用langchain能够很好的实现该功能的调用。
- from langchain.chains import RetrievalQA
- from langchain.document_loaders import TextLoader
- from langchain.embeddings.openai import OpenAIEmbeddings
- from langchain.llms import OpenAI
- from langchain.text_splitter import CharacterTextSplitter
- from langchain.vectorstores import Chroma
- loader = TextLoader("../../state_of_the_union.txt")
- documents = loader.load()
- text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
- texts = text_splitter.split_documents(documents)
-
- embeddings = OpenAIEmbeddings()
- docsearch = Chroma.from_documents(texts, embeddings)
-
- qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
- query = "What did the president say about Ketanji Brown Jackson"
- qa.run(query)

6.2 Programming Language
Gao et al., (2022) 等人提出了一种使用LLM读取自然语言问题并生成程序作为中间推理步骤的方法。作为创造的程序辅助语言模型 (PAL),它与思维链提示的不同之处在于,它不是使用自由格式的文本来获取解决方案,而是将解决方案步骤卸载到编程运行时,例如 Python 解释器。

PAL
6.3 工具增强 Tool
该方法是给大语言模型一些工具的定义,让LLM能够使用定义好的工具,通过这些工具来获得想要的知识。
这块现阶段主流的方法有两种,
- 通过React框架来让大模型一步步推理观察使用的工具输出的内容,并根据输出的内容来整合得到想要的结果。
- 通过训练,例如Toolformer这篇论文。
ReAct框架:是一种通用范式,它将推理和行动与LLM相结合。 ReAct提示LLM为任务生成口头推理跟踪和操作。这允许系统执行动态推理以创建,维护和调整行动计划,同时还允许与外部环境(例如,维基百科)进行交互,以将其他信息纳入推理中。下图显示了 ReAct 的示例以及执行问答所涉及的不同步骤。

REACT
Toolformer这篇论文是由meta AI在2023年提出的工作,Toolformer的一个重要特点是它能够在自监督的方式下学习使用工具,这意味着不需要大量的人工标注。这不仅降低了成本,还因为模型可能找到与人类不同的有用工具而变得更加重要。与现有的方法不同,Toolformer不会失去其通用性,并且能够自主决定何时以及如何使用哪个工具。这使得它能够更全面地使用工具,而不是仅限于特定的任务。以下是Toolformer具体推理过程中的示例:

但是这种方法有个缺陷,就是只能使用经过训练之后的内容,并且通常来说对于输入的参数的要求不是很高。因此对于复杂API的调用还不能够胜任。
本质上Toolformer仍然是一个词语接龙的游戏,简单的来说,在构建数据集的过程中,使用大语言模型来辅助生成样本,在合适的文本中插入相应的API接口的名字和输入的内容,构建大量的数据集,减少了人工标注的工作量。通过该数据集语料来微调训练模型,使其拥有API调用的能力,让模型学习如何决定何时调用哪些工具,传递什么参数,并将结果融合到后续的token的预测中。

