
- 1【计算机毕业选题】400个计算机专业毕业设计选题推荐_计算机毕设选题推荐
- 2PDFBox操作PDF文档之创建PDF文档、加载PDF文档、添加空白页面、删除页面、获取总页数、添加文本内容、PDFBox坐标系-支持Android
- 3深入理解Java消息中间件-云原生和容器化对消息中间件的影响
- 4RabbitMQ(3.8.5) 局域网访问失败_rabbitmq 局域网访问不了
- 5注意力机制(二):Focus Your Attention: A Bidirectional Focal Attention Network for Image-Text Matching_focus your attention (with adaptive iir filters)
- 6使用docker-compose 安装gitlab报错 sudo gitlab-ctl reconfigure_ulimit: pending signals: cannot modify limit: oper
- 7绩效管理的本质是激发员工,而不是扣工资!
- 8a论文写作免费网站推荐!ai论文写作免费网站有哪些
- 9运行EVO问题汇总:AttributeError: module ‘numpy‘ has no attribute ‘typeDict‘_attributeerror: module 'numpy' has no attribute 't
- 10【MongoDB远程连接配置】_单机版mongo url配置问价
Elasticsearch:RBAC 和 RAG - 最好的朋友
赞
踩
作者:来自 Elastic Jeff Vestal
检索增强生成 (RAG) 通过提供额外的上下文或信息来增强大型语言模型 (LLM) 的知识,从而提高响应质量。 尽管 LLMs 拥有令人印象深刻的能力,但也有其局限性,例如无法在培训后保留新信息以及对不熟悉的主题产生错误答案的倾向。 为了克服这些限制,专有的、相关的和更新的数据可以与提示相结合,从而为 LLM 奠定基础,并导致更准确和用户友好的响应。
有关 RAG 的详细信息,请查看我们关于 RAG 的搜索实验室博客。
RBAC - Role-Based Access Control,基于角色的访问控制。
数据保护
保护私人信息应该是任何公司的首要任务。 泄露敏感信息造成的损害可能会带来经济处罚、声誉受损、竞争优势丧失,甚至在个人信息泄露时对个人造成伤害。 由于这些和许多其他原因,有必要考虑你要向 LLM 发送哪些数据。
如今,用户在将 LLM 集成到应用程序中时有多种选择。 最简单的方法是使用公共 LLM 提供商。 虽然这通过简单地连接到 API 消除了所有管理问题,但用户必须注意如何使用他们发送给这些提供商之一的数据。 LLM 不会立即保留信息,但这并不意味着发送到该服务的所有提示都不能被记录并用于未来的培训交互。 通过这些公共服务,用户应该只发送他们不在意的可用于未来训练迭代的信息,从而使这些知识可供任何其他用户使用。
一些服务提供商业计划,其中可能附带法律合同,禁止 LLM 提供商保留和训练发送到其服务的数据。 超大规模企业提供了将这些生成式 LLM 之一部署到客户租户的选项,并承诺隔离客户数据。 这些选项为数据隐私提供了比公共服务更全面的保护。 尽管如此,用户和公司必须相信 LLM 提供商将遵守他们的承诺。
如今,与 LLM 集成的最安全的方式是公司自行运营 LLM。 这应该确保不会保留任何提示信息,并且不会在他们不知情的情况下向外部发送数据。 这种额外的保护伴随着更高的复杂性和管理责任。 公司必须知道如何部署和扩展 LLM。 他们必须能够监控它是否在要求的响应时间内继续响应。 自己运行模型并不意味着它会更具成本效益,但它确实将控制权移回到操作员手中。
无论部署类型如何,通过增强 LLM 的知识来奠定模型仍然同样重要。
内部 vs. 公开数据
如前所述,每家公司都有不公开的信息。 如果最终应用程序供内部员工使用,则非公开数据应保持非公开状态。 如果最终用户是外部的,则在决定内部信息是否可以与外部共享时必须小心。 公共数据已经公开,因此将其发送给 LLM 不会带来额外的风险。
个人身份信息 - PII
个人身份数据 (personal identifiable data - PII) 是当公司失去控制权时就会成为新闻的数据类型。 这通常是个人独有的信息。 虽然所有 PII 都应受到保护,但有些 PII 比其他 PII 更为重要。 使用名字通常不是问题。 但是,将名字、姓氏和社会安全号码发送给公共 LLM 并不是一个好主意。
客户特定数据
与 PII 类似,它对于客户来说是唯一的,但这些数据通常不太敏感。 示例包括过去的订单信息、旅行类型偏好和应用程序设置。
保护这些和其他数据类型是基于角色的访问控制的用武之地。
没有 RBAC 的 RAG
让我们首先看看只有一个用户访问级别的 RAG 应用程序如何工作。 如果你要创建一个将在公共网站上运行并回答文档问题的聊天机器人,它可能只会连接到一个数据集:你的文档。 在此设置中让每个用户处于相同的访问级别就可以了。 每个人都可以访问文档,任何人都可以看到答案。
但是,如果你正在创建一个可以访问人力资源数据的内部聊天机器人,让员工可以提问,该怎么办? 一些人力资源数据应该向所有人开放,但有些数据仍仅限于特定角色,例如经理或人力资源员工。
下面,一位用户问道:“What is our work from home policy? - 我们在家工作的政策是什么?”

这是任何员工都应该有权访问的一般问题,因此只要他们有权访问该应用程序,他们就可以提出问题并获得答案。 请注意,我们可以通过要求用户登录来实现 RBAC,但为了简单起见,我们假设他们只能在工作网络内访问此聊天机器人。
现在,我们假设只有经理才有权访问有关员工薪酬的信息。 当非经理或工程师询问有关未实施 RBAC 的薪酬问题时会发生什么?

聊天机器人返回了看起来有用的答案; 但是,请记住,只有经理才能访问此详细信息!
Elastic RBAC 特性
在我们研究启用 RBAC 的补偿问题的答案之前,我们先简要讨论一下 Elasticsearch 的 RBAC 功能。
- 集群级别 - cluster level
- 最通用的访问级别是集群级别。 用户或帐户可以登录集群吗?
- 索引级别 - index level
- 一旦可以登录,该帐户是否可以读取访问中的数据,是否可以写入、修改和删除索引?
- 文档级别 - document level
- 当用户可以查询索引时,他们可以检索索引中的所有文档,还是只能读取与一组特定元数据匹配的文档?
- 在我们的博客中阅读更多详细信息 - Elasticsearch 中基于文档级属性的访问控制
- 字段级
- 当文档作为查询的一部分返回时,帐户可以查看所有字段还是仅选择字段?
- 属性
- 使用属性来限制对搜索查询和聚合中文档的访问。

有关演示 RBAC 如何影响允许不同组的用户查询的索引和文档的简单示例,请查看此处搜索实验室存储库中的示例 Jypyter notebook。
Elasticsearch 可以与 Active Directory、LDAP、SAML 等更多外部身份验证系统集成。 与这些提供商集成时,外部组将映射到内部 Elasticsearch 角色。 与在应用程序级别管理数据访问相比,这具有多个优势。 首先,外部角色和内部角色之间的映射只需要配置一次。 仅当创建新索引模式或需要修改组访问类型时才需要更新。 其次,通过在 Elasticsearch 中管理组级别的访问,只有用户加入或离开组时才需要更新其成员资格。 他们的访问权限会自动调整以反映他们当前的组从属关系。
第二点尤其重要。 当访问角色发生变化时,权限需要实时传播到所有系统。 RBAC 确保此更改生效,而不必更改多个程序中的访问权限。
要详细了解 RBAC 如何融入 Excellent 搜索中心,请查看此处的 Excellent 博客。
我们的文档更详细地介绍了每个访问级别。
RAG 与 RBAC
现在我们了解了 Elasticsearch 可以采用的各种访问级别,让我们回到 RAG 示例。 在最后一个示例中,我们的 Slackbot 向我们的工程师提出了一个有用的薪酬问题。 但是,由于此信息应仅限于经理,因此不应提供该详细信息!
我们可以通过多种方式配置对此数据的限制,但我们将保持 RBAC 示例简单,为 HR 数据集设置两个访问级别,并将数据拆分为两个索引。 一种索引是 hrdata-general,一种是 hrdata-restricted。 每个员工都可以访问 hrdata-general,只有经理才能访问 hrdata-restricted。 用户可以根据公司的 LDAP 设置和 Elasticsearch 用户/角色之间的角色映射查询一个或两个索引。
当工程师再次询问补偿时,这一次实施了适当的 RBAC,它不会提供受限信息。

当经理登录此聊天机器人并询问相同的问题时,该用户的 RBAC 设置允许他们访问受限的 HR 数据集。
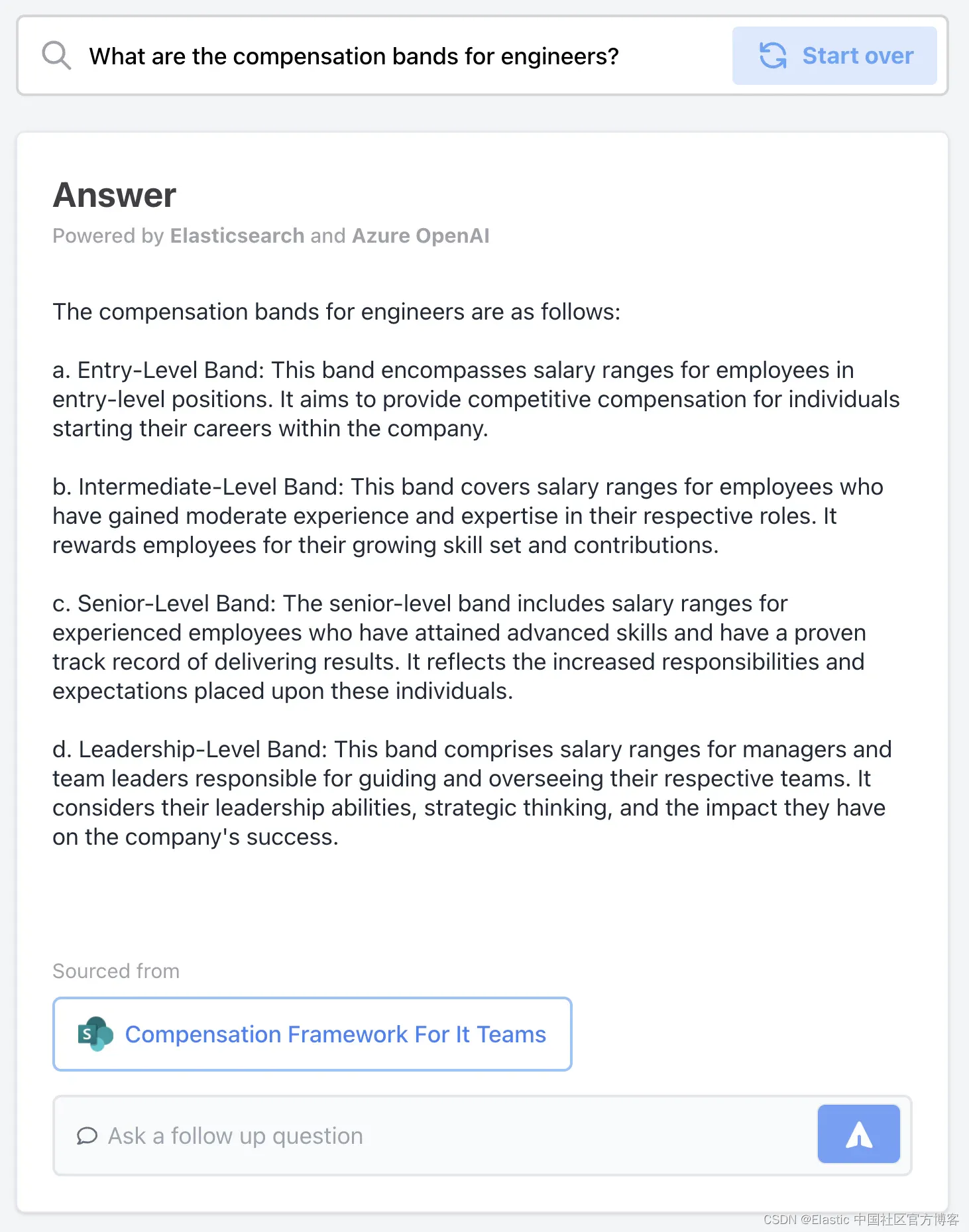
此答案正确地限制为经理角色,而如果没有 RBAC 限制,所有员工都可以查询受限数据集并获取响应。
此示例显示索引级访问如何帮助确保哪些索引组可以访问。 然而,如上所述,Elasticsearch 提供了许多附加且更精细的方法来保护你的数据。 请留意本博客的后续内容,我们将在其中讨论并提供一些高级 RBAC 配置的代码示例。
结束语
在 Elasticsearch 中集成检索增强生成 (RAG) 与基于角色的访问控制 (RBAC),为内部和外部应用程序提供了强大且安全的解决方案。 RAG 增强了大型语言模型的功能,而 RBAC 确保对敏感数据的访问受到严格控制,从而维护公司信息的完整性和机密性。 这种组合在数据保护至关重要的生产环境中尤其重要。 正如我们所演示的,在 Elasticsearch 中实施 RBAC 既实用又简单,使其成为任何希望利用 AI 的力量同时确保数据隐私的公司的理想选择。
我们鼓励您进一步探索此功能,并考虑如何将其应用于你独特的业务需求。 请记住,搜索人工智能不仅仅是生成智能响应,还在于保护你宝贵的数据资产。
准备好将 RAG 构建到您的应用程序中了吗? 想要尝试使用向量数据库的不同 LLMs?
在 Github 上查看我们的 LangChain、Cohere 等示例 notebook,并参加即将开始的 Elasticsearch 工程师培训!

