
- 1单细胞分析(五)——使用Harmony进行数据整合和去批次_单细胞去批次
- 2系统重置后,Windows安全中心空白或者提示联系IT管理员_windows重置后it
- 3汇编jmp指令的理解与用法_汇编 jmp
- 4光纤PCIe 卡学习资料:基于kintex UltraScale XCKU040的双路QSFP+光纤PCIe 卡_ku040支持背板吗
- 5海豚调度器(DolphinScheduler)_dolphinscheduler 调度原理
- 6AI经典书单:入门人工智能该读哪些书?_人工智能初学者看什么书
- 7内网渗透一周目通关_如和用net命令查看管理员账户
- 8项目管理证书 PMP 的含金量高吗?
- 9使用腾讯云轻量服务器Matomo应用模板建网站流量统计系统_matomo前端调用
- 10YOLOv8优化策略:下采样涨点篇 |引入YOLOv9的下采样ADown_yolov8下采样
学习分享——基于深度学习的NILM负荷分解(一)对DL的看法&准备工作
赞
踩
好啦,我来填坑啦哈哈
经过了几个月的对深度学习的学习、了解和实践,
对于用深度学习来做NILM的经验也是积累了不少。
在此,做以小结。
在此,感谢~柳柳,小张,小田,小刘的支持和鼓励。

话不多说,下面开始!~
一,心里上的准备
本文开始的一系列文字,是基于深度学习的方法,来做负荷有用功分解预测以及电器识别的。
如果是要用传统的概率模型,可以参照我之前的几篇,传送门:https://blog.csdn.net/wwb1990/category_9655726.html
说到深度学习,行业内俗称 “炼丹”,用什么炼(各种架构),炼多久(各种参数),怎么炼(网络结构),炼出来的好不好(标准),,,以上基本没有个统一的说法,充满着不确定性(刺激)

而且很多时候,是不能用人的理解方式,去评判训炼出的模型结果的对错的。只能说是网络学到了我们想让他学到的逻辑,或者是学的不是我们期待他学的。
我认为这是个心态问题,即结果的正确率很低,那这时候要思考的,首先应该是,
1,我给网络学习的材料(输入),是不是包含我希望他学的知识。
举个栗子,输入的数据包含了太多的繁杂的信息,那么少量数据的学习,不一定就学到关键信息。
再来个贴切的例子,给网络训练时候,训练红衣服,蓝裤子,让它分类。它可以分出来了,但是有可能你再给他一个蓝衣服的时候,它认成了裤子。
这里面又涉及了两个问题,
一个是训练的数据集少,如果训的数据集包括蓝衣服,那就能将蓝衣服分到衣服里面。这个是数据集的涵盖范围,即,如果你也不清楚用什么特征可以区分分类的话,那就尽可能多的给出各种数据参数来学习,以及尽可能多数量和多样的数据。
第二个是关键属性的提取,也就是数据的预处理。以上面的例子来说,我们人已经知道了,通过颜色是肯定不能区分衣服还是裤子,那为了避免网络学到这个(出现上面蓝衣服问题),在输入数据的时候,可以预处理数据,归纳到只输入衣服和裤子的形状等。
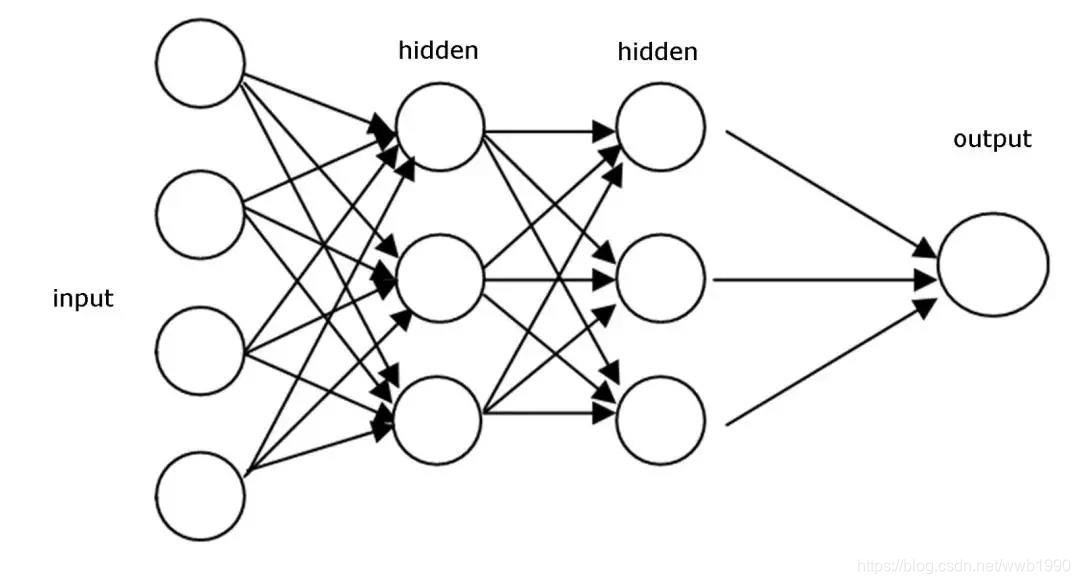
2,它学习的方式(网络结构和类型),能不能总结或提炼出我希望他学的知识。
这个就很好说多了,
循环网络就是提炼一个序列中变化的规律,
卷积网络就是提取图中的细节中找规律
全连接网络就是从一堆数据中找到规律,
卷积+循环就是从序列的图中的细节中找到变化规律
卷积+全连接就是从图中的细节提取的数据中找规律
。。。。
我上面说的都是帮助理解的举例哈,
实际上与输入,网络层间关系,以及输出都有关。也就是说用,举例:全连接也可以学习图的规律,也可以找序列变化规律,但是网络结构,输入输出要做出相应调整。
意思就是,你的网络设计要能学会你需要学到的规律。
3,我如何去改进它
这方面,也是初入丹道的我一直在追寻的,目前认为比较玄学。
因为看书也好,看大神们的博客论文也好,会发现,每个使用场景,甚至每个数据集,每次训练,都是不一样的。
因为深度学习的核心就是随机,所以没有绝对正确的方法。
但这个正是大家在同一起跑线的优势,
而大神们也仅仅是比你的经验多一些(有用的和失败的)
只有不断的开拓创新,实验调参,改善结构,,,各种方案无所不用其极。才能龟速的提升你的模型~~hhhh
所以不用着急,就算一开始正确率比较低,那也不是网络的错(网络他爹的?)
去思考前两点,然后调整各种参数的实验,才能有感觉~~
(这里我用的是感觉,而不是理性思维推导,,因为可能你在尝试了几次某一个参数改大,正确率就降低,然后要放弃的时候,又多改大了一点点,就突然神奇的正确率提升了(匪夷所思就对了~))

二,技能和环境上的准备
前面说了一堆对于深度学习的理解哈,下面开始本项目的切实准备工作。
Python不多说了,我这里用的3.6
pytorch,keras 建议二选一,深度学习新人建议keras。高手直接用TF或者其他网络随意随意。(举个例子:同一个网络,TF要写50行代码,pytorch写20行,keras写10行。当然论灵活性TF原架构最高,pytorch其次,keras低点。易用性keras最高,初学者(我目前= =)能想到的网络都能轻松构建)
初学深度学习的同学,我推荐一本keras的书,我自己就是1个月左右的业余时间,通读+所有代码都是通透了一遍。
(不做广告,只发个豆瓣的,各种网上有书卖的都有,自己去查吧长下面这样https://book.douban.com/subject/30293801/)

安装pytorch和TF2的网上页多得是,我也有篇文字可以参考(RNN & LSTM 学习笔记 —— Anaconda安装,Python安装,PyTorch,Tensorflow配置)
Keras的安装和TF2 GPU版本的安装在这篇文章(深度学习 从零开始 —— 神经网络(三),安装配置keras,GPU版本TensorFlow,安装CUDA各种坑~~~)
最好是有GPU的电脑,TF2-GPU版本能让你时半功成~~
当然,没有GPU或者装CUDA懵圈的同学,那就简单安装普通CUP的TF2吧。就是跑的慢点,结果都一样。去上一天课回来就训完了 hhhhh
这里列一下我使用的一些关键库的版本:
除了nilmtk用的panda库需要0.25.0的以外。其他应该是新的就好吧(大概是)

剩下需要的sci,numpy等等的库就装新的就好。
二,数据集的准备
之前用的是REDD的数据集,用过的同学,打印一下全部就知道,中间时间缺失了一大部分的数据、、、
所以这次我们使用UK-DALE的数据集 https://ukerc.rl.ac.uk/DC/cgi-bin/edc_search.pl?GoButton=Detail&WantComp=41
而且其中已经有转好格式的h5文件,只下载这个就包含前面的原始数据内容了。

以上准备好了
可以开始我们《深度学习大冒险》了
To be continued.


