
- 1微信朋友圈怎么批量发圈_微信朋友圈如何批量发圈
- 2一款基于JQuery和bootstrap的单页面WebApp框架_bootstrap项目能被打包成单页面应用吗
- 3腾讯云 Sql Server 部署_sqlserver部署到服务器上
- 4[嵌入式AI从0开始到入土]17_Ascend C算子开发
- 5Linux中PyTorch的安装教程_linux 安装pytorch
- 6电脑提示mfc140u.dll文件丢失了?怎么快速修复mfc140u.dll文件
- 7git统计每次commit的代码信息_github获取提交记录及每次提交代码量
- 8【UE模型优化教程系列】3.一张图搞懂帧率的秘密
- 9Git 进阶 高级用法,重要命令记录_git高级用法
- 10万字讲解Linux常用指令_linux系统alt+m
c语言结构体 链表_c结构体链表
赞
踩
单链表 尾插法 头插法 看这篇https://blog.csdn.net/viafcccy/article/details/84502334
https://blog.csdn.net/viafcccy/article/details/85041942
单链表实现贪吃蛇看这篇https://blog.csdn.net/viafcccy/article/details/84483828
着两天都是看书没有写代码就把看书的心得思考写下来
先来说说对于内存的看法 因为对于内存机制的理解有助于对于后面的东西的理解
结构体
结构体就是讲多个函数 变量 数组相互链接起来的东西
大概类似于原来多个数据存在磁盘的各个扇区不同的位置,但是你只要写了一个结构体就会调用cpu快速的去找到各个成员的位置将他们关联起来 也就是原来没有关联性的数据现在变得有关联性了
也就是这样原来
| a |
| 其他数据 |
| b |
| 其他数据 |
| c |
变成了
| a |
| b |
| c |
| 其他数据 |
| 其他数据 |
全局变量
全局变量对应的是局部变量也就是下面三种情况
1.各个函数一开头我们要定义的那些变量
2.复合语句里定义的
3.在函数外部定义的
而全局变量是这样的
程序工程中往往遇到这样的问题:某个变量是贯穿始终的,主函数以及不同的子函数都要用到这个变量,并且要调用子函数改变变量的值。这时候全局变量就起到一个桥梁作用,在函数外定义,在主函数中调用定义,在子函数A中调用并赋值,在子函数B中调用该变量,此时的值已经是改变之后的值。
用法:在主函数之前定义全局变量(不包含在任何变量里)
int pointnum;//全局变量,匹配点对个数
在主函数main中调用,要加关键字extern
extern int pointnum; //全局变量,匹配点对个数
在接下来的子函数A中也用extern调用全局变量,并将函数运行中得到的数据赋给全局变量,此时该变量的值已经被改变,无论接下来在主函数还是后面的子函数中用到,都是改变之后的值
int A()//子函数A
{
extern int pointnum;//引用全局变量
pointnum = viewMatches.size();//将匹配点个数传递给全局变量
}
主函数在调用过子函数A之后,pointnum的值被彻底改变为viewmatches.size(),可以供子函数B使用
//调用子函数A,改变pointnum的值
A(srcImage1, srcImage2);//输入两幅图
//调用子函数B,用到pointnum
solveab(matchpoint, pointnum, M1, M2);//传入匹配点坐标,匹配点对个数pointnum,投影矩阵
for (int i = 0; i < pointnum; i++)//释放matchpoint,主函数也用到pointnum
free(matchpoint[i]);
也就是假如是一部法律全局变量在编程一开写的就是国家法律对下面的所有函数都有效,下面的只对他们之后的有效,也就是向下有效。
还有就是链表通过地址将各个数据连接起来关联起来 形成一种数据的结构 感觉很有区块链 神经网络的感觉
具体看下面吧转自https://blog.csdn.net/u012531536/article/details/80170893
链表基础知识总结
链表和数组作为算法中的两个基本数据结构,在程序设计过程中经常用到。尽管两种结构都可以用来存储一系列的数据,但又各有各的特点。
数组的优势,在于可以方便的遍历查找需要的数据。在查询数组指定位置(如查询数组中的第4个数据)的操作中,只需要进行1次操作即可,时间复杂度为O(1)。但是,这种时间上的便利性,是因为数组在内存中占用了连续的空间,在进行类似的查找或者遍历时,本质是指针在内存中的定向偏移。然而,当需要对数组成员进行添加和删除的操作时,数组内完成这类操作的时间复杂度则变成了O(n)。
链表的特性,使其在某些操作上比数组更加高效。例如当进行插入和删除操作时,链表操作的时间复杂度仅为O(1)。另外,因为链表在内存中不是连续存储的,所以可以充分利用内存中的碎片空间。除此之外,链表还是很多算法的基础,最常见的哈希表就是基于链表来实现的。基于以上原因,我们可以看到,链表在程序设计过程中是非常重要的。本文总结了我们在学习链表的过程中碰到的问题和体会。
接下来,我们将对链表进行介绍,用C语言分别实现:链表的初始化、创建、元素的插入和删除、链表的遍历、元素的查询、链表的删除、链表的逆序以及判断链表是否有环等这些常用操作。并附上在Visual Studio 2010 中可以运行的代码供学习者参考。
说到链表,可能有些人还对其概念不是很了解。我们可以将一条链表想象成环环相扣的结点,就如平常所见到的锁链一样。链表内包含很多结点(当然也可以包含零个结点)。其中每个结点的数据空间一般会包含一个数据结构(用于存放各种类型的数据)以及一个指针,该指针一般称为next,用来指向下一个结点的位置。由于下一个结点也是链表类型,所以next的指针也要定义为链表类型。例如以下语句即定义了链表的结构类型。
typedef struct LinkList
{
int Element;
LinkList * next;
}LinkList;
链表初始化
在对链表进行操作之前,需要先新建一个链表。此处讲解一种常见的场景下新建链表:在任何输入都没有的情况下对链表进行初始化。
链表初始化的作用就是生成一个链表的头指针,以便后续的函数调用操作。在没有任何输入的情况下,我们首先需要定义一个头指针用来保存即将创建的链表。所以函数实现过程中需要在函数内定义并且申请一个结点的空间,并且在函数的结尾将这个结点作为新建链表的头指针返回给主调函数。本文给出的例程是生成一个头结点的指针,具体的代码实现如下:
linklist * List_init()
{
linklist *HeadNode= (linklist*)malloc(sizeof(linklist));
if(HeadNode == NULL)
{
printf("空间缓存不足");
return HeadNode;
}
HeadNode->Element= 0;
HeadNode->next= NULL;
returnHeadNode;
}
当然,初始化的过程或者方法不只这一种,其中也包含头指针存在的情况下对链表进行初始化,此处不再一一罗列。
这里引申一下,此处例程中返回的链表指针为该链表的头结点,相对应的还有一个头指针的概念。头指针内只有指针的元素,并没有数据元素,但头结点除了指针还有数据。
头指针就是链表的名字,仅仅是个指针而已。头结点是为了操作的统一与方便而设立的,放在第一个有效元素结点(首元结点)之前,其数据域一般无意义(当然有些情况下也可存放链表的长度、用做监视哨等等)。一般情况下见到的链表的指针多为头指针,但最近在一个程序员编程网站leetcode中发现,题目中所给的链表一般是首元结点作为第一个元素,而不是头指针。
下图为头指针与头结点以及首元结点的关系。
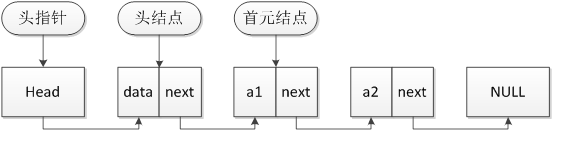
链表创建
创建链表需要将既定数据按照链表的结构进行存储,本文以一种最简单的方式来演示:使用数组对链表赋值。将原来在连续空间存放的数组数据,放置在不连续的链表空间中,使用指针进行链接。
链表创建的步骤一般使用给定的头指针以及需要初始化的数据序列作为输入参数,本文使用数组作为输入数据序列。在下面的例程中,先将首元结点使用数组第一个元素初始化,再在首元结点之后创建新的链表结点赋值数组内余下的数据。具体实现如下:
void CreatList(linklist *HeadNode,int *InData,int DataNum)
{
int i = 0;
linklist *CurrentNode = (linklist*) HeadNode;
for(i = 0;i<DataNum;i++)
{
CurrentNode->Element = InData[i];
if(i< DataNum-1)// 由于每次赋值后需要新建结点,为了保证没有多余的废结点
{
CurrentNode->next =(linklist *)malloc(sizeof(linklist));
CurrentNode= CurrentNode->next;
}
}
CurrentNode->next= NULL;
}
程序内先新建了一个指针变量CurrentNode用来表示当前的结点指针。最初,我们让CurrentNode指向了首元结点HeadNode的位置。然后根据输入数组的大小进行循环赋值,赋值完成之后再重新申请一个结点空间用来存放下一个结点的内容,并且将当前结点指针CurrentNode指向新生成的结点。由于链表创建函数调用时已经存在一个首元结点,按照这个逻辑最终在使用最后一个数组数据赋值之后还会多生成一个结点。因此,为了保证没有冗余的结点,循环内需要用DataNum-1来控制结点数量。
另外,C语言的初学者需要注意:无论被调子函数内含在几个参数,虽然子函数内的形参使用的是主函数内实参的指针,但在子函数内是不会改变主函数里实参的地址的。也就是说,只要子函数不返回指针,子函数的内容就不会影响主函数内的参数指针。正如程序中CurrentNode的指针最初是主函数内的头指针传递进来的,虽然创建链表的函数内CurrentNode的指针一直在往后移动,但并不会改变主调函数内的首元结点的指针。本文链表的学习过程中会大量使用指针,建议各位学习者在打牢基础后再进行学习。
插入链表结点
链表创建完之后,下面我们将介绍如何向链表内插入结点。一般添加结点可以分为两类:一类是在链表尾部插入;另一类为在中间插入。
链表结尾添加结点的步骤就是新建一个链表结点,将其链接到当前链表尾指针。
在中间结点插入结点的步骤稍微复杂一些,其中也包含两种情况,分别是在指定结点前插入和指定结点后插入。其操作原理一样,本文只对指定位置后插入结点进行介绍。指定结点前插入结点留给大家尝试。
假设一个链表内存在几个几点A1,A2,A3,A4….,当根据要求需要在指定位置之后(比如A2结点)插入一个新结点时。首先我们需要新建立一个结点NodeToInsert,然后将新结点的next指向A3,并且将A2的next指针指向新建立的结点NodeToInsert,切记操作顺序不要改变。如果操作顺序变换一下,先将A2的next指向了新建立的结点,那么我们就丢失了A3的寻址方式。因此,在将A2的next指向其他任何地方之前,请务必将A3的地址存在NodeToInsert或者某个新建节点内。
插入结点的具体操作如下:
bool InsertList(linklist *HeadNode,int LocateIndex,int InData)
{
int i=1;// 由于起始结点HeadNode是头结点,所以计数从1开始
linklist *CurrentNode= (linklist *) HeadNode;
//将CurrentNode指向待插入位置的前一个结点(index -1)
while(CurrentNode&& i<LocateIndex-1)
{
CurrentNode= CurrentNode->next;
i++;
}
linklist *NodeToInsert=(linklist*)malloc(sizeof(linklist));
if(NodeToInsert == NULL)
{
printf("空间缓存不足");
return ERROR;
}
NodeToInsert->Element= InData;
NodeToInsert->next = CurrentNode->next;
CurrentNode->next = NodeToInsert;
return OK;
}
删除链表结点
对应于插入链表结点,链表的基本操作中同样也有删除链表结点。删除结点包括删除指定位置的结点和指定元素的结点。其基本原理都是先锁定待删除的结点的位置,然后将该结点的后置结点链接到前置结点的next指针处。这样中间这个结点即我们要删除的结点就从原来的链表中脱离开来。相对于原来的链表,即删除了该结点。
bool DeleteList(linklist * HeadNode,int index, int * DataToDel)
{
int i = 1;
linklist *CurrentNode = HeadNode;
linklist *NodeToDelete;
//将CurrentNode指向待删除位置的前一个结点(index -1)
while(CurrentNode&& i<index-1)
{
CurrentNode= CurrentNode->next;
i++;
}
NodeToDelete = CurrentNode->next;
*DataToDel =NodeToDelete->Element;
CurrentNode->next= NodeToDelete->next;
free(NodeToDelete);
return OK;
}
此处为什么还要重新建立一个指针来记录或者保存待删除的结点呢?明明一个简单的步骤CurrentNode ->next = CurrentNode ->next->next;就可以将这个结点CurrentNode->next删除了,为什么要多此一举呢?
此处新建的链表类型的指针NodeToDelete是为了释放CurrentNode->next。直接使用CurrentNode ->next = CurrentNode ->next->next只是将该节点从链表中剔除,但是没有将其空间从内存中释放。而且,经过了CurrentNode ->next = CurrentNode ->next->next这个赋值语句之后,我们已经丢失了原本需要删除的结点的地址。所以,在删除之前新建了个结点用来保存待删除的结点地址,以便后面对内存空间的释放。
获取链表长度&链表遍历
获取链表的长度实际上和遍历链表具有相同的操作。遍历的过程将链表内的结点都访问了一边。获取链表长度的具体步骤是遍历链表之后能够记录并返回链表结点个数。
本文给出获取链表长的函数代码。
int GetListLength(linklist *HeadNode)
{
int ListLength = 0;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)// 当前指针不为空时可以计数累加
{
ListLength++;
CurrentNode= CurrentNode->next; //指针移到下一结点
}
returnListLength;
}
在该函数中,出现了CurrentNode = CurrentNode ->next的表示方法,这是将CurrentNode ->next这个结点的指针移动到了当前这个结点CurrentNode,下一次使用CurrentNode指针的时候CurrentNode实际已经指向了下一个结点CurrentNode ->next。所以这也是常说到的结点后移。
对于链表内的赋值操作我们总结出几种情况:
获取链表元素
接下来我们将“给定链表中的某一个位置,返回该位置的数据值”和“返回链表内某一个元素的位置”这两个问题放在一起介绍。
这两种情况的思路都是需要遍历链表。在给定元素值的情况下,定义一个元素序号随着遍历的过程累加,遍历的过程校验链表的结点是否与给定的元素匹配,如果匹配则返回元素位置的序号;在给定位置的情况下就更简单一些,元素序号累加到对应位置,返回对应结点的元素即可。
本文只列出给定元素值的例子:
int LocateElement(linklist * HeadNode,int DataToLocate)
{
int LocateIndex = 1;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)
{
if(CurrentNode->Element== DataToLocate)
{
returnLocateIndex; //找到位置返回
}
CurrentNode= CurrentNode->next;
LocateIndex++;
}
return -1; //如果没有这个值,返回-1
}
本函数的逻辑是如果遍历链表之后能够找到与所给元素匹配的结点,则将该结点的位置返回。但如果没有匹配的结点的话,则返回一个-1,表示获取元素位置失败。
链表置空
链表置空又可以称为销毁链表。同样是在遍历的前提下,一直到链表结尾结束,所有遍历到的链表结点均释放掉空间,具体代码如下:
bool DestroyList(linklist * HeadNode)
{
linklist *pNext;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)
{
pNext = CurrentNode->next;
free(CurrentNode);
CurrentNode= pNext;
}
HeadNode->next = NULL;
return OK;
}
链表逆序
链表的逆序有很多种思路,本文介绍一种将当前结点的下一结点一直往头指针之后移动的思路。
假设当前有5个结点,head、a1、a2、a3、a4、a5,他们的头指针是head。我们的思路便是将a1作为当前元素一直往后遍历,并且将a1后面的数据依次挪到head之后。
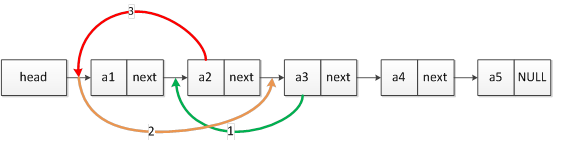
在第一次搬移的过程中,需要将a1的下一个元素a2放在head之后。如图所示,当前结点选定为a1,起一个变量名为current,当前结点的下一个结点为pNext,则a2便成了pNext = current->next。如果想要将pNext移到head之后,我们按照图中第1步先将a3连接到a1的后面,然后第2步再将head后面的整体链表放到要移动的a2的后面,也就是pNext->next= head->next,第3步将a2移到head之后。这三个步骤下来,我们的第一次反转工作就算完成了。此时的链表链表就变成了head、a2、a1、a3、a4、a5,如图所示:

如果上面移动的步骤不按图中进行会出现什么情况呢?假设现在按照3-2-1的步骤来实现a2移动到head后面。当先进行第三步之后,即head->next = pNext;这一步直接将a2挪到了head之后。然后我们接下来应该再将原来head后面的一串数据链接到刚刚移动到head后面的a2后面,此处由于head后面的数据已经被pNext更新了,此时head后面是a2结点,所以在执行第二步以后,链表就变成了无限循环的链表,而且循环的元素值是a2。
按照上图正确的顺序实现第一次反转以后,可以判定当前的current指针是否已经是尾指针,如果不是就可以继续执行。第二次反转后链表就变成了head、a3、a2、a1、a4、a5。因此当把链表内的最后一个元素也移动到head之后时,链表逆序的工作就算完成了。

具体的代码实现如下。
linklist * ListRotate(linklist * HeadNode)
{
linklist* current,*pNext,*pPrev;
pPrev = (linklist*)malloc(sizeof(linklist));
if(pPrev == NULL)
{
printf("空间缓存不足");
return ERROR;
}
pPrev->next = HeadNode;
current = HeadNode;
while(current->next)
{
pNext = current->next;
current->next = pNext->next;
pNext->next = pPrev->next;
pPrev->next = pNext;
}
return pPrev->next;
}
链表判断是否有环
判断链表是否存在环的过程中,通常最先想到的方法就是从定义下手,有环的话就没有尾结点,也就是说不存在一个结点的next指针是null。通过这种思路可以对有环无环进行判定,但需要判定到何时呢?
当遍历了4000个结点都没有遇到null结点,难道就可以断定这就是一个有环的链表吗?如果它的第4001个结点就是尾结点呢?很多情况下,我们是不知道链表的长度的,所以我们很难确定需要判定到哪一个结点才能确定链表是否为环形链表。因此我们需要借助快指针、慢指针的概念,这是目前用来判断链表内有环无环的最通用有效的方法。
假设有这样一种情况,有两辆车,一辆车每秒钟可以跑n米,另外一辆速度要快一些,每秒能跑2n米,这两辆车都匀速运行。如果在一个没有交叉点的跑道上,这时跑道上有一个终点,快车和慢车同时在起始点相遇出发之后,一直到终点,快车和慢车的距离只会越拉越大,等到快车到达终点的时候,两者之间的距离差最大。假想一种情况,如果跑道的终点与起始点连接了起来,虽然说从慢车的角度看,快车在前方越来越远。但快车的角度看,慢车在后面越来越远,但在前面看的话确实越来越近。所以在一个环形的跑道上,快车终究会有第二次与慢车相遇,此时正好超车一圈。
函数的执行过程如下:
bool IsListLoop(linklist *HeadNode)
{
linklist *pFast,*pSlow;
pFast = pSlow = HeadNode;
while(pFast && pSlow)
{
pSlow = pSlow->next;
if(pFast->next)
{
pFast= pFast->next->next;
}
else
{
pFast= pFast->next;
}
if(pFast == pSlow)
{
returnTRUE;
}
}
return FALSE;
}
今天实在太晚了还有一些没写到的就以后慢慢用到了再去补上

