
- 1深度学习机器视觉车道线识别与检测 -自动驾驶 毕业设计_基于机器视觉(传统或深度)实现车道线检测或信号灯识别
- 2程序员因接外包坐牢 456 天!两万字揭露心酸经历
- 3Android Studio最新汉化教程_android汉化包下载
- 4nodejs基本操作,npm与cnpm使用介绍_nodejs cnpm
- 5C++类模板详解_c++里面的class numtype什么意思
- 6快速上手 Kotlin 开发系列之集合操作符 (1)_kotlin 链式对集合操作
- 7基于python的微博情感分析与文本分类系统的设计与实现_微博语言情感分析系统设计的目标与原则
- 8入职车载测试常见面试题(附答案)测试小白_车载蓝牙测试面试题
- 9字节跳动软件测试岗4轮面经(已拿34K+ offer)..._字节跳动测试开发面经校招
- 10KMP算法及其优化_intill算法
在SpringBoot项目中集成TDengine,并通过SQL对数据进行增删改查_springboot建立连接dengine
赞
踩
在SpringBoot项目中集成TDengine,并通过SQL对数据进行增删改查
好久以前写的,忘记发了,补发下;
本篇文章介绍SpringBoot项目集成TDengine后,如何通过MyBatis的mapper操作数据的增删改查,以及数据库,表的创建。
SpringBoot项目如何集成TDengine便不再进行介绍了,可以看上篇 TDengine从安装到与SpringBoot项目集成使用
本文章演示中TDengine的版本:2.4.0.0
创建数据库SQL语句
那么在SpringBoot中调用TDengine,其实和数据库为MySQL时的调用是差不多的,不过是jdbc驱动变了而已。
下面是创建数据库的语句
create database if not exists demo;
- 1
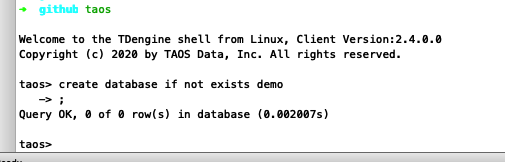
通过该SQL语句,可以创建数据库名为demo的数据库(只有demo数据库不存在的时候才会进行创建)。
查看数据库
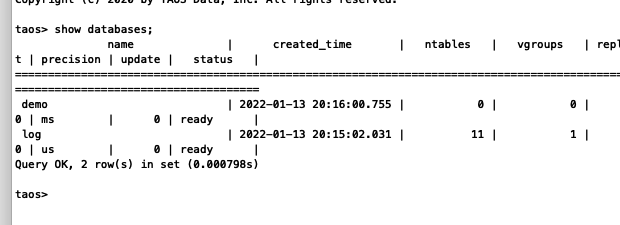
show databases;
- 1
通过该命令可以看到我们刚创建的数据库demo。
删除数据库SQL语句
drop database if exists demo;
- 1
该SQL语句的含义是:如果存在demo数据库,则进行删除
创建demo数据库下的表
创建表时有几个需要特别注意的点:
- 任何一张表或超级表是属于一个库的,在创建表之前,必须先创建库。
- 处于两个不同库的表是不能进行 JOIN 操作的。
- 创建并插入记录、查询历史记录的时候,均需要指定时间戳。
create table if not exists demo.weather(ts timestamp, temperature float, humidity float);
- 1

该SQL语句是在demo数据库下创建了名为weather的表,其中列有ts、temperature、humidity,类型分表为:timestamp、float、float;
TDengine还可以创建超级表STable。
查看表
show tables;
- 1
注意,在执行这句之前,要先进入到数据库。例如:use demo

超级表(也称为:STable)
超级表STable是什么
STable是同一类型数据采集点的抽象,是同类型采集实例的集合,包含多张数据结构一样的子表。每个STable为其子表定义了表结构和一组标签:表结构即表中记录的数据列及其数据类型;标签名和数据类型由STable定义,标签值记录着每个子表的静态信息,用以对子表进行分组过滤。子表本质上就是普通的表,由一个时间戳主键和若干个数据列组成,每行记录着具体的数据,数据查询操作与普通表完全相同;但子表与普通表的区别在于每个子表从属于一张超级表,并带有一组由STable定义的标签值。每种类型的采集设备可以定义一个STable。数据模型定义表的每列数据的类型,如温度、压力、电压、电流、GPS实时位置等,而标签信息属于Meta Data,如采集设备的序列号、型号、位置等,是静态的,是表的元数据。用户在创建表(数据采集点)时指定STable(采集类型)外,还可以指定标签的值,也可事后增加或修改。
超级表STable解决什么
TDengine要求每个数据采集点单独建表。独立建表的模式能够避免写入过程中的同步加锁,因此能够极大地提升数据的插入/查询性能。但是独立建表意味着系统中表的数量与采集点的数量在同一个量级。如果采集点众多,将导致系统中表的数量也非常庞大,让应用对表的维护以及聚合、统计操作难度加大。为降低应用的开发难度,TDengine引入了超级表(Super Table, 简称为STable)的概念。
超级表怎么用
TDengine扩展标准SQL语法用于定义STable,使用关键词tags指定标签信息。
例如下面的SQL
create table if not exists demo.weather(ts timestamp, temperature float, humidity float) tags(location nchar(64), groupId int);
- 1

创建了一个demo数据库下的weather的超级表。其中列有ts、temperature、humidity,类型分表为:timestamp、float、float;
和普通创建方式不同,多了一串:tags(location nchar(64), groupId int)其中tags是关键字,这句表示:带有标签location和标签groupId,类型分别为:nchar(64)、int。
前面完整的SQL表示:
创建了一个名为weather的STable,带有标签location和标签groupId。
创建完STable后,我们并不能直接使用它,而需要创建STable的子表。
创建超级表的子表
假设地区有,4个:杭州余杭区、杭州西湖区、杭州萧山区、上海宝山区。城市分组id有2个:杭州为1,上海为2。
我们对每个地区进行建表:
create table if not exists demo.t1 using demo.weather tags('杭州余杭区', 1);
create table if not exists demo.t2 using demo.weather tags('杭州西湖区', 1);
create table if not exists demo.t3 using demo.weather tags('杭州萧山区', 1);
create table if not exists demo.t4 using demo.weather tags('上海宝山区', 2);
- 1
- 2
- 3
- 4

demo.weather为超级表,创建了t1、t2、t3、t4四个子表,也就是普通的Table。
创建超级表时,tags后跟的是列的定义,而此时tags跟的是列的值。例如:tags(‘上海宝山区’, 2);是指超级表的location列值为上海宝山区,groupId列的值为2。
以t1为例,它表示地区t1的数据,表结构完全由超级表weather定义,标签location=”杭州余杭区”表示地区是杭州余杭区, type=1表示城市分组id是1
然后可以看到四张子表和一个超级表。

插入数据
如果要插入数据,也不是对超级表进行操作,而是对子表进行操作。
下面分别向四张表t1,t2, t3, t4写入一条数据,写入语句如下:
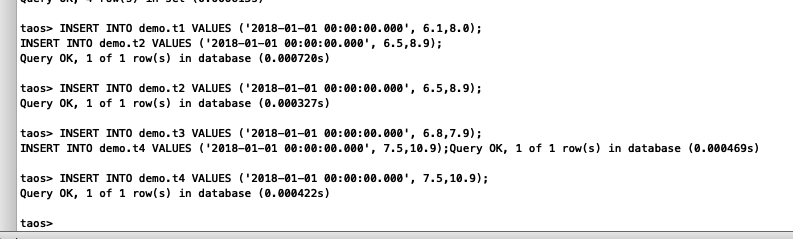
insert into demo.t1 values ('2018-01-01 00:00:00.001', 6.1,8.0);
insert into demo.t2 values ('2018-01-01 00:00:00.002', 6.5,8.9);
insert into demo.t3 values ('2018-01-01 00:00:00.003', 6.8,7.9);
insert into demo.t4 values ('2018-01-01 00:00:00.004', 7.5,10.9);
- 1
- 2
- 3
- 4
查询数据
查询超级表的所有数据
先查询所有数据。
SELECT * FROM demo.weather;
- 1

查询t1子表的所有数据
SELECT * FROM demo.t1;
- 1

聚合查询和函数使用
在这里,我们要查询位于"杭州西湖区"和"上海宝山区"两个地区的平均温度avg(temperature)、平均湿度avg(humidity)、最高温度max(temperature)、最低温度min(temperature),并将结果按所处城市id(groupId)进行聚合。
SELECT AVG(temperature),AVG(humidity), MAX(temperature), MIN(temperature) FROM demo.weather WHERE location='杭州西湖区' or location='上海宝山区' GROUP BY groupId;
- 1

修改数据
我想修改t1表中地区为"杭州西湖区"的温度为10.10。一般来说,很少用到修改数据。但其实用法和MySQL区别很大。
我们先查询一下原来的温度值是多少,那么按照MySQL中的方式这样写
select * from demo.t1 where location='杭州西湖区';
- 1
执行之后,其实是查询不到的,直接会报错。

错误信息:DB error: invalid operation: filter on tag not supported for normal table (0.000592s)
也就是说,正常表是不支持标签值的操作。这是属于超级表的操作。
那么其实我们知道,"杭州西湖区"是超级表中地区标签的值,而t1就是为这个地区建的。所以,直接在超级表上查询即可。
也就是可以这样查询:
select * from demo.weather where location='杭州西湖区';
- 1

这样就不会报错了。
修改数据其实有个大坑,默认是不支持修改数据的。
例如,我通过标签值/时间戳修改数据时报错:
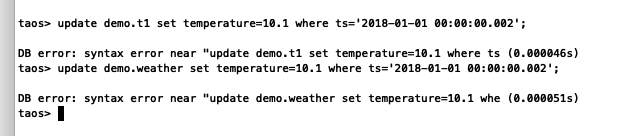
update demo.weather set temperature=10.1 where location='杭州西湖区';
update demo.weather set temperature=10.1 where ts='2018-01-01 00:00:00.002';
- 1
- 2
此语句是不行的。报错如下:

那么,需要怎么修改。
我试了一种方式,就是打开update参数开关。
建库时如果不指定 update 参数,则 update 默认为0,表示数据不可修改。
所以,我们删除库,重新来。 创建库,并指定update参数值为1,执行如下的SQL:
drop database if exists demo;
create database if not exists demo update 1;
create table if not exists demo.weather(ts timestamp, temperature float, humidity float) tags(location nchar(64), groupId int);
create table if not exists demo.t1 using demo.weather tags('杭州余杭区', 1);
create table if not exists demo.t2 using demo.weather tags('杭州西湖区', 1);
create table if not exists demo.t3 using demo.weather tags('杭州萧山区', 1);
create table if not exists demo.t4 using demo.weather tags('上海宝山区', 2);
insert into demo.t1 values ('2018-01-01 00:00:00.001', 6.1,8.0);
insert into demo.t2 values ('2018-01-01 00:00:00.002', 6.5,8.9);
insert into demo.t3 values ('2018-01-01 00:00:00.003', 6.8,7.9);
insert into demo.t4 values ('2018-01-01 00:00:00.004', 7.5,10.9);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此时,update已经修改为1;

然而我发现数据还是无法被更改。
update demo.t1 set temperature=10.1 where ts='2018-01-01 00:00:00.002';
update demo.weather set temperature=10.1 where ts='2018-01-01 00:00:00.002';
- 1
- 2
均进行了尝试。
最后发现,原来TDengine的删除不是通过update,而是通过insert关键字。
那么继续:修改t1表中地区为"杭州西湖区"的温度为10.10。
先查看现在的数据:
select * from demo.weather where location='杭州西湖区';
- 1
接下来是修改
insert into demo.t2 values ('2018-01-01 00:00:00.002', 10.10,8.9);
- 1

你会发现,原来的数据被新的数据覆盖了。这是因为在同一个子表下,如果时间戳一致,则新的数据之间覆盖旧的数据。
这是TDengine的一种机制。
所以,你会发现,时间戳是不可被修改的。
删除数据
TDengine也不支持删除数据。在数据库中有一个keep属性,建库时不指定 keep 参数,则 keep 默认为3650,表示数据存储10年,即 TDengine 具有数据自动清理机制。
有两种修改方式:
- keep与days关联使用,两者之间有限制(keep不可小于days),KEEP 参数是指修改数据文件保存的天数,缺省值为 3650,取值范围 [days, 365000],必须大于或等于 days 参数值,days默认值为10;
- 可通过配置文件(vi /etc/taos/taos.cfg)及建库选项的keep, days参数进行配置。
注意:不能删除数据!
只能设置keep的时间,让TDengine自动清除数据。
我本来是想着是不是插入一个10年前的数据,会自动就变成删除,结果发现,时间戳是keep时间以前的,无法被插入到数据库中。

删除表
例如,删除表weather,那么SQL为:
drop table demo.weather;
- 1
注意:超级表和普通的表都是这样删除。
注意点
- TDengine 对 SQL 语句中的英文字符不区分大小写,自动转化为小写执行。因此用户大小写敏感的字符串及密码,需要使用单引号将字符串引起来。
- 虽然 Binary 类型在底层存储上支持字节型的二进制字符,但不同编程语言对二进制数据的处理方式并不保证一致,因此建议在 Binary 类型中只存储 ASCII 可见字符,而避免存储不可见字符。多字节的数据,例如中文字符,则需要使用 nchar 类型进行保存。如果强行使用 Binary 类型保存中文字符,虽然有时也能正常读写,但并不带有字符集信息,很容易出现数据乱码甚至数据损坏等情况。
- SQL语句中的数值类型将依据是否存在小数点,或使用科学计数法表示,来判断数值类型是否为整型或者浮点型,因此在使用时要注意相应类型越界的情况。例如,9999999999999999999会认为超过长整型的上边界而溢出,而9999999999999999999.0会被认为是有效的浮点数。
源码地址
本项目演示了在Java中创建数据库,创建表,查询单条数据,分页查询数据,修改数据,新增数据,批量新增数据等操作,更多的功能,大家可以再自行研究。
https://github.com/chenhaoxiang/springboot-tdengine-demo
总结

我在Issues看到2019年有人就提出过TDengine不能修改和删除数据,到现在可以修改数据了,但是删除数据还是不行,只能设置keep的时间,让TDengine自动清除数据。
不过修改数据通过insert修改数据,还真是不习惯。
在这里,希望TDengine还是要支持能update关键字修改(并且不局限于时间戳的方式),不能搞卡死时间戳修改数据的权限,甚至是删除数据的权限。因为谁也不敢保证数据一定准确无误,无法人工修正的话,这是一个比较致命的问题。

