
- 1胡乱兼职的,能骂醒一个算一个!
- 2关于微信小程序爬虫关于token自动更新问题_微信公众号 爬虫的token
- 3java线程池(简单易懂)
- 4人工智能研究的各个学派_人工智能符号主义基本思想
- 5Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器_缓存有失效时间吗
- 62024蓝桥杯攻略大全 | 学习路线 | 注意事项_蓝桥之路
- 7数据结构之栈和队列_数据结构栈
- 8多背背八股文确实有奇效,Java后端开发三年,朋友30k,而我12K
- 9LINUX下安装Neo4j 5.5.0版本保姆级教程(安装血泪)_neoj4的linux
- 10VID-视频目标检测_vid测试是什么
HDFS分布式文件存储系统
赞
踩
1-1 HDFS的存储机制
按块(block)存储
hdfs在对文件数据进行存储时,默认是按照
128M(包含)大小进行文件数据拆分,将不同拆分的块数据存储在不同datanode服务器上拆分后的块数据会被分别存储在不同的服务器上
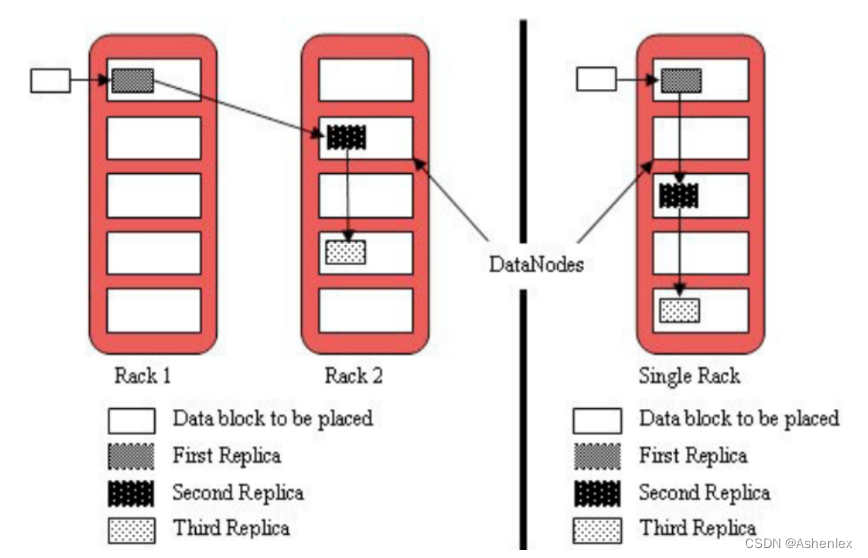
副本机制
为了保证hdfs的数据的安全性,避免数据的丢失,hdfs对每个块数据进行备份,默认情况下块数据会存储3份,叫做3副本
副本块是存在不同的服务器上
默认存储策略由BlockPlacementPolicyDefault类支持。也就是日常生活中提到最经典的3副本策略。
1st replica 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
2nd replica 第二个副本存放于不同第一个副本的所在的机架
3rd replica 第三个副本存放于第二个副本所在的机架,但是属于不同的服务器节点
1-2 HDFS写入数据流程
1、client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、client请求第一个 block该传输到哪些DataNode服务器上;
3、NameNode根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的DataNode的地址,如:A,B,C;
4、 client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,后逐级返回client;
5、 client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(默认64K),A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答。
6、 数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点A将pipeline ack发送给client;
7、 当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
1-3 HDFS数据读取流程
1、 Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址;
3、 这些返回的DN地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离Client近的排靠前;心跳机制中超时汇报的DN状态为STALE,这样的排靠后;
4、 Client选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
5、 底层上本质是建立FSDatainPutStream,重复的调用父类DataInputStream的read方法,直到这个块上的数据读取完毕;一旦到达块的末尾,FSDatainPutStream关闭连接并继续定位下一个块的下一个 DataNode;
6、 当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;一旦客户端完成读取,它就会调用 close() 方法。
7、 读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读。
8、 NameNode只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
9、 最终读取来所有的block会合并成一个完整的最终文件。
1-4 checkpoint机制
checkpont机制是secondname和namenode之间的数据操作
该机制决定了secondname什么时候进行元数据的持久化保存
条件一 距离上一次保存时间过去了1个小时
条件二 文件的事务操作(文件写入,文件修改,文件删除)达到了100万次
两个条件任意一个满足就执行checkpoint
fsimage文件其实是Hadoop文件系统元数据的一个永久性的检查点,其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;fsimage包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;对于文件来说,包含的信息有修改时间、访问时间、块大小和组成一个文件块信息等;而对于目录来说,包含的信息主要有修改时间、访问控制权限等信息。
edits文件存放的是Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所以写操作首先会被记录到edits文件中。
hdfs oiv -p XML -i fsimage_00000000000000000 -o fsimage.xml hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o edits.xml
checkpoint的触发流程
1-NameNode管理着元数据信息,其中有两类持久化元数据文件:edits操作日志文件和fsimage元数据镜像文件。新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源),操作成功之后更新至内存。
2-有dfs.namenode.checkpoint.period和dfs.namenode.checkpoint.txns 两个配置,只要达到这两个条件任何一个,secondarynamenode就会执行checkpoint的操作。
3-当触发checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地(HTTP GET方式)。
4-secondarynamenode将下载下来的fsimage载入到内存,然后一条一条地执行edits文件中的各项更新操作,使得内存中的fsimage保存最新,这个过程就是edits和fsimage文件合并,生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
5-secondarynamenode将新生成的Fsimage.ckpt文件复制到NameNode节点。
6-在NameNode节点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此刚好是一个轮回,即在NameNode中又是edits和fsimage文件。
7-等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
checkpoint不能完全保证元数据不丢失,如果真出现服务器宕机,会丢失最新的操作数据
1-5 安全机制
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求,是一种保护机制,用于保证集群中的数据块的安全性。
如果HDFS处于安全模式下,不允许HDFS客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹,修改副本数等操作。
在hdfs启动后默认是在安全模式,该模式会检查各个块信息,只有确认块数据完整后会退出安全模式
退出安全模式的条件
1-每个数据块最小副本数量,默认为1. 在上传文件时,达到最小副本数,就认为上传是成功的。
2-达到最小副本数的数据块的百分比。默认为0.999f。
3-离开安全模式的最小可用datanode数量要求,默认为0,也就是即使所有datanode都不可用,仍然可以离开安全模式
4-集群可用block比例,可用datanode都达到要求之后,如果在extension配置的时间段之后依然能满足要求,此时集群才离开安全模式。单位为毫秒,默认为30000.也就是当满足条件并且能够维持30秒之后,离开安全模式
因为虚拟机的非正常关机,造成块的数据丢失,就进入安全模式
安全模式的指令操作
# 离开安全模式,但是如果块数丢失较多无法离开使用前置离开 hdfs dfsadmin -safemode leave # 强制退出 hdfs dfsadmin -safemode forceExit

