
热门标签
热门文章
- 1SyntaxError: Non-UTF-8 code starting with_scanning of 172.16.42.198:4433 was aborted (networ
- 2浅谈智能物联网家居平台安全隐患_智能家居行业网络安全(2)
- 3适合上班族做的副业,四个下班后可以操作的副业项目_下班后适合做的副业
- 4【1. MySql基础】_缓存,比如表、记录、权限等等
- 5第14章 用BERT实现中文语句分类_14.1 背景说明 本章用到预训练模型库transformers为自然语言理解(nlu)和自然语言
- 6最全最详细ChatGPT预设词Prompt教程_gpt模拟终端prompt
- 7读取CSV文件并将值存储到数组中_c++ 将csv转成数组
- 82021年第十二届蓝桥杯省赛C/C++B组题解 试题 E: 路径_小蓝的旅行计划 最短路经
- 9Leecode刷题总结
- 10【NLP】实体识别BERT-MRC论文阅读笔记
当前位置: article > 正文
伪分布式hadoop+spark+scala搭建
作者:Gausst松鼠会 | 2024-05-05 22:58:34
赞
踩
伪分布式hadoop+spark+scala搭建
一、伪分布式hadoop
详情请见:hadoop伪分布式安装-CSDN博客
二、spark
1.将spark安装包上传到linux虚拟机的/opt目录下
2.将spark安装包解压到/usr/local
![]()
3.进入解压后的spark安装目录的/conf目录下,复制spark-env.sh.template文件并重命名为spark-env.sh

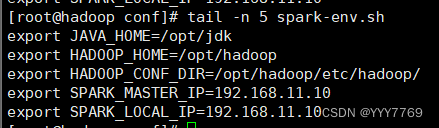
4.配置环境变量
![]()
5.启动spark集群
切换到spark安装目录的/sbin目录下

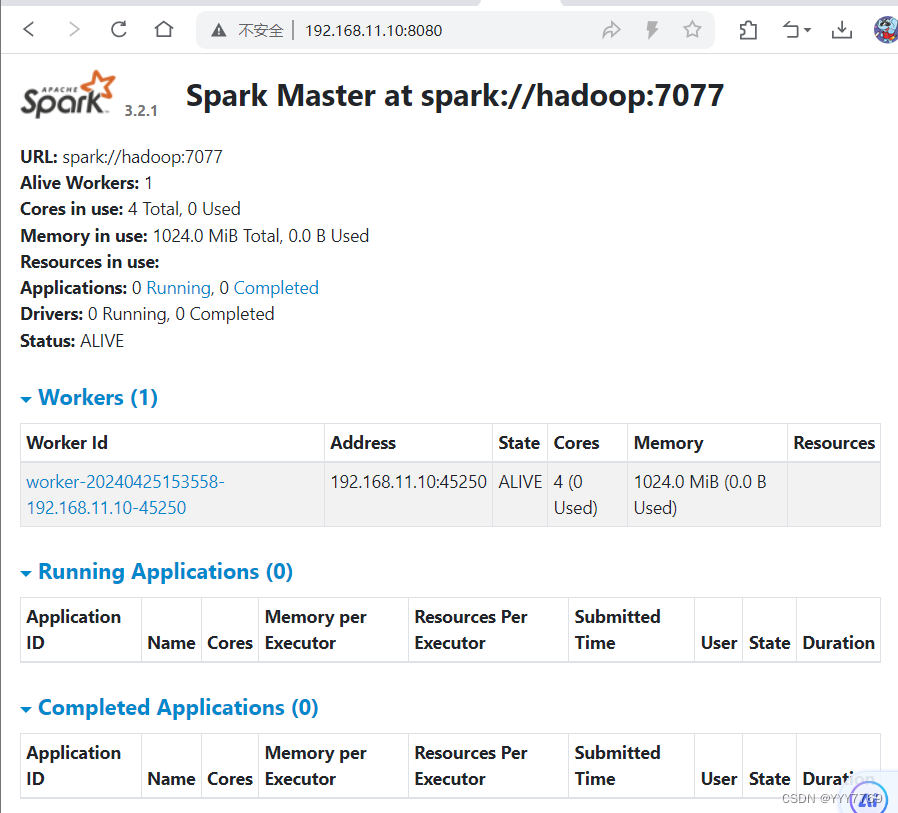
6.验证
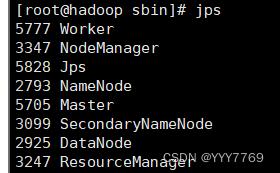
看见worker和master就说明spark集群启动成功
spark-shell

三、scala
1.将scala安装包上传到linux虚拟机的/opt目录下
2.将spark安装包解压到/usr/local
![]()
3.配置环境变量
使profile文件更新生效
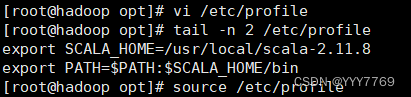
4.验证

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/541234
推荐阅读
相关标签

