
热门标签
热门文章
- 1[图解]SysML和EA建模住宅安全系统-04_sysml案例 ea
- 2idea 换maven项目jdk版本_idea maven 更换项目的jdk
- 3fpga快速入门书籍推荐_fpga入门书推进
- 4实验 5 Spark SQL 编程初级实践
- 5Git忽略已经上传的文件和文件夹_git 忽略文件以及忽略已上传文件
- 6解决哈希碰撞:选择合适的方法优化哈希表性能
- 7idea java 插件开发_IDEA插件开发之环境搭建过程图文详解
- 8《五》Word文件编辑软件调试及测试
- 9ubuntu下faster-whisper安装、基于faster-whisper的语音识别示例、同步生成srt字幕文件_装faster whisper需要卸载whisper吗
- 10大疆 植保无人机T60 评测_大疆t60无人机参数
当前位置: article > 正文
one-stage/two-stage区别_onestage和twostage的区别
作者:Gausst松鼠会 | 2024-05-21 19:40:38
赞
踩
onestage和twostage的区别
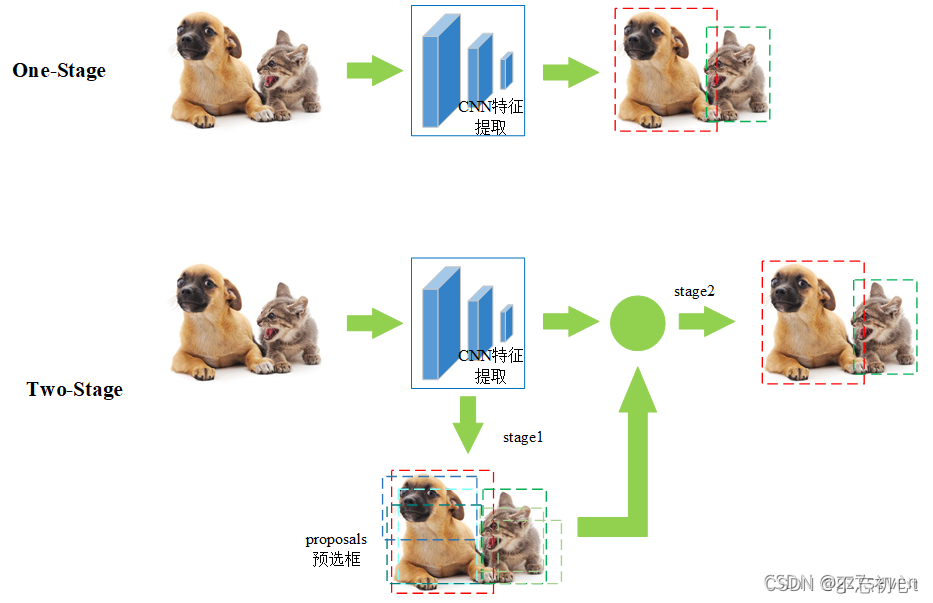
One-stage和Two-stage是目标检测中的两种主要方法,它们在处理速度和准确性上存在显著差异。以下是两者的主要区别:
- 处理流程:One-stage方法通过卷积神经网络直接提取特征,并预测目标的分类与定位,一步到位,速度相对较快。而Two-stage方法则首先进行区域生成,即生成候选区域(Region Proposal),然后再通过卷积神经网络对这些候选区域进行分类和定位,这种分步处理的方式相对较慢。
- 准确性:虽然One-stage方法在速度上具有优势,但其准确性通常低于Two-stage方法。这是因为Two-stage方法通过生成候选区域并对每个区域进行精细处理,能够更准确地识别和定位目标。而One-stage方法则需要在速度和准确性之间进行权衡,通常会牺牲一定的准确性以换取更快的处理速度。
- 网络结构:One-stage方法通常使用单一的网络结构进行特征提取和目标预测,例如YOLO系列网络。而Two-stage方法则通常包含两个网络结构,一个用于生成候选区域,另一个用于对这些区域进行分类和定位,例如Faster R-CNN网络。
需要注意的是,以上区别并非绝对,实际使用中需要根据具体需求和场景进行选择。在某些情况下,One-stage方法可能更适合于实时性要求较高的场景,而Two-stage方法则可能更适合于对准确性要求较高的场景。同时,随着深度学习技术的不断发展,One-stage和Two-stage方法也在不断改进和优化,未来的发展趋势可能会更加注重两者的融合和互补。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/604317
推荐阅读
相关标签

