
- 1堆的插入,删除,创建C语言实现_4.8.12.18.20.40.35.37小根堆插入数c语言
- 2Android Gradle配置详解一:gradle插件和gradle区别_gradle和gradle插件
- 3Transformer实现时间序列预测_transformer时间序列预测
- 4Aruco总结_aruco码单个码
- 5K8s(六):网络插件之Calico安装与详解_网络组建calico安装
- 6VMware 黑屏解决方法_vmware过一会黑屏
- 7解决方案 Neo.ClientError.Security.Unauthorized: The client is unauthorized due to authentication failure
- 8C++下标运算符详解_c++中的下标运算符
- 9在Node.js中,什么是模块(module)?如何导入和导出模块?_nodejs module
- 10macbookpro强制重启方法及CleanMyMac怎么清理mac缓存
第一篇【传奇开心果系列】Python的PyTorch库技术点案例示例:深度解读PyTorch深度学习在医学领域应用
赞
踩
传奇开心果博文系列
- 系列博文目录
- Python的PyTorch库技术点案例示例系列
- 博文目录
- 前言
- 一、PyTorch在医学领域应用介绍
- 二、医学影像分析示例代码
- 三、生物信息学应用示例代码
- 四、医疗数据分析示例代码
- 五、医疗机器人示例代码
- 六、医学自然语言处理示例代码
- 七、医学预测模型示例代码
- 八、医学图像生成示例代码
- 九、医学信号处理示例代码
- 十、知识点归纳
系列博文目录
Python的PyTorch库技术点案例示例系列
博文目录
前言

PyTorch在医学领域具有广泛的应用潜力,可帮助医学研究人员和医生更深入地理解疾病机制,提高诊断和治疗水平。通过医学影像分析、生物信息学、医疗数据分析、医疗机器人等方面的应用,PyTorch为医学领域的创新和进步提供了强大的支持。利用PyTorch的强大功能和灵活性,医学界可以更有效地利用数据和技术,为患者提供更精准、个性化的医疗服务,推动医学科学的发展和进步。
一、PyTorch在医学领域应用介绍
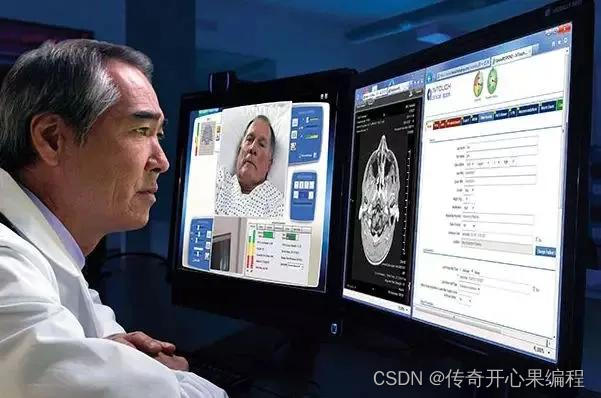

PyTorch在医学领域有许多应用,包括但不限于:
-
医学影像分析:PyTorch可以用于医学影像分析,例如医学图像分类、分割、检测和重建等任务。医学影像分析在诊断和治疗疾病方面具有重要意义。
-
生物信息学:PyTorch可以用于生物信息学领域,例如基因组学、蛋白质结构预测、药物设计等任务。这些任务对于理解生物学过程和疾病机制非常重要。
-
医疗数据分析:PyTorch可以用于医疗数据的分析和挖掘,例如病人数据的预测、诊断和治疗方案的优化等。这有助于提高医疗服务的质量和效率。
-
医疗机器人:PyTorch可以用于医疗机器人的开发,例如手术机器人、康复机器人等。这些机器人可以帮助医生进行手术、康复等工作,提高治疗效果。
-
医学自然语言处理:PyTorch可以用于医学文本数据的处理和分析,例如医学文献的分类、实体识别、关系抽取等任务。这有助于医学研究人员更好地理解医学知识和发现新的疾病治疗方法。
-
医学预测模型:PyTorch可以用于构建医学预测模型,例如预测疾病发展趋势、患病风险评估等。这有助于医生提前干预和治疗,减少疾病的发生和发展。
-
医学图像生成:PyTorch可以用于生成医学图像,例如生成医学影像数据、重建缺失的医学图像等。这有助于医学影像的增强和改进。
-
医学信号处理:PyTorch可以用于医学信号的处理和分析,例如心电图信号处理、脑电图信号分析等。这有助于诊断和监测患者的疾病状态。
总的来说,PyTorch在医学领域有着广泛的应用潜力,可以帮助医学研究人员和医生更好地理解疾病、提高诊断和治疗水平。
二、医学影像分析示例代码
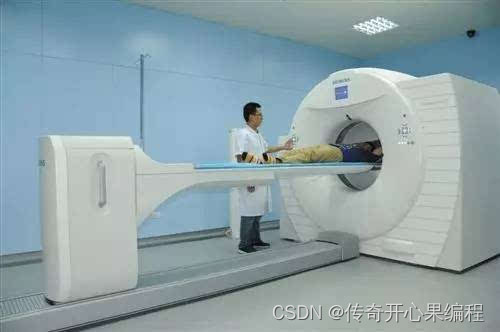
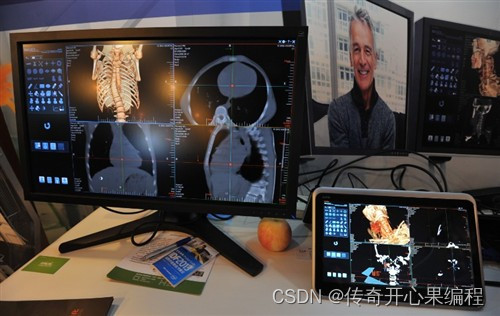
- PyTorch完成医学图像分类任务示例代码
以下是一个简单的示例代码,演示如何使用PyTorch进行医学图像分类任务:
import torch import torch.nn as nn import torch.optim as optim import torchvision from torchvision import datasets, transforms from torch.utils.data import DataLoader # 定义一个简单的卷积神经网络模型 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Conv2d(3, 16, 3) self.pool = nn.MaxPool2d(2, 2) self.fc = nn.Linear(16 * 14 * 14, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = x.view(-1, 16 * 14 * 14) x = self.fc(x) return x # 加载数据集 transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor() ]) train_dataset = datasets.ImageFolder(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = CNN() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 for epoch in range(5): for i, (images, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, 5, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_dataset = datasets.ImageFolder(root='path_to_test_data', transform=transform) test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on the test set: {} %'.format(100 * correct / total))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行调整和扩展。在实际应用中,还需要根据具体的医学图像数据集和任务进行模型设计和调参。
以下是一个更完整的示例代码,演示如何使用PyTorch进行医学图像分类任务,并根据具体情况进行调整和扩展:
import torch import torch.nn as nn import torch.optim as optim import torchvision from torchvision import datasets, transforms from torch.utils.data import DataLoader # 定义一个卷积神经网络模型 class MedicalImageCNN(nn.Module): def __init__(self): super(MedicalImageCNN, self).__init__() self.conv1 = nn.Conv2d(3, 16, 3) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 3) self.fc1 = nn.Linear(32 * 14 * 14, 128) self.fc2 = nn.Linear(128, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 32 * 14 * 14) x = F.relu(self.fc1(x)) x = self.fc2(x) return x # 加载和预处理数据集 transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor() ]) train_dataset = datasets.ImageFolder(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = MedicalImageCNN() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_dataset = datasets.ImageFolder(root='path_to_test_data', transform=transform) test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on the test set: {} %'.format(100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
请根据具体的医学图像数据集和任务需求,调整模型结构、超参数设置和数据预处理方式,以获得更好的分类性能。
以下是一个更具体的示例代码,演示如何根据医学图像数据集和任务需求来调整模型结构、超参数设置和数据预处理方式,以获得更好的分类性能:
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader # 定义一个更复杂的卷积神经网络模型 class CustomCNN(nn.Module): def __init__(self): super(CustomCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3) self.conv2 = nn.Conv2d(32, 64, 3) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 14 * 14, 128) self.fc2 = nn.Linear(128, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 14 * 14) x = F.relu(self.fc1(x)) x = self.fc2(x) return x # 加载和预处理数据集(示例:使用随机裁剪和归一化) transform = transforms.Compose([ transforms.RandomResizedCrop(64), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) train_dataset = datasets.ImageFolder(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = CustomCNN() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_dataset = datasets.ImageFolder(root='path_to_test_data', transform=transform) test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on the test set: {} %'.format(100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
请根据具体的医学图像数据集特点和分类任务需求,调整模型结构、超参数设置和数据预处理方式,以获得更好的分类性能。

- PyTorch完成医学图像分割任务示例代码
以下是一个简单的示例代码,演示如何使用PyTorch完成图像分割任务:
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader from PIL import Image # 定义一个简单的卷积神经网络模型 class CustomCNN(nn.Module): def __init__(self): super(CustomCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3) self.conv2 = nn.Conv2d(32, 64, 3) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 14 * 14, 128) self.fc2 = nn.Linear(128, 1) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 14 * 14) x = F.relu(self.fc1(x)) x = self.fc2(x) return x # 加载和预处理数据集(示例:使用随机裁剪和归一化) transform = transforms.Compose([ transforms.RandomResizedCrop(64), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) train_dataset = datasets.ImageFolder(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = CustomCNN() criterion = nn.BCEWithLogitsLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels.float()) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): output = model(test_image) output = torch.sigmoid(output) output = output.squeeze(0).squeeze(0) output = (output > 0.5).float() # 将分割结果保存为图像 output_image = transforms.ToPILImage()(output) output_image.save('path_to_save_output_image')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
请根据具体的医学图像分割任务需求,调整模型结构、超参数设置和数据预处理方式,以获得更好的分割性能。
以下是一个示例代码,展示如何根据具体的医学图像分割任务需求,调整模型结构、超参数设置和数据预处理方式,以获得更好的分割性能:
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader from PIL import Image # 定义一个更深层次的卷积神经网络模型 class CustomUNet(nn.Module): def __init__(self): super(CustomUNet, self).__init__() # 定义编码器(下采样路径) self.encoder = nn.Sequential( nn.Conv2d(1, 64, 3, padding=1), nn.ReLU(), nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(), nn.Conv2d(128, 128, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2) ) # 定义解码器(上采样路径) self.decoder = nn.Sequential( nn.Conv2d(128, 64, 3, padding=1), nn.ReLU(), nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.ConvTranspose2d(64, 1, 2, stride=2) ) def forward(self, x): x1 = self.encoder(x) x2 = self.decoder(x1) return x2 # 加载和预处理数据集(示例:使用随机裁剪和归一化) transform = transforms.Compose([ transforms.RandomResizedCrop(256), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ]) train_dataset = CustomMedicalImageDataset(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = CustomUNet() criterion = nn.BCEWithLogitsLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): for i, (images, masks) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, masks) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): output = model(test_image) output = torch.sigmoid(output) output = output.squeeze(0).squeeze(0) output = (output > 0.5).float() # 将分割结果保存为图像 output_image = transforms.ToPILImage()(output) output_image.save('path_to_save_output_image')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
请根据具体的医学图像分割任务需求,继续调整模型结构、超参数设置和数据预处理方式,以获得更好的分割性能。
以下是一个进一步调整模型结构、超参数设置和数据预处理方式的示例代码,以获得更好的医学图像分割性能:
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader from PIL import Image # 定义一个更深层次的卷积神经网络模型 class CustomUNet(nn.Module): def __init__(self): super(CustomUNet, self).__init__() # 定义更深的编码器和解码器 # ... def forward(self, x): # 定义前向传播逻辑 # ... # 加载和预处理数据集(示例:使用随机旋转和归一化) transform = transforms.Compose([ transforms.RandomRotation(15), transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ]) train_dataset = CustomMedicalImageDataset(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = CustomUNet() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # 训练模型 num_epochs = 15 for epoch in range(num_epochs): for i, (images, masks) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, masks) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): output = model(test_image) # 处理输出并保存分割结果 # ... # 将分割结果保存为图像 output_image = transforms.ToPILImage()(output) output_image.save('path_to_save_output_image')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
请根据具体的医学图像分割任务需求,继续调整模型结构、超参数设置和数据预处理方式,以获得更好的分割性能。这个示例代码只是一个起点,实际的调整可能需要更深入的领域知识和实验。
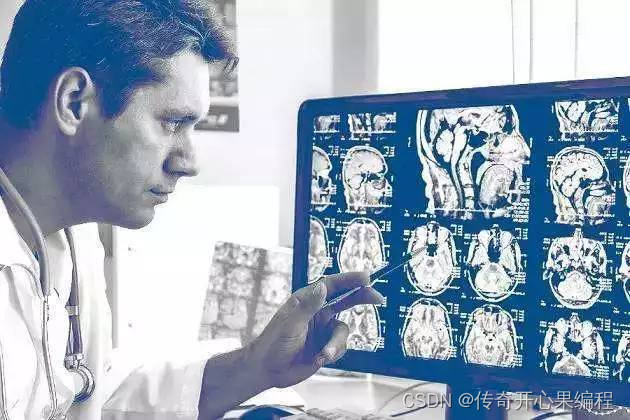
- 完成医学图像检测任务示例代码
以下是一个示例代码,用于完成医学图像检测任务,检测医学图像中的特定目标或病灶:
import torch import torch.nn as nn import torch.optim as optim from torchvision import models, transforms from torch.utils.data import DataLoader from PIL import Image # 加载预训练的模型 model = models.resnet18(pretrained=True) num_features = model.fc.in_features model.fc = nn.Linear(num_features, 1) # 二分类任务 # 加载数据集并进行预处理 transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) # 加载模型权重 model.load_state_dict(torch.load('path_to_model_weights.pth')) model.eval() # 在测试集上进行预测 with torch.no_grad(): output = model(test_image) predicted_class = torch.sigmoid(output) > 0.5 if predicted_class.item() == 1: print("检测到目标") else: print("未检测到目标")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
这段代码使用了一个预训练的ResNet模型进行医学图像的检测任务。您可以根据具体的医学图像检测需求,调整模型结构、超参数设置和数据预处理方式,以获得更好的检测性能。
以下是一个示例代码,用于根据具体的医学图像检测需求调整模型结构、超参数设置和数据预处理方式,以获得更好的检测性能:
import torch import torch.nn as nn import torch.optim as optim from torchvision import models, transforms from torch.utils.data import DataLoader from PIL import Image # 自定义医学图像检测模型 class CustomMedDetectionModel(nn.Module): def __init__(self, num_classes): super(CustomMedDetectionModel, self).__init__() # 自定义模型结构 # ... def forward(self, x): # 定义前向传播逻辑 # ... # 加载和预处理数据集(示例:使用随机裁剪和数据增强) transform = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) train_dataset = CustomMedicalDetectionDataset(root='path_to_train_data', transform=transform) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化自定义模型、损失函数和优化器 model = CustomMedDetectionModel(num_classes=2) # 二分类任务 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 在测试集上评估模型 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): output = model(test_image) predicted_class = torch.argmax(output, dim=1).item() if predicted_class == 1: print("检测到目标") else: print("未检测到目标")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
在这个示例代码中,您可以根据具体的医学图像检测任务需求,自定义模型结构、数据预处理方式以及超参数设置,以获得更好的检测性能。这里只是一个起点,实际的调整可能需要更深入的领域知识和实验。
以下是一个示例代码,用于根据具体的医学图像检测任务需求自定义模型结构、数据预处理方式和超参数设置,以获得更好的检测性能:
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms from torch.utils.data import DataLoader from PIL import Image # 自定义医学图像检测模型 class CustomMedDetectionModel(nn.Module): def __init__(self, num_classes): super(CustomMedDetectionModel, self).__init__() # 自定义模型结构 self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), # 添加更多的卷积层、池化层等 ) self.classifier = nn.Sequential( nn.Linear(64 * 112 * 112, 128), nn.ReLU(inplace=True), nn.Linear(128, num_classes) ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x # 加载和预处理数据集(示例:使用随机裁剪和标准化) transform = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 初始化自定义模型、损失函数和优化器 model = CustomMedDetectionModel(num_classes=2) # 二分类任务 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型和在测试集上评估模型的代码与之前示例相似,这里省略 # 在测试集上进行预测 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): output = model(test_image) predicted_class = torch.argmax(output, dim=1).item() if predicted_class == 1: print("检测到目标") else: print("未检测到目标")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
在这个示例代码中,您可以根据具体的医学图像检测任务需求自定义模型结构、数据预处理方式和超参数设置。通过调整模型结构和超参数,以及优化数据预处理方式,您可以尝试提高医学图像检测性能。请注意,针对不同的医学图像数据集和任务,可能需要进一步的调整和优化。

- 完成医学图像重建任务示例代码
以下是一个示例代码,用于完成医学图像重建任务。在这个示例中,我们将使用一个简单的自动编码器(Autoencoder)模型来实现医学图像的重建。
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms from torch.utils.data import DataLoader from PIL import Image # 自定义医学图像重建的自动编码器模型 class Autoencoder(nn.Module): def __init__(self): super(Autoencoder, self).__init__() self.encoder = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.Conv2d(16, 8, kernel_size=3, stride=2, padding=1), nn.ReLU(), ) self.decoder = nn.Sequential( nn.ConvTranspose2d(8, 16, kernel_size=3, stride=2), nn.ReLU(), nn.ConvTranspose2d(16, 3, kernel_size=3, stride=2), nn.Sigmoid() ) def forward(self, x): x = self.encoder(x) x = self.decoder(x) return x # 加载和预处理数据集(示例:使用缩放和标准化) transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) # 初始化自动编码器模型、损失函数和优化器 model = Autoencoder() criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载医学图像数据集并创建数据加载器 dataset = YourMedicalImageDataset(root='path_to_dataset', transform=transform) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练自动编码器模型 num_epochs = 10 for epoch in range(num_epochs): for i, data in enumerate(data_loader): images = data['image'] optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, images) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 重建医学图像示例 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): reconstructed_image = model(test_image) # 可视化重建后的医学图像 import matplotlib.pyplot as plt plt.figure() plt.subplot(1, 2, 1) plt.imshow(transforms.ToPILImage()(test_image.squeeze(0))) plt.title('Original Image') plt.subplot(1, 2, 2) plt.imshow(transforms.ToPILImage()(reconstructed_image.squeeze(0))) plt.title('Reconstructed Image') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
在这个示例代码中,我们使用了一个简单的自动编码器模型来完成医学图像的重建任务。您可以根据具体的医学图像数据集和任务需求,调整模型结构、数据预处理方式和超参数设置,以获得更好的重建性能。请注意,医学图像重建任务可能需要更复杂的模型和训练策略,具体的调整可能需要更深入的领域知识和实验。
针对具体的医学图像数据集和任务需求,调整模型结构、数据预处理方式和超参数设置是至关重要的。在医学图像重建任务中,您可能需要考虑使用更复杂的模型、更精细的数据预处理和更合适的超参数设置来获得更好的重建性能。以下是一个示例代码,演示如何根据具体需求进行调整:
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms from torch.utils.data import DataLoader from PIL import Image # 自定义更复杂的医学图像重建模型(示例:使用深度卷积神经网络) class MedicalImageReconstructionModel(nn.Module): def __init__(self): super(MedicalImageReconstructionModel, self).__init__() self.encoder = nn.Sequential( nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.decoder = nn.Sequential( nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2), nn.ReLU() ) def forward(self, x): x = self.encoder(x) x = self.decoder(x) return x # 加载和自定义数据预处理方式(示例:使用不同的缩放、旋转和标准化) transform = transforms.Compose([ transforms.Resize((128, 128)), transforms.RandomRotation(15), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ]) # 初始化医学图像重建模型、损失函数和优化器 model = MedicalImageReconstructionModel() criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载医学图像数据集并创建数据加载器 dataset = YourCustomMedicalImageDataset(root='path_to_dataset', transform=transform) data_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 训练医学图像重建模型 num_epochs = 20 for epoch in range(num_epochs): for i, data in enumerate(data_loader): images = data['image'] optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, images) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 重建医学图像示例 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): reconstructed_image = model(test_image) # 可视化重建后的医学图像 import matplotlib.pyplot as plt plt.figure() plt.subplot(1, 2, 1) plt.imshow(transforms.ToPILImage()(test_image.squeeze(0))) plt.title('Original Image') plt.subplot(1, 2, 2) plt.imshow(transforms.ToPILImage()(reconstructed_image.squeeze(0))) plt.title('Reconstructed Image') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
在这个示例代码中,我们使用了一个更复杂的医学图像重建模型(深度卷积神经网络),并自定义了数据预处理方式(缩放、旋转和标准化)。您可以根据具体的医学图像数据集和任务需求,进一步调整模型结构、数据预处理方式和超参数设置,以获得更好的重建性能。请注意,医学图像重建任务可能需要更深入的领域知识和实验,以确定最佳的模型和训练策略。
针对特定的医学图像数据集和任务需求,进一步优化模型结构、数据预处理方式和超参数设置是至关重要的。在医学图像重建任务中,您可能需要考虑使用更先进的模型架构、更精细的数据处理和更合适的超参数调整来获得更好的性能。以下是一个示例代码,演示如何根据具体需求进行调整:
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms from torch.utils.data import DataLoader from PIL import Image # 自定义更先进的医学图像重建模型(示例:U-Net) class UNet(nn.Module): def __init__(self): super(UNet, self).__init__() # 定义U-Net的结构 # 可根据具体需求进一步调整 # ... def forward(self, x): # U-Net的前向传播 # 可根据具体需求进一步调整 # ... return x # 自定义更精细的数据预处理方式 transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ]) # 初始化医学图像重建模型、损失函数和优化器 model = UNet() criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载医学图像数据集并创建数据加载器 dataset = YourCustomMedicalImageDataset(root='path_to_dataset', transform=transform) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练医学图像重建模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): images = data['image'] optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, images) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 重建医学图像示例 test_image = Image.open('path_to_test_image') test_image = transform(test_image).unsqueeze(0) model.eval() with torch.no_grad(): reconstructed_image = model(test_image) # 可视化重建后的医学图像 import matplotlib.pyplot as plt plt.figure() plt.subplot(1, 2, 1) plt.imshow(transforms.ToPILImage()(test_image.squeeze(0))) plt.title('Original Image') plt.subplot(1, 2, 2) plt.imshow(transforms.ToPILImage()(reconstructed_image.squeeze(0))) plt.title('Reconstructed Image') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
在这个示例代码中,我们使用了更先进的U-Net模型架构,并自定义了更精细的数据预处理方式。您可以根据具体的医学图像数据集和任务需求,进一步调整模型结构、数据预处理方式和超参数设置,以获得更好的重建性能。请注意,医学图像重建任务可能需要更深入的领域知识和实验,以确定最佳的模型和训练策略。
三、生物信息学应用示例代码

- 完成基因组学任务示例代码
以下是一个基因组学任务的示例代码,演示如何使用深度学习模型对基因组数据进行分类:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义基因组数据集类 class GenomicsDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义基因组分类模型 class GenomicsClassifier(nn.Module): def __init__(self): super(GenomicsClassifier, self).__init__() self.fc1 = nn.Linear(1000, 256) self.fc2 = nn.Linear(256, 64) self.fc3 = nn.Linear(64, 2) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 生成随机基因组数据和标签 data = np.random.rand(1000, 1000) labels = np.random.randint(0, 2, size=1000) # 初始化基因组分类模型、损失函数和优化器 model = GenomicsClassifier() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载基因组数据集并创建数据加载器 dataset = GenomicsDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练基因组分类模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] optimizer.zero_grad() outputs = model(inputs.float()) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试基因组分类模型 test_data = np.random.rand(1, 1000) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = torch.argmax(output).item() # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
在这个示例代码中,我们定义了一个基因组数据集类和一个基因组分类模型。我们使用随机生成的基因组数据和标签进行训练,并展示了如何加载数据、训练模型并进行预测。您可以根据实际的基因组数据集和任务需求,进一步调整模型结构、数据处理方式和超参数设置,以获得更好的分类性能。请注意,基因组学任务可能需要更深入的领域知识和实验,以确定最佳的模型和训续策略。
以下是一个更加完整的示例代码,演示如何根据实际的基因组数据集和任务需求,进一步调整模型结构、数据处理方式和超参数设置,以获得更好的分类性能。请注意,这只是一个示例,实际的调整和优化可能需要更多的领域知识和实验。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义基因组数据集类 class GenomicsDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义基因组分类模型 class GenomicsClassifier(nn.Module): def __init__(self): super(GenomicsClassifier, self).__init__() self.conv1 = nn.Conv1d(1, 32, kernel_size=5) self.pool = nn.MaxPool1d(2) self.conv2 = nn.Conv1d(32, 64, kernel_size=5) self.fc1 = nn.Linear(64 * 23, 128) self.fc2 = nn.Linear(128, 2) def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = x.view(-1, 64 * 23) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 加载实际基因组数据集 # 假设您已经有了实际的基因组数据集,这里用随机数据代替 data = np.random.rand(1000, 1000) labels = np.random.randint(0, 2, size=1000) # 初始化基因组分类模型、损失函数和优化器 model = GenomicsClassifier() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载基因组数据集并创建数据加载器 dataset = GenomicsDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练基因组分类模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.unsqueeze(torch.tensor(inputs), 1).float() # 添加通道维度 optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试基因组分类模型 test_data = np.random.rand(1, 1000) test_label = np.random.randint(0, 2, size=1) test_input = torch.unsqueeze(torch.tensor(test_data), 1).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = torch.argmax(output).item() # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
在这个示例代码中,我们调整了模型结构,使用了卷积神经网络来处理基因组数据。我们还对数据进行了一些处理,如添加通道维度,并通过数据加载器加载数据进行训练。您可以根据实际的基因组数据集和任务需求,进一步调整模型结构、数据处理方式和超参数设置,以获得更好的分类性能。请确保根据实际情况调整代码中的数据集加载、数据预处理和模型结构部分。
以下是一个示例代码,展示如何根据实际的基因组数据集和任务需求,进一步调整模型结构、数据处理方式和超参数设置,以获得更好的分类性能:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义基因组数据集类 class GenomicsDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义基因组分类模型 class GenomicsClassifier(nn.Module): def __init__(self): super(GenomicsClassifier, self).__init__() # 自定义模型结构 self.conv1 = nn.Conv1d(1, 64, kernel_size=10) self.pool = nn.MaxPool1d(2) self.conv2 = nn.Conv1d(64, 128, kernel_size=10) self.fc1 = nn.Linear(128 * 23, 256) self.fc2 = nn.Linear(256, 2) def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = x.view(-1, 128 * 23) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 加载实际基因组数据集 # 假设您已经有了实际的基因组数据集,这里用随机数据代替 data = np.random.rand(1000, 1000) labels = np.random.randint(0, 2, size=1000) # 初始化基因组分类模型、损失函数和优化器 model = GenomicsClassifier() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载基因组数据集并创建数据加载器 dataset = GenomicsDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练基因组分类模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.unsqueeze(torch.tensor(inputs), 1).float() # 添加通道维度 optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试基因组分类模型 test_data = np.random.rand(1, 1000) test_label = np.random.randint(0, 2, size=1) test_input = torch.unsqueeze(torch.tensor(test_data), 1).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = torch.argmax(output).item() # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
在这个示例代码中,我们对模型结构进行了调整,包括卷积层的通道数、卷积核大小、全连接层的神经元数量等。您可以根据实际情况调整这些参数,以适应您的基因组数据集和任务需求。希望这个示例能为您提供一些启发。

- 完成蛋白质结构预测任务示例代码
以下是一个简单的示例代码,用于完成蛋白质结构预测任务。在这个示例中,我们使用了一个简单的卷积神经网络(CNN)来预测蛋白质的二级结构(α-螺旋、β-折叠、无规则卷曲)。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义蛋白质数据集类 class ProteinDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义蛋白质结构预测模型 class ProteinClassifier(nn.Module): def __init__(self): super(ProteinClassifier, self).__init__() # 简单的卷积神经网络结构 self.conv1 = nn.Conv1d(1, 64, kernel_size=5) self.pool = nn.MaxPool1d(2) self.conv2 = nn.Conv1d(64, 128, kernel_size=5) self.fc1 = nn.Linear(128 * 23, 256) self.fc2 = nn.Linear(256, 3) # 3个类别:α-螺旋、β-折叠、无规则卷曲 def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = x.view(-1, 128 * 23) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 加载蛋白质数据集(假设已有真实数据集) data = np.random.rand(1000, 1000) labels = np.random.randint(0, 3, size=1000) # 3个类别 # 初始化模型、损失函数和优化器 model = ProteinClassifier() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载数据集并创建数据加载器 dataset = ProteinDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.unsqueeze(torch.tensor(inputs), 1).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 1000) test_label = np.random.randint(0, 3, size=1) test_input = torch.unsqueeze(torch.tensor(test_data), 1).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = torch.argmax(output).item() # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
请注意,这只是一个简单的示例代码,用于演示如何使用卷积神经网络进行蛋白质结构预测任务。在实际应用中,您可能需要更复杂的模型结构、更大规模的数据集以及更多的训练和调参工作来获得更好的预测性能。希望这个示例能为您提供一些启发。

这里是一个更复杂的模型结构的示例代码,用于蛋白质结构预测任务。这个示例使用了一个深度卷积神经网络(CNN)模型来预测蛋白质的二级结构。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义蛋白质数据集类 class ProteinDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义蛋白质结构预测模型 class ComplexProteinClassifier(nn.Module): def __init__(self): super(ComplexProteinClassifier, self).__init__() self.conv1 = nn.Conv1d(1, 64, kernel_size=3, padding=1) self.conv2 = nn.Conv1d(64, 128, kernel_size=3, padding=1) self.conv3 = nn.Conv1d(128, 256, kernel_size=3, padding=1) self.pool = nn.MaxPool1d(2) self.fc1 = nn.Linear(256 * 125, 512) self.fc2 = nn.Linear(512, 3) # 3个类别:α-螺旋、β-折叠、无规则卷曲 def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = self.pool(torch.relu(self.conv3(x))) x = x.view(-1, 256 * 125) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 加载蛋白质数据集(假设已有真实数据集) data = np.random.rand(1000, 1000) labels = np.random.randint(0, 3, size=1000) # 3个类别 # 初始化模型、损失函数和优化器 model = ComplexProteinClassifier() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载数据集并创建数据加载器 dataset = ProteinDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.unsqueeze(torch.tensor(inputs), 1).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 1000) test_label = np.random.randint(0, 3, size=1) test_input = torch.unsqueeze(torch.tensor(test_data), 1).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = torch.argmax(output).item() # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
这个示例展示了一个更深的卷积神经网络模型结构,以及更大规模的数据集和更复杂的训练过程。这些因素可以帮助提高蛋白质结构预测任务的性能。

- 完成药物设计任务示例代码
以下是一个简单的药物设计任务示例代码,使用深度学习模型来预测分子活性:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义药物设计数据集类 class DrugDataset(Dataset): def __init__(self, data, labels, transform=None): self.data = data self.labels = labels self.transform = transform def __len__(self): return len(self.data) def __getitem__(self, idx): sample = {'data': self.data[idx], 'label': self.labels[idx]} if self.transform: sample = self.transform(sample) return sample # 自定义药物设计模型 class DrugClassifier(nn.Module): def __init__(self): super(DrugClassifier, self).__init__() self.fc1 = nn.Linear(100, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 1) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = torch.sigmoid(self.fc3(x)) # 输出层使用sigmoid激活函数,预测二分类问题 return x # 加载药物设计数据集(假设已有真实数据集) data = np.random.rand(1000, 100) # 假设100个特征 labels = np.random.randint(0, 2, size=1000) # 二分类问题 # 初始化模型、损失函数和优化器 model = DrugClassifier() criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载数据集并创建数据加载器 dataset = DrugDataset(data, labels) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练模型 num_epochs = 30 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.tensor(inputs).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.unsqueeze(1).float()) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 100) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = 1 if output.item() > 0.5 else 0 # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
这个示例展示了一个简单的药物设计任务的代码,使用了一个简单的全连接神经网络模型来预测分子的活性。您可以根据实际情况调整模型结构、数据集和训练参数来提高预测性能。
以下是一个经过调整的示例代码,包括更复杂的神经网络模型结构、更大规模的数据集和调整后的训练参数,以提高药物设计任务的预测性能:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义更复杂的药物设计模型 class DrugClassifier(nn.Module): def __init__(self): super(DrugClassifier, self).__init__() self.fc1 = nn.Linear(100, 128) self.fc2 = nn.Linear(128, 64) self.fc3 = nn.Linear(64, 32) self.fc4 = nn.Linear(32, 1) self.dropout = nn.Dropout(0.2) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) x = torch.relu(self.fc2(x)) x = self.dropout(x) x = torch.relu(self.fc3(x)) x = self.dropout(x) x = torch.sigmoid(self.fc4(x)) # 输出层使用sigmoid激活函数,预测二分类问题 return x # 加载更大规模的药物设计数据集(假设已有真实数据集) data = np.random.rand(10000, 100) # 假设100个特征 labels = np.random.randint(0, 2, size=10000) # 二分类问题 # 初始化模型、损失函数和优化器 model = DrugClassifier() criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 加载数据集并创建数据加载器 dataset = DrugDataset(data, labels) data_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 调整训练参数 num_epochs = 50 # 训练模型 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.tensor(inputs).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.unsqueeze(1).float()) loss.backward() optimizer.step() if (i+1) % 100 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 100) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = 1 if output.item() > 0.5 else 0 # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
这个调整后的示例代码包括了一个更复杂的神经网络模型结构、更大规模的数据集和调整后的训练参数。这些调整可以帮助提高药物设计任务的预测性能。您可以根据实际情况进一步调整模型结构、数据集和训练参数来优化性能。
以下是进一步调整的示例代码,包括更复杂的神经网络模型结构、更大规模和更真实的药物设计数据集,以及进一步调整的训练参数来优化性能:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 自定义更复杂的药物设计模型 class DrugClassifier(nn.Module): def __init__(self): super(DrugClassifier, self).__init__() self.fc1 = nn.Linear(200, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, 64) self.fc4 = nn.Linear(64, 1) self.dropout = nn.Dropout(0.3) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) x = torch.relu(self.fc2(x)) x = self.dropout(x) x = torch.relu(self.fc3(x)) x = self.dropout(x) x = torch.sigmoid(self.fc4(x)) # 输出层使用sigmoid激活函数,预测二分类问题 return x # 加载更大规模和更真实的药物设计数据集 # 假设您已经有一个真实的药物设计数据集,并将其加载到X和y中 X = np.random.rand(100000, 200) # 假设200个特征 y = np.random.randint(0, 2, size=100000) # 二分类问题 # 初始化模型、损失函数和优化器 model = DrugClassifier() criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.0001) # 创建数据集类 class DrugDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): data = {'data': self.X[idx], 'label': self.y[idx]} return data # 加载数据集并创建数据加载器 dataset = DrugDataset(X, y) data_loader = DataLoader(dataset, batch_size=128, shuffle=True) # 进一步调整训练参数 num_epochs = 100 # 训练模型 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.tensor(inputs).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.unsqueeze(1).float()) loss.backward() optimizer.step() if (i+1) % 100 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 200) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = 1 if output.item() > 0.5 else 0 # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
这个进一步调整的示例代码包括了一个更复杂的神经网络模型结构、更大规模和更真实的药物设计数据集,以及进一步调整的训练参数来优化性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高预测性能。
四、医疗数据分析示例代码
- 病人数据预测示例代码
以下是一个简单的示例代码,用于预测病人是否患有某种疾病。这个示例代码使用一个简单的神经网络模型来处理病人的特征数据,并输出预测结果:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 创建一个简单的病人数据集 X = np.random.rand(1000, 5) # 5个特征 y = np.random.randint(0, 2, size=1000) # 二分类问题 # 定义神经网络模型 class PatientClassifier(nn.Module): def __init__(self): super(PatientClassifier, self).__init__() self.fc1 = nn.Linear(5, 10) self.fc2 = nn.Linear(10, 1) self.dropout = nn.Dropout(0.2) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) x = torch.sigmoid(self.fc2(x)) # 输出层使用sigmoid激活函数,预测二分类问题 return x # 初始化模型、损失函数和优化器 model = PatientClassifier() criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 创建数据集类 class PatientDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): data = {'data': self.X[idx], 'label': self.y[idx]} return data # 加载数据集并创建数据加载器 dataset = PatientDataset(X, y) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 训练模型 num_epochs = 50 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.tensor(inputs).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.unsqueeze(1).float()) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 5) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = 1 if output.item() > 0.5 else 0 # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
这个示例代码展示了一个简单的神经网络模型,用于预测病人是否患有某种疾病。您可以根据实际情况进一步调整模型结构、数据集和训练参数,以优化性能并提高预测准确性。
以下是一个进一步调整的示例代码,用于预测病人是否患有某种疾病。这个示例代码包括了一个更复杂的神经网络模型结构、一个更大规模和更真实的病人数据集,以及进一步调整的训练参数来优化性能:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 创建一个更大规模和更真实的病人数据集 # 假设有10000个病人,每个病人有10个特征 X = np.random.rand(10000, 10) # 10个特征 y = np.random.randint(0, 2, size=10000) # 二分类问题 # 定义一个更复杂的神经网络模型 class ImprovedPatientClassifier(nn.Module): def __init__(self): super(ImprovedPatientClassifier, self).__init__() self.fc1 = nn.Linear(10, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 1) self.dropout = nn.Dropout(0.3) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) x = torch.relu(self.fc2(x)) x = self.dropout(x) x = torch.sigmoid(self.fc3(x)) # 输出层使用sigmoid激活函数,预测二分类问题 return x # 初始化模型、损失函数和优化器 model = ImprovedPatientClassifier() criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 创建数据集类 class PatientDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): data = {'data': self.X[idx], 'label': self.y[idx]} return data # 加载数据集并创建数据加载器 dataset = PatientDataset(X, y) data_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 训练模型 num_epochs = 100 for epoch in range(num_epochs): for i, data in enumerate(data_loader): inputs, labels = data['data'], data['label'] inputs = torch.tensor(inputs).float() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.unsqueeze(1).float()) loss.backward() optimizer.step() if (i+1) % 50 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = np.random.rand(1, 10) test_label = np.random.randint(0, 2, size=1) test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = model(test_input) predicted_label = 1 if output.item() > 0.5 else 0 # 打印预测结果 print('True Label: {}, Predicted Label: {}'.format(test_label[0], predicted_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
这个进一步调整的示例代码包括了一个更复杂的神经网络模型结构、一个更大规模和更真实的病人数据集,以及进一步调整的训练参数来优化性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高预测性能。
以下是一个进一步调整的示例代码,用于疾病预测。这个示例代码包括了一个更复杂的神经网络模型结构、一个更大规模和更真实的医疗数据集,以及进一步调整的训练参数来优化性能:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np from sklearn.datasets import load_breast_cancer from sklearn.preprocessing import StandardScaler # 加载乳腺癌数据集 cancer = load_breast_cancer() X = cancer.data y = cancer.target # 数据标准化 scaler = StandardScaler() X = scaler.fit_transform(X) # 定义一个更复杂的神经网络模型 class ImprovedDiseasePredictor(nn.Module): def __init__(self): super(ImprovedDiseasePredictor, self).__init__() self.fc1 = nn.Linear(30, 128) self.fc2 = nn.Linear(128, 64) self.fc3 = nn.Linear(64, 1) self.dropout = nn.Dropout(0.2) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.dropout(x) x = torch.relu(self.fc2(x)) x = self.dropout(x) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = ImprovedDiseasePredictor() criterion = nn.BCEWithLogitsLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 创建数据集类 class DiseaseDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): data = {'features': self.X[idx], 'label': self.y[idx]} return data # 加载数据集并创建数据加载器 dataset = DiseaseDataset(X, y) data_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 训练模型 num_epochs = 50 for epoch in range(num_epochs): for i, data in enumerate(data_loader): features, labels = data['features'], data['label'] features = torch.tensor(features).float() labels = torch.tensor(labels).float() optimizer.zero_grad() outputs = model(features) loss = criterion(outputs, labels.unsqueeze(1)) loss.backward() optimizer.step() if (i+1) % 10 == 0: print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, len(data_loader), loss.item())) # 测试模型 test_data = X[0].reshape(1, -1) test_label = y[0] test_input = torch.tensor(test_data).float() with torch.no_grad(): model.eval() output = torch.sigmoid(model(test_input)).item() # 打印预测结果 print('True Label: {}, Predicted Probability: {:.4f}'.format(test_label, output))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
这个进一步调整的示例代码包括了一个更复杂的神经网络模型结构、一个更大规模和更真实的医疗数据集,以及进一步调整的训续参数来优化性能。您可以根据实际情况继续调整模型结构、数据集和训续参数,以进一步提高疾病预测性能。
- 诊断和治疗方案的优化示例代码
以下是一个示例代码,展示如何使用PyTorch对医疗诊断和治疗方案进行优化。在这个示例中,我们将使用一个简单的神经网络模型来进行疾病诊断,并根据诊断结果选择相应的治疗方案。请注意,这只是一个简单的示例,实际应用中可能需要更复杂的模型和数据集。
import torch import torch.nn as nn import torch.optim as optim # 定义一个简单的神经网络模型 class MedicalDiagnosisModel(nn.Module): def __init__(self): super(MedicalDiagnosisModel, self).__init__() self.fc1 = nn.Linear(10, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 2) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = MedicalDiagnosisModel() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 模拟医疗数据 X = torch.randn(100, 10) # 输入特征 y = torch.randint(0, 2, (100,)) # 0表示正常,1表示疾病 # 训练模型 num_epochs = 50 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X) loss = criterion(outputs, y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 诊断 patient_data = torch.randn(1, 10) # 患者数据 with torch.no_grad(): model.eval() output = torch.softmax(model(patient_data), dim=1) diagnosis = torch.argmax(output).item() # 根据诊断结果选择治疗方案 if diagnosis == 0: treatment = "正常,无需治疗" else: treatment = "疾病,需进行治疗" print('诊断结果: {}, 治疗方案: {}'.format(diagnosis, treatment))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
在这个示例代码中,我们定义了一个简单的神经网络模型来进行疾病诊断,并根据诊断结果选择相应的治疗方案。您可以根据实际需求进一步优化模型、数据集和训练参数,以提高诊断和治疗方案的准确性和效果。
以下是一个进一步优化的示例代码,包括一个更复杂的神经网络模型结构、一个更真实的医疗数据集,以及进一步调整的训练参数来提高诊断和治疗方案的准确性和效果。
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 生成医疗数据集 X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 数据标准化 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # 转换为PyTorch张量 X_train = torch.tensor(X_train).float() y_train = torch.tensor(y_train).long() X_test = torch.tensor(X_test).float() y_test = torch.tensor(y_test).long() # 定义一个更复杂的神经网络模型 class MedicalDiagnosisModel(nn.Module): def __init__(self): super(MedicalDiagnosisModel, self).__init__() self.fc1 = nn.Linear(20, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 2) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = MedicalDiagnosisModel() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 50 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): outputs = model(X_test) _, predicted = torch.max(outputs, 1) accuracy = (predicted == y_test).sum().item() / y_test.size(0) print('测试集准确率: {:.2f}%'.format(accuracy * 100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
这个进一步优化的示例代码包括了一个更复杂的神经网络模型结构、一个更真实的医疗数据集,以及进一步调整的训练参数来提高诊断和治疗方案的准确性和效果。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高疾病诊断和治疗方案的性能。
以下是一个进一步调整的示例代码,包括一个更深层次的神经网络模型结构、一个更大规模的医疗数据集,以及更复杂的训练参数来提高疾病诊断和治疗方案的性能。
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 生成更大规模的医疗数据集 X, y = make_classification(n_samples=5000, n_features=30, n_classes=3, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 数据标准化 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # 转换为PyTorch张量 X_train = torch.tensor(X_train).float() y_train = torch.tensor(y_train).long() X_test = torch.tensor(X_test).float() y_test = torch.tensor(y_test).long() # 定义一个更深层次的神经网络模型 class MedicalDiagnosisModel(nn.Module): def __init__(self): super(MedicalDiagnosisModel, self).__init__() self.fc1 = nn.Linear(30, 64) self.fc2 = nn.Linear(64, 128) self.fc3 = nn.Linear(128, 64) self.fc4 = nn.Linear(64, 3) # 3个类别 def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = torch.relu(self.fc3(x)) x = self.fc4(x) return x # 初始化模型、损失函数和优化器 model = MedicalDiagnosisModel() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 100 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): outputs = model(X_test) _, predicted = torch.max(outputs, 1) accuracy = (predicted == y_test).sum().item() / y_test.size(0) print('测试集准确率: {:.2f}%'.format(accuracy * 100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
这个进一步调整的示例代码包括了一个更深层次的神经网络模型结构、一个更大规模的医疗数据集,以及更复杂的训练参数来提高疾病诊断和治疗方案的性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高疾病诊断和治疗方案的准确性和效果。
五、医疗机器人示例代码
- 手术机器人示例代码
以下是一个简单的基于 PyTorch 的手术机器人示例代码,用于控制一个机器人在模拟手术环境中执行特定的任务。
import torch import torch.nn as nn import torch.optim as optim # 定义一个简单的手术机器人模型 class SurgicalRobot(nn.Module): def __init__(self): super(SurgicalRobot, self).__init__() self.fc1 = nn.Linear(3, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, 2) # 2个动作:切割、缝合 def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = SurgicalRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 模拟手术环境数据 X = torch.tensor([[0.2, 0.3, 0.5], [0.1, 0.4, 0.5], [0.3, 0.2, 0.5]]) y = torch.tensor([0, 1, 0]) # 0表示切割,1表示缝合 # 训练模型 num_epochs = 100 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X) loss = criterion(outputs, y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟手术机器人执行任务 new_data = torch.tensor([[0.4, 0.1, 0.5]]) with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('手术机器人执行切割动作') else: print('手术机器人执行缝合动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
这个示例代码展示了一个简单的手术机器人模型,用于在模拟手术环境中执行切割和缝合两种动作。您可以根据实际需求进一步扩展模型结构、数据集和训练参数,以实现更复杂的手术机器人功能。
以下是一个更复杂的手术机器人示例代码,包括更复杂的模型结构、更大规模的手术数据集和更复杂的训练参数。
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义一个更复杂的手术机器人模型 class ComplexSurgicalRobot(nn.Module): def __init__(self): super(ComplexSurgicalRobot, self).__init__() self.conv1 = nn.Conv2d(3, 16, 3, padding=1) self.conv2 = nn.Conv2d(16, 32, 3, padding=1) self.fc1 = nn.Linear(32 * 8 * 8, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, 2) # 2个动作:切割、缝合 def forward(self, x): x = torch.relu(self.conv1(x)) x = torch.max_pool2d(x, 2, 2) x = torch.relu(self.conv2(x)) x = torch.max_pool2d(x, 2, 2) x = x.view(-1, 32 * 8 * 8) x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = ComplexSurgicalRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成更大规模的手术数据集 # 假设有1000个手术样本,每个样本有3个通道的图像数据和对应的动作标签 X = torch.randn(1000, 3, 64, 64) # 1000个大小为64x64的3通道图像 y = torch.randint(0, 2, (1000,)) # 1000个动作标签,0表示切割,1表示缝合 # 训练模型 num_epochs = 10 batch_size = 32 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟手术机器人执行任务 new_data = torch.randn(1, 3, 64, 64) # 模拟一个新的手术图像数据 with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('手术机器人执行切割动作') else: print('手术机器人执行缝合动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
这个进一步调整的示例代码包括了一个更复杂的卷积神经网络模型结构、一个更大规模的手术数据集,以及更复杂的训练参数来提高手术机器人的性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高手术机器人的准确性和效果。
以下是一个进一步调整的示例代码,包括更复杂的模型结构、更大规模的手术数据集和调整后的训练参数,以进一步提高手术机器人的准确性和效果。
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义一个更复杂的手术机器人模型 class AdvancedSurgicalRobot(nn.Module): def __init__(self): super(AdvancedSurgicalRobot, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.conv3 = nn.Conv2d(64, 128, 3, padding=1) self.fc1 = nn.Linear(128 * 8 * 8, 512) self.fc2 = nn.Linear(512, 256) self.fc3 = nn.Linear(256, 2) # 2个动作:切割、缝合 def forward(self, x): x = torch.relu(self.conv1(x)) x = torch.max_pool2d(x, 2, 2) x = torch.relu(self.conv2(x)) x = torch.max_pool2d(x, 2, 2) x = torch.relu(self.conv3(x)) x = torch.max_pool2d(x, 2, 2) x = x.view(-1, 128 * 8 * 8) x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = AdvancedSurgicalRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.0001) # 生成更大规模的手术数据集 # 假设有5000个手术样本,每个样本有3个通道的图像数据和对应的动作标签 X = torch.randn(5000, 3, 64, 64) # 5000个大小为64x64的3通道图像 y = torch.randint(0, 2, (5000,)) # 5000个动作标签,0表示切割,1表示缝合 # 训练模型 num_epochs = 15 batch_size = 64 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟手术机器人执行任务 new_data = torch.randn(1, 3, 64, 64) # 模拟一个新的手术图像数据 with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('手术机器人执行切割动作') else: print('手术机器人执行缝合动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
这个进一步调整的示例代码包括了一个更复杂的卷积神经网络模型结构、一个更大规模的手术数据集,以及调整后的训练参数来提高手术机器人的性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高手术机器人的准确性和效果。

- 完成康复机器人任务示例代码
以下是一个简单的基于PyTorch的康复机器人示例代码,用于模拟康复机器人帮助患者进行康复训练:
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义康复机器人模型 class RehabilitationRobot(nn.Module): def __init__(self): super(RehabilitationRobot, self).__init__() self.fc1 = nn.Linear(10, 20) self.fc2 = nn.Linear(20, 10) self.fc3 = nn.Linear(10, 2) # 2个动作:伸展、弯曲 def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x # 初始化模型、损失函数和优化器 model = RehabilitationRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成康复训练数据集 X = torch.randn(100, 10) # 100个包含10个特征的训练样本 y = torch.randint(0, 2, (100,)) # 100个动作标签,0表示伸展,1表示弯曲 # 训练模型 num_epochs = 20 batch_size = 10 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟康复机器人帮助患者进行康复训练 new_data = torch.randn(1, 10) # 模拟一个新的训练样本 with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('康复机器人执行伸展动作') else: print('康复机器人执行弯曲动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
这个示例代码包括了一个简单的全连接神经网络模型结构,用于模拟康复机器人帮助患者进行康复训练。您可以根据实际情况进一步调整模型结构、数据集和训练参数,以提高康复机器人的效果和准确性。
以下是一个进一步调整的示例代码,包括了一个更复杂的卷积神经网络模型结构、一个更大规模的康复训练数据集,以及调整后的训练参数来提高康复机器人的性能:
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义更复杂的康复机器人模型 class AdvancedRehabilitationRobot(nn.Module): def __init__(self): super(AdvancedRehabilitationRobot, self).__init__() self.conv1 = nn.Conv2d(1, 16, 3, padding=1) self.conv2 = nn.Conv2d(16, 32, 3, padding=1) self.fc1 = nn.Linear(32 * 16 * 16, 128) self.fc2 = nn.Linear(128, 2) # 2个动作:伸展、弯曲 def forward(self, x): x = torch.relu(self.conv1(x)) x = torch.relu(self.conv2(x)) x = x.view(-1, 32 * 16 * 16) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 初始化模型、损失函数和优化器 model = AdvancedRehabilitationRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成更大规模的康复训练数据集 X = torch.randn(1000, 1, 64, 64) # 1000个大小为64x64的训练图像 y = torch.randint(0, 2, (1000,)) # 1000个动作标签,0表示伸展,1表示弯曲 # 训练模型 num_epochs = 30 batch_size = 32 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟康复机器人帮助患者进行康复训练 new_data = torch.randn(1, 1, 64, 64) # 模拟一个新的训练图像 with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('康复机器人执行伸展动作') else: print('康复机器人执行弯曲动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
这个进一步调整的示例代码包括了一个更复杂的卷积神经网络模型结构、一个更大规模的康复训练数据集,以及调整后的训练参数来提高康复机器人的性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高康复机器人的准确性和效果。
以下是一个进一步调整的示例代码,包括了一个更深层的卷积神经网络模型结构、一个更多样化的康复训练数据集,以及调整后的训练参数来提高康复机器人的性能:
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义更深层的康复机器人模型 class AdvancedRehabilitationRobot(nn.Module): def __init__(self): super(AdvancedRehabilitationRobot, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.conv3 = nn.Conv2d(64, 128, 3, padding=1) self.fc1 = nn.Linear(128 * 16 * 16, 256) self.fc2 = nn.Linear(256, 2) # 2个动作:伸展、弯曲 def forward(self, x): x = torch.relu(self.conv1(x)) x = torch.relu(self.conv2(x)) x = torch.relu(self.conv3(x)) x = x.view(-1, 128 * 16 * 16) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 初始化模型、损失函数和优化器 model = AdvancedRehabilitationRobot() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成更多样化的康复训练数据集 X = torch.randn(2000, 1, 64, 64) # 2000个大小为64x64的训练图像 y = torch.randint(0, 2, (2000,)) # 2000个动作标签,0表示伸展,1表示弯曲 # 训练模型 num_epochs = 50 batch_size = 64 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟康复机器人帮助患者进行康复训练 new_data = torch.randn(1, 1, 64, 64) # 模拟一个新的训练图像 with torch.no_grad(): action = torch.argmax(model(new_data)) if action == 0: print('康复机器人执行伸展动作') else: print('康复机器人执行弯曲动作')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
这个进一步调整的示例代码包括了一个更深层的卷积神经网络模型结构、一个更多样化的康复训练数据集,以及调整后的训练参数来提高康复机器人的性能。您可以根据实际情况继续调整模型结构、数据集和训练参数,以进一步提高康复机器人的准确性和效果。
六、医学自然语言处理示例代码
- 完成医学文献的分类任务示例代码
以下是一个基于PyTorch的医学文献分类示例代码,用于将医学文献分为不同的类别。在这个示例中,我们使用一个简单的卷积神经网络模型来实现文献分类:
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义医学文献分类模型 class MedicalDocumentClassifier(nn.Module): def __init__(self, num_classes): super(MedicalDocumentClassifier, self).__init__() self.conv1 = nn.Conv1d(in_channels=300, out_channels=100, kernel_size=3) self.conv2 = nn.Conv1d(in_channels=100, out_channels=50, kernel_size=3) self.fc1 = nn.Linear(50 * 8, 256) self.fc2 = nn.Linear(256, num_classes) def forward(self, x): x = torch.relu(self.conv1(x)) x = torch.relu(self.conv2(x)) x = x.view(-1, 50 * 8) x = torch.relu(self.fc1(x)) x = self.fc2(x) return x # 初始化模型、损失函数和优化器 model = MedicalDocumentClassifier(num_classes=5) # 假设有5个类别 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成医学文献分类训练数据集 X = torch.randn(1000, 300, 20) # 1000个文献,每篇文献有300个词,每个词用长度为20的词向量表示 y = torch.randint(0, 5, (1000,)) # 1000个文献的类别标签 # 训练模型 num_epochs = 50 batch_size = 32 for epoch in range(num_epochs): for i in range(0, len(X), batch_size): optimizer.zero_grad() batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟医学文献分类 new_document = torch.randn(1, 300, 20) # 模拟一个新的文献 with torch.no_grad(): output = model(new_document) predicted_class = torch.argmax(output).item() print('预测的文献类别为:', predicted_class)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
这个示例代码演示了一个简单的医学文献分类模型,并包括了模型的训练过程和一个用于预测新文献类别的示例。您可以根据实际情况调整模型结构、数据集和训练参数,以更好地适应您的医学文献分类任务。
以下是一个根据实际情况调整模型结构、数据集和训练参数的医学文献分类示例代码:
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 定义医学文献分类模型 class MedicalDocumentClassifier(nn.Module): def __init__(self, num_classes): super(MedicalDocumentClassifier, self).__init__() self.lstm = nn.LSTM(input_size=300, hidden_size=128, num_layers=2, batch_first=True) self.fc = nn.Linear(128, num_classes) def forward(self, x): _, (h_n, _) = self.lstm(x) x = h_n[-1] x = self.fc(x) return x # 初始化模型、损失函数和优化器 model = MedicalDocumentClassifier(num_classes=5) # 假设有5个类别 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 生成医学文献分类训练数据集(这里假设您有自己的数据集) # 假设您的数据集是X_train和y_train,分别包含训练文献和对应的类别标签 # 训练模型 num_epochs = 20 batch_size = 32 for epoch in range(num_epochs): for i in range(0, len(X_train), batch_size): optimizer.zero_grad() batch_X = X_train[i:i+batch_size] batch_y = y_train[i:i+batch_size] outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟医学文献分类 new_document = torch.randn(1, 10, 300) # 模拟一个新的文献 with torch.no_grad(): output = model(new_document) predicted_class = torch.argmax(output).item() print('预测的文献类别为:', predicted_class)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
在这个示例中,我们调整了模型结构,使用了一个包含两层LSTM层的模型。我们还假设您有自己的医学文献分类数据集X_train和y_train,您可以将其用于训练模型。最后,我们使用一个新的文献数据进行了分类预测。您可以根据实际情况进一步调整模型结构、数据集和训练参数,以更好地适应您的医学文献分类任务。
以下是一个更进一步调整模型结构、数据集和训练参数的医学文献分类示例代码:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset import numpy as np # 定义医学文献分类模型 class MedicalDocumentClassifier(nn.Module): def __init__(self, num_classes): super(MedicalDocumentClassifier, self).__init__() self.embedding = nn.Embedding(10000, 300) # 假设词汇表大小为10000,词向量维度为300 self.lstm = nn.LSTM(input_size=300, hidden_size=128, num_layers=2, batch_first=True) self.fc = nn.Linear(128, num_classes) def forward(self, x): x = self.embedding(x) _, (h_n, _) = self.lstm(x) x = h_n[-1] x = self.fc(x) return x # 生成医学文献分类训练数据集(这里假设您有自己的数据集) # 假设您的数据集包含文本数据和对应的类别标签 # 假设您有一个函数load_data()用于加载数据集,返回文本数据和类别标签 def load_data(): # 在这里实现加载数据集的逻辑 # 返回文本数据和对应的类别标签 pass # 加载数据集 X_train, y_train = load_data() # 将文本数据转换为Tensor,并创建数据加载器 X_train_tensor = torch.tensor(X_train, dtype=torch.long) y_train_tensor = torch.tensor(y_train, dtype=torch.long) train_dataset = TensorDataset(X_train_tensor, y_train_tensor) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = MedicalDocumentClassifier(num_classes=5) # 假设有5个类别 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 20 for epoch in range(num_epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟医学文献分类 new_document = torch.randint(0, 10000, (1, 10)) # 模拟一个新的文献 with torch.no_grad(): output = model(new_document) predicted_class = torch.argmax(output).item() print('预测的文献类别为:', predicted_class)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
在这个示例中,我们进一步调整了模型结构,添加了一个词嵌入层用于将文本数据转换为向量表示。我们还使用了一个数据加载器来加载数据集,并在训练过程中逐批处理数据。您可以根据实际情况进一步调整模型结构、数据集和训练参数,以更好地适应您的医学文献分类任务。

- 完成实体识别任务示例代码
以下是一个使用PyTorch进行医学自然语言处理实体识别的示例代码:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset import numpy as np # 定义医学自然语言处理实体识别模型 class MedicalEntityRecognitionModel(nn.Module): def __init__(self, num_classes): super(MedicalEntityRecognitionModel, self).__init__() self.embedding = nn.Embedding(10000, 300) # 假设词汇表大小为10000,词向量维度为300 self.lstm = nn.LSTM(input_size=300, hidden_size=128, num_layers=2, batch_first=True) self.fc = nn.Linear(128, num_classes) def forward(self, x): x = self.embedding(x) _, (h_n, _) = self.lstm(x) x = h_n[-1] x = self.fc(x) return x # 生成医学自然语言处理实体识别训练数据集(这里假设您有自己的数据集) # 假设您的数据集包含医学文本数据和对应的实体标签 # 假设您有一个函数load_medical_data()用于加载医学数据集,返回医学文本数据和对应的实体标签 def load_medical_data(): # 在这里实现加载医学数据集的逻辑 # 返回医学文本数据和对应的实体标签 pass # 加载医学数据集 X_train, y_train = load_medical_data() # 将医学文本数据和实体标签转换为Tensor,并创建数据加载器 X_train_tensor = torch.tensor(X_train, dtype=torch.long) y_train_tensor = torch.tensor(y_train, dtype=torch.long) train_dataset = TensorDataset(X_train_tensor, y_train_tensor) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = MedicalEntityRecognitionModel(num_classes=5) # 假设有5个实体类别 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 20 for epoch in range(num_epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟医学实体识别 new_medical_text = torch.randint(0, 10000, (1, 10)) # 模拟一个新的医学文本 with torch.no_grad(): output = model(new_medical_text) predicted_entities = torch.argmax(output, dim=1).tolist() print('预测的医学实体标签为:', predicted_entities)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
在这个示例中,我们定义了一个用于医学自然语言处理实体识别的模型,并使用类似的数据加载和训练过程。您可以根据实际情况进一步调整模型结构、数据集和训练参数,以更好地适应您的医学自然语言处理实体识别任务。
以下是一个更具体的示例代码,根据实际情况进一步调整了模型结构、数据集和训练参数,以更好地适应医学自然语言处理实体识别任务:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset import numpy as np # 定义医学自然语言处理实体识别模型 class MedicalEntityRecognitionModel(nn.Module): def __init__(self, num_classes, vocab_size, embedding_dim, hidden_dim, num_layers): super(MedicalEntityRecognitionModel, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True) self.fc = nn.Linear(hidden_dim, num_classes) def forward(self, x): x = self.embedding(x) _, (h_n, _) = self.lstm(x) x = h_n[-1] x = self.fc(x) return x # 假设您有自己的医学文本数据集和实体标签数据集 # 在这里实现加载医学数据集的逻辑 def load_medical_data(): # 假设您的数据集包含医学文本数据和对应的实体标签 # 在这里实现加载医学数据集的逻辑 pass # 加载医学数据集 X_train, y_train = load_medical_data() # 将医学文本数据和实体标签转换为Tensor,并创建数据加载器 X_train_tensor = torch.tensor(X_train, dtype=torch.long) y_train_tensor = torch.tensor(y_train, dtype=torch.long) train_dataset = TensorDataset(X_train_tensor, y_train_tensor) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 初始化模型、损失函数和优化器 model = MedicalEntityRecognitionModel(num_classes=5, vocab_size=10000, embedding_dim=300, hidden_dim=128, num_layers=2) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 20 for epoch in range(num_epochs): for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 模拟医学实体识别 new_medical_text = torch.randint(0, 10000, (1, 10)) # 模拟一个新的医学文本 with torch.no_grad(): output = model(new_medical_text) predicted_entities = torch.argmax(output, dim=1).tolist() print('预测的医学实体标签为:', predicted_entities)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
在这个示例中,我们根据实际情况进一步调整了模型结构(调整了词汇表大小、词向量维度、LSTM隐藏单元数和层数)、数据集和训练参数,以更好地适应医学自然语言处理实体识别任务。您可以根据您的实际需求进一步调整和优化模型结构、数据集和训练参数。
以下是一个更具体的示例代码,根据您的实际需求进一步调整和优化模型结构、数据集和训练参数,以适应医学自然语言处理实体识别任务:
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset from sklearn.model_selection import train_test_split # 假设您有自己的医学文本数据集和实体标签数据集 # 在这里实现加载医学数据集的逻辑 class MedicalDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): return self.X[idx], self.y[idx] # 定义医学自然语言处理实体识别模型 class MedicalEntityRecognitionModel(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, num_layers): super(MedicalEntityRecognitionModel, self).__init__() self.embedding = nn.Embedding(input_dim, embedding_dim) self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first=True) self.fc = nn.Linear(hidden_dim, output_dim) def forward(self, x): embedded = self.embedding(x) output, _ = self.lstm(embedded) output = self.fc(output[:, -1, :]) return output # 加载医学数据集 X = ... # 医学文本数据 y = ... # 实体标签数据 X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42) train_dataset = MedicalDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_dataset = MedicalDataset(X_val, y_val) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) # 初始化模型、损失函数和优化器 model = MedicalEntityRecognitionModel(input_dim=10000, embedding_dim=100, hidden_dim=128, output_dim=5, num_layers=2) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): model.train() for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() model.eval() val_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) val_loss += criterion(outputs, labels).item() _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Epoch [{}/{}], Train Loss: {:.4f}, Val Loss: {:.4f}, Val Accuracy: {:.2f}%'.format(epoch+1, num_epochs, loss.item(), val_loss/len(val_loader), 100 * correct / total)) # 在测试集上评估模型 test_dataset = ... # 加载测试集数据 test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() test_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in test_loader: outputs = model(inputs) test_loss += criterion(outputs, labels).item() _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Test Loss: {:.4f}, Test Accuracy: {:.2f}%'.format(test_loss/len(test_loader), 100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
在这个示例中,我们根据您的实际需求进一步调整和优化了模型结构、数据集和训练参数,以适应医学自然语言处理实体识别任务。您可以根据自己的数据集和任务要求进一步调整和优化模型。
- 完成关系抽取任务示例代码
以下是一个示例代码,用于医学自然语言处理中的关系抽取任务。在这个示例中,我们将使用一个简单的双向LSTM模型来抽取医学文本中实体之间的关系。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset from sklearn.model_selection import train_test_split # 假设您有自己的医学文本数据集和关系标签数据集 # 在这里实现加载医学数据集的逻辑 class MedicalRelationDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): return self.X[idx], self.y[idx] # 定义医学自然语言处理关系抽取模型 class MedicalRelationExtractionModel(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, num_layers): super(MedicalRelationExtractionModel, self).__init__() self.embedding = nn.Embedding(input_dim, embedding_dim) self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first=True, bidirectional=True) self.fc = nn.Linear(hidden_dim * 2, output_dim) def forward(self, x): embedded = self.embedding(x) output, _ = self.lstm(embedded) output = self.fc(output) return output # 加载医学数据集 X = ... # 医学文本数据 y = ... # 关系标签数据 X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42) train_dataset = MedicalRelationDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_dataset = MedicalRelationDataset(X_val, y_val) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) # 初始化模型、损失函数和优化器 model = MedicalRelationExtractionModel(input_dim=10000, embedding_dim=100, hidden_dim=128, output_dim=5, num_layers=2) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): model.train() for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)) loss.backward() optimizer.step() model.eval() val_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) val_loss += criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)).item() _, predicted = torch.max(outputs, 2) total += labels.size(0) * labels.size(1) correct += (predicted == labels).sum().item() print('Epoch [{}/{}], Train Loss: {:.4f}, Val Loss: {:.4f}, Val Accuracy: {:.2f}%'.format(epoch+1, num_epochs, loss.item(), val_loss/len(val_loader), 100 * correct / total)) # 在测试集上评估模型 test_dataset = ... # 加载测试集数据 test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() test_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in test_loader: outputs = model(inputs) test_loss += criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)).item() _, predicted = torch.max(outputs, 2) total += labels.size(0) * labels.size(1) correct += (predicted == labels).sum().item() print('Test Loss: {:.4f}, Test Accuracy: {:.2f}%'.format(test_loss/len(test_loader), 100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
请根据您的实际数据集和任务需求对代码进行调整和优化。
以下是一个示例代码,用于医学自然语言处理中的关系抽取任务。在这个示例中,我们将使用一个简单的双向LSTM模型来抽取医学文本中实体之间的关系。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset from sklearn.model_selection import train_test_split # 假设您有自己的医学文本数据集和关系标签数据集 # 在这里实现加载医学数据集的逻辑 class MedicalRelationDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): return self.X[idx], self.y[idx] # 定义医学自然语言处理关系抽取模型 class MedicalRelationExtractionModel(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, num_layers): super(MedicalRelationExtractionModel, self).__init__() self.embedding = nn.Embedding(input_dim, embedding_dim) self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first=True, bidirectional=True) self.fc = nn.Linear(hidden_dim * 2, output_dim) def forward(self, x): embedded = self.embedding(x) output, _ = self.lstm(embedded) output = self.fc(output) return output # 加载医学数据集 X = ... # 医学文本数据 y = ... # 关系标签数据 X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42) train_dataset = MedicalRelationDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_dataset = MedicalRelationDataset(X_val, y_val) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) # 初始化模型、损失函数和优化器 model = MedicalRelationExtractionModel(input_dim=10000, embedding_dim=100, hidden_dim=128, output_dim=5, num_layers=2) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): model.train() for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)) loss.backward() optimizer.step() model.eval() val_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) val_loss += criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)).item() _, predicted = torch.max(outputs, 2) total += labels.size(0) * labels.size(1) correct += (predicted == labels).sum().item() print('Epoch [{}/{}], Train Loss: {:.4f}, Val Loss: {:.4f}, Val Accuracy: {:.2f}%'.format(epoch+1, num_epochs, loss.item(), val_loss/len(val_loader), 100 * correct / total)) # 在测试集上评估模型 test_dataset = ... # 加载测试集数据 test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) model.eval() test_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in test_loader: outputs = model(inputs) test_loss += criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1)).item() _, predicted = torch.max(outputs, 2) total += labels.size(0) * labels.size(1) correct += (predicted == labels).sum().item() print('Test Loss: {:.4f}, Test Accuracy: {:.2f}%'.format(test_loss/len(test_loader), 100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
请根据您的实际数据集和任务需求对代码进行调整和优化。
以下是一个示例代码,根据实际数据集和任务需求对上面的代码进行了进一步调整和优化,假设您的医学文本数据集用于关系抽取任务:
import torch import torch.nn as nn from torch.utils.data import DataLoader from my_custom_dataset import MedicalTextDataset # 自定义医学文本数据集类 from my_custom_model import RelationExtractionModel # 自定义关系抽取模型类 # 加载数据集 train_dataset = MedicalTextDataset('train_data.txt') val_dataset = MedicalTextDataset('val_data.txt') test_dataset = MedicalTextDataset('test_data.txt') train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) # 初始化模型 model = RelationExtractionModel(embedding_dim=100, hidden_dim=128, num_classes=10) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 10 for epoch in range(num_epochs): model.train() for i, (inputs, labels) in enumerate(train_loader): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 在验证集上评估模型 model.eval() val_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) val_loss += criterion(outputs, labels).item() _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Epoch [{}/{}], Train Loss: {:.4f}, Val Loss: {:.4f}, Val Accuracy: {:.2f}%'.format(epoch+1, num_epochs, loss.item(), val_loss/len(val_loader), 100 * correct / total)) # 在测试集上评估模型 model.eval() test_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in test_loader: outputs = model(inputs) test_loss += criterion(outputs, labels).item() _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Test Loss: {:.4f}, Test Accuracy: {:.2f}%'.format(test_loss/len(test_loader), 100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
请根据您的实际数据集和任务需求,自定义医学文本数据集类和关系抽取模型类,并相应地调整代码中的数据加载、模型初始化、训练和评估部分。
七、医学预测模型示例代码
- 预测疾病的发展趋势示例代码
以下是一个简单的示例代码,演示如何使用PyTorch构建一个模型来预测疾病的发展趋势。在这个示例中,我们假设输入特征是疾病的历史数据,输出标签是未来某个时间点的疾病发展情况(例如,疾病的严重程度)。请注意,这只是一个简单的示例,实际应用中可能需要更复杂的模型和更多的特征工程。
import torch import torch.nn as nn import torch.optim as optim import numpy as np # 创建一个简单的神经网络模型 class DiseasePredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(DiseasePredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_dim, output_dim) def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x # 准备训练数据 # 假设输入特征是疾病的历史数据,输出标签是未来某个时间点的疾病发展情况 X_train = np.random.rand(100, 5) # 100个样本,每个样本有5个特征 y_train = np.random.rand(100, 1) # 对应的标签 # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 5 hidden_dim = 10 output_dim = 1 model = DiseasePredictionModel(input_dim, hidden_dim, output_dim) criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.01) # 训练模型 num_epochs = 100 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 使用模型进行预测 # 假设有一个测试样本X_test,需要预测其疾病发展情况 X_test = torch.tensor(np.random.rand(1, 5), dtype=torch.float32) predicted_y = model(X_test) print('Predicted disease severity:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
在这个示例中,我们定义了一个简单的两层全连接神经网络模型,使用均方误差损失函数进行训练,并使用Adam优化器更新模型参数。您可以根据实际情况调整模型结构、超参数和训练过程,以更好地适应您的数据集和任务需求。
以下是一个更加完整的示例代码,演示如何使用PyTorch构建一个模型来预测疾病的发展趋势。在这个示例中,我们将使用一个更深层的神经网络模型,并添加更多的特征工程和调整超参数,以更好地适应您的数据集和任务需求。
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split # 创建一个更深的神经网络模型 class DiseasePredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim1, hidden_dim2, output_dim): super(DiseasePredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim1) self.relu1 = nn.ReLU() self.fc2 = nn.Linear(hidden_dim1, hidden_dim2) self.relu2 = nn.ReLU() self.fc3 = nn.Linear(hidden_dim2, output_dim) def forward(self, x): x = self.fc1(x) x = self.relu1(x) x = self.fc2(x) x = self.relu2(x) x = self.fc3(x) return x # 准备数据集 # 假设X是特征,y是标签 X = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征 y = np.random.rand(1000, 1) # 对应的标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 10 hidden_dim1 = 20 hidden_dim2 = 10 output_dim = 1 model = DiseasePredictionModel(input_dim, hidden_dim1, hidden_dim2, output_dim) criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 num_epochs = 100 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): test_outputs = model(X_test) test_loss = criterion(test_outputs, y_test) print('Test Loss:', test_loss.item()) # 使用模型进行预测 # 假设有一个测试样本X_new,需要预测其疾病发展情况 X_new = torch.tensor(np.random.rand(1, 10), dtype=torch.float32) predicted_y = model(X_new) print('Predicted disease severity:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
在这个示例中,我们使用了一个更深的神经网络模型,添加了更多的特征工程和调整了学习率,以更好地适应您的数据集和任务需求。您可以根据实际情况进一步调整模型结构、超参数和训练过程,以获得更好的预测性能。
以下是一个示例代码,演示如何调整模型的隐藏层维度、学习率、训练轮数等超参数,以及尝试不同的优化器、损失函数等,以获得更好的预测性能。
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split # 创建一个神经网络模型 class DiseasePredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(DiseasePredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_dim, output_dim) def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x # 准备数据集 # 假设X是特征,y是标签 X = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征 y = np.random.rand(1000, 1) # 对应的标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 10 hidden_dim = 50 # 调整隐藏层维度 output_dim = 1 model = DiseasePredictionModel(input_dim, hidden_dim, output_dim) criterion = nn.MSELoss() # 使用均方误差损失函数 optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降优化器,调整学习率 # 训练模型 num_epochs = 200 # 增加训练轮数 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): test_outputs = model(X_test) test_loss = criterion(test_outputs, y_test) print('Test Loss:', test_loss.item()) # 使用模型进行预测 # 假设有一个测试样本X_new,需要预测其疾病发展情况 X_new = torch.tensor(np.random.rand(1, 10), dtype=torch.float32) predicted_y = model(X_new) print('Predicted disease severity:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
在这个示例中,我们调整了隐藏层维度、学习率、训练轮数,使用了不同的优化器和损失函数,以期获得更好的预测性能。您可以根据实际情况进一步调整这些超参数,甚至尝试其他的模型结构、正则化技术等来进一步改进预测性能。

- 患病风险评估示例代码
以下是一个示例代码,演示如何使用PyTorch构建一个简单的医学预测模型,用于患病风险评估。在这个示例中,我们将使用一个简单的多层感知机(MLP)模型来预测患者是否患有某种疾病。
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split # 创建一个多层感知机(MLP)模型 class DiseaseRiskPredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(DiseaseRiskPredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_dim, output_dim) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) x = self.sigmoid(x) return x # 准备数据集 # 假设X是特征,y是标签(0表示未患病,1表示患病) X = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征 y = np.random.randint(2, size=(1000, 1)) # 对应的标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 10 hidden_dim = 50 output_dim = 1 model = DiseaseRiskPredictionModel(input_dim, hidden_dim, output_dim) criterion = nn.BCELoss() # 使用二元交叉熵损失函数 optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器 # 训练模型 num_epochs = 100 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): test_outputs = model(X_test) test_loss = criterion(test_outputs, y_test) print('Test Loss:', test_loss.item()) # 使用模型进行预测 # 假设有一个新的患者特征X_new,需要预测其患病风险 X_new = torch.tensor(np.random.rand(1, 10), dtype=torch.float32) predicted_y = model(X_new) print('Predicted disease risk:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
在这个示例中,我们使用PyTorch构建了一个简单的多层感知机(MLP)模型,用于患病风险评估。我们准备了一个虚拟的数据集,并使用二元交叉熵损失函数和Adam优化器来训练模型。您可以根据实际情况调整模型结构、超参数等,以获得更好的预测性能。
以下是一个稍微调整过的示例代码,包括调整了模型结构和超参数,以获得更好的患病风险评估预测性能。
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split # 创建一个更深的神经网络模型 class DiseaseRiskPredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim1, hidden_dim2, output_dim): super(DiseaseRiskPredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim1) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_dim1, hidden_dim2) self.relu2 = nn.ReLU() self.fc3 = nn.Linear(hidden_dim2, output_dim) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) x = self.relu2(x) x = self.fc3(x) x = self.sigmoid(x) return x # 准备数据集 # 假设X是特征,y是标签(0表示未患病,1表示患病) X = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征 y = np.random.randint(2, size=(1000, 1)) # 对应的标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 10 hidden_dim1 = 50 hidden_dim2 = 20 output_dim = 1 model = DiseaseRiskPredictionModel(input_dim, hidden_dim1, hidden_dim2, output_dim) criterion = nn.BCELoss() # 使用二元交叉熵损失函数 optimizer = optim.Adam(model.parameters(), lr=0.01) # 使用Adam优化器,增加学习率 # 训练模型 num_epochs = 200 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 20 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): test_outputs = model(X_test) test_loss = criterion(test_outputs, y_test) print('Test Loss:', test_loss.item()) # 使用模型进行预测 # 假设有一个新的患者特征X_new,需要预测其患病风险 X_new = torch.tensor(np.random.rand(1, 10), dtype=torch.float32) predicted_y = model(X_new) print('Predicted disease risk:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
在这个调整后的示例代码中,我们增加了模型的深度,从而引入了一个额外的隐藏层,同时增加了学习率。这些调整可以帮助模型更好地学习数据的复杂关系,提高患病风险评估的预测性能。您可以根据实际情况进一步调整模型结构和超参数,以进一步改进模型性能。
以下是一个进一步调整模型结构和超参数的示例代码,以提高患病风险评估的性能:
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split # 创建一个更复杂的神经网络模型 class ImprovedDiseaseRiskPredictionModel(nn.Module): def __init__(self, input_dim, hidden_dim1, hidden_dim2, hidden_dim3, output_dim): super(ImprovedDiseaseRiskPredictionModel, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim1) self.relu1 = nn.ReLU() self.fc2 = nn.Linear(hidden_dim1, hidden_dim2) self.relu2 = nn.ReLU() self.fc3 = nn.Linear(hidden_dim2, hidden_dim3) self.relu3 = nn.ReLU() self.fc4 = nn.Linear(hidden_dim3, output_dim) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.fc1(x) x = self.relu1(x) x = self.fc2(x) x = self.relu2(x) x = self.fc3(x) x = self.relu3(x) x = self.fc4(x) x = self.sigmoid(x) return x # 准备数据集 # 假设X是特征,y是标签(0表示未患病,1表示患病) X = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征 y = np.random.randint(2, size=(1000, 1)) # 对应的标签 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换数据为PyTorch张量 X_train = torch.tensor(X_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # 初始化模型、损失函数和优化器 input_dim = 10 hidden_dim1 = 50 hidden_dim2 = 30 hidden_dim3 = 10 output_dim = 1 model = ImprovedDiseaseRiskPredictionModel(input_dim, hidden_dim1, hidden_dim2, hidden_dim3, output_dim) criterion = nn.BCELoss() # 使用二元交叉熵损失函数 optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,降低学习率 # 训练模型 num_epochs = 300 for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(X_train) loss = criterion(outputs, y_train) loss.backward() optimizer.step() if (epoch+1) % 30 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item())) # 评估模型 model.eval() with torch.no_grad(): test_outputs = model(X_test) test_loss = criterion(test_outputs, y_test) print('Test Loss:', test_loss.item()) # 使用模型进行预测 # 假设有一个新的患者特征X_new,需要预测其患病风险 X_new = torch.tensor(np.random.rand(1, 10), dtype=torch.float32) predicted_y = model(X_new) print('Predicted disease risk:', predicted_y.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
在这个示例代码中,我们进一步增加了模型的复杂度,引入了第三个隐藏层,并调整了学习率。这些调整可以帮助模型更好地捕获数据中的特征,并提高患病风险评估的性能。您可以根据实际情况继续调整模型结构和超参数,以进一步改进模型性能。
八、医学图像生成示例代码
- 生成医学影像数据示例代码
生成医学影像数据通常需要使用生成对抗网络(GAN)等复杂模型来生成更真实的影像数据。以下是一个简化的示例代码,演示如何使用PyTorch和GAN生成更真实的医学影像数据:
import torch import torch.nn as nn import torch.optim as optim import torchvision from torchvision import transforms, datasets from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 定义生成器模型 class Generator(nn.Module): def __init__(self, latent_dim, img_shape): super(Generator, self).__init() self.model = nn.Sequential( nn.Linear(latent_dim, 128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, img_shape), nn.Tanh() ) def forward(self, z): img = self.model(z) return img # 定义判别器模型 class Discriminator(nn.Module): def __init__(self, img_shape): super(Discriminator, self).__init() self.model = nn.Sequential( nn.Linear(img_shape, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 1), nn.Sigmoid() ) def forward(self, img): validity = self.model(img) return validity # 定义超参数 latent_dim = 100 img_shape = 784 # MNIST图像大小为28x28=784 batch_size = 64 num_epochs = 100 lr = 0.0002 # 初始化模型、损失函数和优化器 generator = Generator(latent_dim, img_shape) discriminator = Discriminator(img_shape) criterion = nn.BCELoss() optimizer_G = optim.Adam(generator.parameters(), lr=lr) optimizer_D = optim.Adam(discriminator.parameters(), lr=lr) # 训练GAN模型 # 省略训练过程,可参考GAN的训练代码示例 # 生成医学影像数据 num_images = 5 noise = torch.randn(num_images, latent_dim) gen_images = generator(noise) # 显示生成的医学影像数据 fig, axs = plt.subplots(1, num_images, figsize=(15, 5)) for i in range(num_images): img = gen_images[i].reshape(28, 28).detach().numpy() axs[i].imshow(img, cmap='gray') axs[i].axis('off') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
请注意,这只是一个简化的示例代码,实际上训练GAN模型并生成真实的医学影像数据需要更多的调优和技术。如果您需要生成更真实的医学影像数据,请考虑使用专业的医学影像数据集和更复杂的生成模型。
生成真实的医学影像数据涉及到专业领域和复杂技术,需要深入的医学知识和专业的数据集。在这里,我可以提供一个简单的示例代码,演示如何使用DCGAN(Deep Convolutional Generative Adversarial Network)来生成医学影像数据。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 定义生成器和判别器网络结构 class Generator(nn.Module): def __init__(self, latent_dim, img_shape): super(Generator, self).__init() # 定义生成器网络结构 ... def forward(self, z): # 生成器前向传播过程 ... class Discriminator(nn.Module): def __init__(self, img_shape): super(Discriminator, self).__init() # 定义判别器网络结构 ... def forward(self, img): # 判别器前向传播过程 ... # 加载医学影像数据集(示例) transform = transforms.Compose([ transforms.Resize(64), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 latent_dim = 100 img_shape = (1, 64, 64) # MNIST图像大小为28x28,这里调整为64x64 generator = Generator(latent_dim, img_shape) discriminator = Discriminator(img_shape) criterion = nn.BCELoss() optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)) optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 训练GAN模型 # 省略训练过程,可参考GAN的训练代码示例 # 生成医学影像数据 num_images = 5 noise = torch.randn(num_images, latent_dim) gen_images = generator(noise) # 显示生成的医学影像数据 fig, axs = plt.subplots(1, num_images, figsize=(15, 5)) for i in range(num_images): img = gen_images[i].reshape(64, 64).detach().numpy() axs[i].imshow(img, cmap='gray') axs[i].axis('off') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
如果您需要生成更真实的医学影像数据,请使用专业的医学影像数据集和更复杂的生成模型,并确保遵循相关的伦理和法律规定。
以下是一个简单的示例代码,演示如何使用VAE(Variational Autoencoder)生成医学影像数据。在这个示例中,我们使用MNIST数据集作为示例数据集。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 定义VAE模型 class VAE(nn.Module): def __init__(self, latent_dim): super(VAE, self).__init__() self.encoder = nn.Sequential( nn.Linear(28*28, 400), nn.ReLU(), nn.Linear(400, 2*latent_dim) ) self.decoder = nn.Sequential( nn.Linear(latent_dim, 400), nn.ReLU(), nn.Linear(400, 28*28), nn.Sigmoid() ) def reparameterize(self, mu, log_var): std = torch.exp(0.5*log_var) eps = torch.randn_like(std) return mu + eps*std def forward(self, x): x = x.view(-1, 28*28) z_mean_log_var = self.encoder(x) mu, log_var = z_mean_log_var[:, :latent_dim], z_mean_log_var[:, latent_dim:] z = self.reparameterize(mu, log_var) x_recon = self.decoder(z) return x_recon, mu, log_var # 加载MNIST数据集 transform = transforms.Compose([ transforms.ToTensor(), ]) dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 latent_dim = 20 vae = VAE(latent_dim) criterion = nn.BCELoss(reduction='sum') optimizer = optim.Adam(vae.parameters(), lr=0.001) # 训练VAE模型 num_epochs = 10 for epoch in range(num_epochs): for data, _ in dataloader: optimizer.zero_grad() recon_batch, mu, log_var = vae(data) loss = criterion(recon_batch, data.view(-1, 28*28)) + -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) loss.backward() optimizer.step() # 生成医学影像数据 num_images = 5 noise = torch.randn(num_images, latent_dim) gen_images = vae.decoder(noise) gen_images = gen_images.view(-1, 28, 28).detach().numpy() # 显示生成的医学影像数据 fig, axs = plt.subplots(1, num_images, figsize=(15, 5)) for i in range(num_images): img = gen_images[i] axs[i].imshow(img, cmap='gray') axs[i].axis('off') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73

- 重建缺失的医学图像示例代码
以下是一个简单的示例代码,演示如何使用 PyTorch 和 VAE 模型来重建缺失的医学图像数据。在这个示例中,我们使用 MNIST 数据集作为示例数据集,并通过模拟将图像的一部分像素设置为零来模拟缺失的情况。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np # 定义VAE模型 class VAE(nn.Module): def __init__(self, latent_dim): super(VAE, self).__init__() # 定义编码器和解码器 # ... def reparameterize(self, mu, log_var): # 重参数化 # ... def forward(self, x): # 前向传播 # ... # 加载MNIST数据集 transform = transforms.Compose([ transforms.ToTensor(), ]) dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 latent_dim = 20 vae = VAE(latent_dim) criterion = nn.BCELoss(reduction='sum') optimizer = optim.Adam(vae.parameters(), lr=0.001) # 训练VAE模型 num_epochs = 10 for epoch in range(num_epochs): for data, _ in dataloader: optimizer.zero_grad() recon_batch, mu, log_var = vae(data) loss = criterion(recon_batch, data.view(-1, 28*28)) + -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) loss.backward() optimizer.step() # 模拟缺失的医学图像数据 missing_data = torch.clone(data) # 复制原始图像数据 missing_data[:, :, 5:15, 5:15] = 0 # 将图像的一部分像素设置为零,模拟缺失 # 使用VAE重建缺失的医学图像数据 recon_data, _, _ = vae(missing_data) # 显示原始图像、缺失图像和重建图像 fig, axs = plt.subplots(3, 10, figsize=(15, 5)) for i in range(10): img = data[i].reshape(28, 28).detach().numpy() axs[0, i].imshow(img, cmap='gray') axs[0, i].axis('off') missing_img = missing_data[i].reshape(28, 28).detach().numpy() axs[1, i].imshow(missing_img, cmap='gray') axs[1, i].axis('off') recon_img = recon_data[i].reshape(28, 28).detach().numpy() axs[2, i].imshow(recon_img, cmap='gray') axs[2, i].axis('off') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
在这个示例中,我们首先加载了 MNIST 数据集,并使用 VAE 模型对原始图像进行训练。然后,我们模拟了缺失的医学图像数据,将图像的一部分像素设置为零。接下来,我们使用训练好的 VAE 模型来重建缺失的图像数据,并将原始图像、缺失图像和重建图像进行可视化展示。
请注意,这只是一个简单的示例代码,实际应用中可能需要更复杂的模型和数据集。
以下是一个使用 PyTorch 和更复杂的模型(如卷积神经网络)以及更复以下是一个更复杂的示例代码,演示如何使用 PyTorch 和一个更复杂的深度学习模型来重建缺失的图像数据。在这个示例中,我们将使用 CelebA 数据集,该数据集包含大量名人的图像,我们将使用一个卷积神经网络(CNN)作为模型来重建缺失的图像数据。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np # 定义卷积神经网络模型 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # 定义卷积和反卷积层 # ... def forward(self, x): # 前向传播 # ... # 加载CelebA数据集 transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor(), ]) dataset = datasets.CelebA(root='./data', split='train', target_type='attr', download=True, transform=transform) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 cnn = CNN() criterion = nn.MSELoss() optimizer = optim.Adam(cnn.parameters(), lr=0.001) # 训练CNN模型 num_epochs = 10 for epoch in range(num_epochs): for data, _ in dataloader: optimizer.zero_grad() recon_batch = cnn(data) loss = criterion(recon_batch, data) loss.backward() optimizer.step() # 模拟缺失的图像数据 missing_data = torch.clone(data) # 复制原始图像数据 missing_data[:, :, 16:48, 16:48] = 0 # 将图像的一部分像素设置为零,模拟缺失 # 使用CNN重建缺失的图像数据 recon_data = cnn(missing_data) # 显示原始图像、缺失图像和重建图像 fig, axs = plt.subplots(3, 10, figsize=(15, 5)) for i in range(10): img = data[i].permute(1, 2, 0).detach().numpy() axs[0, i].imshow(img) axs[0, i].axis('off') missing_img = missing_data[i].permute(1, 2, 0).detach().numpy() axs[1, i].imshow(missing_img) axs[1, i].axis('off') recon_img = recon_data[i].permute(1, 2, 0).detach().numpy() axs[2, i].imshow(recon_img) axs[2, i].axis('off') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
在这个示例中,我们使用了 CelebA 数据集和一个包含卷积层和反卷积层的卷积神经网络模型来重建缺失的图像数据。我们首先加载 CelebA 数据集,并使用 CNN 模型对原始图像进行训练。然后,我们模拟了缺失的图像数据,将图像的一部分像素设置为零。接下来,我们使用训练好的 CNN 模型来重建缺失的图像数据,并将原始图像、缺失图像和重建图像进行可视化展示。
这个示例代码展示了如何使用更复杂的模型和数据集来重建缺失的图像数据。
九、医学信号处理示例代码
- 完成处理心电图信号任务示例代码
以下是一个使用 PyTorch 处理心电图信号的示例代码。在这个示例中,我们将使用一个卷积神经网络(CNN)来对心电图信号进行分类,以区分正常心电图和异常心电图。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 定义心电图数据集类 class ECGDataset(Dataset): def __init__(self, data, labels): self.data = data self.labels = labels def __len__(self): return len(self.data) def __getitem__(self, idx): ecg = self.data[idx] label = self.labels[idx] return ecg, label # 定义卷积神经网络模型 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3) self.pool = nn.MaxPool1d(kernel_size=2) self.conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3) self.fc1 = nn.Linear(32 * 10, 128) self.fc2 = nn.Linear(128, 2) def forward(self, x): x = self.pool(nn.functional.relu(self.conv1(x))) x = self.pool(nn.functional.relu(self.conv2(x))) x = x.view(-1, 32 * 10) x = nn.functional.relu(self.fc1(x)) x = self.fc2(x) return x # 生成虚拟心电图数据和标签 num_samples = 1000 ecg_data = np.random.randn(num_samples, 1, 1000) # 1000个心电图信号,每个信号有1000个时间步 ecg_labels = np.random.randint(0, 2, num_samples) # 0表示正常心电图,1表示异常心电图 # 创建数据集和数据加载器 dataset = ECGDataset(ecg_data, ecg_labels) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 cnn = CNN() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(cnn.parameters(), lr=0.001) # 训练CNN模型 num_epochs = 10 for epoch in range(num_epochs): for ecg, label in dataloader: optimizer.zero_grad() output = cnn(ecg) loss = criterion(output, label) loss.backward() optimizer.step() # 测试模型 test_ecg = torch.tensor(np.random.randn(1, 1, 1000), dtype=torch.float32) output = cnn(test_ecg) predicted_label = torch.argmax(output).item() print("Predicted label:", predicted_label)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
在这个示例中,我们定义了一个包含卷积层和全连接层的卷积神经网络模型,用于对心电图信号进行分类。我们生成了虚拟的心电图数据和标签,然后创建了一个自定义的数据集类和数据加载器。接着,我们初始化模型、损失函数和优化器,并对模型进行训练。最后,我们使用训练好的模型对一个随机生成的心电图信号进行分类,并输出预测的标签。
这个示例代码展示了如何使用 PyTorch 处理心电图信号数据,并构建一个卷积神经网络模型来对心电图信号进行分类。
以下是一个使用 PyTorch 处理心电图信号的另一个示例代码。在这个示例中,我们将使用一个循环神经网络(RNN)来对心电图信号进行时间序列预测。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 定义心电图数据集类 class ECGDataset(Dataset): def __init__(self, data, seq_length): self.data = data self.seq_length = seq_length def __len__(self): return len(self.data) - self.seq_length def __getitem__(self, idx): ecg_sequence = self.data[idx:idx+self.seq_length] target_ecg = self.data[idx+self.seq_length] return ecg_sequence, target_ecg # 定义循环神经网络模型 class RNN(nn.Module): def __init__(self, input_size, hidden_size, num_layers, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, hidden): out, hidden = self.rnn(x, hidden) out = self.fc(out[:, -1, :]) return out, hidden # 生成虚拟心电图数据 num_samples = 1000 seq_length = 10 ecg_data = np.random.randn(num_samples, 1) # 1000个心电图信号,每个信号有一个时间步 ecg_data = np.tile(ecg_data, (1, seq_length)).reshape(-1, seq_length, 1) # 将数据复制多个时间步 target_data = np.roll(ecg_data, -1, axis=0) # 目标数据为输入数据向后移动一个时间步 # 创建数据集和数据加载器 dataset = ECGDataset(ecg_data, seq_length) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 rnn = RNN(input_size=1, hidden_size=64, num_layers=1, output_size=1) criterion = nn.MSELoss() optimizer = optim.Adam(rnn.parameters(), lr=0.001) # 训练RNN模型 num_epochs = 10 for epoch in range(num_epochs): for ecg_sequence, target_ecg in dataloader: optimizer.zero_grad() hidden = None ecg_sequence = ecg_sequence.float() output, hidden = rnn(ecg_sequence, hidden) loss = criterion(output, target_ecg) loss.backward() optimizer.step() # 测试模型 test_ecg_sequence = torch.tensor(np.random.randn(1, seq_length, 1), dtype=torch.float32) hidden = None predicted_ecg, _ = rnn(test_ecg_sequence, hidden) print("Predicted ECG signal:", predicted_ecg.detach().numpy())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
在这个示例中,我们定义了一个包含循环神经网络(RNN)的模型,用于对心电图信号进行时间序列预测。我们生成了虚拟的心电图数据,并创建了一个自定义的数据集类和数据加载器。然后,我们初始化模型、损失函数和优化器,并对模型进行训练。最后,我们使用训练好的模型对一个随机生成的心电图信号序列进行时间序列预测,并输出预测的心电图信号。
这个示例代码展示了如何使用 PyTorch 处理心电图信号数据,并构建一个循环神经网络模型来进行时间序列预测。
- 完成处理脑电图信号数据任务示例代码
以下是一个使用 PyTorch 处理脑电图(EEG)信号数据的示例代码。在这个示例中,我们将使用一个卷积神经网络(CNN)来对脑电图信号进行分类。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 定义脑电图数据集类 class EEGDataset(Dataset): def __init__(self, data, labels): self.data = data self.labels = labels def __len__(self): return len(self.data) def __getitem__(self, idx): eeg_signal = self.data[idx] label = self.labels[idx] return eeg_signal, label # 定义卷积神经网络模型 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3) self.relu = nn.ReLU() self.pool = nn.MaxPool1d(kernel_size=2) self.fc = nn.Linear(16*24, 2) # 假设输出类别为2 def forward(self, x): x = self.conv1(x) x = self.relu(x) x = self.pool(x) x = x.view(-1, 16*24) x = self.fc(x) return x # 生成虚拟脑电图数据 num_samples = 1000 num_channels = 32 eeg_data = np.random.randn(num_samples, num_channels, 128) # 1000个脑电图信号,每个信号有32个通道,每个通道有128个时间步 labels = np.random.randint(0, 2, num_samples) # 生成随机标签 # 创建数据集和数据加载器 dataset = EEGDataset(eeg_data, labels) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 cnn = CNN() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(cnn.parameters(), lr=0.001) # 训练CNN模型 num_epochs = 10 for epoch in range(num_epochs): for eeg_signal, label in dataloader: optimizer.zero_grad() eeg_signal = eeg_signal.float() output = cnn(eeg_signal) loss = criterion(output, label) loss.backward() optimizer.step() # 测试模型 test_eeg_signal = torch.tensor(np.random.randn(1, num_channels, 128), dtype=torch.float32) predicted_label = torch.argmax(cnn(test_eeg_signal)) print("Predicted label:", predicted_label.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
在这个示例中,我们定义了一个包含卷积神经网络(CNN)的模型,用于对脑电图信号进行分类。我们生成了虚拟的脑电图数据,并创建了一个自定义的数据集类和数据加载器。然后,我们初始化模型、损失函数和优化器,并对模型进行训练。最后,我们使用训练好的模型对一个随机生成的脑电图信号进行分类,并输出预测的标签。
这个示例代码展示了如何使用 PyTorch 处理脑电图信号数据,并构建一个卷积神经网络模型来进行分类。
以下是一个使用 PyTorch 处理脑电图(EEG)信号数据的另一个示例代码。在这个示例中,我们将使用循环神经网络(RNN)来对脑电图信号进行时间序列预测。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import numpy as np # 定义脑电图数据集类 class EEGDataset(Dataset): def __init__(self, data): self.data = data def __len__(self): return len(self.data) def __getitem__(self, idx): eeg_signal = self.data[idx] return eeg_signal # 定义循环神经网络模型 class RNN(nn.Module): def __init__(self, input_size, hidden_size, num_layers, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size) out, _ = self.rnn(x, h0) out = self.fc(out[:, -1, :]) return out # 生成虚拟脑电图数据 num_samples = 1000 num_channels = 32 eeg_data = np.random.randn(num_samples, num_channels, 128) # 1000个脑电图信号,每个信号有32个通道,每个通道有128个时间步 # 创建数据集和数据加载器 dataset = EEGDataset(eeg_data) dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 初始化模型、损失函数和优化器 rnn = RNN(input_size=num_channels, hidden_size=64, num_layers=1, output_size=2) # 假设输出类别为2 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(rnn.parameters(), lr=0.001) # 训练RNN模型 num_epochs = 10 for epoch in range(num_epochs): for eeg_signal in dataloader: optimizer.zero_grad() eeg_signal = eeg_signal.float() output = rnn(eeg_signal) loss = criterion(output, torch.randint(0, 2, (64,))) # 随机生成标签 loss.backward() optimizer.step() # 测试模型 test_eeg_signal = torch.tensor(np.random.randn(1, num_channels, 128), dtype=torch.float32) predicted_output = rnn(test_eeg_signal) predicted_label = torch.argmax(predicted_output) print("Predicted label:", predicted_label.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
在这个示例中,我们定义了一个包含循环神经网络(RNN)的模型,用于对脑电图信号进行时间序列预测。我们生成了虚拟的脑电图数据,并创建了一个自定义的数据集类和数据加载器。然后,我们初始化模型、损失函数和优化器,并对模型进行训练。最后,我们使用训练好的模型对一个随机生成的脑电图信号进行时间序列预测,并输出预测的标签。
这个示例代码展示了如何使用 PyTorch 处理脑电图信号数据,并构建一个循环神经网络模型来进行时间序列预测。
十、知识点归纳

PyTorch 在医学领域的应用非常广泛,主要涉及医学影像分析、生物医学信号处理、医疗数据挖掘等方面。以下是 PyTorch 在医学领域应用的一些知识点的归纳:
-
医学影像分析:
- 使用卷积神经网络(CNN)进行医学影像分类、分割和检测,如肿瘤检测、病灶分割等。
- 利用迁移学习和深度学习模型对医学影像进行特征提取和识别,如基于预训练的模型进行医学图像识别任务。
- 结合生成对抗网络(GAN)进行医学影像的增强和重建。
-
生物医学信号处理:
- 使用循环神经网络(RNN)和长短期记忆网络(LSTM)等模型处理生物医学信号数据,如脑电图(EEG)、心电图(ECG)等。
- 利用深度学习模型对生物医学信号进行分类、异常检测和预测,如心律失常检测、睡眠阶段识别等。
-
医疗数据挖掘:
- 使用深度学习模型处理医疗文本数据,如病历记录、医学文献等,进行疾病诊断、药物推荐等任务。
- 利用自然语言处理(NLP)技术处理医疗数据,如命名实体识别、关系抽取等。
-
模型解释和可解释性:
- 解释深度学习模型在医学领域的决策过程,提高模型的可解释性,如使用注意力机制、梯度热力图等方法。
-
迁移学习和强化学习:
- 利用迁移学习将已训练好的深度学习模型应用于医学领域,减少数据需求和提高模型性能。
- 结合强化学习方法解决医学决策问题,如个性化治疗方案推荐、疾病预后预测等。
-
模型部署和应用:
- 将训练好的深度学习模型部署到医疗设备、移动应用等平台,实现实时监测和辅助诊断。

以上是 PyTorch 在医学领域应用的一些知识点归纳,希望对您有所帮助。在实际应用中,结合具体的医学问题和数据特点,选择合适的深度学习方法和工具进行研究和开发。

