
- 1探究Hugging Face Pipeline类:一站式自然语言处理工具_huggingfacepipeline
- 2spring整合mybatis(实现数据的增删改查)_spring mybatis增删改查
- 3Python中的模块化编程与软件架构设计_python系统软件架构设计
- 4【误码率仿真】多径信道下OFDM通信系统误码率仿真【含Matlab源码 2078期】_matlab实现ofdm误码率仿真
- 5循环、使用dict和set
- 6github新建项目_github创建新项目
- 7node.js安装与环境配置以及npm、cnpm下载_下载cnpm
- 8Python - Flask 无脑学习实践 (三)Flask Blueprint 使用和运行的简单说明_python blueprint
- 9uniapp使用request下载图片,并且显示出来_uni.request获取本地图片
- 10m基于FPGA的8FSK调制解调系统verilog实现,包含testbench测试文件_fpga实现fsk
single-pass聚类算法实现天气聚类_对天气数据进行聚类分析
赞
踩
聚类算法介绍
(1)系统聚类法
系统聚类法的基本思想是:距离近的样品先聚成类,距离远的后聚成类。
根据类间定义的不同,系统聚类法又可以分成最短距离法、最长距离法、中间距离法、重心法、类平均法、可变类平均法、可变法、离差平方和法8种。
需要注意的是:
(1)该方法不需要事先指定聚类个数,而是根据最终的分类过程确定。
(2)为了直观的反映,可以把分类系统画成一张谱系图,所以系统聚类也称谱系分析。
(2)K-means聚类法
K-means聚类法是非常经典的聚类算法,有关资料很丰富,故本文不再赘述。
需要注意的是:
(1)该方法通过计算欧氏距离,比较样品间的相似度进行聚类。不过我也有看过,通过计算相关系数来聚类的。
(2)该法需要指定聚类个数,而K的确定是个难点,有很多针对K优化的方法。
(3)single-pass聚类法
含义适用
Single-pass clustering,中文名一般译作“单遍聚类”,它是一种简洁且高效的文本聚类算法。相比于常用的K-means聚类法,它的计算速度非常快,且不需要指定聚类个数,而是通过设定相似度阈值来限定。
Single-pass聚类算法同时是一种增量聚类算法(Incremental Clustering Algorithm),每个文档只需要流过算法一次,常用与文本主题的聚类中。它可以很好的应用于话题监测与追踪、在线事件监测等社交媒体大数据领域,特别适合流式数据(Streaming Data),比如微博的帖子信息等。
流数据:一组顺序、大量、快速、连续到达的数据序列。一般情况下,流数据可被视为一个随时间延续而无限增长的动态数据集合。
来源:百度百科
处理步骤
Single-pass算法顺序处理文本,以第一篇文档为种子,建立一个新主题。之后再进行新进入文档与已有主题的相似度,将该文档加入到与它相似度最大的、且大于一定阈值的主题中。如果与所有已有话题相似度都小于阈值,则以该文档为聚类种子,建立新的主题类别。其算法流程如下:
(1)以第一篇文档为种子,建立一个主题;
(2)将文档X向量化;
(3)将文档X与已有的所有话题均做相似度计算,可采用欧氏距离或余弦距离等距离度量方法
(4)找出与文档X具有最大相似度的已有主题;
(5)若相似度值大于阈值θ ,则把文档X加入到有最大相似度的主题中,跳转至 (7);
(6)若相似度值小于阈值θ , 则文档X不属于任一已有主题, 需创建新的主题类别,同时将当前文本归属到新创建的主题类别中;
(7)聚类结束,等待下一篇文档进入
注:上述中讲相似度最大的划为一类,在实际代码中,所谓相似度最大大于某个阈值,也可以理解为距离最近(小)小于某个阈值。
样本描述
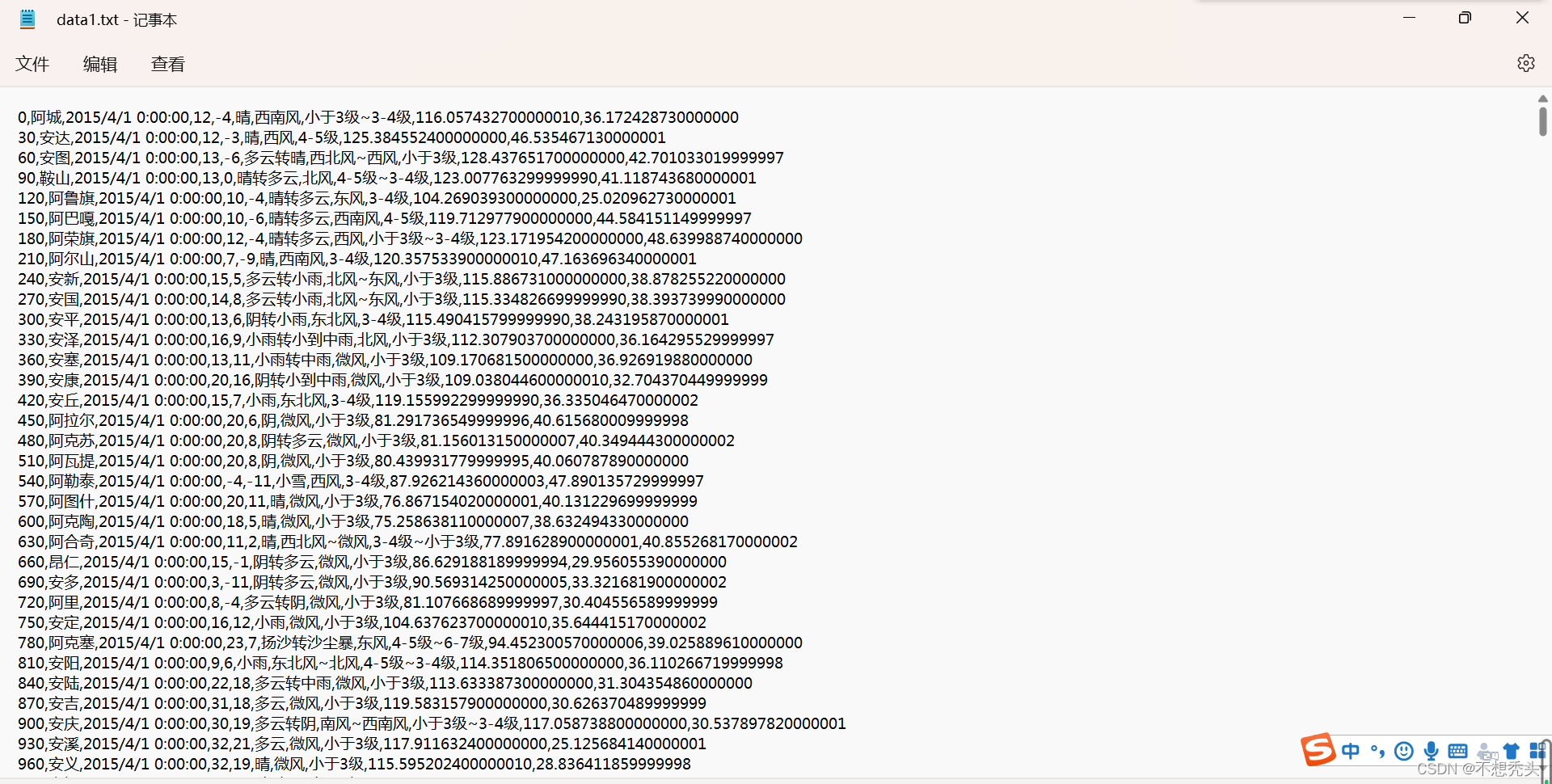
将样本信息保存至TXT文件中,截图后如上所示。
有多少行我没数,用python中describe()一下就知道了,列数是十列。
日期后面两类是最高温和最低温,最后两列表示该地的经度和纬度。
代码实现
定义类和函数
首先定义了一个簇单元 ClusterUnit ,定义了一个单类 OnePassCluster ,定义了向量a与b间的欧式距离euclidian_distance。
# coding=utf-8 import numpy as np from math import sqrt import time import matplotlib.pylab as pl # 定义一个簇单元 class ClusterUnit: def __init__(self): self.node_list = [] # 该簇存在的节点列表 self.node_num = 0 # 该簇节点数 self.centroid = None # 该簇质心 def add_node(self, node, node_vec): """ 为本簇添加指定节点,并更新簇心 node_vec:该节点的特征向量 node:节点 return:null """ self.node_list.append(node) try: self.centroid = (self.node_num * self.centroid + node_vec) / (self.node_num + 1) # 更新簇心 except TypeError: self.centroid = np.array(node_vec) * 1 # 初始化质心 self.node_num += 1 # 节点数加1 def remove_node(self, node): # 移除本簇指定节点 try: self.node_list.remove(node) self.node_num -= 1 except ValueError: raise ValueError("%s not in this cluster" % node) # 该簇本身就不存在该节点,移除失败 def move_node(self, node, another_cluster): # 将本簇中的其中一个节点移至另一个簇 self.remove_node(node=node) another_cluster.add_node(node=node) # cluster_unit = ClusterUnit() # cluster_unit.add_node(1, [1, 1, 2]) # cluster_unit.add_node(5, [2, 1, 2]) # cluster_unit.add_node(3, [3, 1, 2]) # print(cluster_unit.centroid) # 计算向量a与向量b的欧式距离 def euclidian_distance(vec_a, vec_b): diff = vec_a - vec_b return sqrt(np.dot(diff, diff)) # dot计算矩阵内积 class OnePassCluster: def __init__(self, t, vector_list): # t:一趟聚类的阈值 self.threshold = t # 一趟聚类的阈值 self.vectors = np.array(vector_list) # 数据列表(向量列表) self.cluster_list = [] # 聚类后簇的列表 t1 = time.time() self.clustering() t2 = time.time() self.cluster_num = len(self.cluster_list) # 聚类完成后 簇的个数 self.spend_time = t2 - t1 # 聚类花费的时间 def clustering(self): self.cluster_list.append(ClusterUnit()) # 初始新建一个簇 self.cluster_list[0].add_node(0, self.vectors[0]) # 将读入的第一个节点归于该簇 for index in range(len(self.vectors))[1:]: min_distance = euclidian_distance(vec_a=self.vectors[index], vec_b=self.cluster_list[0].centroid) # 与簇的质心的最小距离 min_cluster_index = 0 # 最小距离的簇的索引 for cluster_index, cluster in enumerate(self.cluster_list[1:]): # enumerate会将数组或列表组成一个索引序列 # 寻找距离最小的簇,记录下距离和对应的簇的索引 distance = euclidian_distance(vec_a=self.vectors[index], vec_b=cluster.centroid) if distance < min_distance: min_distance = distance min_cluster_index = cluster_index + 1 if min_distance < self.threshold: # 最小距离小于阈值,则归于该簇 self.cluster_list[min_cluster_index].add_node(index, self.vectors[index]) else: # 否则新建一个簇 new_cluster = ClusterUnit() new_cluster.add_node(index, self.vectors[index]) self.cluster_list.append(new_cluster) del new_cluster def print_result(self, label_dict=None): # 打印出聚类结果 # label_dict:节点对应的标签字典 print("*********** single-pass的聚类结果展示 ***********") for index, cluster in enumerate(self.cluster_list): print("cluster:%s" % index) # 簇的序号 print(cluster.node_list) # 该簇的节点列表 if label_dict is not None: print(" ".join([label_dict[n] for n in cluster.node_list])) # 若有提供标签字典,则输出该簇的标签 print("node num: %s" % cluster.node_num) print( "-------------") print( "所有节点的个数为: %s" % len(self.vectors)) print("簇类的个数为:%s" % self.cluster_num) print("花费的时间为: %.9fs" % (self.spend_time / 1000))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
运行之后,一共聚类十类,聚类个数从0-9。
如下图为第八个类别所包含的城市以及他们对应的索引:

整体运行结果如下:

调用与画图
之后通过实例化类和调用函数,来实现聚类
# 读取测试集 temperature_all_city = np.loadtxt('data1.txt', delimiter=",", usecols=(3, 4),encoding='utf-8') # 读取聚类特征 xy = np.loadtxt('data1.txt', delimiter=",", usecols=(8, 9),encoding='utf-8') # 读取各地经纬度 f = open('data1.txt', 'r',encoding='utf-8') lines = f.readlines() zone_dict = [i.split(',')[1] for i in lines] # 读取地区并转化为字典 f.close() # 构建一趟聚类器 clustering = OnePassCluster(vector_list=temperature_all_city, t=9) clustering.print_result(label_dict=zone_dict) print(temperature_all_city) # 将聚类结果导出图 fig, ax = pl.subplots() fig = zone_dict c_map = pl.get_cmap('jet', clustering.cluster_num) c = 0 for cluster in clustering.cluster_list: for node in cluster.node_list: #ax.scatter(xy[node][0], xy[node][1], c=c, s=30, cmap=c_map, vmin=0, vmax=clustering.cluster_num) ax.scatter(xy[node][0], xy[node][1]) c += 1 #pl.axis('off') # 不显示坐标轴 pl.savefig('./map.jpg') pl.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
根据样本中经纬度的信息,并结合聚类算法的结果,可画图如下:

总结
本文主要给出single-pass聚类算法的实例,该例很好复现。希望对各位兄弟姐妹们有所帮助。
参考:https://blog.csdn.net/maqian5/article/details/107333316
本文数据与代码均引用他处,如未标注来源,请联系我更改加上。
需要本文数据和代码,可在本文评论区留言。希望对各位兄弟姐妹们有所帮助。

