- 1【GitHub学生包】2022年12月GitHub学生包最新申请教程 18次认证失败的经验之谈_github education pack学生包
- 2Postgresql数据库介绍7——使用_there is a column named "anln1" in table "ams_asse
- 3protobuf 编码探究_proto的协议号
- 4Navicat for MySQL 11注册码_navicat 11.1注册
- 5数据结构学习笔记——线性表的概念及顺序表示(超详细最终版+++)建议反复看看ヾ(≧▽≦*)o_顺序表的输出
- 6Flyway 数据库版本管理 | 专业解决方案
- 7学习FPGA-4:点个灯_td软件点灯
- 8Java实战09之 linux 下 prometheus+Grafana 监控 快速上手_java 普罗米修斯
- 9RocketMQ 之 IoT 消息解析:物联网需要什么样的消息技术?_mq 物联网
- 10数据结构——数组与链表_数组和链表
基于stm32f407cube ai实例_stm32cube.al
赞
踩
基于stm32f407cube ai实例
(一)Cube ai简介
得益于st的一套新的人工智能(ai)解决方案,您现在可以在广泛的stm32微控制器产品组合上映射和运行预先训练的人工神经网络(ann)。stm32cube.ai是广泛使用的stm32cubemx配置和代码生成工具的扩展包,支持基于stm32 arm cortex -m的微控制器上的ai。要访问它,请下载并安装stm32cubemx(版本5.0.1以后)
(二)用处
1.用stm32cube.ai简化人工神经网络映射
与流行的深度学习培训工具互操作
兼容许多ide和编译器
传感器和rtos不可知
允许多个人工神经网络在单个stm32 mcu上运行
完全支持超低功耗stm32 mcus
2.提高你的生产力
在stm32应用程序中,利用深度学习的力量来提高信号处理性能和生产率。创建人工神经网络并将其映射到stm32(自动生成的优化代码),而不是构建手工代码。有关更多信息,您可以下载此演示文稿。
(三)使用stm32cube.ai部署神经网络的5个步骤
1.捕获数据
捕获足够数量的关于正在建模的现象的代表性数据。
这通常需要将传感器放在被监控对象上或附近,以便记录其状态和随时间变化的情况。物理参数的示例包括加速度、温度、声音和视觉,具体取决于您的应用程序。
ST提供有助于数据捕获和标记的工具,例如我们的ST BLE传感器智能手机应用程序,它可作为传感器瓦形状系数、电池供电平台的遥控器。传感器瓦配有运动和环境传感器、微控制器、SD卡接头和蓝牙连接。
2.清理、标记数据并构建人工神经网络拓扑
创建一个人工神经网络需要从传感器和预处理中获取标记数据。
对于所谓的“监督学习”,必须对数据集进行特征化,以便正确分类不同的输出。这个分类集是“地面真相”,将用于训练人工神经网络,然后验证它。开发人员必须决定ann应该具有的拓扑类型,以便能够最好地从数据中学习并为目标应用程序提供有用的输出。通常开发人员使用流行的现成深度学习框架来构建和训练人工神经网络拓扑。st与许多合作伙伴合作,提供人工神经网络工程服务,并与专门的数据科学家和人工神经网络架构师一起提供支持。
3.训练人工神经网络模型
训练神经网络涉及到以迭代的方式通过神经网络传递数据集,以便网络的输出可以最小化期望的错误标准。人工神经网络的定义、培训和测试通常使用现成的深度学习框架来执行。这通常是在一个强大的计算平台上完成的,该平台具有几乎无限的内存和计算能力,允许在短时间内进行多次迭代。该训练的结果是预训练的人工神经网络。
ai工具与人工智能开发人员社区广泛使用的流行的深度学习培训工具提供简单有效的互操作性。这些工具的输出可以直接导入stm32cube.ai。
4.将人工神经网络转换为stm32 mcu的优化代码
下一步是将预先训练好的神经网络嵌入到一个微控制器中(优化的代码使复杂度和内存需求最小化)。
借助stm32cube.ai软件工具,此部分非常简单直观。作为广泛使用的stm32cubemx工具的扩展,stm32cube.ai完全集成到stm32软件开发生态系统中。
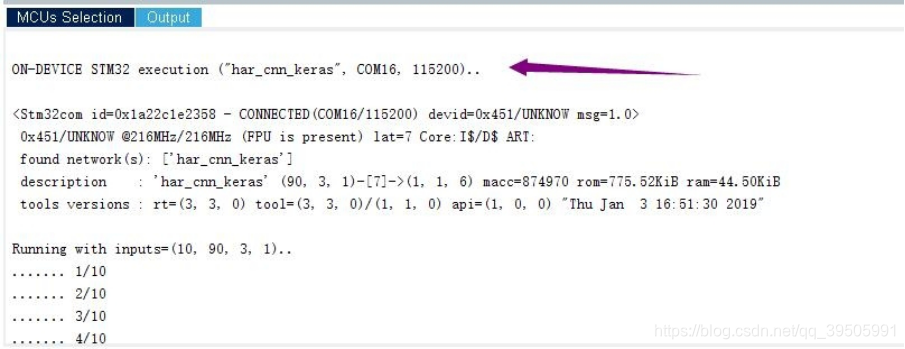
它允许快速、自动地将预先培训好的人工神经网络转换成可以在单片机上运行的优化代码。该工具指导用户选择正确的MCU,并提供所选MCU中神经网络性能的快速反馈,同时在您的PC和目标STM32 MCU上运行验证。查看我们的入门视频。
5.使用训练有素的人工神经网络处理和分析新数据
最后,在应用程序中部署嵌入在MCU中的ANN。
在这里,由于集成软件包(功能包),ST还使设计者更容易快速地创建他们的创新应用程序原型。这些包是端到端的示例,将低级驱动程序、中间件库和示例应用程序的组合嵌入到单个软件包中。开发人员可以很容易地从这些示例开始,并进行修改以适应其特定的应用程序。为人工智能启用的两个示例是音频和运动捕获和处理功能包。
(六)实例演示
这里我们应用的模型是基于卷积神经网络的人体活动识别的模型,可以在https://github.com/Shahnawax/HAR-CNN-Keras中下载。
keras中基于卷积神经网络的人体活动识别(model.h5)
这个存储库包含一个小项目的代码。这个项目的目的是创建一个简单的基于卷积神经网络(cnn)的人类活动识别(har)系统。该系统使用来自x、y和z轴的3d加速度计的传感器数据,并识别用户的活动,例如行走、慢跑、上楼或下楼等。
在这些实验中,我们使用了actitracker数据集,该数据集由无线传感器数据挖掘(wisdm)实验室发布,可以在[链接上找到]。这个数据库中提供数据是用智能手机从36个用户那里收集的,采样速率为每秒20个样本。数据包含x、y和z轴的加速度值,而用户在受控环境中执行六种不同的活动。这些活动包括
下楼,慢跑,坐着,站着,上楼,走路。
步骤
首先需要下载cube最新版本,5.0.1以上的版本都可以,这个到网上找一大堆安装教程。
然后需要安装X-CUBE-AI插件
点击help
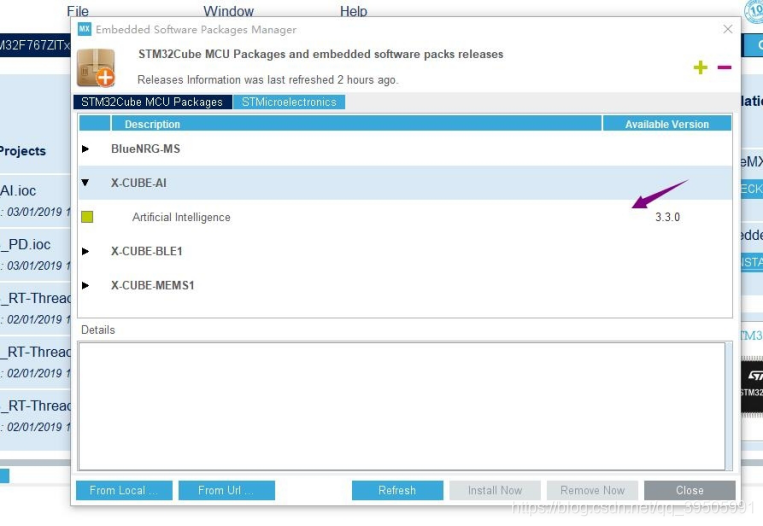
然后新建工程,点file,new project
左边拖到下面可以看到
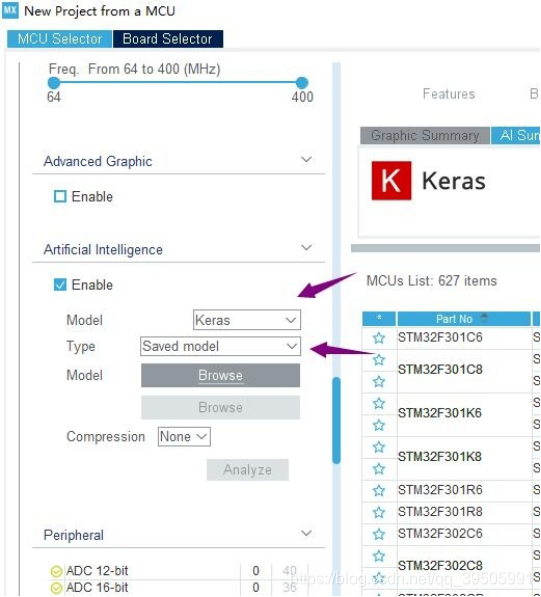
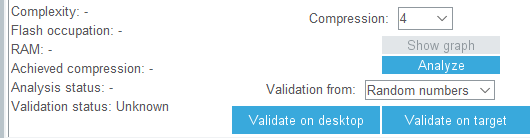
Compression选4,这个是选择压缩参数,不同的压缩参数对MCU的flash容量
要求也不一样。。
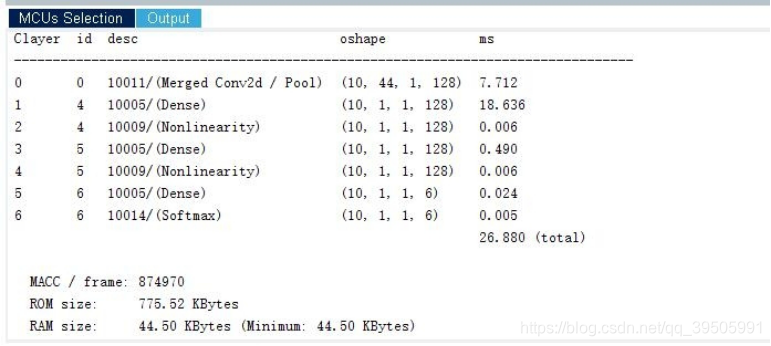
然后点Analyze计算使用这个神经网络算法的ram和flash容量占用
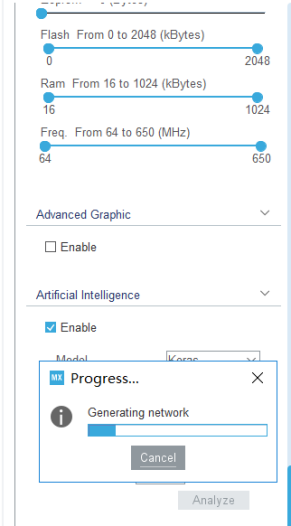
好了之后

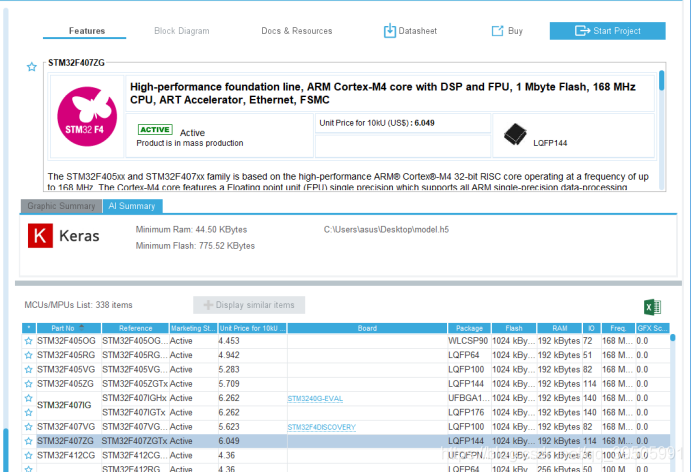
然后选择芯片,(根据所需的flash大小),这里选择stm32f407ZG,然后点start project
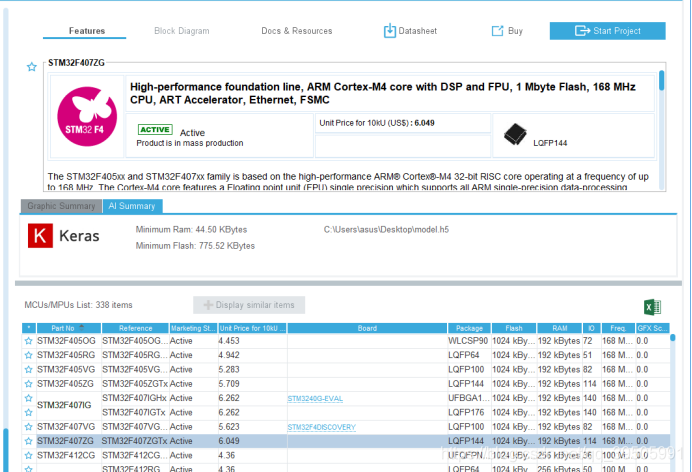
好了选择好了,板卡,我们还需要给它添加
扩展库,也就是AI库
点Addition Software
- List item


选择Validition,core打钩,然后点ok
左下角会多出一个
点开

两个都打钩,选network
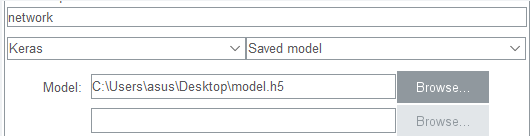
然后往下拖,选Analyze
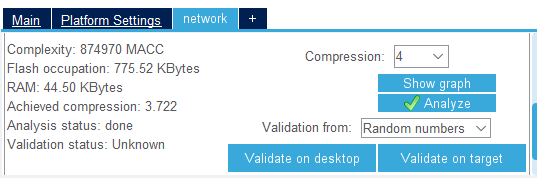
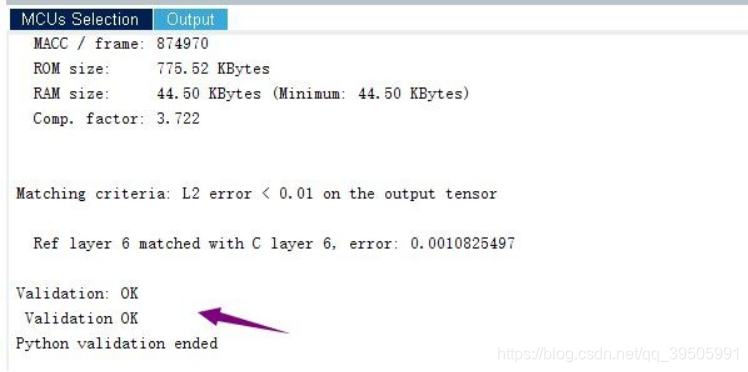
打勾表示验证通过
然后配置时钟,点击

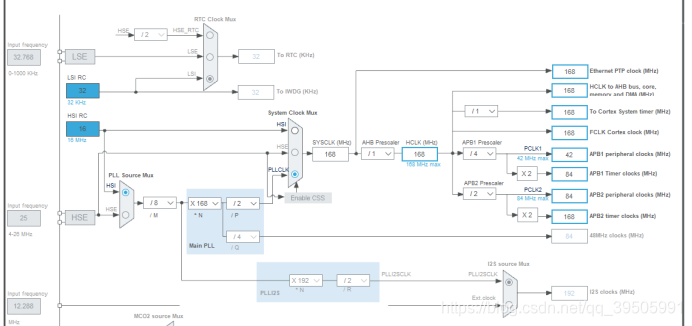
按照图上配置好
然后我们需要配置串口1和CubeMx进行通讯,验证我们
工程。。。

PA9,PA10选择好,然后点击Connectivity
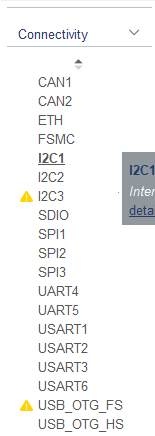
点击USART1
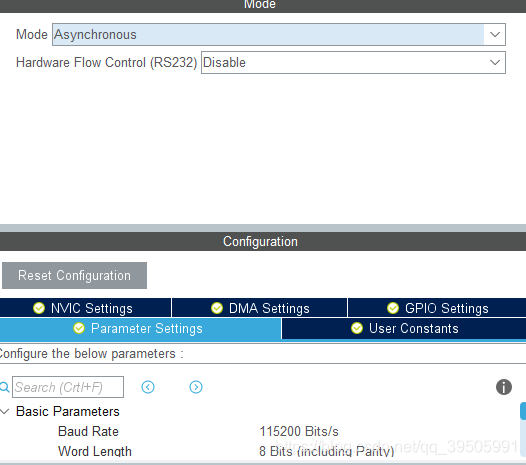
Mode选好
然后在 AI扩展功能里选择通讯端口为串口1
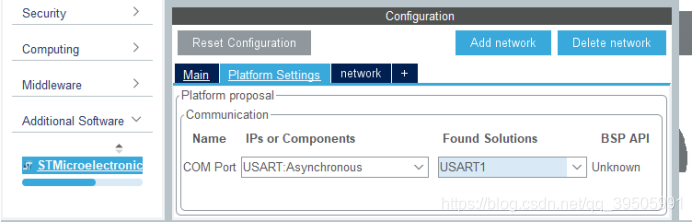
然后配置下工程信息
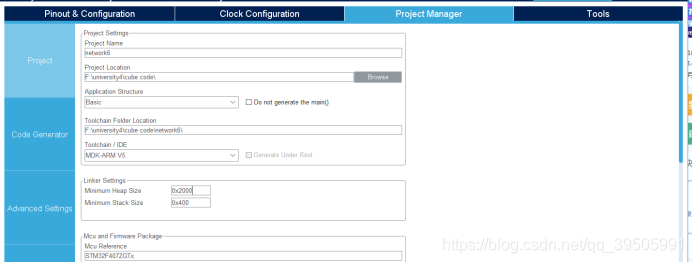
Project name,这个可以自己命名,然后IDE选择下,这里选mdk5,heap size记得选0x2000
然后code generator
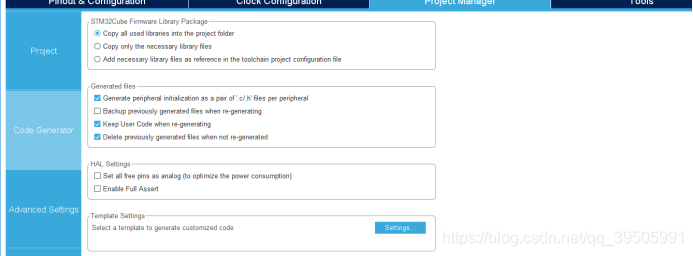
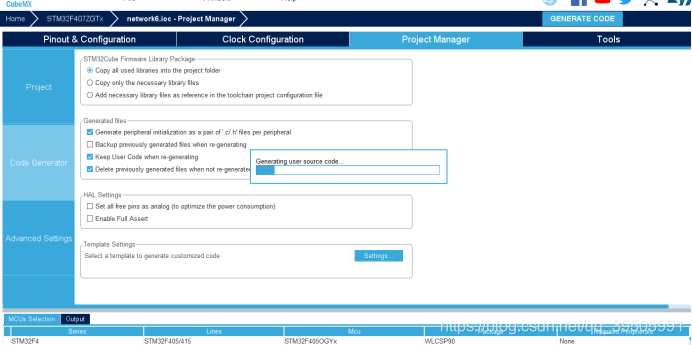
最后点击右上角 生成代码工程
生成代码工程
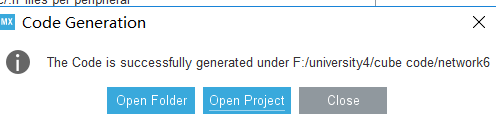
没问题后点open project就可以直接打开工程了
然后选择芯片型号
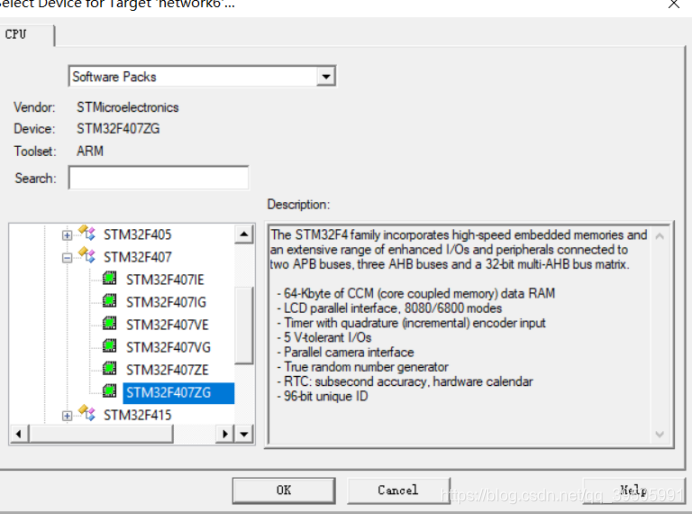
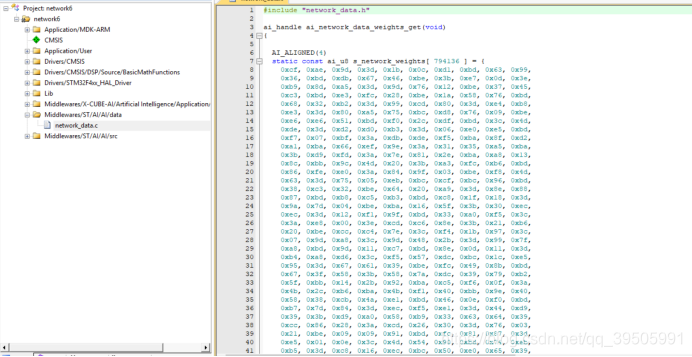
在data中可以看到相应的数据。
然后编译下工程,这个需要等待几分钟
没有错误后就可以下载到板子上验证了。
Stlink或者jlink自己配置下,然后下载。记得要用串口线,因为需要与cube通信。
好了,现在我们需要回到CubeMx里,回到
AI扩展功能里。。 先重启下开发板,然后
点击Validation on target
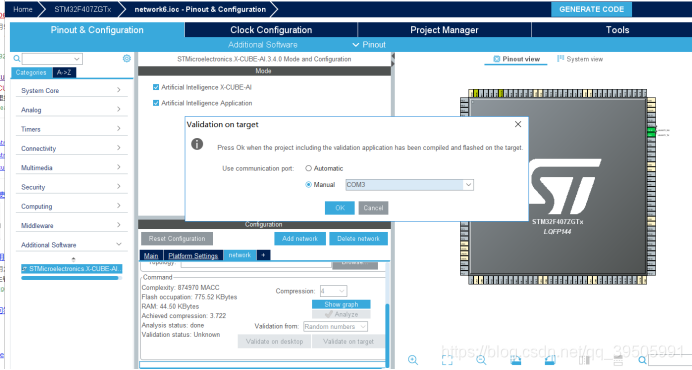
选择相应的串口号,这个可以在我的电脑设备管理器中看到
验证成功后可以看到状态那边显示成功
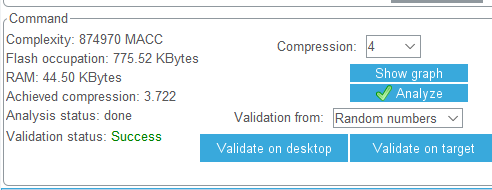
在output中可以看到相应的数据