
- 1中国人情世故的63个定律 。_达人归纳的63则中国人情世故的定律
- 2python 连接clickhouse数据库及简单操作
- 3安装visio2019Pro提示报错“0xC004F017“具体解决办法
- 4KubeEdge安装加入边缘节点报错: error unmarshaling JSON: while decoding JSON: json: cannot unmarshal number into_error decoding json: json: cannot unmarshal number
- 5深度解析Kafka中的消息奥秘
- 6HarmonyOS RUST 应用开发指导_deveco reload rust project
- 7Flask表单详解
- 8自学Python做兼职月入过万,用Python做项目有多赚钱?_python副业可以赚多少钱
- 9Nacos下载配置启动
- 10单片机:STC89C52的最小单元_单片机52最小系统显示屏元器件名称
【GitHub项目推荐--13个最佳开源语音识别引擎】【转载】_音频提取文字 开源项目
赞
踩
语音识别(ASR)在人机交互方面发挥着重要的作用,可用于:转录、翻译、听写、语音合成、关键字定位、语音日记、语言增强等场景。语音识别基本过程一般包括:分析音频、音频分解、格式转换、文本匹配,但实际的语音识别系统可能会更复杂,并且可能包括其他步骤和功能组件,例如:噪声抑制、声学模型、语言模型和置信度评估等。
多年来,语音识别技术的进步令人印象深刻,我们可以使用语音识别技术实现智能家居、控制汽车实现自动驾驶、与ChatGPT等大模型对接进行对话、智能音箱、居家机器人等等。这些年来也因为自然语言处理、语音识别等技术的发展,诞生了很多优秀的公司,例如:讯飞**。
随着AI技术发展,越来越多的人或组织投入到语音识别相关领域的研究,也促进了该领域的开源项目蓬勃发展。开源项目往往更加易于定制化开发、使用成本更低、透明,并且可私有化部署,数据安全可控。这使得开源语音识别引擎在应用开发中越来越受到技术人员的青睐。
2024年已开始,AI热度不减,以下是几个截止目前比较优秀的开源语音识别引擎。
01
Whisper
源码:
https://github.com/openai/whisper
官网:
https://openai.com/research/whisper
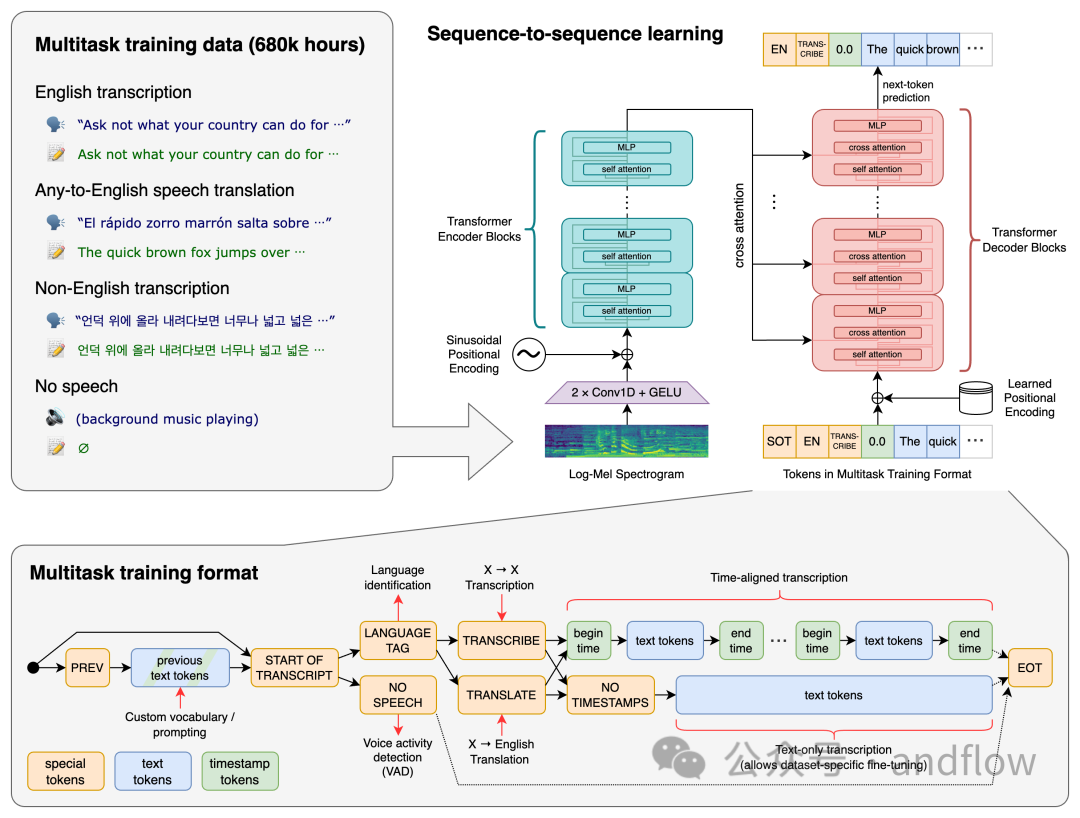
Whisper是Open AI的创意工具,提供了转录和翻译服务。该AI工具于2022年9月发布,是最准确的自动语音识别模型之一。它从市场上的其他工具中脱颖而出,因为它训练了大量的训练数据集:来自互联网的68万小时的音频文件。这种多样化的数据范围提高了该工具的鲁棒性。
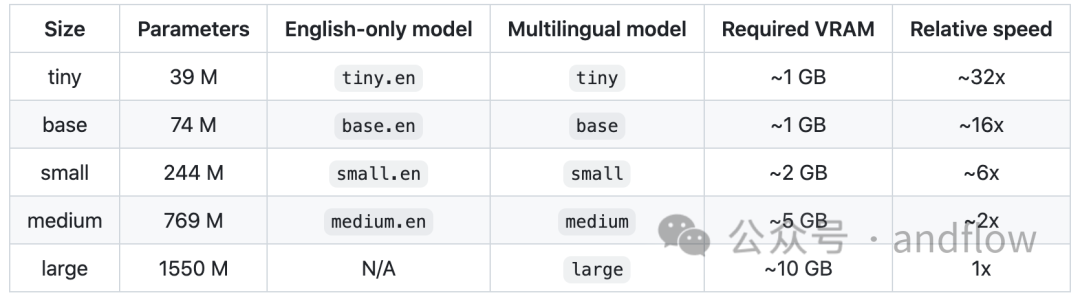
用Whisper进行转录必须先安装Python或命令行界面。他提供了五种型号的模型,所有型号都具有不同的大小和功能。这些包括微小、基本、小型、中型和大型。模型越大,转录速度越快。尽管如此,你必须要有一个好的CPU和GPU设备,才能最大限度发挥它们的性能。
与精通LibriSpeech性能(最常见的语音识别基准之一)的模型相比还是有差距,但是,它的零样本性能表现优异,API的错误比相同的模型少50%。
优点
-
它支持的内容格式,如MP3,MP4,M4A,Mpeg,MPGA,WEBM和WAV。
-
它可以转录99种语言,并将它们全部翻译成英语。
-
该工具是免费使用的。
缺点
-
模型越大,消耗的GPU资源就越多,这可能会很昂贵。
-
这将花费您的时间和资源来安装和使用该工具。
-
它不提供实时语音转录功能。
02
Project DeepSpeech
源码:
https://github.com/mozilla/DeepSpeech
Project DeepSearch是Mozilla的一个开源语音转文本引擎。此语音转文本命令和库在Mozilla公共许可证(MPL)下发布。它的模型参考的是百度深度语音研究论文,具有端到端的可训练性,并支持多种语言音频转录。它使用Google的TensorFlow进行训练和实现。
从GitHub下载源代码,并将其安装到您的Python中以使用它。该工具已经在英语模型上进行了预训练。但是,您仍然可以使用您的数据训练模型。或者,您可以获得一个预先训练的模型,并使用自定义数据对其进行改进。
优点
-
DeepSpeech很容易定制,因为它是一个原生代码解决方案。
-
它为Python、C、.Net Framework和JavaScript提供了开发包,不管哪一个开发语言,都可以使用该工具。
-
它可以在各种小设备上运行,包括Raspberry Pi设备。
-
它的每字错误率非常低,为7.5%。
-
Mozilla对隐私问题采取了严肃的态度。
缺点
-
据报道,Mozilla将终止DeepSpeech的开发。这意味着在出现错误和实现问题时将提供更少的支持。
03
Kaldi
源码:
https://github.com/kaldi-asr/kaldi

Kaldi是专门为语音识别的研究人员创建的语音识别工具。它是用C++编写的,并在Apache 2.0许可证下发布,这是限制最少的开源许可。与Whisper和DeepSpeech等专注于深度学习的工具不同,Kaldi主要专注于使用老式可靠工具的语音识别模型。这些模型包括隐马尔可夫模型(Hidden Markov Models)、高斯混合模型(Gaussian Mixture Models)和有限状态传感器(Finite State Transducers)。
优点
-
Kaldi非常可靠。它的代码经过彻底验证。
-
虽然它的重点不是深度学习,但它有一些模型可以实现转录服务。
-
它非常适合学术和行业相关的研究,允许用户测试他们的模型和技术。
-
它有一个活跃的论坛,提供适量的支持。
-
还有一些资源和文档可以帮助用户解决任何问题。
-
作为开源,有隐私或安全问题的用户可以检查代码以了解它是如何工作的。
缺点
-
它使用传统的模型方法可能会限制其准确性水平。
-
Kaldi不是用户友好的,因为它只是在命令行界面上运行。
-
它使用起来相当复杂,适合有技术经验的用户。
-
你需要大量的计算能力来使用这个工具包。
04
SpeechBrain
源码:
https://github.com/speechbrain/speechbrain

SpeechBrain是一个用于促进语音相关技术的研究和开发的开源工具包。它支持各种任务,包括:语音识别、增强、分离、说话日志和麦克风信号处理等。Speechbrain使用PyTorch作为开发框架。开发人员和研究人员可以从Pytorch的生态系统和支持中受益,以构建和训练神经网络。
优点
-
用户可以选择传统的或者基于深度学习的ASR模型。
-
很容易定制模型以适应您的需求。
-
它与Pytorch的集成使其更易于使用。
-
用户可以使用预训练模型来开发语音转文本的任务。
缺点
-
SpeechBrain的文档不像Kaldi的文档那么广泛。
-
它的预训练模型是有限的。
-
您可能需要特殊的专业知识来使用该工具。没有它,你可能需要经历一个陡峭的学习曲线。
05
Coqui
源码:
https://github.com/coqui-ai/STT
Coqui是一个先进的深度学习工具包,非常适合培训和部署stt模型。根据Mozilla公共许可证2.0授权,您可以使用它生成多个转录本,每个转录本都有一个置信度分数。它提供了预先训练的模型以及示例音频文件,您可以使用这些文件来测试引擎并帮助进行进一步的微调。此外,它有非常详细的文档和资源,可以帮助您使用和解决任何出现的问题。
优点
-
它提供的STT模型经过高质量数据的高度训练。
-
模型支持多种语言。
-
有一个友好的支持社区,您可以在那里提出问题并获得与STT相关的任何细节。
-
它支持实时转录,延迟极低,以秒计。
-
开发人员可以根据各种用例自定义模型,从转录到充当语音助手。
缺点
-
Coqui已经停止维护STT项目,专注于他们的文本到语音工具包。这意味着您可能需要自己解决任何问题。
06
Julius
源码:
https://github.com/julius-speech/julius

Julius是一个古老的语音转文本项目,起源于日本,最早可以追溯到1997年。它是在BSD-3许可证下发布。它主要支持日语ASR,但作为一个独立于语言的程序,该模型可以理解和处理多种语言,包括英语,斯洛文尼亚语,法语,泰语等。转录的准确性在很大程度上取决于您是否拥有正确的语言和声学模型。该项目是用C语言编写的,支持在Windows,Linux,Android和macOS系统中运行。
优点
-
Julius可以执行实时语音到文本的转录,内存占用率低。
-
它有一个活跃的社区,可以帮助解决ASR问题。
-
用英语训练的模型可以在网上下载。
-
它不需要访问互联网进行语音识别,因此适合重视隐私的用户。
缺点
-
像任何其他开源程序一样,您需要具有技术经验的用户才能使其工作。
-
它有一个巨大的学习曲线。
07
Flashlight ASR
源码:
https://github.com/flashlight/wav2letter
Flashlight ASR是由Facebook AI研究团队设计的开源语音识别工具包。它拥有处理大型数据集的能力,速度和效率非常突出。可以将速度归功于其在语言建模、机器翻译和语音合成中仅使用卷积神经网络。
在理想情况下,大多数语音识别引擎使用卷积和递归神经网络来理解和建模语言。然而,递归网络可能需要高计算能力,从而影响引擎的速度。
Flashlight ASR使用C++编译,支持在CPU和GPU上运行。
优点
-
它是最快的语音转文本系统之一。
-
您可以将其用于各种语言和方言。
-
该模型不会消耗大量的GPU和CPU资源。
缺点
-
它不提供任何预先训练的语言模型,包括英语。
-
你需要有深厚的编码专业知识来操作这个工具。
-
对于新用户来说,它有一个陡峭的学习曲线。
08
PaddleSpeech
源码:
https://github.com/PaddlePaddle/Paddle

PaddleSpeech是个开源的语音转文本工具包,可以在Paddlepaddle平台上使用,该工具在Apache 2.0许可下开源。PaddleSpeech是功能最多的工具包之一,能够执行语音识别、语音到文本转换、关键字定位、翻译和音频分类。它的转录质量非常好,赢得了NAACL2022最佳演示奖。
该语音转文本引擎支持多种语言模型,但优先考虑中文和英文模型。特别是中文模型,具有较为规范的文本和发音,使其适应中文语言的规则。
优点
-
该工具包提供使用市场上最好的技术的高端和超轻型型号。
-
语音转文本引擎提供了命令行和服务器选项,使其易于使用。
-
这对于开发人员和研究人员来说都是非常方便的。
-
它的源代码是用最常用的语言之一Python编写的。
缺点
-
它的重点是中文资源,因此在支持其他语言方面存在一些限制。
-
它有一个陡峭的学习曲线。
-
您需要具备一定的专业知识来集成和使用该工具。
09
OpenSeq2Seq
源码:
https://github.com/NVIDIA/OpenSeq2Seq

OpenSeq2Seq正如它的名字一样,是一个开源的语音转文本工具包,可以帮助训练不同类型的序列到序列模型。该工具包由Nvidia开发,在Apache 2.0许可证下发布,这意味着它对所有人都是免费的。它训练执行转录,翻译,自动语音识别和情感分析任务的语言模型。
可以根据自己的需求,使用默认预训练模型或者训练自己的模型。OpenSeq2Seq在使用多个显卡和计算机时可以达到最佳性能。它在Nvidia驱动的设备上工作得最好。
优点
-
该工具具有多种功能,使其非常通用。
-
它可以与最新的Python,TensorFlow和CUDA版本一起使用。
-
开发人员和研究人员可以访问该工具,进行协作并进行创新。
-
对使用Nvidia驱动设备的用户有利。
缺点
-
由于其并行处理能力,可能消耗大量的计算机资源。
-
随着Nvidia暂停项目开发,社区支持随着时间的推移而减少。
-
对于没有Nvidia硬件的用户可能不是很有利。
10
Vosk
源码:
https://github.com/alphacep/vosk-api
官网:
https://alphacephei.com/vosk/
Vosk是最紧凑、最轻量级的语音转文本引擎之一。这个开源工具包可以在多种设备上离线运行,包括:Android、iOS和Raspberry Pi。它支持20多种语言或方言,包括:英语、中文、葡萄牙语、波兰语、德语等。
Vosk提供了小型语言模型,不占用太多空间,理想情况下,大约只有50MB。然而,一些大型模型可以占用高达1.4GB。该工具响应速度快,可以连续将语音转换为文本。
优点
-
支持各种编程语言开发,如Java、Python、C++、Kotlyn和Shell等等。
-
它有各种各样的用例,从传输到开发聊天机器人和虚拟助手。
-
具有快速的响应时间。
缺点
-
引擎的准确性可能会因语言和口音而出现差异。
-
您需要开发专业知识来集成、使用该工具。
11
Athena
源码:
https://github.com/athena-team/athena
Athena是一个基于序列到序列的语音转文本开源引擎,在Apache 2.0开源许可下发布。该工具包适合研究人员和开发人员的端到端语音处理需求。模型可以处理的任务包括:自动语音识别(ASR)、语音合成、语音检测和关键字定位等。所有语言模型都基于TensorFlow实现,使更多开发人员可以访问该工具包。
优点
-
Athena用途广泛,从转录服务到语音合成。
-
它不依赖于Kaldi,因为它有自己的Python特征提取器。
-
该工具维护良好,并且定期更新。
-
它是开源的,免费使用,可供各种用户使用。
Cons缺点
-
它对新用户有比较陡峭的学习曲线。
-
虽然它有一个WeChat群组来提供社区支持,但它将访问权限限制为只有那些可以访问该平台的人。
12
ESPnet
源码:
https://github.com/espnet/espnet

ESPnet是一个基于Apache 2.0许可证发布的开源语音转文本软件,它提供端到端语音处理功能,涵盖了ASR、翻译、语音合成、增强和日志化等任务。该工具包采用Pytorch作为其深度学习框架,并遵循Kaldi数据处理风格。因此,您可以获得各种语言处理任务的全面配方。该工具支持多语言。可以将其与现成的预训练模型一起使用,或根据需求创建自己的模型。
优点
-
与其他语音转文本软件相比,该工具包具备出色的性能。
-
它可以实时处理音频,使其适合现场语音转录。
-
适合研究人员和开发人员使用。
-
它是提供各种语音处理任务的最通用工具之一。
缺点
-
对于新用户来说,集成和使用它可能很复杂。
-
您必须熟悉Pytorch和Python才能运行该工具包。
13
Tensorflow ASR
源码:
https://github.com/TensorSpeech/TensorFlowASR
Tensorflow ASR是一个使用Tensorflow 2.0作为深度学习框架来实现各种语音处理的语音转文本开源引擎。这个项目在Apache 2.0许可下发布。
Tensorflow最大优势是其准确率,作者声称它几乎是一个“最先进”的模型。它也是维护最好的工具之一,定期更新以改进其功能。例如,该工具包现在还支持在TPU(一种特殊硬件)上进行语言培训。
Tensorflow还支持使用特定的模型,如:Conformer、ContextNet、DeepSpeech2和Jasper。可以根据要处理的任务进行选择。例如,对于一般任务可以考虑DeepSpeech2,但对于精度有较高要求的则使用Conformer。
优点
-
在处理语音转文本时,语言模型具备较高准确性和效率。
-
可以将模型转换为TFlite格式,使其轻量且易于部署。
-
它可以提供各种语音到文本相关的任务。
-
它支持多种语言,并提供预先训练的英语、越南语、德语等语言模型。
缺点
-
对于初学者来说,安装过程可能相当复杂。用户需要具备一定的专业知识。
-
使用高级模型有一个比较陡峭的学习曲线。
-
TPU不允许测试,限制了工具的功能。
选型
以上推荐的开源语音识别引擎各有优缺点。如何选择,取决于具体应用需求和可用资源。
如果您需要一个兼容各种设备的轻量级工具包,那么Vosk 以及 Julius比较合适。因为它们可以在Android、iOS、Raspberry Pi上运行,并且还不会占用太多资源。
如果您需要自己训练模型,可以使用Whisper、OpenSeq2Seq、Flashlight ASR或者Athena等工具包。
原文链接:

