- 1MATLAB机器学习、深度学习_matlab app 机器学习和深度学习
- 2Clickhouse 持久化 Kafka 数据_clickhouse kafka_format
- 3AI产业前瞻报告:探讨GPTs背后的产业逻辑:拉开AIGC应用生态的帷幕
- 4RabbitMQ学习(三)-- Spring boot 集成 RabbitTemplate_springboot rabbittemplate
- 5确实会画PCB会看原理图之后我再看嵌入式项目,整个系统得多_嵌入式需要画pcb和原理图吗
- 6Win10和Win11设置开机默认开启数字小键盘_initialkeyboardindicators
- 7【华为OD】给航天器一侧加装长方形和正方形的太阳能板_给航天器的一次加装
- 8【内网穿透】远程访问RabbitMQ服务
- 9阿里创新自动化测试工具平台--Doom
- 10Spring Bean Scope
JavaEE 多线程详细讲解(1)
赞
踩
1.线程是什么
(shift + F6)改类名
1.1.并发编程是什么
(1)当前的CPU,都是多核心CPU
(2)需要一些特定的编程技巧,把要完成的仍无,拆解成多个部分,并且分别让他们在不同的cpu上运行。
要不然就会编程,一核有难,多核围观的场景
并发编程指的是(并行+并发)
(3)通过多进程编程的模式就可以达到并发编程的效果。
因为进程可以被调度到不同的cpu上面运行
此时就可以把多个cpu核心核心都很好的利用起来
(4)虽然多进程编程可以解决上述问题,但是带来了新的问题。
1.2.问题?
(1)在编程过程中,服务器开发的圈子李,这种并发编程要能够给多个客户端提供服务。
如果同一时间来了很多客户端,服务器如果只利用一个cpu核心工作,速度会比较慢
(2)多搞几个厨师,来炒菜,这样就大幅的提高了效率
(3)一个比较好的做法就是每个客户端连上服务器,服务器都创建一个新的进程,给客户端提供服务,这个客户端断开了,服务器再把进程示范掉
如果服务器,频繁有客户端来来去去,服务器就需要频繁创建销毁进程。(服务器响应速度会变慢)
1.3.如何解决这个问题?线程的引出
引入线程,主要的出现,就是为了解决上述进程,太重量的问题
(1)线程(thread)也叫做轻量级进程(创建销毁的开销更小)。
(2)线程可以理解为进程的一部分,一个进程中可以包含一个线程或者多个线程
(3)描述进程使用的是PCB这样的结构体,事实上更严格的说,一个PCB其实是描述一个进程的,若干个PCB联合在一起,是描述一个进程的。
(4)pcb中包括(pid 内存指针 文件描述表 状态上下文,优先级,记账信息 tgid)每一个线程所提供的pid是不一样的但是tgit是一样的,所以我们可以用tgit来判断这个线程是不是在一个线程下面
(5)还要同一个进程的若干个线程,这里的内存指针和文件描述表,其实是同一个。
(6)状态上下文优先级记账信息每个线程有一组自己的属性
(7)同一个进程中的若干个线程之间,是相同的内存资源和文件资源的。
线程之间可以互相访问
进程是系统资源分配的基本单位
线程是系统调度执行的基本单位
同一个进程包括N个线程,线程之间是共用资源
只有你创建第一个线程的时候,去进行资源的申请操作,后序再创建线程,都没有申请资源的过程了。
1.3.1并发编程
(1)在我们引入了进程以后,那么我们就可以思考,进程的作用是什么?
(2)图解举例

(3)我们现在的计算机不都是好多核心,所以我们可以用多个线程来对工作进行拆分
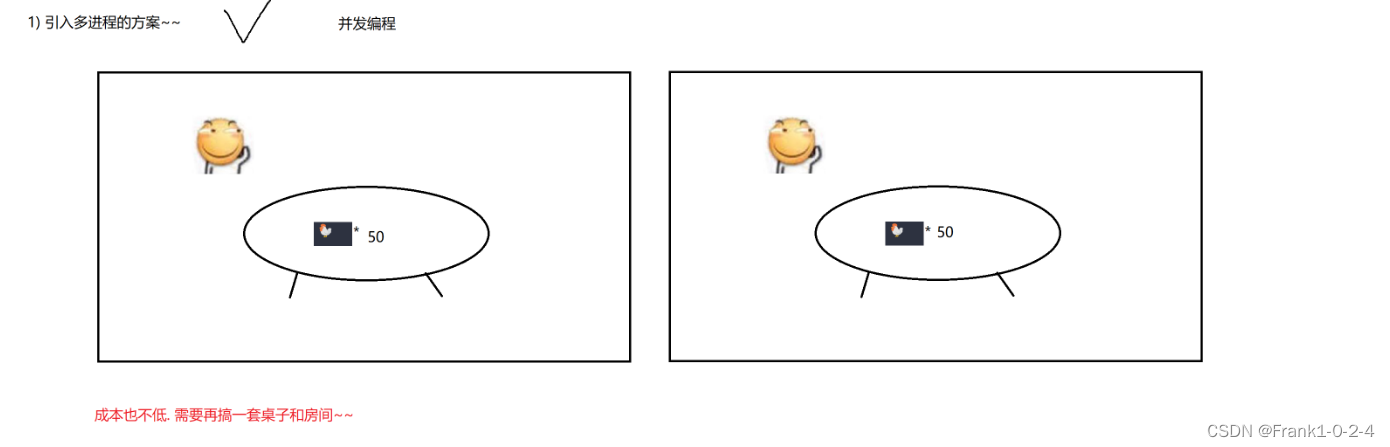
(4)由于成本很高,而且电脑的核心也并不是特别的多,所以我们引出了多线程编程。
相当于线程为进程分担了问题
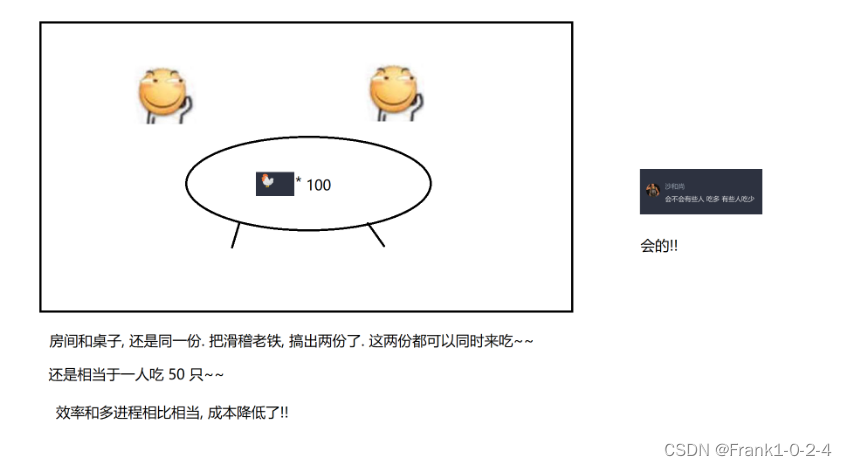
(5)这时候就有同学提出问题,是不是线程越多越好,这当然不是,因为线程的调度也是需要分配资源的,合适的线程可以帮助你来更好的管理资源,但是如果线程过多的化那么线程就会变慢。
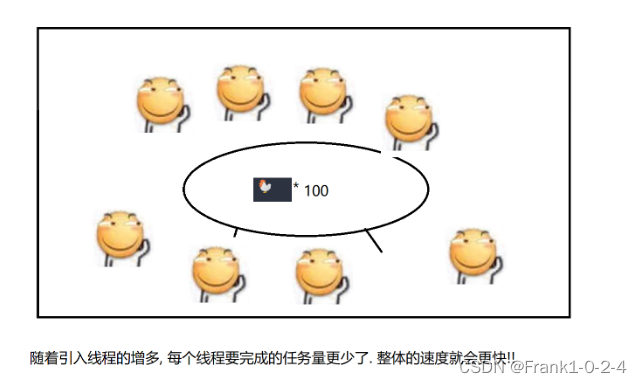
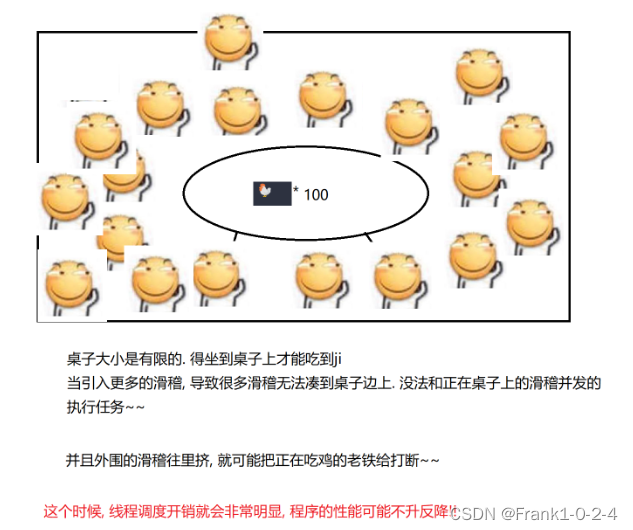
(6)其中我们还要思考一个问题就是线程的调度资源到底花费到哪里

(7)其中多核CPU才能进行这种操作

(8)其中,在线程不是太多的情况下,也可能发生线程安全的问题。
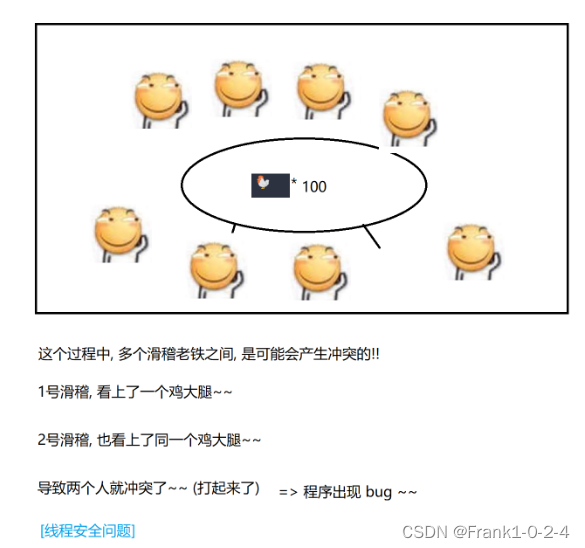

1.4总结
总结:为啥说线程更加轻量,开销更小,核心就在于,创建进程可能包含多个线程,这个过程中,涉及到资源分配,资源释放。
1.5线程于进程的关系以及相关问题
1.6关键面试题(线程和进程的区
别)
2.代码实现线程和进程、
线程本身是操作系统提供的。
操作系统提供了API让我们操作系统
JVM就对操作系统的api进行封装
线程这里提供了thread类实现了封装
2.1线程的代码实现
其中,操作系统提供了api来对线程进行操作,然而我们的编译器,使用了JVM(java虚拟机)来进行操作,操作系统的api,其中,在java中我们使用的就是Thread类来对线程进行操作



2.1.1Thread 代码的基本实现
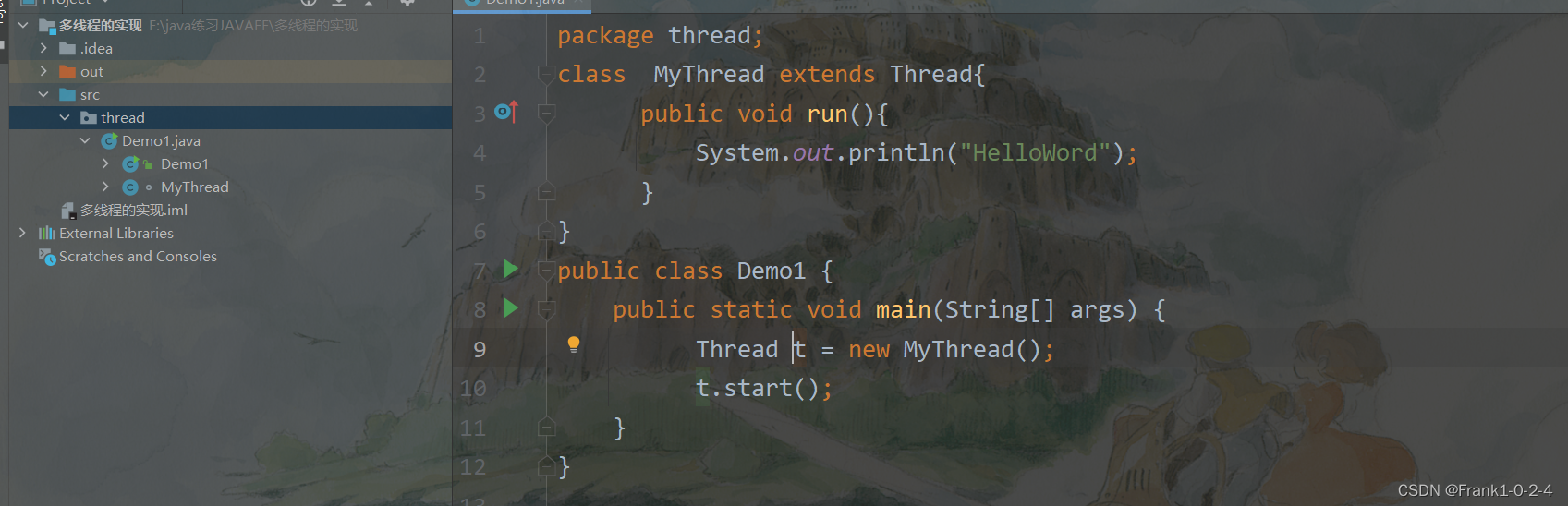
其中,run方法是Thread中本来就有的方法 ,我们把他重写了
进入源代码

可以看到我们重写了run方法。
2.1.1.1注意事项
(1)上面的这段代码其实是创建了两个线程,分别是main线程,另一个就是t线程
(2)其中main是主线程,也就是jvm在运行的时候就会创建出来。
(3)其中一个线程中至少包含一个进程,然后再进程中,至少包含一个线程,在没有引入多并发编程之前,我们运行的程序都是一个进程,然后我们在一个线程下面编写代码。
(4)在上面的程序中就是,一个进程,然后进程的下面有两个线程,分别是t线程,然后是jvm生成的主线程mian
2.1.2线程的状况(线程一直进行来进行分析)
其中try catch来对其进行捕获,是因为防止在其他线程或者什么东东调用正在休眠的线程,这时候就会一直等下去,也就是阻塞,所以我们要用trycatch来进行处理
- try {
- // 尝试执行这里的代码,可能会抛出异常
- } catch (ExceptionType1 e) {
- // 如果try块中的代码抛出了ExceptionType1类型的异常,则执行这里的代码
- } catch (ExceptionType2 e) {
- // 如果try块中的代码抛出了ExceptionType2类型的异常,则执行这里的代码
- } finally {
- // 无论是否发生异常,finally块中的代码总是会被执行
- }
代码整体实现
- package thread;
- class MyThread extends Thread{
- public void run(){
- while(true){
- System.out.println("HelloThread1");
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- public class Demo1 {
- public static void main(String[] args) {
- Thread t = new MyThread();
- t.start();
-
- while(true){
- System.out.println("HelloThread1");
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }

其中main和t线程是并发执行的

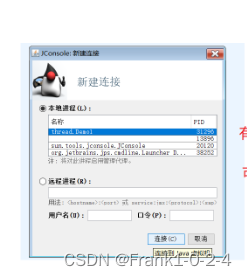
其中我们要注意的一点就是sleep后面的休眠时间的单位是ms,其中sleep的作用就是将这个停一下在方到系统上面的CPU上面进行执行
时间到了以后就会解除阻塞状态也就是。
它可以让我们的CPU的调度有休息可以更好的处理资源的调度
2.1.3线程的使用情况(2.1.2中的代码)
在运行的时候我们可以看到每秒钟打印一次
其中main可能t线程的前面
t线程也可能在main线程的后面
也就是谁抢上资源谁就进行输出
2.1.4其他一些关系线程的东西就一起来说明了
(1)
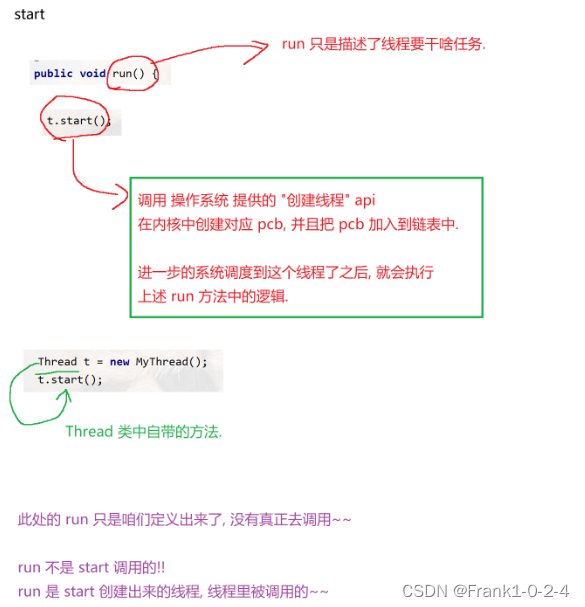
总的来说就是,我们定义了一个线程的基本框架(MyThread类),其中在main方法中的Thread t = new MyThread只是实例化这个对象而已,也没有创建线程,这时候的start是Thread中里面的方法,只有在调用这个方法的时候,才会使用我们实例化的线程框架,来创建线程
通俗点说就是

(2)其中要注意的是
 所以刚才写的代码就是线程的串行执行
所以刚才写的代码就是线程的串行执行
2.2Thread的五种写法
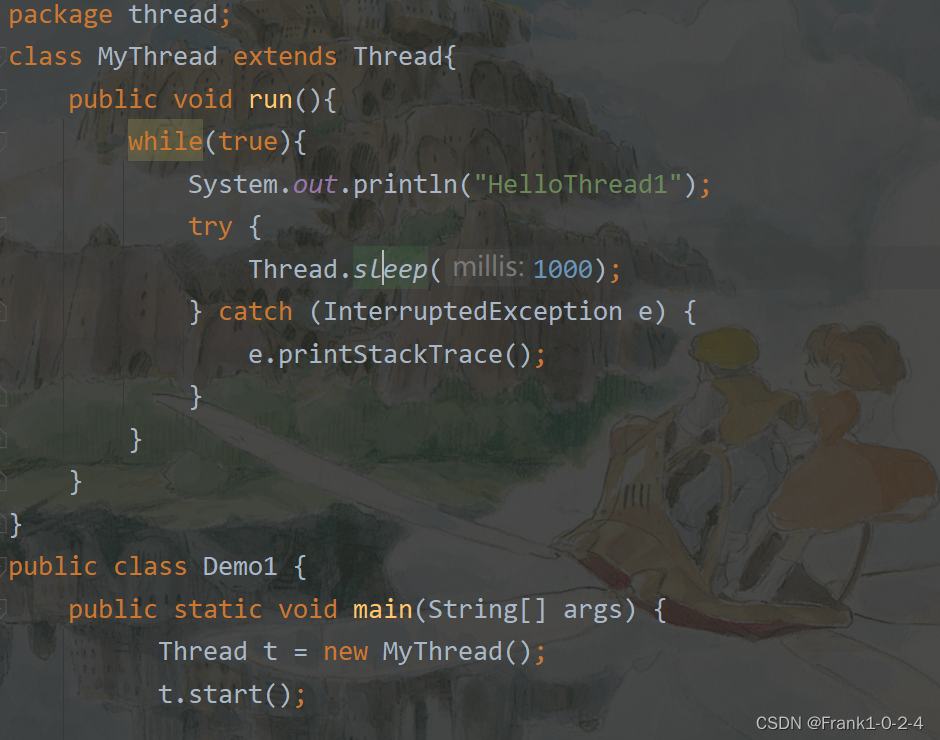
2.2.1第一种创建一个类继承Thread方法
这个是我们一开始说的那个方法
2.2.2第二种创建一个类描述线程,实现Thread的方法
这个方法实现线程的方式是比较好的方式
它能大大的降低耦合度
我们不同于第一种创建,我们是实例化Thread然后把MyRunnable作为参数传入实例化的对象中作为参数

两种Thread的对比(1)和(2)种方法

2.2.3第三种创建 使用匿名内部类创建线程框架(继承Thread类)
代码实现
这个定义了一个匿名内部类来对,这个匿名内部类直接继承Thread类然后重写Thread的中的run方法,然后最后t.star就可以了
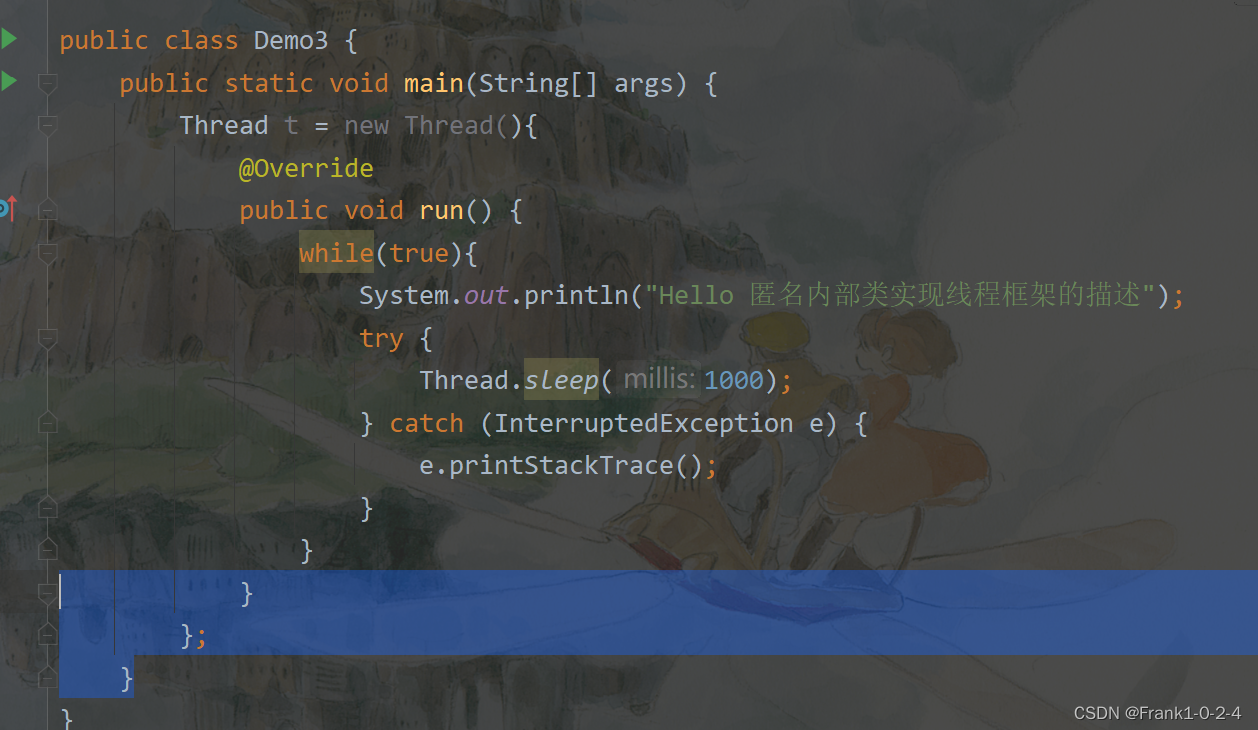
总结

2.2.4第四种创建方式lambod表达式创建(JDK8的新属性)
这个方式可以理解为用函数式接口的方法
在Thread类中式没有抽象方法的,但是在Thread中实现了Runnable接口,里面有一个run抽象方法,lambod表达式就会重写这个方法来做出线程的框架
相较于Thread的内部类来实现来说 lambad表达式只能用函数式接口来重写run,但是比内部类实现来说方便许多,匿名内部类实现的化比它麻烦一点,但是它的扩展性比lamda表达式要好很多
注意的一点就是主线程一直在其他线程完成以后再执行的
代码实现

2.2.5第五种方法是实现Runnable重写run使用内部类

总结


2.3线程的几种其他用法
2.3.1给线程定义名字
(1)在线程的结尾来定义名字
代码示例
- package thread;
-
- public class Demo6{
- public static void main(String[] args) {
- Thread t = new Thread(()->{
- while (true){
- System.out.println("make name from Thread");
- try {
- Thread.sleep(10000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- },"Frank");
- t.start();
- }
- }
2.4Catch中写的是什么?Sleep的注意事项
(1)
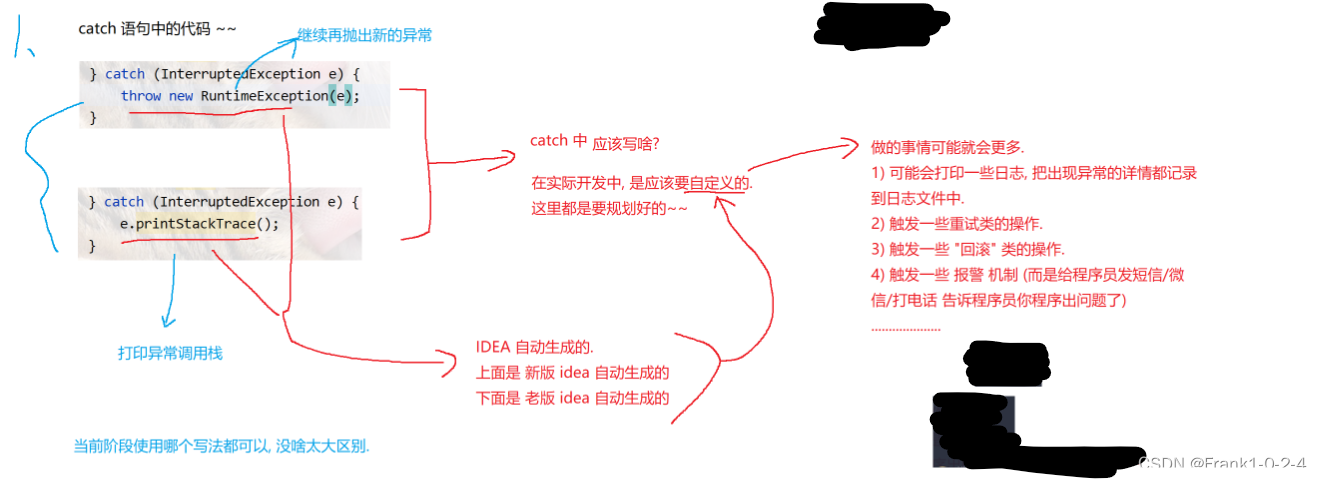
(2)
其中我们要注意的就是在main方法中我们有两种方法来处理sleep
分别时 :try catch 和Throws
用try catch 可以捕获异常然后程序员选则如何处理这个异常
用Throws是捕获的异常必须要优先处理
2.5小结
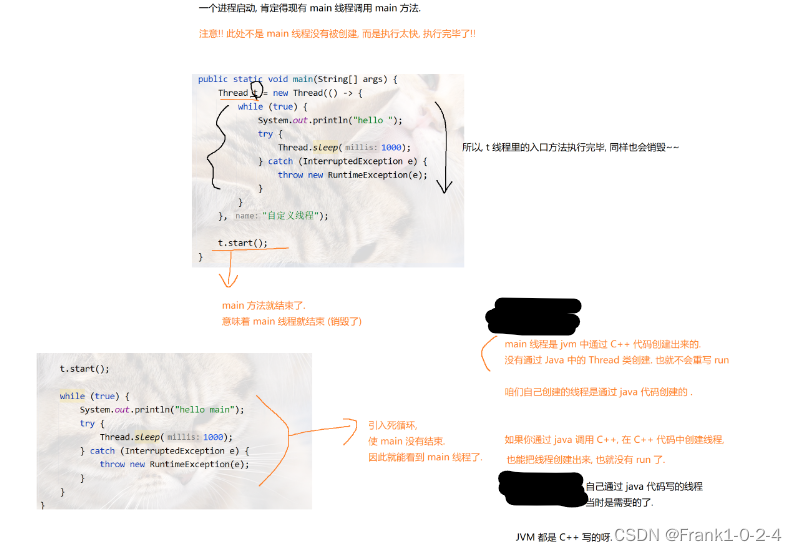
3线程的区别
线程分为分为前台线程和后台线程
前台线程就是这个线程不结束java程序
后台线程就是这前台线程结束那么他就结束了
4将进程设置为后台进程
代码实现
- public class DaemonThreadExample {
- public static void main(String[] args) {
- // 创建一个线程
- Thread daemonThread = new Thread(new Runnable() {
- @Override
- public void run() {
- while (true) {
- try {
- System.out.println("Daemon Thread is running...");
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- });
-
- // 将线程设置为后台线程
- daemonThread.setDaemon(true);
-
- // 启动线程
- daemonThread.start();
-
- // 主线程执行完毕,由于daemonThread是后台线程,程序不会等待它执行完毕就会退出
- System.out.println("Main thread is exiting...");
- }
- }

5.其他知识的扩充
(1)

6.如何让线程中断
我们可以定义一个布尔值的变量其中,我们可以用布尔值来控制循环的开始和结束。
代码实现
其中要注意的是外部类成员是不会报错
![]()

(2)线程的中断

总结一下,`t`线程在`sleep`状态时,就像你的朋友决定去睡觉并且不想被打扰一样,它是不会响应中断请求的。如果你想让它在需要的时候提前醒来,你需要在编写代码时,让它能够检查并响应中断请求。
6.1线程如何更好的中断


代码解析
首先,我们要明白什么是线程中断。在Java中,线程中断是一种协作机制,允许一个线程请求另一个线程停止它正在做的事情。这通常是因为某种原因,比如用户取消了操作,或者系统需要释放资源。
Thread.currentThread().isInterrupted()
这个方法用来检查当前线程是否已经被其他线程中断。中断状态是一个标志,当一个线程调用另一个线程的
interrupt()
方法时,它会设置这个标志。
while (!Thread.currentThread().isInterrupted())
这个循环的意思是:“只要当前线程还没有被中断,就继续执行循环里的代码。” 如果线程在循环内部被中断(比如其他线程调用了它的
interrupt()
方法),那么
isInterrupted()
方法会返回
true
,循环条件变为
false
,循环就会停止。
现在,让我们看一个简单的例子:
假设你正在煮一壶水,并且你想在水开之前不断检查它。你可以把煮水的过程想象成一个线程的任务。如果突然有急事要离开,你可能会想中断这个线程(也就是停止检查水是否开了)。
在这个例子中,
while (!Thread.currentThread().isInterrupted())
就像是你在不断地问自己:“我是不是应该停止检查水是否开了?” 只要你没有被中断(也就是没有急事发生),你就会继续检查。一旦你收到中断信号(比如有人叫你),你就会停止检查并去处理其他事情。
Thread.interrupt()
方法就像是有人按下了停止按钮,告诉线程:“你应该停止你正在做的事情了。” 而
isInterrupted()
方法就像是线程在回答:“好的,我已经收到停止的信号了。”
这时候当我们进行运行的时候会发现虽然我们返回了true想要中断,但是却没有中断,这是因为sleep会将false再修改回true,这是为了能够让程序员更好的控制线程而不是让程序自己控制线程,我们可以再catch中选择他是继续往下进行还是结束
图解
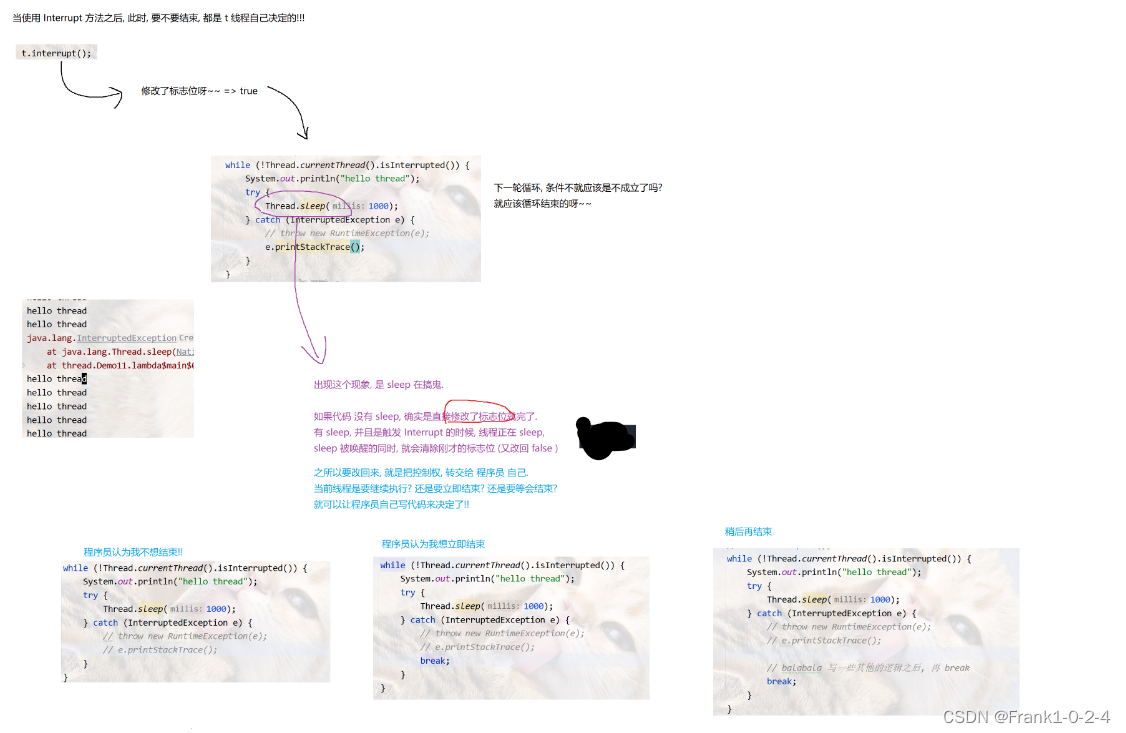
7线程的其他方法
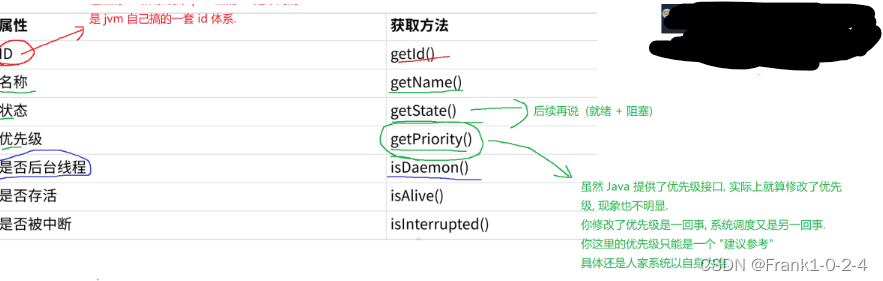
详细图解
其要注意的就是前台线程结束后台线程不管如何都会结束,而后台线程结束那么前台线程是不会结束的。

注意事项

3.Thread中的join方法(线程的阻塞)
3.1join方法的本质
(1)
图解

(2)join方法的本质是指的是使用了这个方法的线程就会阻塞
图解

所以main线程永远是最后进行执行的。
其中要注意的就是如果没有设置sleep就是哪个线程先用join那么哪个线程就先执行,还有就是只有start了以后才能join,如果休眠时间一样也按这种方式处理,如果休眠时间不一样,那么休眠间短的线程先执行然后再是休眠时间最长的,最后再是main线程。
3.2代码示例
- public class JoinExample {
- public static void main(String[] args) {
- Thread thread1 = new Thread(() -> {
- System.out.println("Thread 1 starting...");
- try {
- Thread.sleep(1000); // 模拟耗时操作
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("Thread 1 ending...");
- });
-
- Thread thread2 = new Thread(() -> {
- System.out.println("Thread 2 starting...");
- try {
- Thread.sleep(1500); // 模拟耗时操作,比线程1稍微长一些
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("Thread 2 ending...");
- });
-
- thread1.start(); // 启动线程1
- thread2.start(); // 启动线程2
-
- try {
- thread1.join(); // 等待线程1完成
- thread2.join(); // 等待线程2完成
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
-
- System.out.println("Main thread continuing..."); // 当两个子线程都完成后,主线程继续执行
- }
- }
3.3join最大等待时间
1. 概念 join方法可以理解为谁调用这个方法谁就会被阻塞然后等待这个线程运行结束以后然后恢复执行。
2.这个就相当于join等待不能一直等待,我们可以规定一个时间来限制他。
图示(深度解析)

3.4sleep 和join 方法的区别
(1)sleep在java的库中是native方法也就是本地方法,它的底层我们是看不到的
(2)通俗点来讲,sleep是控制这个线程的休眠时间而不是两个代码的执行的间隔时间。
(3)sleep是根据时间戳来对其进行休眠时间的判定
(3)system.currentTimeMillis()这个代码可以获得我们系统的时间戳
注意事项

(4)对于join方法来说,这个就是真正的阻塞,只有前面没有调用这个方法的线程执行结束,这个阻塞才会恢复然后执行这个调用这个join方法的线程
4.引出线程安全问题(为下一篇文章做基础)
4.1引言
(1)我们之前提到过线程的状态,其中我们也可以叫它为PCB状态,其中linux 和windos系统,linux系统有非常成熟的系统来操控PCB,当然windos系统中也会有选项来对其进行操作,只不过性能方面没有比linux更好罢了。
(2)其中在我们java的jdk中的jvm虚拟机中,nb的大佬程序员都为我们封装好了这些东西来对其进行操作,相较于C++来说,java方便太多,C++语言的特征是性能高稳定但是编写难度较高。
4.2 六种PCB状态梳理
(1)NEW状态
这个状态就是Thread线程的对象已经有了,没有进行start,系统内部的线程还没有创建。
(2).Terminated状态
这个状态是Thread线程的对象有了,也执行完毕,然后被销毁,最后还剩下一个Thread对象。
(3)Runnable状态(就绪状态)
这个指的是,这个线程已经调度到了系统的CPU上面,其中有两种情况。
第一种就是:这个线程已经在CPU上面,但是还没有执行
第二种就是:这个线程已经在CPU上面进行执行了
!!!!!!我看了很多资料讲解的都不是很好,他们将这两种状态分开了,叫出了两种名称,我认为其实没啥用,因为都已经到CPU上面了,已经不是人能决定的了,而是全部由系统决定,你就算再nb你能对系统进行操作吗??所以这两种状态我都称之为就绪状态。
5.阻塞的三种状态讲解
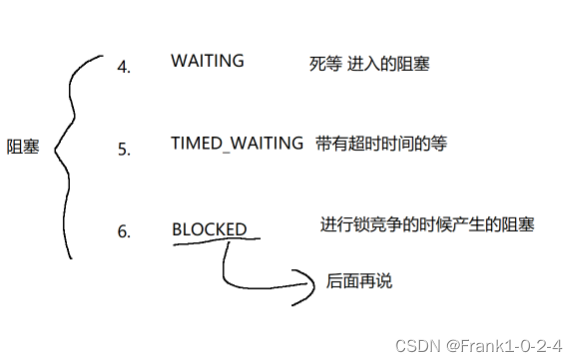
最后一个状态我们在下一篇文章中进行讲解
打开idea的文件夹找到查看线程状态的软件,来对阻塞进行讲解
可以看到,join是死等,join带有最大阻塞时间和sleep休眠是TIMD-WAITING是带有时间的阻塞。
这个的作用就是在你以后工作的时候来判断你的各个线程的状态来更好的开发项目

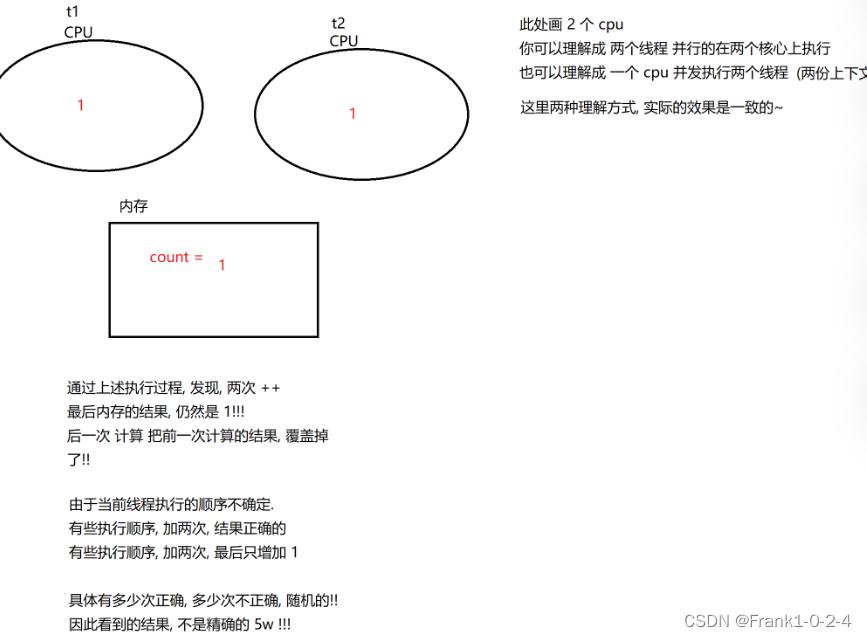
(1)线程不安全示例

相当于它会重复的对数据进行读取这是非常不好的。
我们可以进行串行执行

这样就好了
所以死锁问题就是这样产生的。
(1)为什么,发生这种问题的简单原因。

(2)其中在上面的加到5000的情况下面还有一个情况就是两个加在一起小于5w的情况。
在多线程环境中,每个线程都有自己的 CPU 缓存和工作内存。当一个线程修改了变量的值时,这个变化不会立即反映到主内存中,而是在适当的时机才会同步到主内存中。其他线程在读取这个变量的值时,可能会直接从自己的 CPU 缓存或者工作内存中读取,而不是从主内存中读取,这就导致了可能读取到旧值的情况发生。