
热门标签
热门文章
- 1python嵌套列表展示_创建学校演讲比赛复赛入围名单集合输入学生姓名查询该学生在不在入围名单中使
- 27-java连接oracle-Oracle中的事务处理_java取oracle序列需要事务吗
- 3【Flutter 实战】pubspec.yaml 配置文件详解
- 4python编译器安装第三方库,python编译器安装模块_python 编译模块
- 5git仓库迁移_git push --mirror
- 6安装faac-1.28报错 /bin/bash^M: bad interpreter: No such file or directory解决办法_输入bootstrap后no such
- 7oracle 19c CDB容器数据库监听和tns文件配置_oracle 19c listener.ora
- 8Java接入支付宝支付超级详细教程——从入门到精通_java接入支付宝自动扣费
- 9python:求素数_python求素数
- 10ERROR:node with name “rabbit“ already running on “XXX“_error: node with name "rabbit" already running on
当前位置: article > 正文
DataLoader的使用_dataloader 使用
作者:Gausst松鼠会 | 2024-05-04 10:12:02
赞
踩
dataloader 使用
介绍
打开pytorch官网,点击pytorch官网搜索dataloader
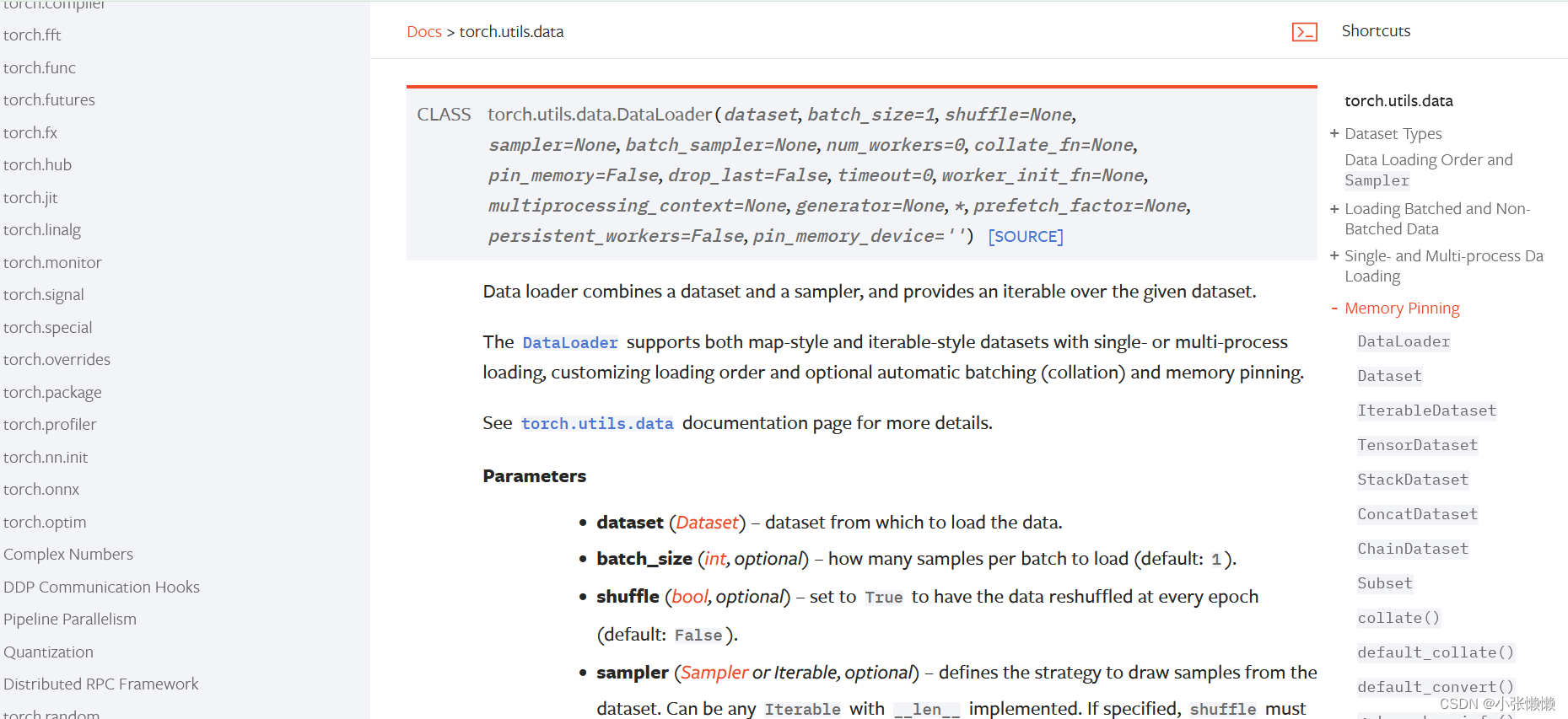
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='')
- 1
常见的参数介绍
- dataset (Dataset) – dataset from which to load the data.
- batch_size (int, optional) – how many samples per batch to load (default: 1).每次取几个
- shuffle (bool, optional) – set to True to have the data reshuffled at every epoch (default: False). 是否打乱,true为打乱
- num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0) 加载数据时是采用单进程还是多进程,在Windows系统下,若设置成大于0,可能会出现问题,解决方法:该参数设置为0
- drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False) 如果数据集中的sample数量除不尽,是否舍去,true为舍去,false为不舍去
使用
import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 准备测试集 test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor()) # 每次从test_data中取4个数据并打包 test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False) # 保存测试数据集中第一张图片及target img, target = test_data[0] print(img.shape) #图片为3通道,大小为32×32 print(target) writer = SummaryWriter("logs") step = 0 for data in test_loader: imgs, targets = data writer.add_images("test_data", imgs, step) step = step + 1 writer.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
打开tensorboard,可以看到dataloader把数据集64张图片为一组打包
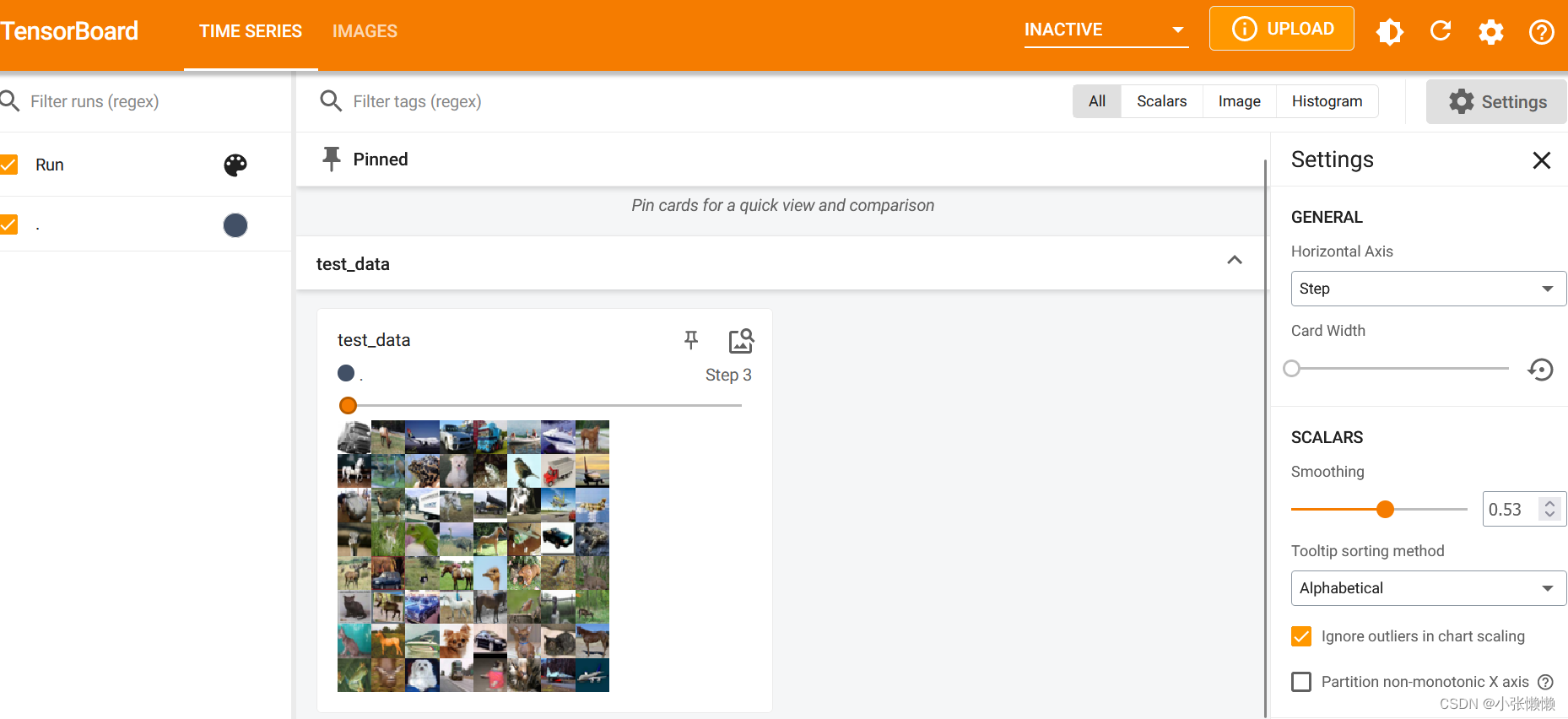
对于shuffle参数,设置为true后打包的数据每次都会打乱
使用for epoch in range(2):进行两次循环
import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 准备测试集 test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor()) # 每次从test_data中取4个数据并打包 test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False) # 保存测试数据集中第一张图片及target img, target = test_data[0] print(img.shape) #图片为3通道,大小为32×32 print(target) writer = SummaryWriter("logs") # 两次循环 for epoch in range(2): step = 0 for data in test_loader: imgs, targets = data writer.add_images("Epoch: {}".format(epoch), imgs, step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
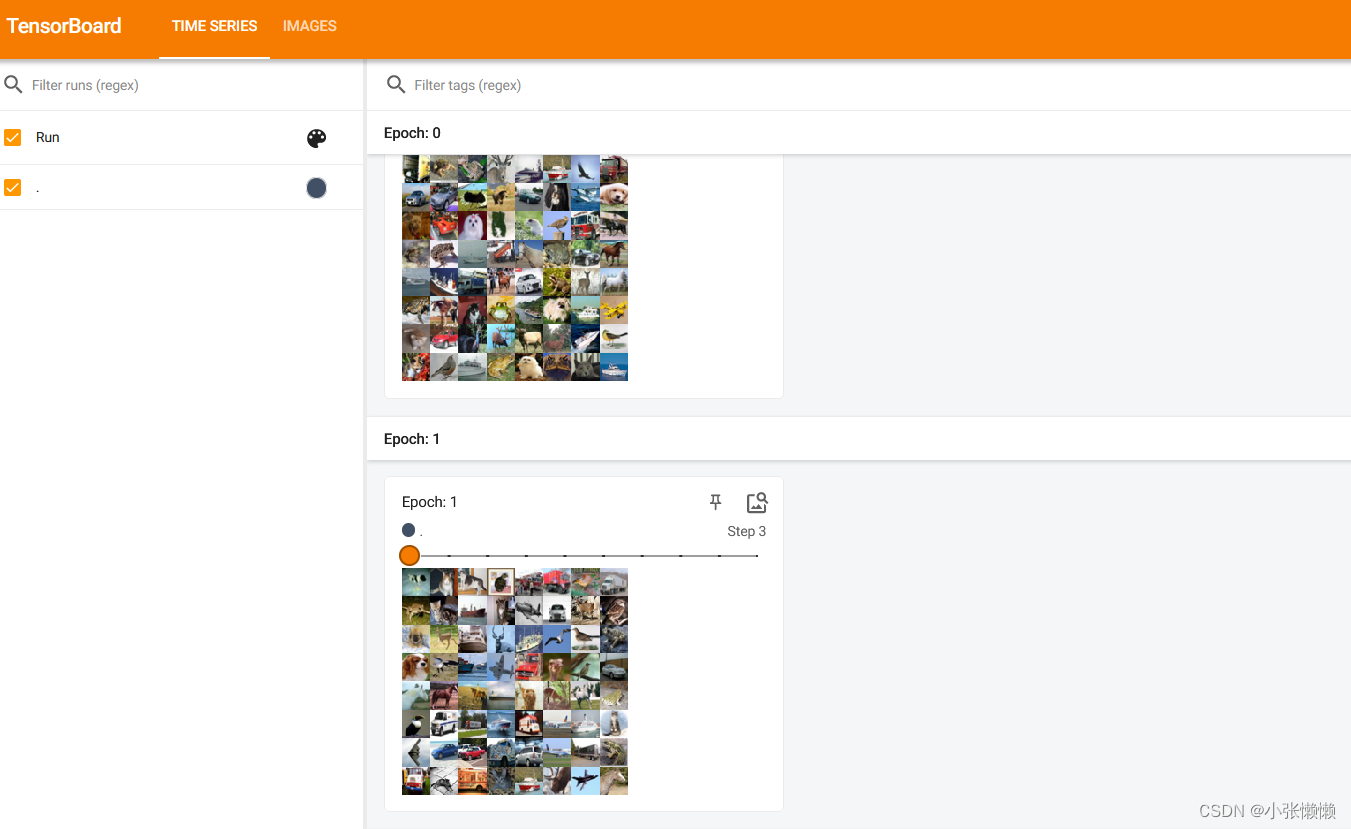
最后结果显示两次打包数据不一样
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/533983
推荐阅读
相关标签

