
- 12024年网络安全行业真的内卷了吗?_2024年行业内卷,2024年最新你的技术真的到天花板了吗
- 2使用pandas-alive对“2022年冬奥运奖牌信息“可视化_pandas_alive使用方法
- 3Pipeline详解及Spark MLlib使用示例(Scala/Java/Python)_pipeline的建立和使用spark
- 4QGC调试px4固件飞控_pixhawk2.4.8推荐刷哪个版本的px4固件
- 5【书生·浦语大模型实战营】第6节笔记:Lagent & AgentLego 智能体应用搭建
- 6用多模态信息做 prompt,解锁 GPT 新玩法
- 7基于GSYVideoPlayer自定义布局结合RecyclerView高仿抖音实现上下滑动双击屏幕点赞/单击暂停,拖动进度条实时改变时间以及进度条放大_android gsyvideoplayer
- 8英雄为何失败--看《汉武大帝》中的李广与程不识_汉武大帝看书
- 9使用Spring Boot实现大文件断点续传及文件校验_springboot整合文件断点续传
- 10linux g++ 环境编译配置笔记_linu g++ 快捷键
二叉搜索树(二叉排序树,二叉查找树)(附图详解+代码实现+应用分析)
赞
踩
最近学习了有关搜索二叉树的相关知识,在此特意将该知识进行总结分享,希望对大家有所帮助。
一.二叉搜索树
1.1二叉搜索树的概念
二叉搜索树又叫二叉排序树,二叉查找树,可以为空,也可以不为空,具体有以下的特性:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树

1.2二叉搜索树的操作(含思路分析+代码实现)
一个基本的二叉搜索树需要有哪些函数(接口)呢?
1.2.1二叉搜索树的查找(递归实现看最后总代码)
基于二叉搜索树的结构的特点:左节点小于根,右节点大于根
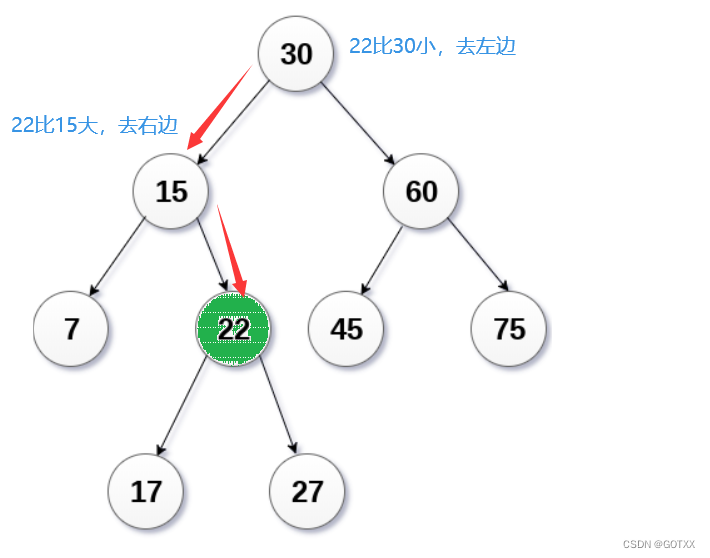
查找的思路分析:
a、从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。
b、最多查找高度次,走到到空,还没找到,这个值不存在。
图解:
代码实现:
bool Find(const K& key) //key为寻找关键字 { if (_root == nullptr) //如果为空,直接返回 { return false; } else { Node* cur = _root; //用cur迭代寻找 while (cur) { if (key > cur->_key) //如果key比根节点的值大,则去右子树寻找 { cur = cur->_right; } else if(key < cur->_key) //如果key比根节点的值小,则去左子树寻找 { cur = cur->_left; } else { return true; //相等,返回true } } return false; //出循环,还没找到,返回false } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.2.2二叉搜索树的插入(递归实现看最后总代码)
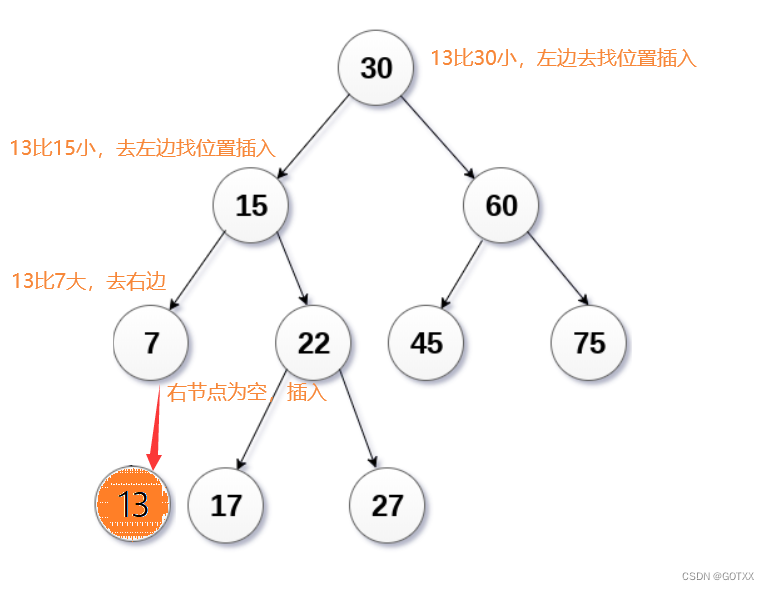
插入思路分析:
a. 树为空,则直接新增节点,赋值给root指针
b. 树不空,按二叉搜索树性质查找插入位置,插入新节点
图解:
代码实现:
bool insert(const K& key) { if (_root == nullptr) //如果为空树,直接插入 { Node* newNode = new Node(key); //new一个节点 _root = newNode; //链接 return true; //插入成功,返回true } else { Node* parent = nullptr; //因为要链接,所以需要记录父亲 Node* cur = _root; while (cur) //while循环和find函数类似,目的找到合适位置插入 { if (key > cur->_key) { parent = cur; //记录父节点 cur = cur->_right; } else if(key < cur->_key) { parent = cur; cur = cur->_left; } else { return false; //搜索二叉树里面的值不能重复,如果已经存在,则返回false } } //cur空,结束循环,代表找到位置了 Node* newNode = new Node(key); //new节点 if (key < parent->_key) parent->_left = newNode; if (key > parent->_key) //判断是链接到父亲的左还是右 parent->_right = newNode; return true; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
1.2.3二叉搜索树的删除(递归实现看最后总代码)
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
a. 要删除的结点无孩子结点 //直接删除
b. 要删除的结点只有左孩子结点 //托孤
c. 要删除的结点只有右孩子结点 //托孤
d. 要删除的结点有左、右孩子结点 //替换法删除
看起来有待删除节点有4中情况,实际情况a可以与情况b或者c合并起来,因此真正的删除过程如下:
情况b:删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点–直接删除
情况c:删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点–直接删除
情况d:在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题–替换法删除
托孤发删除的原理:
假设我们要删除【图一】的22,它只有一个孩子,就可以使用托孤的方法,直接让父节点(15)指向它的孩子(17);
该方法也可以在删除没有孩子的节点上使用(将它看作有一个为NULL的孩子即可),例如下【图二】,假设删除17;
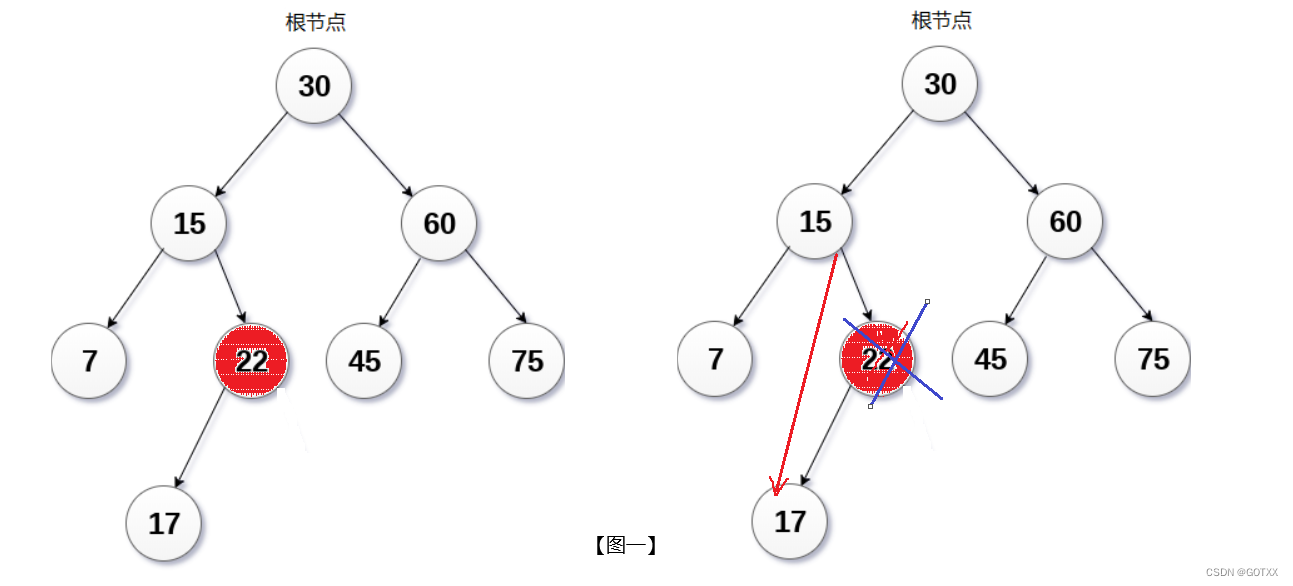
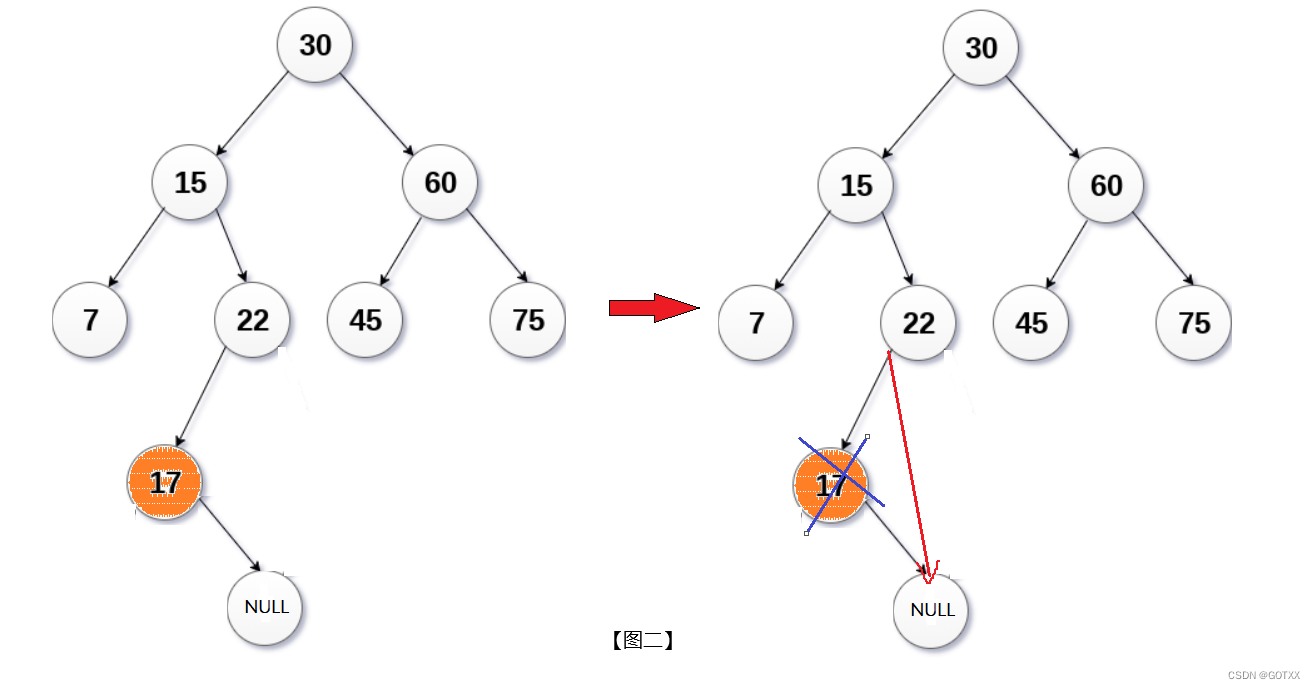
替换法删除的原理:
方法作用于有两个孩子的节点:
a,找到该节点左子树的最右节点(即左子树最大的节点)或则右子树的最左节点(即右子树最小值);
b,然后将待删除节点的值与找到的最大(或最小)节点的值进行交换,转化为删除找到的这个节点;
c,最后用上面的托孤的方法删除该节点
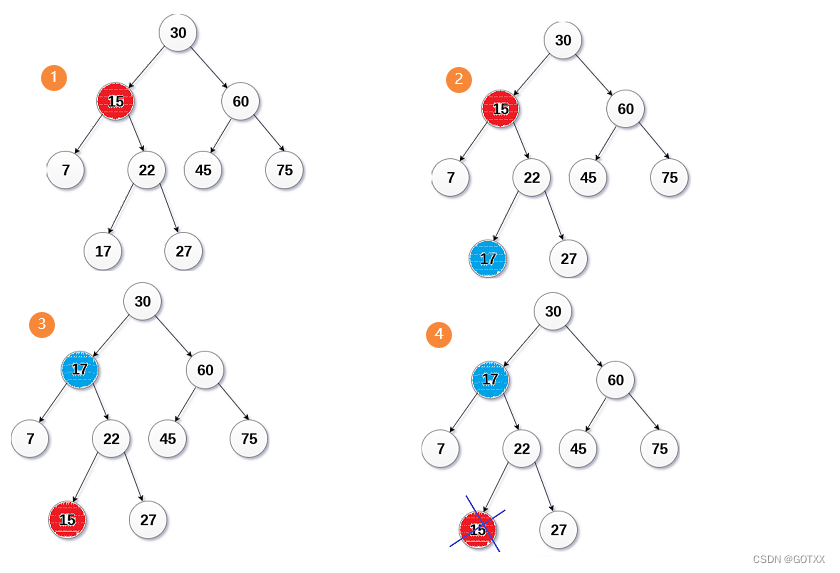
代码实现:
bool Erase(const K& key) { if (_root == nullptr) //如果树为空,直接返回 return false; else //树不为空 { Node* parent = _root; Node* cur = _root; while (cur) //while循环,先找到待删除节点以及记录它父节点 { //该循环体与find和insert类似 if (key > cur->_key) { parent = cur; cur = cur->_right; } else if (key < cur->_key) { parent = cur; cur = cur->_left; } else //找到该节点了,开始删除 { //1.只有一个孩子或则没有孩子 Node* del = cur; //保存要删除的这个节点,防止等下托孤后该节点找不到 if (!(cur->_left && cur->_right)) //两个孩子都存在的逻反就是有一个孩子或则没有孩子 { if (cur == _root) //这里,判断如果该节点是头节点,直接将头节点置空,返回 { _root = nullptr; } if (parent->_left == cur) //该删除节点为父节点的左子树,则将它的孩子连接到它父节点的左子树上 { if (cur->_left) //判断孩子是待删除节点的哪个孩子 { parent->_left = cur->_left; } else { parent->_left = cur->_right; } return true; } else //和上面一样 { if (cur->_left) { parent->_right = cur->_left; } else { parent->_right = cur->_right; } return true; } } //2.待删除节点有两个孩子 else //这里实现的是替换法中找右子树中最小的节点 { Node* rightMinparent = cur; //记录最小节点的父亲,因为等下需要托孤 Node* rightMin = cur->_right; //记录最小节点 while (rightMin->_left) { rightMinparent = rightMin; rightMin = rightMin->_left; } //到这里说明中找到了右树的最小节点 swap(rightMin->_key, cur->_key); //交换最小节点与待删除节点的值,转换为删除这个最小节点 if (rightMinparent->_left==rightMin) //下面的逻辑与上面的托孤一样 { rightMinparent->_left = rightMin->_right; } else { rightMinparent->_right = rightMin->_right; } delete rightMin; //最后删除 } return true; } } return false; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
总代码(含递归实现):
#pragma once #include<iostream> using namespace std; template<class K> struct Binary_Serach_TreeNode { typedef Binary_Serach_TreeNode<K> Node; Node* _left; Node* _right; K _key; Binary_Serach_TreeNode(const K& key) :_left(nullptr) , _right(nullptr) , _key(key) {} }; template<class K> class B_S_Tree { public: typedef Binary_Serach_TreeNode<K> Node; //B_S_Tree() = default; //强制生成默认构造 B_S_Tree() :_root(nullptr) {} B_S_Tree(B_S_Tree<K>& bst) { _root = copy(bst._root); } Node* copy(Node* root) { if (root == nullptr) return nullptr; Node* newroot = new Node(root->_key); newroot->_left = copy(root->_left); newroot->_right = copy(root->_right); return newroot; } B_S_Tree<K>& operator=(B_S_Tree<K> bst) { std::swap(bst._root, _root); return *this; } bool insert(const K& key) { if (_root == nullptr) //如果为空树,直接插入 { Node* newNode = new Node(key); //new一个节点 _root = newNode; //链接 return true; //插入成功,返回true } else { Node* parent = nullptr; //因为要链接,所以需要记录父亲 Node* cur = _root; while (cur) //while循环和find函数类似,目的找到合适位置插入 { if (key > cur->_key) { parent = cur; //记录父节点 cur = cur->_right; } else if(key < cur->_key) { parent = cur; cur = cur->_left; } else { return false; //搜索二叉树里面的值不能重复,如果已经存在,则返回false } } //cur空,结束循环,代表找到位置了 Node* newNode = new Node(key); //new节点 if (key < parent->_key) parent->_left = newNode; if (key > parent->_key) //判断是链接到父亲的左还是右 parent->_right = newNode; return true; } } bool Erase(const K& key) { if (_root == nullptr) //如果树为空,直接返回 return false; else //树不为空 { Node* parent = _root; Node* cur = _root; while (cur) //while循环,先找到待删除节点以及记录它父节点 { //该循环体与find和insert类似 if (key > cur->_key) { parent = cur; cur = cur->_right; } else if (key < cur->_key) { parent = cur; cur = cur->_left; } else //找到该节点了,开始删除 { //1.只有一个孩子或则没有孩子 Node* del = cur; //保存要删除的这个节点,防止等下托孤后该节点找不到 if (!(cur->_left && cur->_right)) //两个孩子都存在的逻反就是有一个孩子或则没有孩子 { if (cur == _root) //这里,判断如果该节点是头节点,直接将头节点置空,返回 { _root = nullptr; } if (parent->_left == cur) //该删除节点为父节点的左子树,则将它的孩子连接到它父节点的左子树上 { if (cur->_left) //判断孩子是待删除节点的哪个孩子 { parent->_left = cur->_left; } else { parent->_left = cur->_right; } return true; } else //和上面一样 { if (cur->_left) { parent->_right = cur->_left; } else { parent->_right = cur->_right; } return true; } } //2.待删除节点有两个孩子 else //这里实现的是替换法中找右子树中最小的节点 { Node* rightMinparent = cur; //记录最小节点的父亲,因为等下需要托孤 Node* rightMin = cur->_right; //记录最小节点 while (rightMin->_left) { rightMinparent = rightMin; rightMin = rightMin->_left; } //到这里说明中找到了右树的最小节点 swap(rightMin->_key, cur->_key); //交换最小节点与待删除节点的值,转换为删除这个最小节点 if (rightMinparent->_left==rightMin) //下面的逻辑与上面的托孤一样 { rightMinparent->_left = rightMin->_right; } else { rightMinparent->_right = rightMin->_right; } delete rightMin; //最后删除 } return true; } } return false; } } bool Find(const K& key) //key为寻找关键字 { if (_root == nullptr) //如果为空,直接返回 { return false; } else { Node* cur = _root; //用cur迭代寻找 while (cur) { if (key > cur->_key) //如果key比根节点的值大,则去右子树寻找 { cur = cur->_right; } else if(key < cur->_key) //如果key比根节点的值小,则去左子树寻找 { cur = cur->_left; } else { return true; //相等,返回true } } return false; //出循环,还没找到,返回false } } bool insertR(const K& key) { return _inserR(_root, key); } bool FindR(const K& key) { return _FindR(_root,key); } bool EraseR(const K& key) { return _EraseR(_root, key); } void OrdPrint() { _OrdPrint(_root); cout << endl; } ~B_S_Tree() { //_Destory(_root); } private: void _OrdPrint(Node* root) { if (root == nullptr) return; _OrdPrint(root->_left); cout << root->_key <<' '; _OrdPrint(root->_right); } bool _FindR(Node* root, const K& key) { if (root == nullptr) return false; if (key < root->_key) return _FindR(root->_left, key); else if (key < root->_key) return _FindR(root->_right, key); else return true; } bool _inserR(Node*& root, const K& key) { if (root == nullptr) { root = new Node(key); return true; } if (key < root->_key) return _inserR(root->_left, key); else if (key > root->_key) return _inserR(root->_right, key); else return false; } bool _EraseR(Node*& root,const K& key) { if (root == nullptr) return false; if (key < root->_key) _FindR(root->_left, key); else if (key < root->_key) _FindR(root->_right, key); else { Node* del = root; if (root->_left==nullptr) root = root->_right; else if(root->_right==nullptr) root = root->_left; else { Node* rightMinparent = root; Node* rightMin = root->_right; while (rightMin->_left) { rightMinparent = rightMin; rightMin = rightMin->_left; } swap(root->_key, rightMin->_key); return _EraseR(root->_right, key); } delete del; return true; } } void _destory(Node* root) { if (root == nullptr) return; else { _destory(root->_left); _destory(root->_right); delete root; } } private: Node* _root; };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
二. 二叉搜索树的应用
应用一:
K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
应用二:
KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。
三.二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树)【如图左】,其平均比较次数为:log_2 N
最差情况下,二叉搜索树退化为单支树(或者类似单支)【如图右】,其平均比较次数为:N

本章完~看完觉得对你有用就点个赞吧!


