
- 1基于区块链的不动产登记电子证照应用服务系统设计方案---3.总体设计_基于区块链的可信电子证照方案设计
- 2Qt Design Studio使用场景
- 3Qt Quick QML 与 C++ 交互系列之二
- 4自然语言处理在智能客服中的实践与优化
- 5元学习Meta-Learning_元学习的情景训练
- 6一切皆是映射:AI的去中心化:区块链技术的融合
- 7macOS系统安装pycharm社区版本_pycharm社区版本下载mac
- 8火车票预售系统(JavaGUI)_网上购票系统java+gui界面
- 9快速查询的秘籍 —— B+索引的建立_索引 b+ 页中查询
- 10骨架算法(skeleton)的实现_skeleton3d函数图示
Face Anti-Spoofing FAS 综述
赞
踩
Presentation Attacks(PA)
在AntiSpoofing Wiki中对PA进行了详细的划分,总的分为:恶意(下面重点记录)与非恶意。
恶意的PA中分为两类:基于合成的PA和基于人类的PA。
基于合成的PA通常是使用假的肢体部件、合成图像、深度伪造的视频、带特殊纹理的眼镜片(虹膜PA)、遮挡的面部图像,它们可以是静态的、动态的或是混合的。
基于人类的PA通常是活体或者是死物直接呈现给系统(但必须是真实的人),可能是使用活体或者死体的部位,或是模仿攻击
细分的小类中下面仅记录Facial attacks。
面具:现存的面具攻击所使用的面具可能在各方面都极为精致,比如带有放热的硅胶面具,以模拟人体体温。
Deepfake(深度伪造):使用AI,可以对静态图像和动态视频实时实现AI换脸,从而绕过活体检测。
打印的照片:简单粗暴的方式,直接使用照片用于识别。
重播攻击:使用预先录制的结合了Deepfake的视频,投放到高清屏幕上,用于识别。
Presentation Attacks Detection(FAD)
传统方法大多基于:生理活性信号(如:眨眼、头部面部运动等)、人为研究出的特征(在不同的颜色空间中发现伪造的痕迹)。后者也是2018年后的主要研究方向。
生理活性信号可以被高质量的视频伪造,而且不方便部署。
而后产生了基于人工特征+深度学习、端到端深度学习的方法。在此类方法中,FAS通常被视为二分类问题(活体/非活体),使用交叉熵损失函数即可描述训练目标。
但不同于传统的二分类问题(如:性别检测),FAS问题的特征没有语义性(其实就是不可解释),而且非常细节,因此顺理成章地引入CNN用于检测伪造痕迹。但CNN+二分类方法也会学习到无关紧要的伪造痕迹(如:图像边框),而且会出现过拟合状态。
由于大部分的伪造痕迹都和位置感知的辅助任务相关(比如:在面具或照片的表面会出现不和谐的反光等),同时高质量的图像接收放大了这些线索,有利于深度模型的学习。因此,基于上面的辅助任务,学者提出了像素级辅助监督方法、松弛像素级重建约束(对欺骗模式的本质进行建模)。
Face Spoofing Attacks
作者将FSA大致分为两类:数字操作、物理上的表示攻击(PA),作者主要讨论后者,其操作流程大致如下:
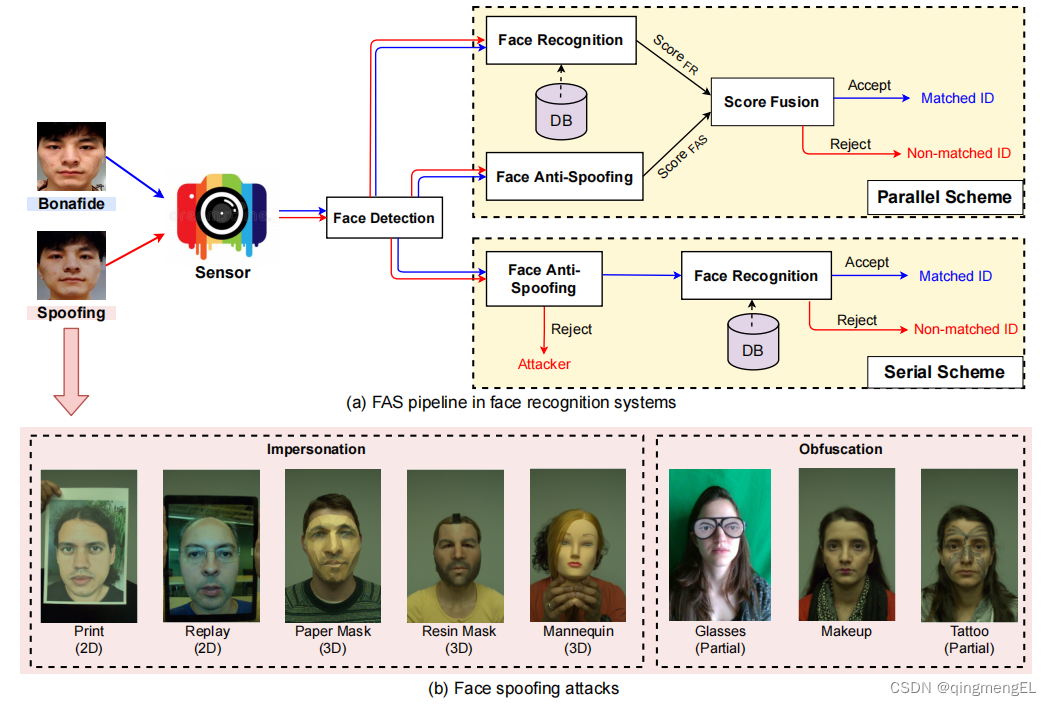
从图(a)中可以看出含FAS的FR(Face Recognition)大致分为两种:并行、串行
- 并行:FR系统和FAS系统分别输出一个得分,经过分数融合输出最终得分,用于判断是否源于活体。
- 串行:先进行FAS系统的活体判断,再进行FR,用于早期FAS。
图(b)中展示了各种PA形式,根据攻击目的,作者将其分为两类:
- 模仿:把真正用户的人脸特征复制到照片、电子屏幕、3D面具等上,欺骗FR系统。
- 混淆:通过眼睛、化妆、假发等抹除自己的身份。
根据几何属性,分为两类:
- 2D:用传感器展示照片和视频来展现面部特征,如:平面/折起来的照片、切割的照片、视频回放。
- 3D:3D面具。
根据覆盖面部的区域大小,分为两类:
- 全部:涉及到整张人脸的替换,如:照片、视频、3D面具。
- 部分:切割的照片、眼睛。
数据集
作者调研了所有公开FAS相关数据集:
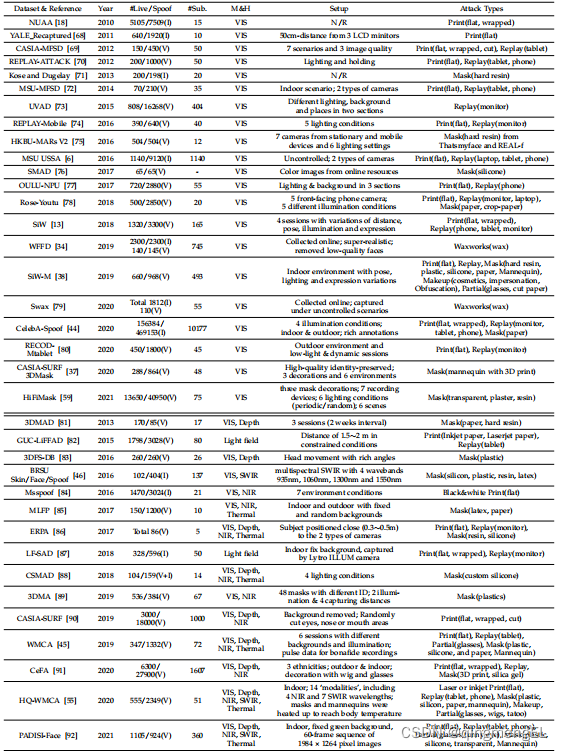
数据集的发展有如下趋势:
- 数据集体量增大。
- 数据分布多样:数据集不再限制于单一攻击方式、取样场景。
- 多模态和特殊传感器:不再局限于RGB摄像机。
评价度量
- 拒识率(FRR):错误拒绝的正确访问。
- 误识率(FAR):错误接受的欺骗访问。
- 半总错误率(HTER):FRR和FAR的平均值
- 等错误率(EER):FRR和FAR相等时的HTER
- AUC:ROC曲线(真阳性率为纵坐标,假阳性率为横坐标)下的面积,表示决策边界的合理性
- 攻击分类错误率(APCER):攻击角度的FAR。
- 真实分类错误率(BPCER):攻击角度的FRR。
- 平均分类错误率(ACER):APCER和BPCER的平均值。
评估协议
每个数据集约定俗成的模型评估方法,由数据集作者提出使用方法,适用于对应数据集,用于判定模型的某些具体性能,作者将协议分为四类:
- 数据集内类内协议(Intra-Dataset Intra-Type Protocol):测试集和训练集基本处在

