- 1【嵌入式】STM32进阶-OLED显示时间+温度和湿度_只使用单片机和oled可以显示时间吗
- 2vite-admin框架搭建,ESLint + Prettier 语法检测和代码格式化_vite eslint pritter
- 3win10系统使用yolov5,安装cuda、anaconda、pytorch、opencv避坑避雷最全讲解+常见问题解答_yolov5 cuda
- 4Appstore上架:提审被拒之Guideline 2.3.1 拒审解析和解决办法_ios 审核 2.3.1 被拒解决办法
- 5【附源码】基于java的宠物店管理系统ab3xl9计算机毕设SSM_java宠物店管理系统
- 6华为mindspore-Bloom模块代码分析1.head/BloomLMHeadModel_bloom 源代码
- 7C语言学生信息管理系统(最全面的)
- 8AWS学习笔记-存储小结_ebs provides a persistent store
- 9TensorFlow2.0(十)--实现深度可分离卷积神经网络_tensorflow深度可分离卷积实战
- 1026个人工智能和机器学习大厂面试常见问题_教师面试问题:人工智能
动手学深度学习——残差网络ResNet(原理解释+代码详解)_残差块resnet
赞
踩
ResNet为了解决“新添加的层如何提升神经网络的性能”,它在2015年的ImageNet图像识别挑战赛夺魁
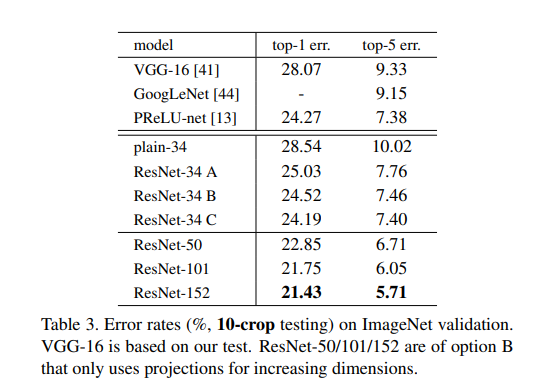
它深刻影响了后来的深度神经网络的设计,ResNet的被引用量更是达到了19万+。

1. 函数类
假设有一类特定的神经网络架构F,它包括学习速率和其他超参数设置。对于所有f∈F,存在一些参数集(例如权重和偏置),这些参数可以通过在合适的数据集上进行训练而获得。
现在假设 f* 是我们真正想要找到的函数,如果是 f*∈F,那可以轻而易举的训练得到它。
给定一个具有X特性和y标签的数据集
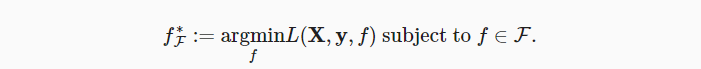
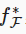 是我们要找的函数,为了使其更近似真正的 f* ,则需要更强的架构F’。
是我们要找的函数,为了使其更近似真正的 f* ,则需要更强的架构F’。
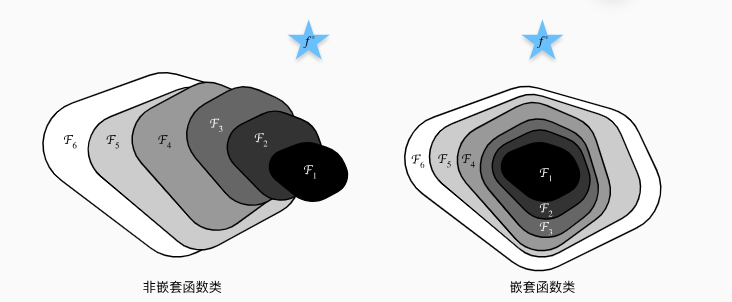
对于非嵌套函数类,较复杂的函数类并不总是向“真”函数 f* 靠拢(复杂度由F1向F6递增)。虽然F3比F1更接近 f*,但却离F6的更远了。
而右侧的嵌套函数可以避免上述问题。
2. 残差块
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
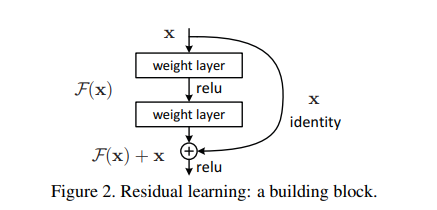
F(x) + x包含了原始元素。
ResNet沿用了VGG完整的3x3卷积层设计。
- 残差块里首先有2个有相同输出通道数的3x3卷积层。
- 每个卷积层后接一个批量规范化层和ReLU激活函数。
- 然后通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。
import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l class Residual(nn.Module): #@save # use_ixiconv:残差连接是直接连接还是通过卷积层连接 def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1): super().__init__() self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides) self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) if use_1x1conv: self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides) else: self.conv3 = None self.bn1 = nn.BatchNorm2d(num_channels) self.bn2 = nn.BatchNorm2d(num_channels) def forward(self, X): Y = F.relu(self.bn1(self.conv1(X))) Y = self.bn2(self.conv2(Y)) if self.conv3: X = self.conv3(X) Y += X return F.relu(Y)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
此代码生成两种类型的网络:
- 一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。
- 另一种是当use_1x1conv=True时,添加通过1x1卷积调整通道和分辨率。
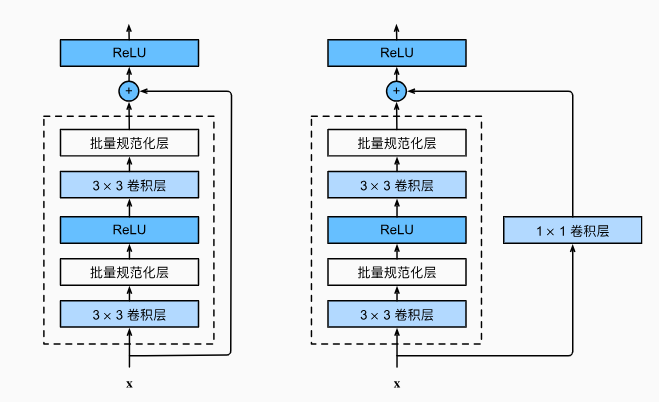 查看输入和输出形状一致的情况
查看输入和输出形状一致的情况
# 输入、输出的情况
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
- 1
- 2
- 3
- 4
- 5

在增加输出通道数的同时,减半输出的高和宽
# 增加输出通道的同时,减半输出的高度和宽度
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shape
- 1
- 2
- 3

3. ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7x7卷积层后,接步幅为2的3x3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
# ResNet在每个卷积层后增加了批量规范层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
- 1
- 2
- 3
- 4
ResNet使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
第一个模块的通道数同输入通道数一致。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
# 实现残差连接模块:由4个残差连接块组成
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
# 定义空网络结构
blk = []
for i in range(num_residuals):
# 第2,3,4个Inception块的第一个残差模块连接1x1卷积层
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
# 在ResNet加入所有残差块,每个模版使用2个残差块
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
- 1
- 2
- 3
- 4
- 5
最后在ResNet中加入全局平均汇聚层,以及全连接层输出。
# 在ResNet加入全局平均汇聚层以及全连接层输出
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
- 1
- 2
- 3
- 4
每个模块有4个卷积层,加上第一个7x7卷积层和最后一个全连接层,共有18层,这种模型通常被称为ResNet-18。
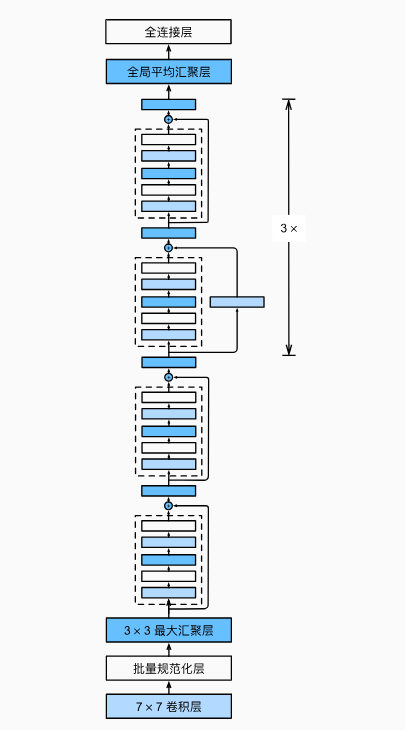
观察一下ResNet中不同模块的输入形状是如何变化
# 每个模块有4个卷积层(不包括恒等映射的1x1卷积层)。
# 加上第一个7x7卷积层和最后一个全连接层,共有18层。
# 因此,这种模型通常被称为ResNet-18。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output_shape:\t', X.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

4. 训练模型
在Fashion-MNIST数据集上训练ResNet
定义精度评估函数
""" 定义精度评估函数: 1、将数据集复制到显存中 2、通过调用accuracy计算数据集的精度 """ def evaluate_accuracy_gpu(net, data_iter, device=None): #@save # 判断net是否属于torch.nn.Module类 if isinstance(net, nn.Module): net.eval() # 如果不在参数选定的设备,将其传输到设备中 if not device: device = next(iter(net.parameters())).device # Accumulator是累加器,定义两个变量:正确预测的数量,总预测的数量。 metric = d2l.Accumulator(2) with torch.no_grad(): for X, y in data_iter: # 将X, y复制到设备中 if isinstance(X, list): # BERT微调所需的(之后将介绍) X = [x.to(device) for x in X] else: X = X.to(device) y = y.to(device) # 计算正确预测的数量,总预测的数量,并存储到metric中 metric.add(d2l.accuracy(net(X), y), y.numel()) return metric[0] / metric[1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
定义GPU训练函数
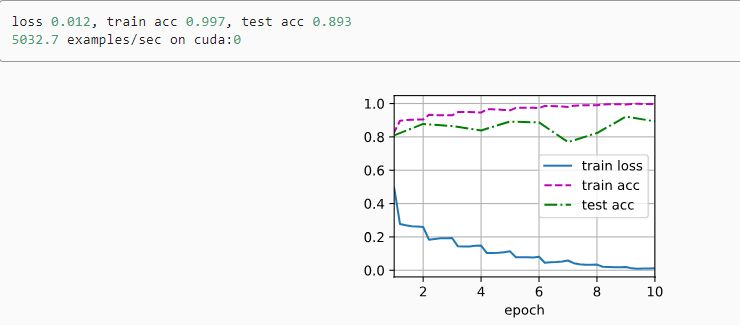
""" 定义GPU训练函数: 1、为了使用gpu,首先需要将每一小批量数据移动到指定的设备(例如GPU)上; 2、使用Xavier随机初始化模型参数; 3、使用交叉熵损失函数和小批量随机梯度下降。 """ #@save def train_ch6(net, train_iter, test_iter, num_epochs, lr, device): """用GPU训练模型(在第六章定义)""" # 定义初始化参数,对线性层和卷积层生效 def init_weights(m): if type(m) == nn.Linear or type(m) == nn.Conv2d: nn.init.xavier_uniform_(m.weight) net.apply(init_weights) # 在设备device上进行训练 print('training on', device) net.to(device) # 优化器:随机梯度下降 optimizer = torch.optim.SGD(net.parameters(), lr=lr) # 损失函数:交叉熵损失函数 loss = nn.CrossEntropyLoss() # Animator为绘图函数 animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['train loss', 'train acc', 'test acc']) # 调用Timer函数统计时间 timer, num_batches = d2l.Timer(), len(train_iter) for epoch in range(num_epochs): # Accumulator(3)定义3个变量:损失值,正确预测的数量,总预测的数量 metric = d2l.Accumulator(3) net.train() # enumerate() 函数用于将一个可遍历的数据对象 for i, (X, y) in enumerate(train_iter): timer.start() # 进行计时 optimizer.zero_grad() # 梯度清零 X, y = X.to(device), y.to(device) # 将特征和标签转移到device y_hat = net(X) l = loss(y_hat, y) # 交叉熵损失 l.backward() # 进行梯度传递返回 optimizer.step() with torch.no_grad(): # 统计损失、预测正确数和样本数 metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) timer.stop() # 计时结束 train_l = metric[0] / metric[2] # 计算损失 train_acc = metric[1] / metric[2] # 计算精度 # 进行绘图 if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1: animator.add(epoch + (i + 1) / num_batches, (train_l, train_acc, None)) # 测试精度 test_acc = evaluate_accuracy_gpu(net, test_iter) animator.add(epoch + 1, (None, None, test_acc)) # 输出损失值、训练精度、测试精度 print(f'loss {train_l:.3f}, train acc {train_acc:.3f},' f'test acc {test_acc:.3f}') # 设备的计算能力 print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec' f'on {str(device)}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70

训练模型
# 训练模型
lr, num_epochs, batch_size = 0.05, 10 ,256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
- 1
- 2
- 3
- 4