
- 1清除浮动的五种方法_不受浮动影响的方法
- 2机器学习--逻辑回归算法1_x_mapped = map_feature(x_train[:, 0], x_train[:, 1
- 3【花雕动手做】ASRPRO语音识别(19)---语音和按键控制继电器_asrpro 固定词汇
- 4自动驾驶技术的基础知识_自动驾驶要掌握哪些知识
- 5【图像篡改检测1】Learning Rich Features for Image Manipulation Detection
- 6python训练自己中文语料库_中文语料库构建过程详细教程
- 7文档图像倾斜校正算法(3)——二位傅里叶变化法倾斜校正_基于傅里叶变化 文档倾斜角度检测
- 8torch.nn.Embedding_def embedding(weight: tensor, indices: tensor, pad
- 9Transformer模型的多头注意力机制是通过以下步骤来实现的_怎样往模型放多头注意力机制
- 10dict是什么意思
基于 SageMaker Notebook 快速搭建托管的 Stable Diffusion – AI 作画可视化环境
赞
踩
本文主要介绍如何使用 Amazon SageMaker Notebook 机器学习服务轻松托管 Stable Diffusion WebUI,一键部署开箱即用的 AIGC 图片方向轻量级应用。通过 Amazon CloudFormation 基础设施即代码的服务,实现底层环境、AI 模型和前端 Stable Diffusion WebUI 的快速部署,帮助用户在 15~20 分钟部署一套文生图、图生图的 AI 应用。此方案适合企业级客户对 AIGC 图片方向做前期调研和快速验证、小型团队快速搭建轻量级 AI 应用的业务场景。
[注]:此方案目前提供基于 Stable Diffusion 1.5 的图片生成,基于 dreambooth 的图片训练和推理;暂不提供脚本(script)和插件(extension)的技术支持,读者可持续关注后续方案的功能迭代。
1. 方案架构
|
|
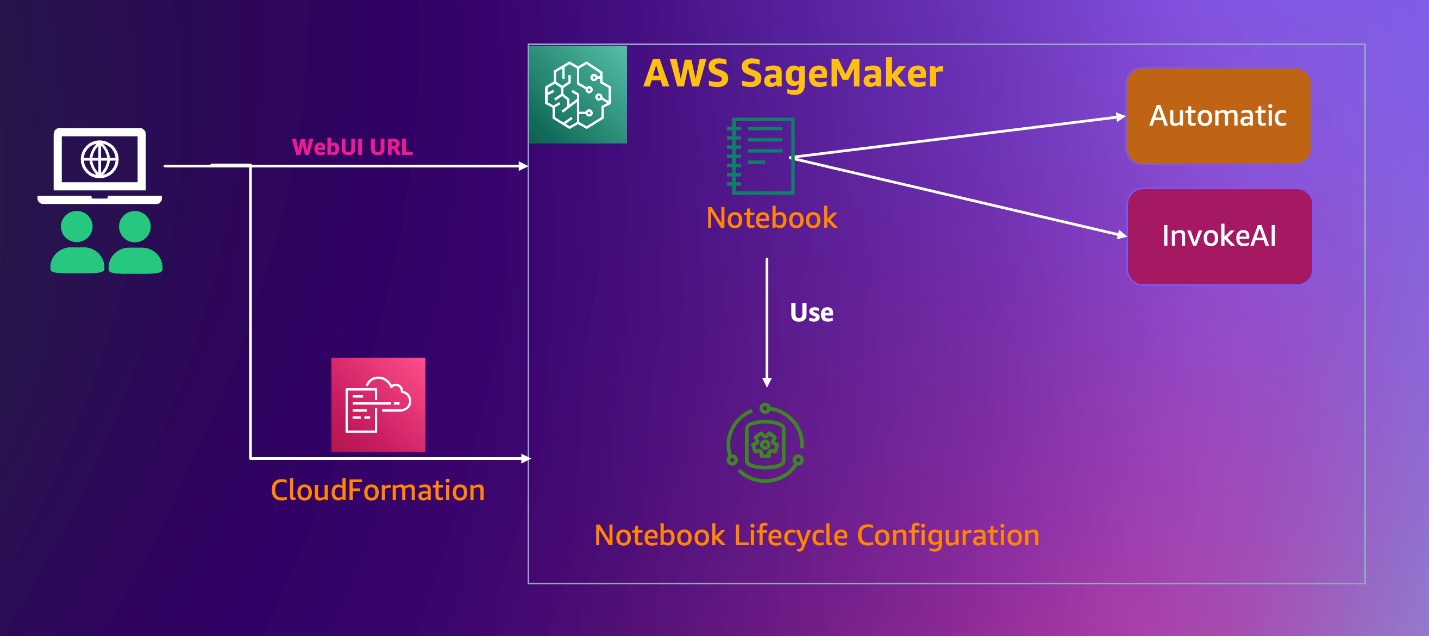
2. 方案优势
- 本方案使用 CloudFormation 一键部署,仅需点击几个步骤,即可快速在您的 AWS 账户中成功部署一套 AIGC 图片方向的 web 应用环境,交互界面简洁友好,帮助用户快速体验文本生成图片、图片生成图片等 AI 服务。
- 底层使用 Amazon SageMaker Notebook Instance 托管的 Jupyter 笔记本实例,您无需关心基础环境(如存储、网络等)的构建及底层基础设施运维。
- 方案采用全托管的 Stable Diffusion AI 模型服务(1.5 轻量版本,包含 Stable Diffusion WebUI 与 InvokeAI 两个界面),具备良好的开源项目使用体验,并支持根据您的需要安装插件以扩展使用场景(如 ControlNet)。
- 用户可使用自带的图片数据微调模型,产出的模型可基于自动化流水线工具快速部署上线至推理节点,方便规模化的图片推理调用。
- 本方案完全开源,用户可以在 SageMaker Notebook 中对模型和扩展(extension)定制开发,满足自身业务需求。
3. 方案组件
3.1 Amazon SageMaker Notebook
Amazon SageMaker 笔记本实例是运行 Jupyter Notebook 应用程序的机器学习 (ML) 计算实例。 SageMaker 管理实例和相关资源的创建。在您的笔记本实例中使用 Jupyter 笔记本来准备和处理数据、编写代码来训练模型、将模型部署到 SageMaker 托管,以及测试或验证您的模型。
3.2 Stable Diffusion 模型
Stable Diffusion 是由 CompVis 、 Stability AI 和 LAION 共同开发的一个文本转图像模型,它通过 LAION-5B 子集大量的 512×512 图文模型进行训练,用户只要简单的输入一段文本,Stable Diffusion 就可以迅速将其转换为图像。同样,用户也可以置入图片或视频,配合文本对其进行处理。
3.3 用户交互界面
3.3.1 Stable Diffusion WebUI + 使用示例参考
Stable Diffusion WebUI 是 Stable Diffusion 的一个浏览器交互界面,它提供了多种功能,如 txt2img、img2img 等,还包含了许多模型融合改进、图片质量修复等附加升级。通过调节不同参数可以生成不同效果,用户可以根据自己的需要和喜好进行创作。它不仅支持生成图片,使用各种各样的模型来达到你想要的效果,还能训练你自己的专属模型。
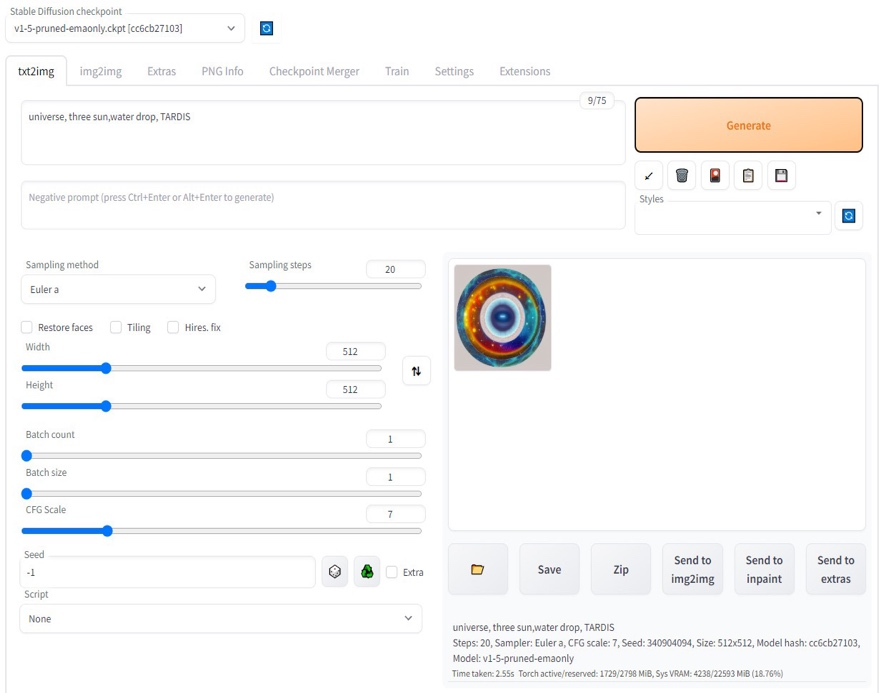
以文字生成图片为例,用户可在“txt2img”界面,使用提示词生成期望图片,步骤如下:
- 点击“txt2img”进入文生图界面
- 在提示词输入框内输入提示词
- 点击“Generate”按钮即可生成图片
|
|

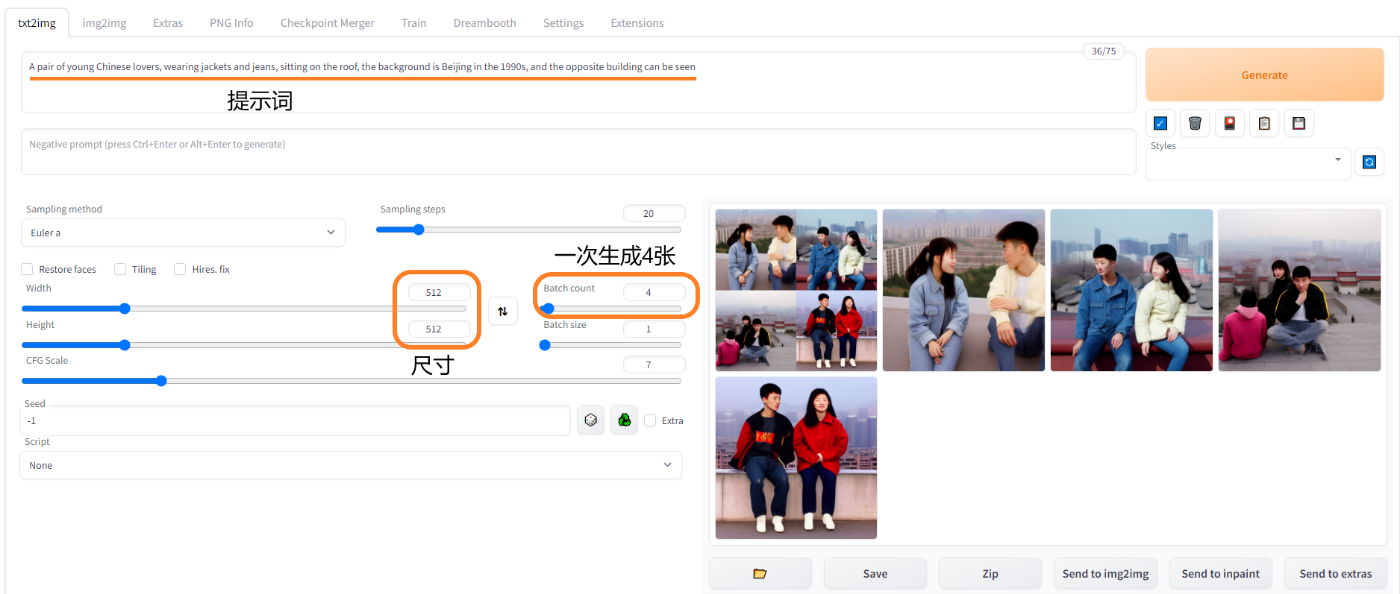
1. 生成一对 90 年代中国情侣,尺寸 512×512,一次生成 4 张图
提示词(Prompt):A pair of young Chinese lovers, wearing jackets and jeans, sitting on the roof, the background is Beijing in the 1990s, and the opposite building can be seen
|
|
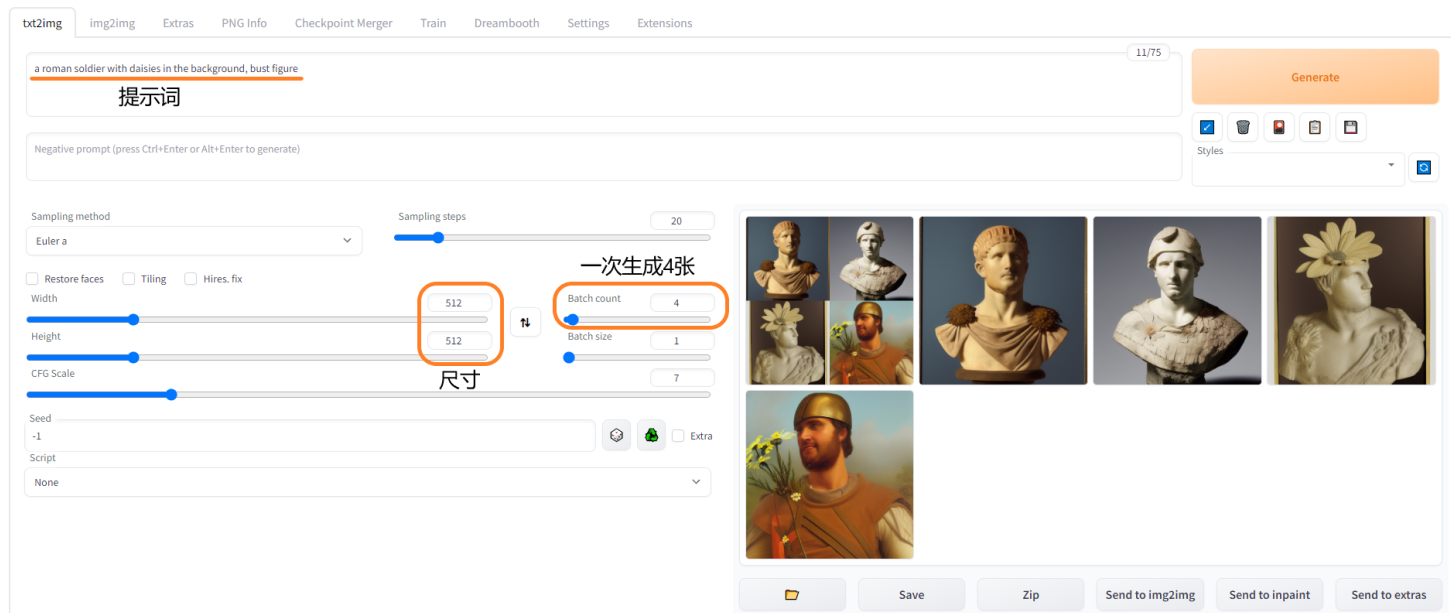
2. 生成背景为雏菊的罗马士兵半身像,尺寸 512×512,一次生成 4 张图
提示词(Prompt):A roman soldier with daisies in the background, bust figure
|
|
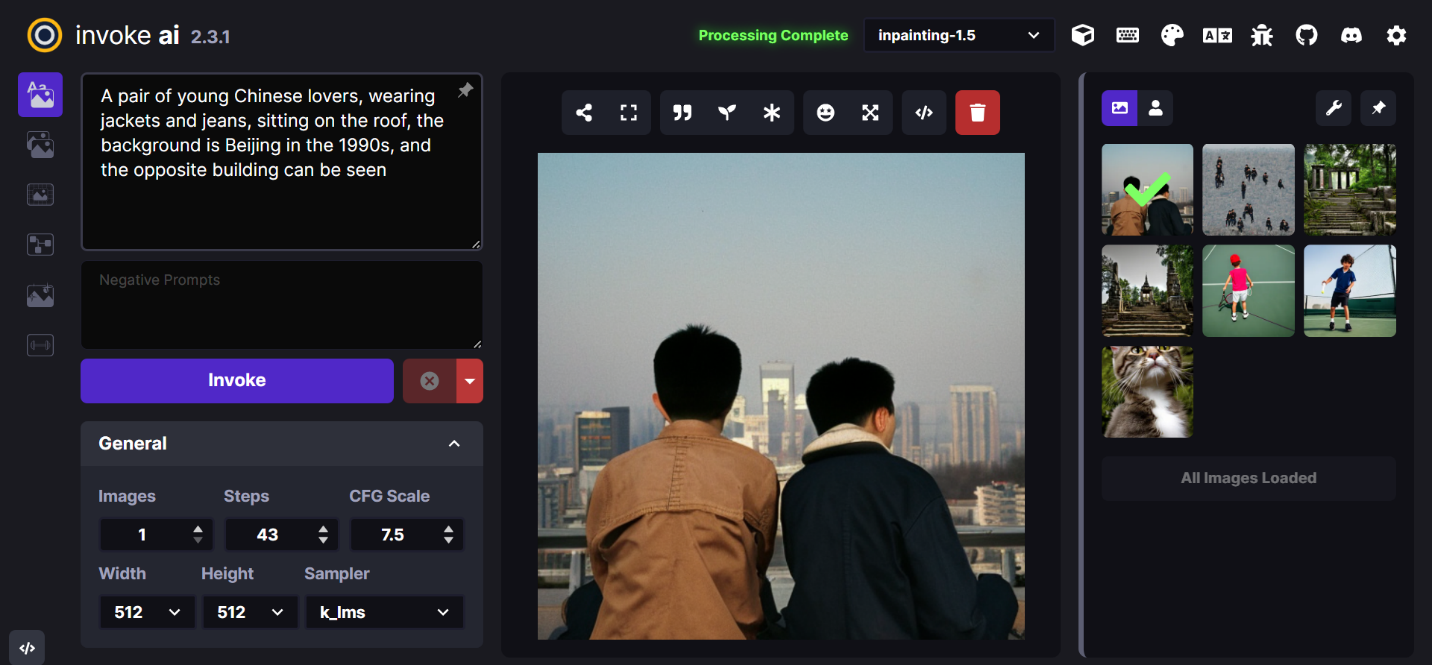
3.3.2 InvokeAI + 使用示例参考
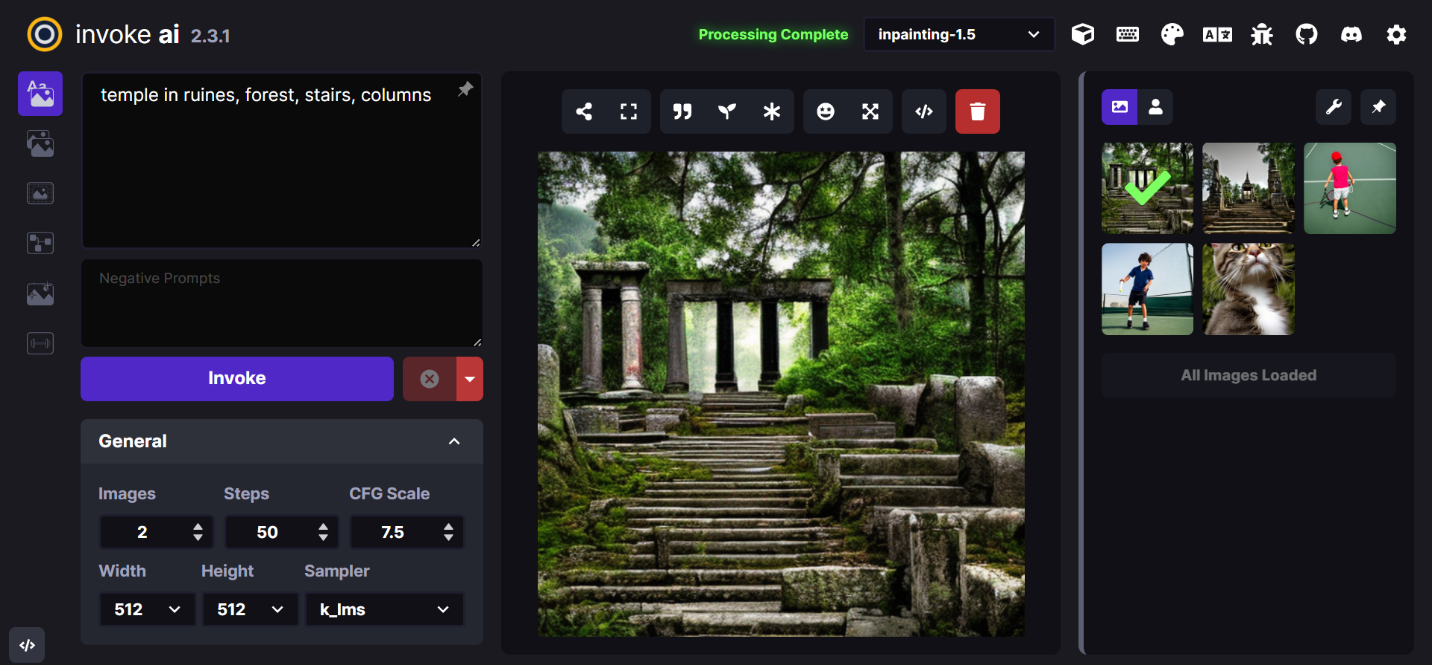
InvokeAI 是 Stable Diffusion 的一个实现,它是开源文本到图像和图像到图像生成器。 它提供了一个具有各种新功能和选项的简化流程,以帮助图像生成过程。
提示词(Prompt):temple in ruines, forest, stairs, columns
|
|
提示词(Prompt):A pair of young Chinese lovers, wearing jackets and jeans, sitting on the roof, the background is Beijing in the 1990s, and the opposite building can be seen
|
|
3.4 方案部署
3.4.1 方案部署操作步骤
1. 登录控制台,在控制台页面右上角切换区域至 us-east-1。
|
|
2. 在 Service 搜索框中输入 Cloudformation,点击进入。
|
|
3. 创建堆栈 -使用新资源(标准)- Amazon S3 URL,填入 https://xiekl.s3.cn-northwest-1.amazonaws.com.cn/sd-webui.yml。
|
|
4. 填入堆栈名称,Instance Type 建议选择 g5.2xlarge,磁盘 Volume 大小默认为 100G,选择 WebUI Type,默认是 auto 代表 Stable Diffusion WebUI,WebUI Version 选择 0316,点击“下一步” 。
|
|
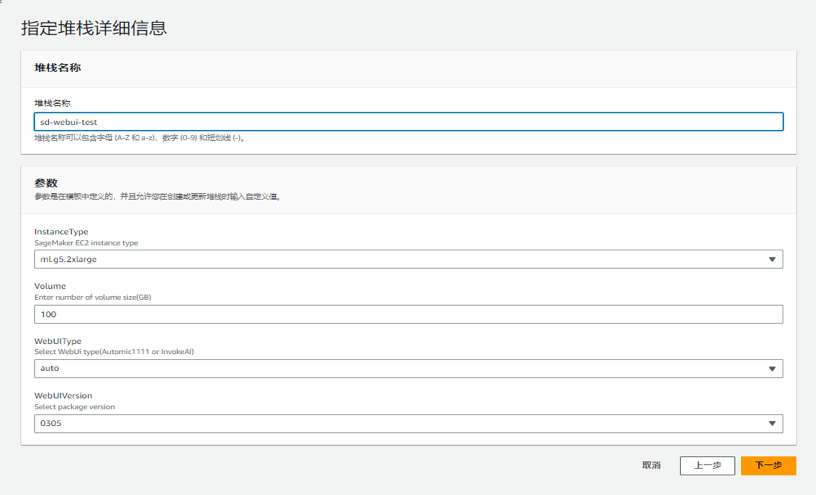
5. 设置保持默认,点击“下一步”。
|
|

6. 确认配置(维持默认即可),勾选“我确认…”,点击“提交” ,等待 15-20 分钟部署完成。
|
|
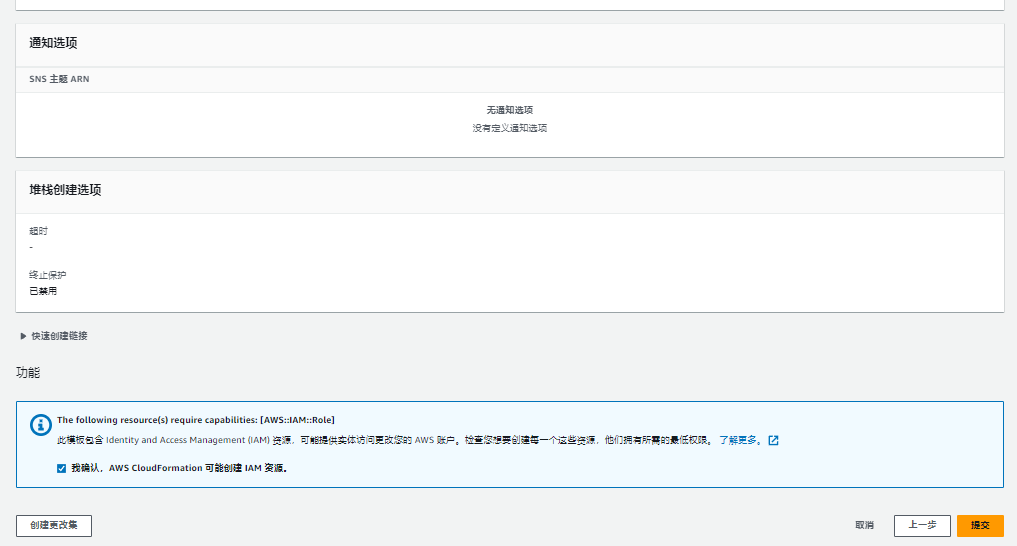
3.4.2 使用 Stable Diffusion WebUI 进行文生图
1. 创建堆栈后等待资源陆续启动(约 20 分钟),待堆栈状态显示为“CREATE_COMPLETE”后,点击“输出”。点击“键”为“WebUI URL”相应的“值”位置的 URL。
|
|
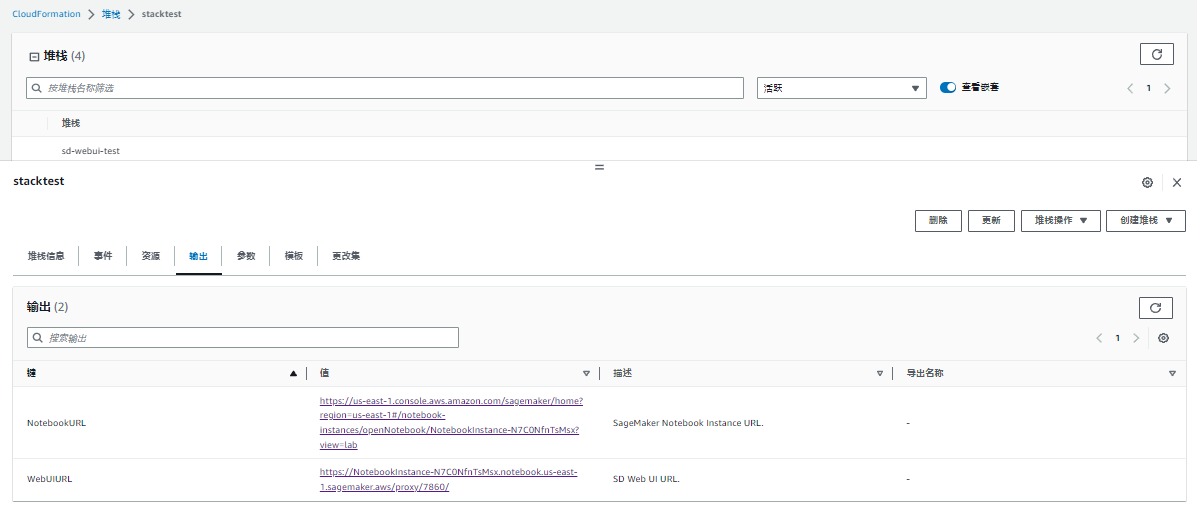
2. 进入 WebUI 界面,输入 prompt,点击 generate 即可生成图片。
|
|
3.4.3 使用 Stable Diffusion WebUI 进行训练(微调)
下面介绍如何使用 Stable Diffusion WebUI 训练您自己的图片。
1. 首先要创建一个模型。导航到 DreamBooth ⻚面。
|
|
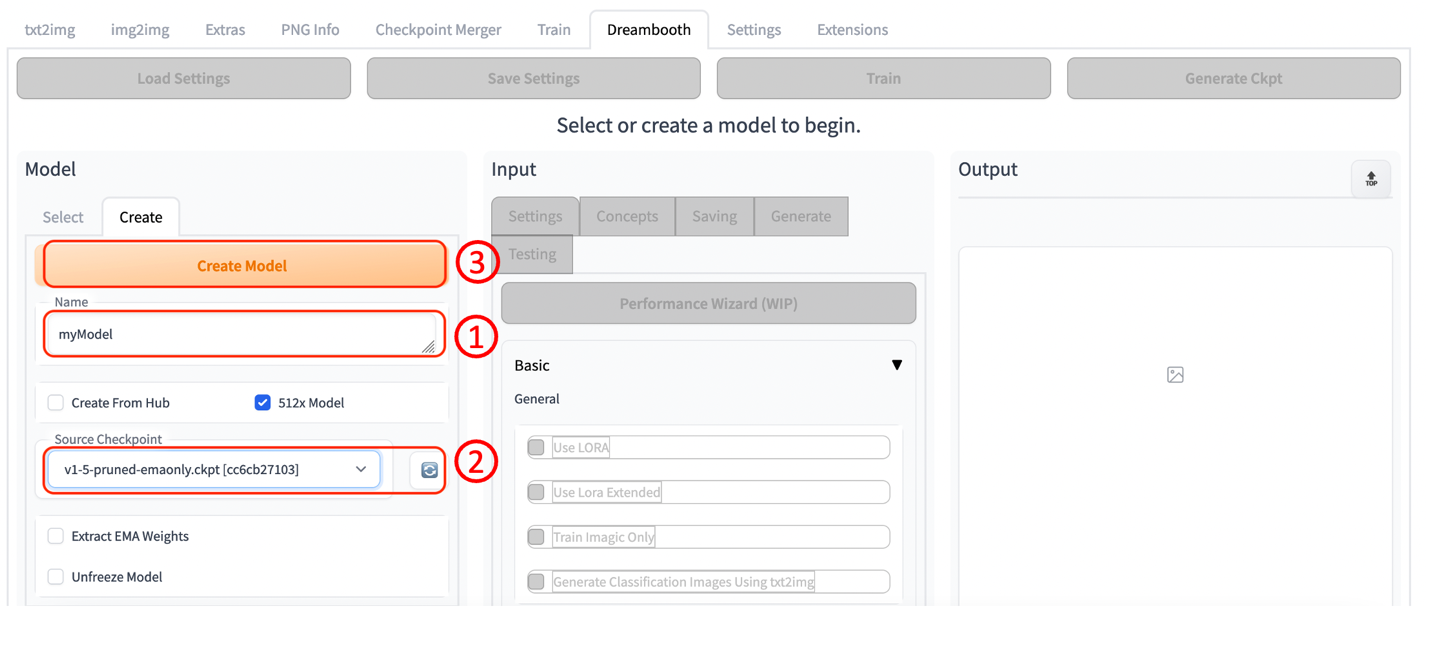
2. 创建成功后,如下图所示。
|
|

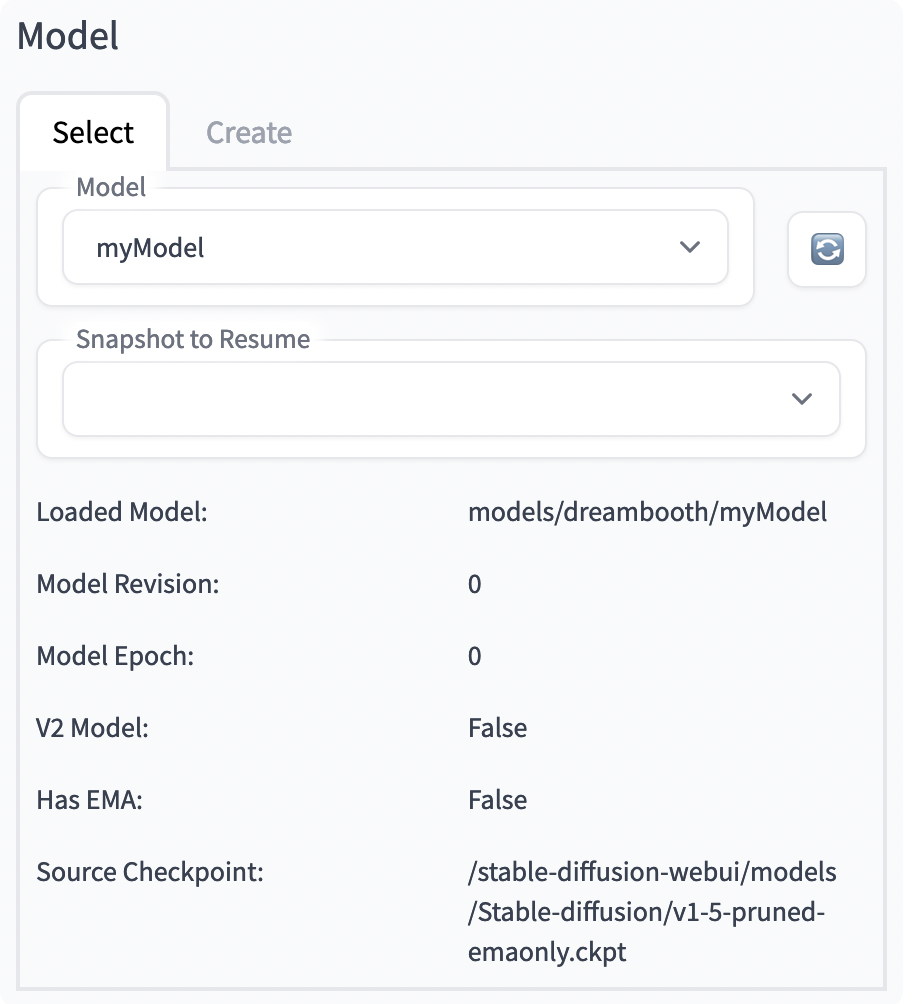
3. 设置训练参数,导航到 Select ⻚面,如图所。
|
|
4. 在 input ⻚面,设置 Setting,Basic 的参数保持默认即可,点击右侧箭。
|
|
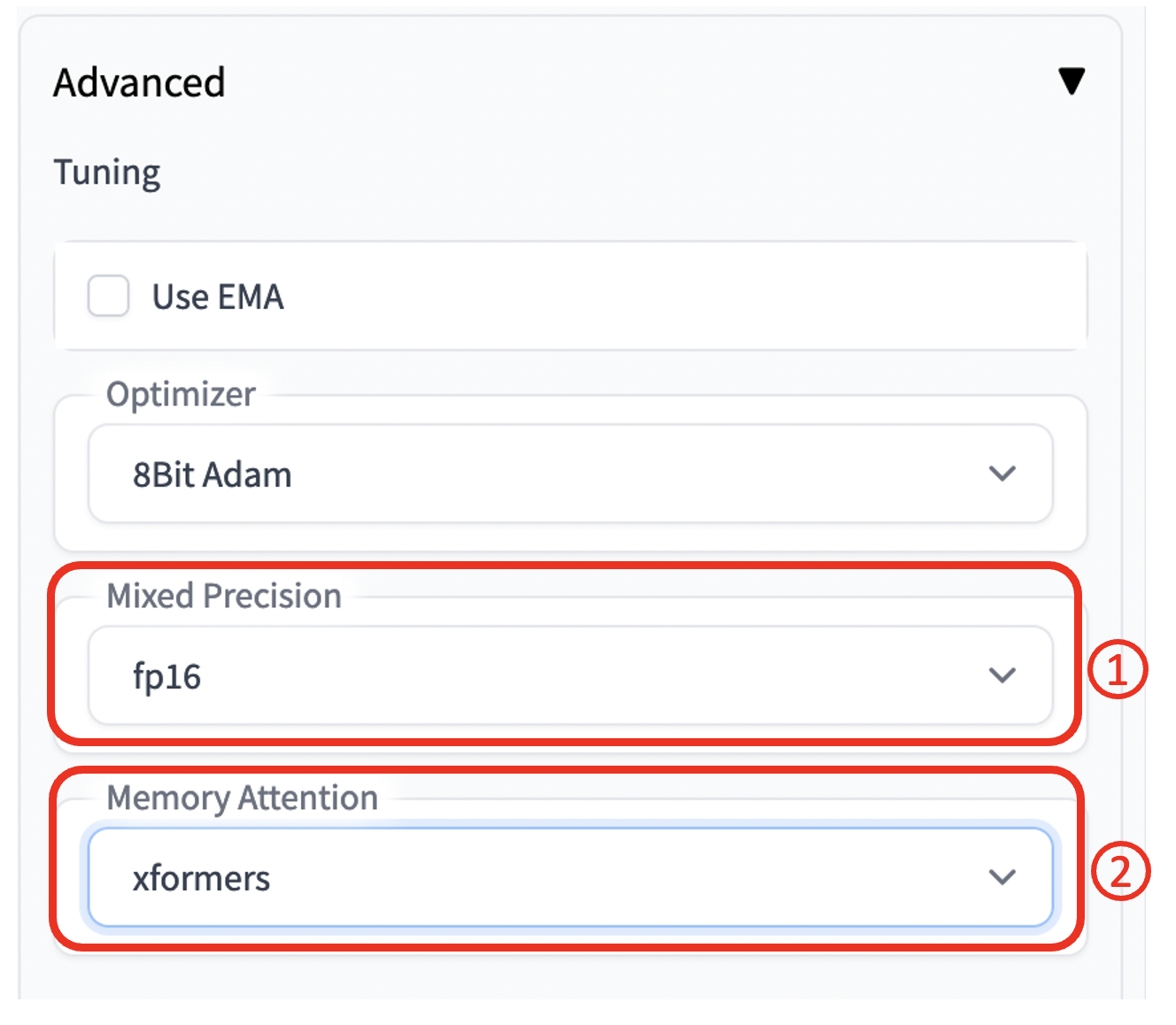
5. 点击 Advance 右侧箭头,展开选项卡。在 Mixed Precision 选择 fp16,Memory Attention 选择 xformers,其他选项保持默认即可,如下图所示。
|
|
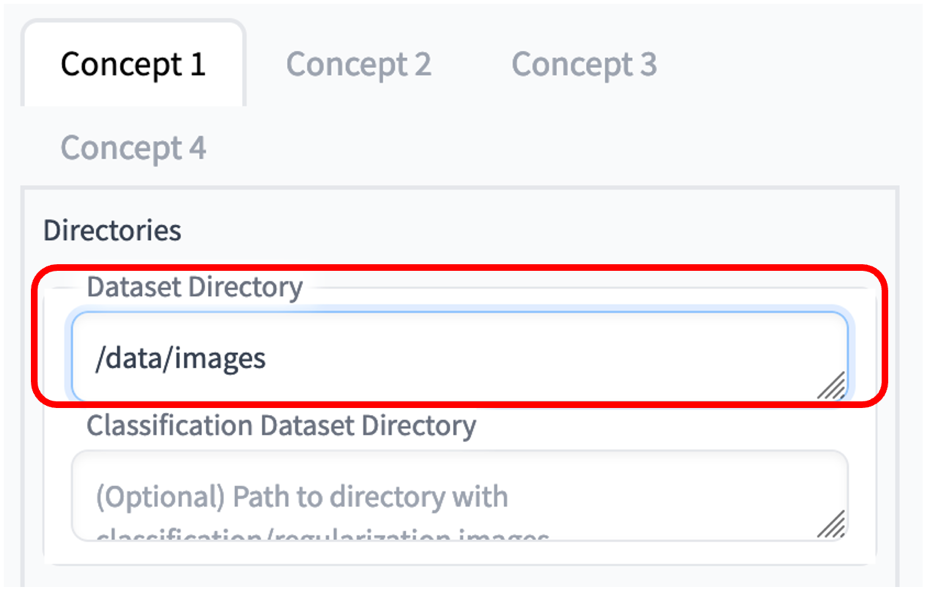
6. 点击 Concepts 选项卡,在 Dataset Directory 输入实例图片所在的目录。我们事先准备了示例图片 在/data/images 中,读者也可以把自己的图像文件放在该目录中。
|
|
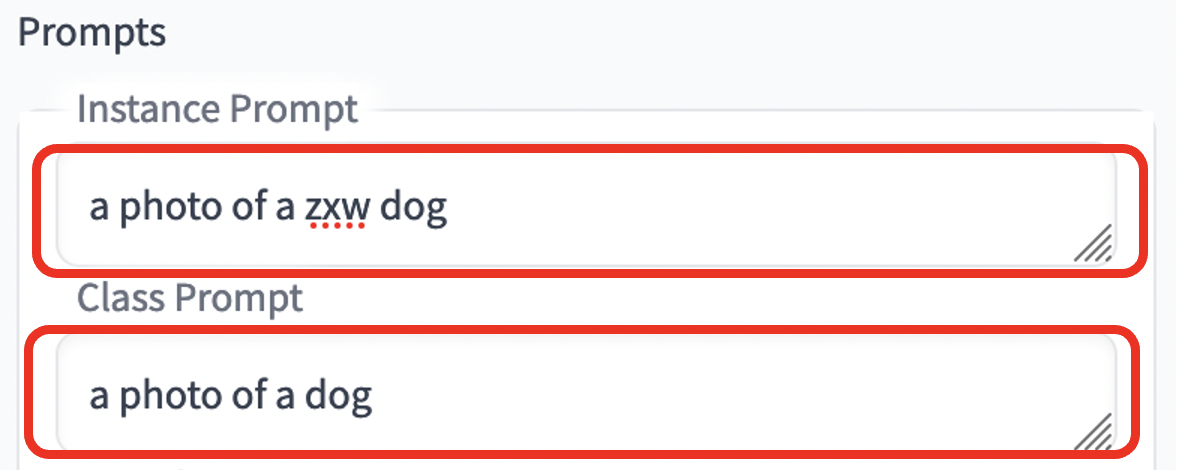
7. 向下拉动滚动条,在 Instance Prompt 中输入”a photo of a zxw dog”,在 Class Prompt 中输入”a photo of dog”,其他保持默认。
|
|
8. 点击⻚面上方的”Train”按钮。
|
|

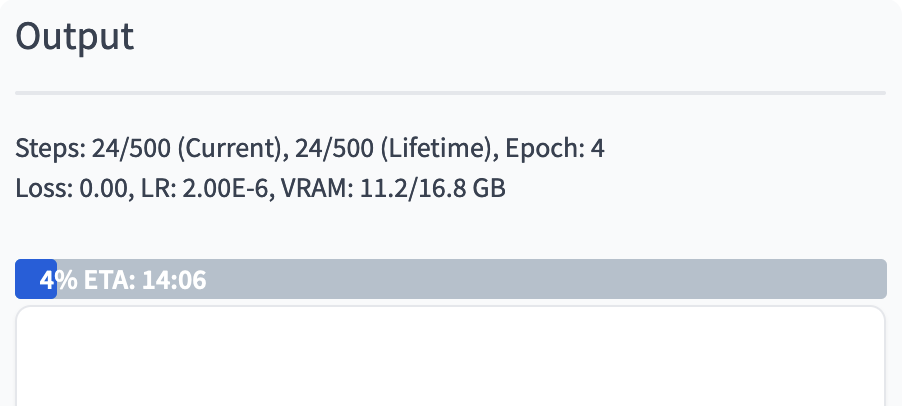
9. 观察右侧 Output 选项卡的训练进度,等待训练完成。
|
|
10. 训练完成后,点击刷新按钮,模型列表中将出现刚训练好的模型,选择新训练的模型。
|
|

11. 点击 txt2img,跳转到文生图⻚面。输入 Prompt,注意要带上 zwx 前缀,查看结果。
|
|

12. 下面介绍如何用自己的图片进行训练。在 Cloudfomation 的输出中,点击 NotebookURL 链接。
|
|
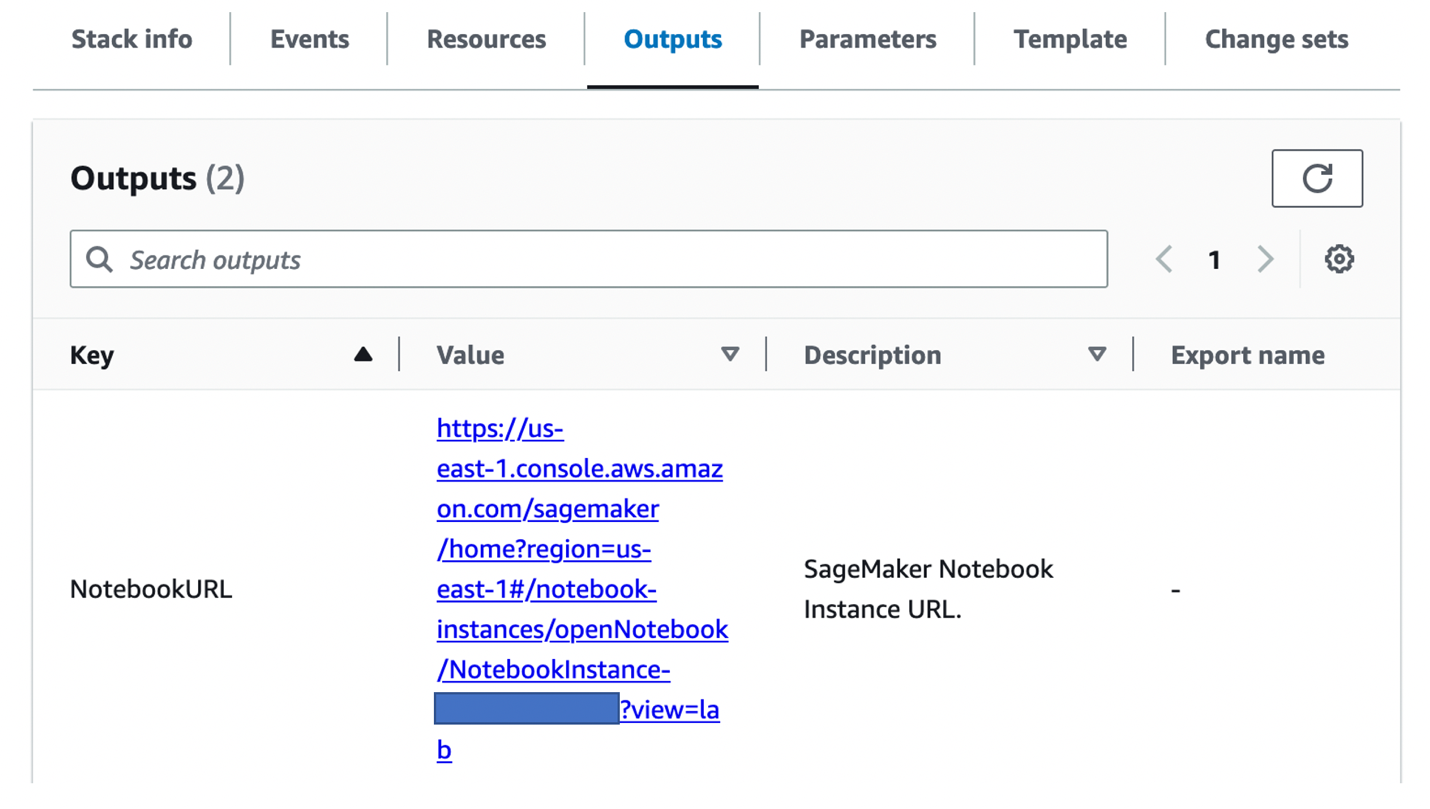
13. 如下图所示,点击 sd-webui 进入到 data/images/文件夹。在文件上依次点击右键,删除文件。
|
|

14. 点击 Upload files 按钮,上传您自己的图片作为训练集。上传完成后,重复上述步骤完成训练过程。
|
|
4. 总结
本文简单介绍了如何使用托管的笔记本服务 SageMaker Notebook 来一键部署 Stable Diffusion WebUI,轻松构建 AI 生成图片的界面化、快速验证环境。方案只需点击几次即可实现自动化部署,基于托管服务的特性让您无需忧心底层基础设施的搭建与运维,同时拥有良好的开源项目体验。您还可以使用自己的图片对模型进行微调,为定制特色的 AIGC 应用做好准备。

