
- 1Solana初识\了解Solana:领导者轮换机制_solana原理
- 2解决pytorch报错:RuntimeError: DataLoader worker (pid(s) ***, ***, ***, ***) exited unexpectedly_runtimeerror: dataloader worker (pid(s) 18832, 852
- 3【 C++ 】哈希表底层结构剖析_c++ 实现哈希表开散度
- 4软考高项:项目沟通及干系人管理模拟试题_关于项目干系人的选择题怎么写
- 5MySQL数据库基础
- 6com.alibaba.otter.canal.client.impl.ServerNotFoundException: no alive canal server for ucs_sf_to_qg_
- 7软件测试笔试题1(附答案)_软件测试笔试题博客
- 8百川智能发布超千亿大模型Baichuan 3,中文评测超越GPT-4
- 9一个小技巧 N-garm_ngarm算法
- 10十月丰收季,程序员小跃都收获了什么?_10月程序员
硬件成本节省60%,四川华迪基于OceanBase的健康大数据数仓建设实践
赞
踩

导语:本文为四川华迪数据计算平台使用 OceanBase 替代 Hadoop 的实践,验证了 OceanBase 在性能和存储成本方面的优势:节省了 60% 的硬件成本,并将运维工作大幅减少,从 Hadoop 海量组件中释放出来;一套系统处理 HTAP 场景需求,简化了运维复杂度。
作者简介:向平,现任四川华迪信息技术有限公司智慧医养研发部技术总监,主要负责智慧医养板块大数据和人工智能相关架构设计和团队管理工作。
随着老龄化现象加剧,养老问题逐渐成为社会广泛关注的话题,尤其是健康养老这个难题,需要汇聚社会各方智慧、资源和力量来破解。
四川华迪信息技术有限公司(以下简称“华迪”)充分利用大数据、云计算、物联网、人工智能、移动互联网等新一代信息技术的融合创新,打造了“齐家乐智慧医养大数据公共服务平台”。并与项目示范所在地政府及其主管部门合作共同探索和创建了“校地企智慧医养新模式”,汇聚居民社区、老人亲属、养老机构、医疗机构、医学院、地方政府、科技企业、以及生活服务机构等各方力量,为适龄老人提供专业、高效、便捷、安全的健康养老服务。
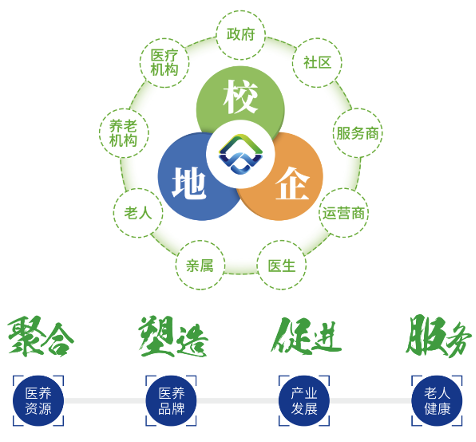

“齐家乐”平台是医养结合的资源整合平台、工作平台、服务平台、宣传平台,将健康信息预警、慢病和老年病辅助决策、医养结合服务、健康知识学习等功能融为一体,形成了纵贯省、市、县(区)、乡镇(街道)、村(社区)五级,全方位、专业化、综合性医养公共服务网络,打造多层级“健康数据采集→大数据分析预警→干预服务→效果评价”的智慧医养闭环服务体系。形成了以老年人群为主,聚合家庭、社区、医养机构、医院、政府为一体的多场景医养服务模式,通过实时、实名、动态、连续的现代社区智慧医养服务,实现医养信息和医养资源的人联、智联、物联。
我们依托医院和政府积累的医疗数据、养老数据、产业数据,形成数据资源池,借助大数据系统对资源进行存储和计算,完成了一个处理能力强且易于扩展的数据计算平台的搭建。我们的数据计算平台能够对海量数据进行存储、清洗、加工、建模、分析等,并且充分利用资源池中的每一条数据,形成各个维度数据的聚合,为统计决策分析、算法分析服务、大数据预测等应用提供更充足的参考数据,从而实现对医疗数据更深层的价值挖掘。

目前,我们已经积累了 20TB 左右数据总量,前期使用 Hadoop 生态搭建数据计算平台,如下图所示。
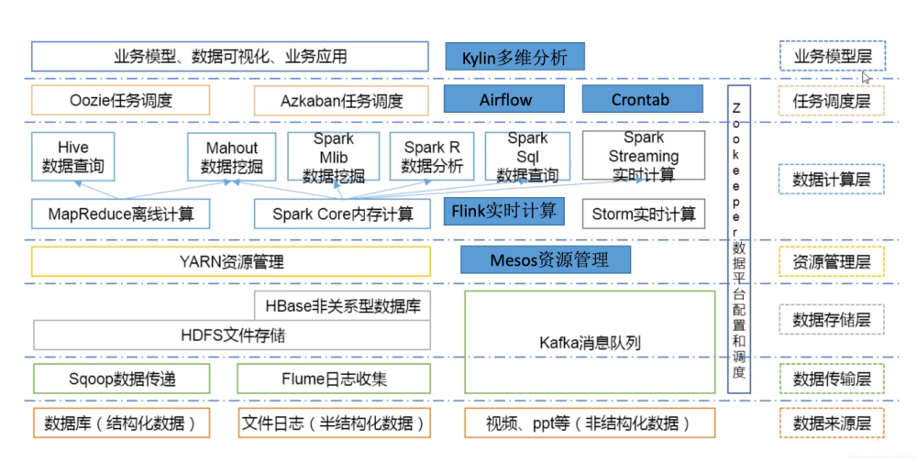
但是我们在使用和运维这套环境的过程中遇到很多问题,比如组件过多、搭建复杂、运维成本高。最关键的问题是,这套复杂的环境出现故障后难以排查,不能及时解决。
为了解决上述问题,我们开始对分布式数据库进行调研。其中,我们通过阅读 OceanBase 官方文档、浏览开源社区中的博客和问答区的内容,了解到 OceanBase 支持单集群部署上千个 OBServer 节点,单集群最大数据量早已达到 PB 级别,最大单表行数达万亿级。基于“同一份数据,同一个引擎”,同时支持在线实时交易及实时分析两种场景,“一份数据” 的多个副本可以存储成多种形态,用于不同工作负载。并且提供了自动迁移工具 OMS,支持迁移评估和反向同步以保障数据迁移安全。
考察到 OceanBase 的开源生态产品可以满足我们数据的规模和数据计算平台的需求后,我们进行了初步测试。我们首先注意到了 OceanBase 的 HTAP 能力,其次还提供了以下 5 项能力,这对我们而言非常重要。
-
易运维。每个 OBServer 节点内都包含了存储引擎和计算引擎,节点之间对等,组件数量少、部署简单、易于运维,不需要我们再为数据库补充其他组件来实现高可用及自动故障转移等功能。
-
高压缩。基于 LSM-Tree 数据组织形式,全量数据 = 增量数据 + 基线数据。因为数据首先会写入增量数据中的 Memtable 中,Memtable 是内存中的数据,所以写入性能相当于内存数据库的性能。基线数据是静态数据,只有在下次合并的时候才会有变化,可以采用比较激进的压缩算法,从而实现了至少 60% 的压缩率。我们从 Oracle RAC 集群把数据迁移到 OceanBase 之后,利用三备份存储模式磁盘占用率只用到原先的 1/3 左右。(*关于 OceanBase 数据压缩的核心技术可以阅读《历史库存储成本节约至少 50% ,OceanBase数据压缩核心技术解读》)
-
高兼容。目前 OceanBase 社区版本几乎完美兼容了 MySQL 的语法和功能,大部分统计分析任务基于 SQL 就可以达到目的, OceanBase 还支持我们经常用到的存储过程、触发器等高级功能。
-
高扩展。OceanBase 提供线性扩展的能力,在数据量增大之后,可通过增加服务器节点的数量实现性能的线性扩展,并且增加节点只需要我们的 DBA 执行一条命令。集群扩容之后,数据会在节点之间进行自动的负载均衡,DBA 同学不需要再亲自去搬迁数据了。
-
高可用。OceanBase 原生具备高可用的能力,通过 Paxos 协议实现分区级别的高可用,在少数派节点出现故障之后,依然能够提供服务,对业务无影响。

(一)架构变化
我们原来数据计算平台的架构是利用 10 台机器部署的一个 Hadoop 环境,其中使用了 20 多种不同的开源组件,这些组件分别负责数据导入导出、数据清洗和 AP 分析等功能。我们会先使用 ETL 工具把原始数据传到 HDFS 上,然后通过 Hive 的命令进行装载,最后再用 Spark SQL 做数据分析。
在这种架构下,数据需要来来回回地反复倒腾,而且和大量组件相关的版本适配、性能调优等工作,也需要非常专业的同学来做。最关键的是组件多、链路长,排查问题的环节太多,很多问题难以在短时间内定位具体是哪个组件出了问题。
最初,我们只是想使用 OceanBase 对数据进行整合和清洗:数据通过专线拉到前置机(Oracle RAC),再从前置机通过 ETL 工具 DataX 把数据拉到 OceanBase ,在 OceanBase 中进行数据的解密、清洗和整合,最后将清洗之后的数据从 OceanBase 拉到 Hadoop 环境进行 AP 分析(见下图)。
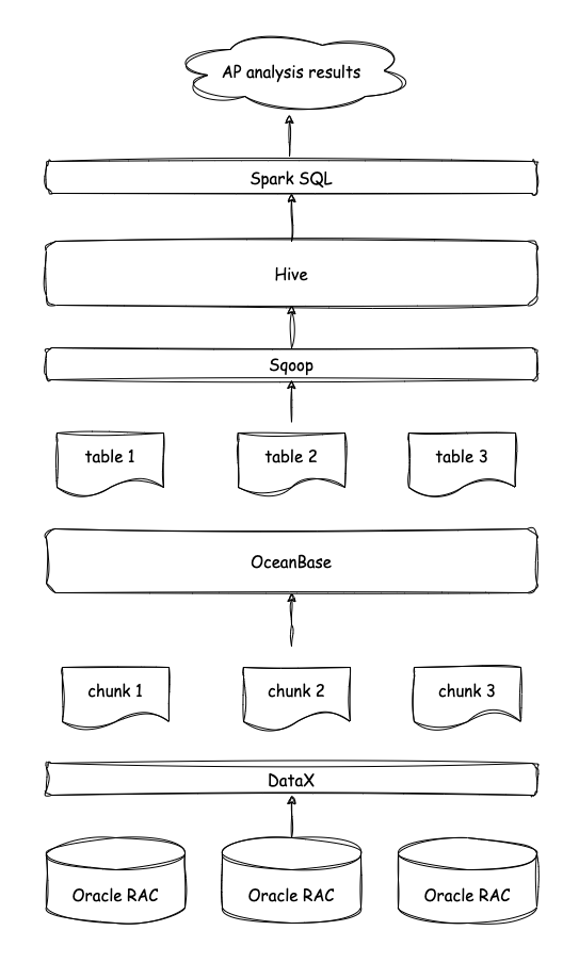
后来我们看到 OceanBase 官网提到了 HTAP 的能力,就尝试直接在 3 台 OceanBase 节点构成的集群中对数据进行 AP 分析,却意外发现即使在 OceanBase 中没有对数据进行分区,也没有使用并行执行,对 5 亿行的数据进行 AP 分析的时间都可以控制在一分钟以内。
原来是使用相同规格的 10 台机器部署的 Hadoop 环境,其 AP 分析性能居然已经被 3 台 OceanBase 超越。出乎我们意料的是,目前直接在 OceanBase 里写 SQL 就好,不需要再把数据装载到 hive 后再用 Spark SQL 进行分析,也不用依赖各种各样的开源组件,数据计算平台的链路就可以被简化成下图所示。
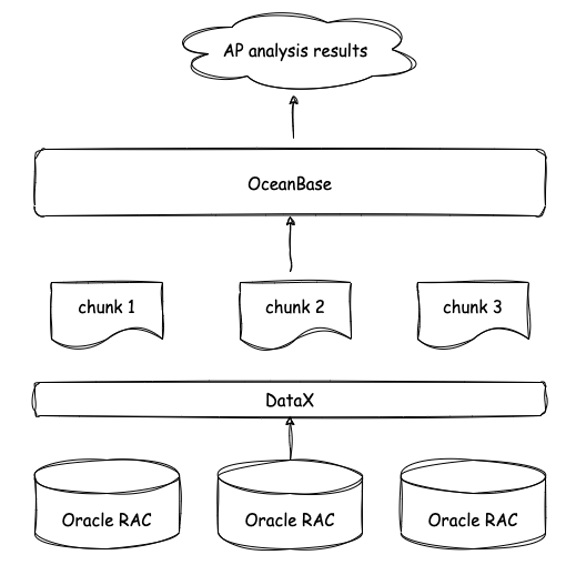
本来打算把数据导入 OceanBase 进行数据整合,然后再导入 Hadoop,然而,我们发现链路中 OceanBase 后面的整套 Hadoop 集群好像都没有用武之地了,再加上 OceanBase 是分布式数据库,可以水平扩展,所以这套 Hadoop 集群目前已经被弃用。
我们现在还没有花精力对 OceanBase 进行性能调优,后续将会在更多数据的环境中使用 OceanBase 对 100 亿数据进行 AP 分析,到时再研究下 OceanBase 的分区和并行执行这些功能。
最终,我们的数据计算平台架构调整为利用 4 台机器(1 台 OCP,3 台 OB)部署的一个 OceanBase 集群,基于 OceanBase 集群构建的计算平台的服务器配置如下。
| OCP | CentOS7 (64 位) | 64G | 20 vCPUs | 2T |
| observer 1 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
| observer 2 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
| observer 3 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
在通过 ETL 工具把数据导入OceanBase 之后,数据解密、数据清洗、聚合和 AP 分析等功能都在 OceanBase 内完成,而且 AP 分析方面还能获取一些性能提升。OceanBase 集群中除了单独部署的集群管理工具 OCP 外,就只有 OBServer 一种节点,节点和节点之间完全对等,极大地降低了运维管理难度。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

