
- 1红队攻防渗透技术实战流程:云安全之云原生安全:K8s搭建及节点漏洞利用_云原生安全攻防
- 2【SpringBoot篇】基于Redis分布式锁的 误删问题 和 原子性问题_redisson 防止误删
- 3【保驾护航】HarmonyOS应用开发者基础认证-题库-2024_关于video组件的回调事件,下列说法错误的是
- 4LeetCode 刷题 [C++] 第122题. 买卖股票的最佳时机 II (贪心算法与动态规划)_给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。 对该股票可以进行多
- 5快速排序算法—图文详解,一篇就够了!_快速排序算法图解
- 6基于layui 下拉多选 三级联动省市区demo_layui tree省市
- 7Manjaro安装QQ和微信(deepin-wine5版)(2021-4-14更新)_manjaro 安装微信
- 8网络安全顶刊——TDSC 2023 论文清单与摘要(3)
- 9Spark修炼之道(基础篇)——Linux大数据开发基础:第十五节:基础正则表达式(一)_在spark内,可以使用正则表达式对syslog进行拆分成结构化字段,以下是示例代码:
- 10计算机视觉相关学习项目(上)——附MATLAB源代码_基于多尺度形态学提取眼前节组织
2024年最全大数据实战平台环境搭建_搭建大数据平台_大数据环境搭建
赞
踩
图24:解压完成
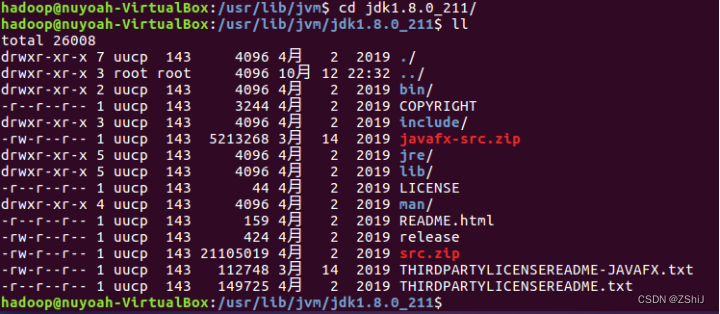
图25:确认解压是否成功
在终端输入cd jdk1.8.0_211/进入该文件夹确认解压是否成功,如果该文件夹为空则前面某一步有问题导致解压不成功,反之则为解压成功。
6、配置环境变量

图26:进入环境变量配置
在终端输入cd …返回上一级文件夹,再输入vim ~/.bashrc进入环境变量配置。
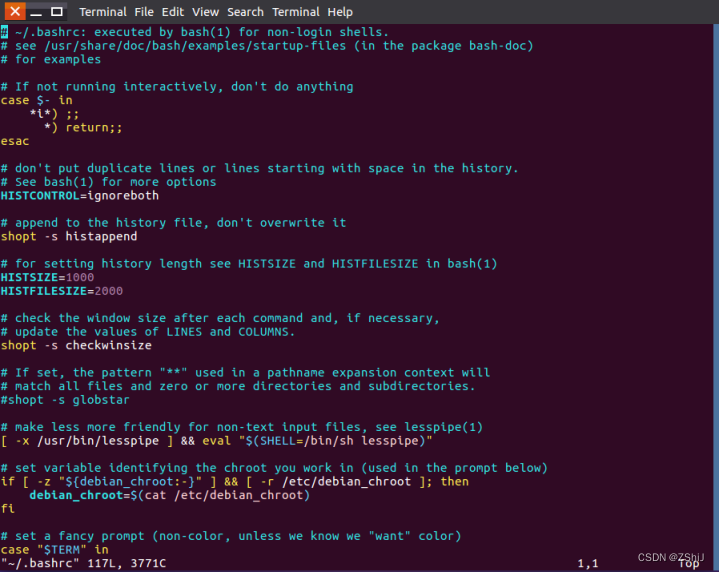
图27:进入环境变量
进入环境变量,此时补课编辑,只可查看。需要按“i”进入 insert 模式。
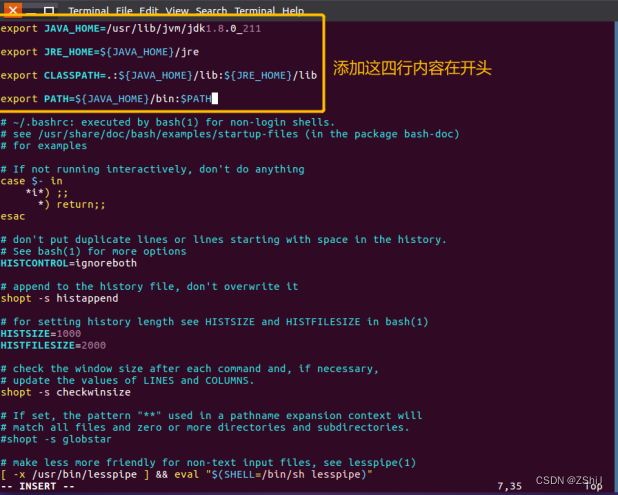
图28:配置环境变量
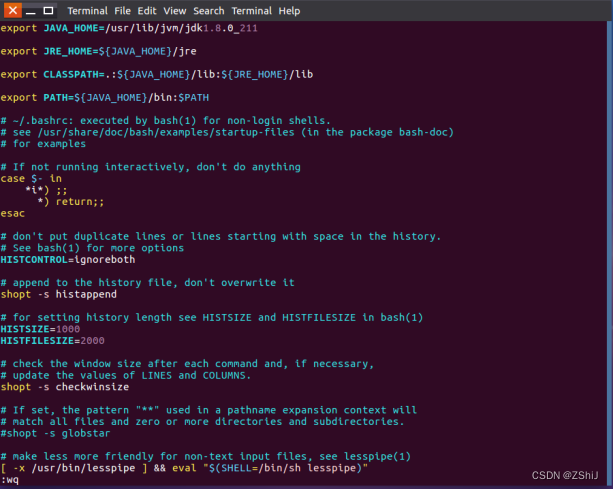
图29:按 ESC 保存,然后 shift+:wq
按 ESC 保存,然后 shift+:wq退出环境配置。
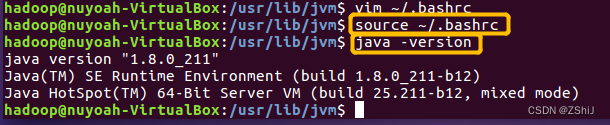
图30:确认jdk安装成功
在终端输入source ~/.bashrc激活刚刚配置的环境变量,接着在终端输入java -version查看java版本,确认jdk安装成功。
五、安装单机 Hadoop
1、确认文件及文件夹
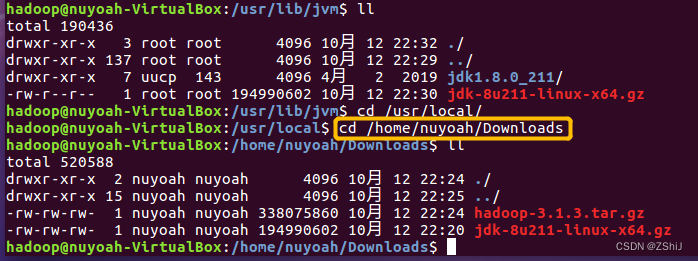
图31:确认文件及文件夹
在终端进入Downloads文件夹确认hadoop的安装包在该文件夹内。
2、解压安装包到/usr/local下

图32:解压安装包到/usr/local
在终端输入sudo tar -zxvf hadoop-3.1.3.tar.gz -C /uer/local解压指令对hadoop文件解压。(-zxvf :z代表gzip的压缩包;x代表解压;v代表显示过程信息;f代表后面接的是文件)
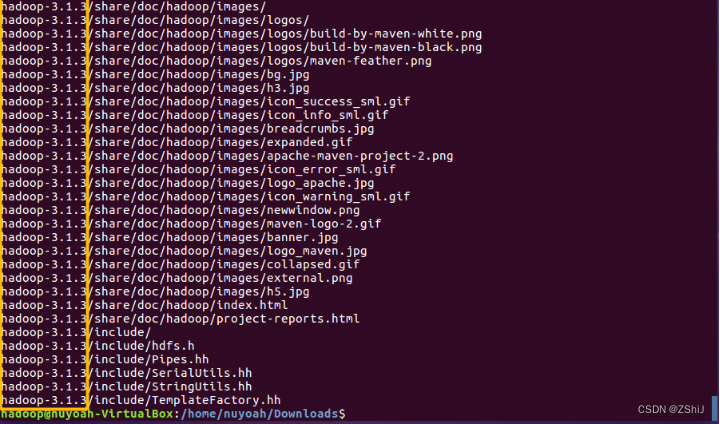
图33:解压完成
Hadoop安装包解压完成,其中hadoop-3.1.3/是解压后的文件夹的名称。
3、修改目录名及目录权限
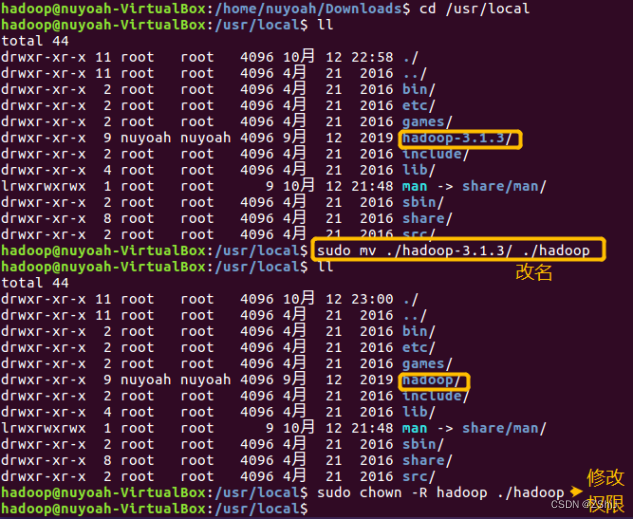
图34:修改目录名及目录权限
在终端输入cd /uer/local进入local文件夹,通过ll查看改文件夹内的文件。为了方便,通过输入sudo mv ./hadoop-3.1.3/ ./hadoop将文件夹hadoop-3.1.3的名字改成了hadoop。通过输入sudo chown -R hadoop ./hadoop修改权限。
4、查看版本信息

图35:查看版本信息
在终端输入cd hadoop/进入hadoop文件夹,再输入./bin/hadoop version查看版本信息。
5、测试
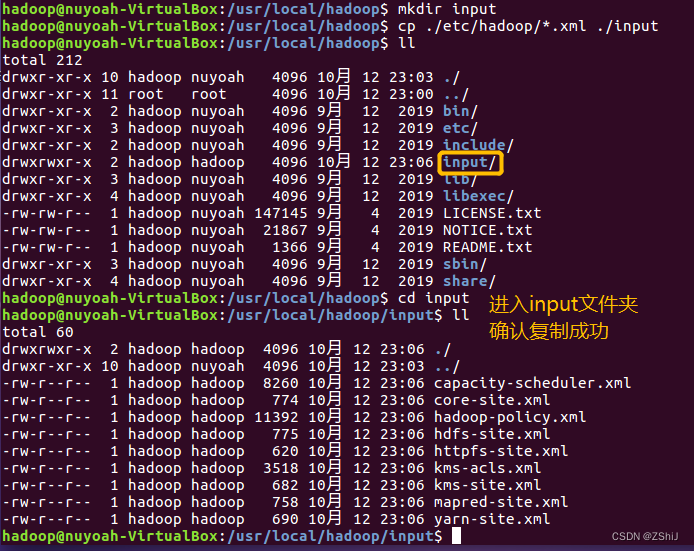
图36:复制文件到新建文件夹input内
在终端输入mkdir input新建文件夹input,接着输入cp ./etc/hadoop/.xml ./input(其中.xml代表所有的.xml文件),此行目的是将uer/local/hadoop/etc/hadoop下的所有的.xml文件复制到input文件夹内。
通过cd input进入input文件夹我们确认了复制成功。
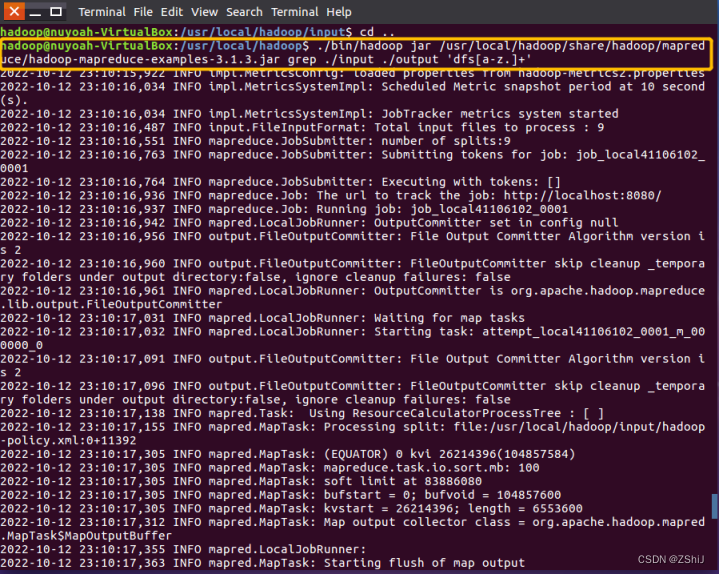
图37:测试
在终端输入./bin/hadoop jar /usr/loacl/hadoop/share/hadoop/mapreduce/
hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'测试指令进行测试。
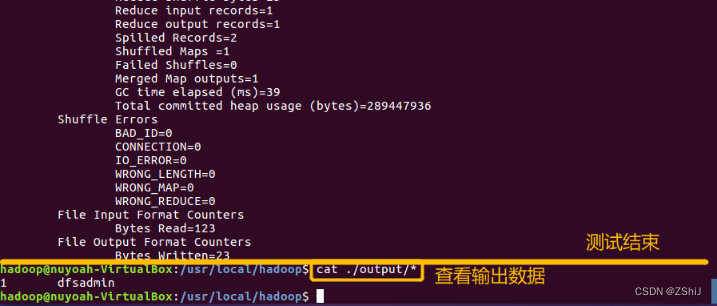
图38:测试完成
测试完成,在终端输入cat ./output/*查看输出数据。
六、Hadoop 伪分布式安装
1、修改配置文件(在etc/hadoop下)
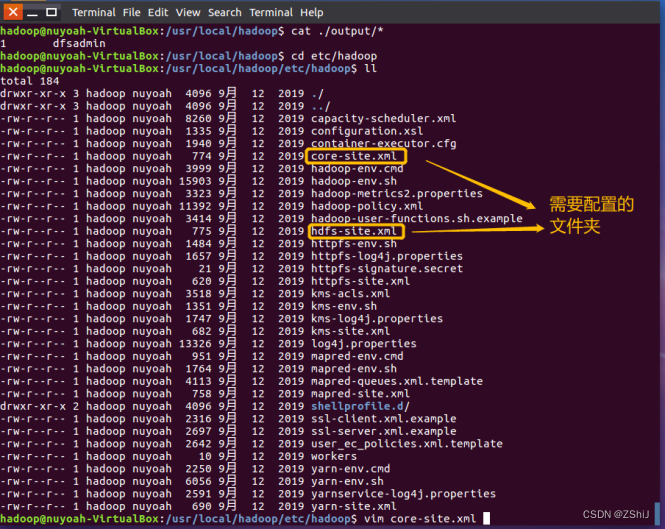
图39:查看要修改的配置文件
通过终端cd etc/hadoop进入etc/hadoop查看要修改的配置文件。通过查看得知需要配置core-site.xml和hdfs-site.xml两个文件夹。
在终端输入vim core-site.xml使用vim编辑器配置。
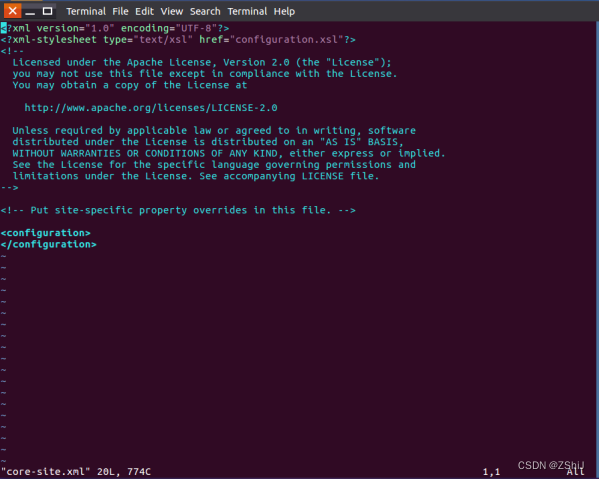
图40:进入core-site.xml
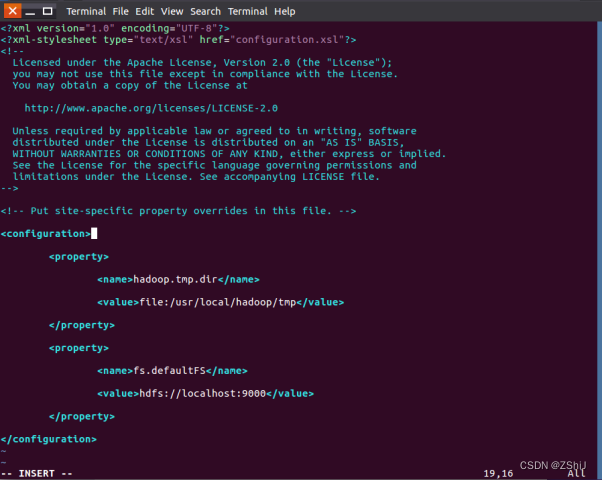
图41:core-site.xml配置完成
2、配置

图42:配置hdfs-site.xml
在终端输入vim hdfs-site.xml使用vim编辑器配置。
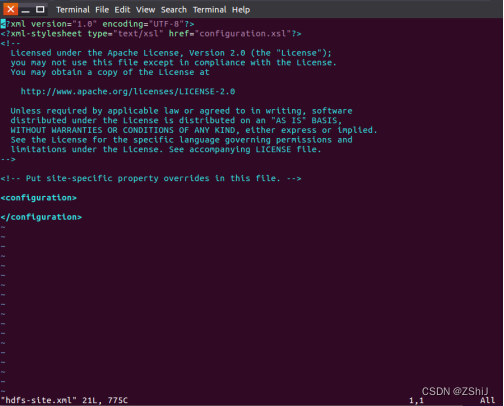
图43:进入hdfs-site.xml
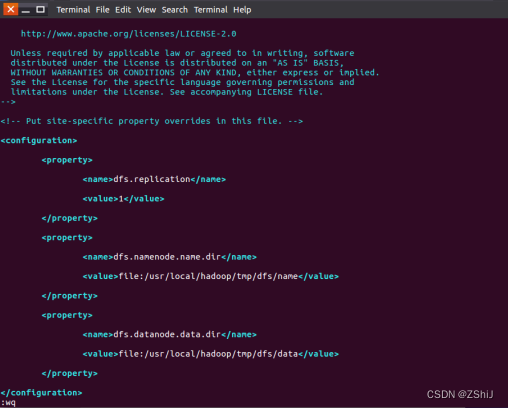
图44:hdfs-site.xml配置完成
3、初始化
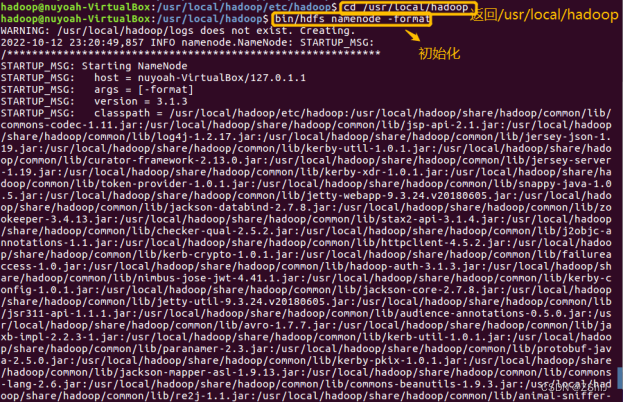
图45:初始化
在终端输入cd /usr/local/hadoop回到/usr/local/hadoop文件夹,再输入bin/hdfs namenode -format进行初始化。
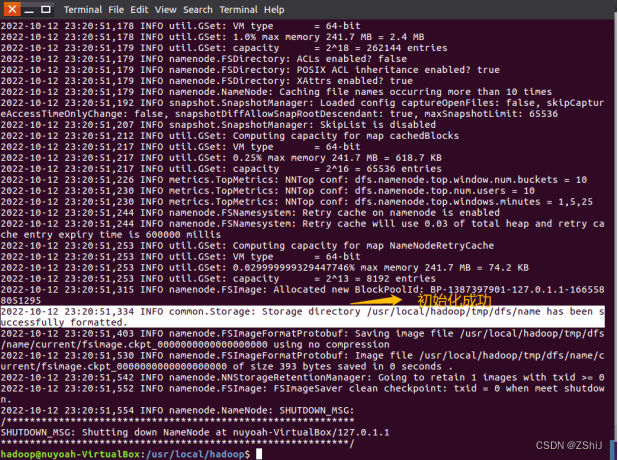
图46:初始化成功
4、启动 hdfs

图47:启动hdfs
在终端输入./sbin/start-dfs.sh启动hsfd,再输入jsp查看java进程。
5、查看 Hadoop(用 Browser)
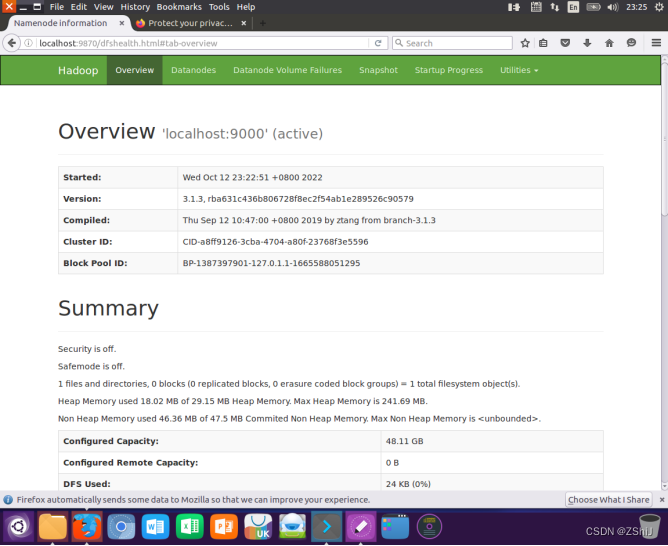
图48:用 Browser查看 Hadoop
注意这里要用Ubuntu自带的浏览器,地址为:http://localhost:9870
6、创建Hadoop用户的用户目录及input目录

图49:创建 Hadoop 用户的用户目录及 input 目录
在终端输入./bin/hdfs dfs -mkdir -p /usr/hadoop创建Hadoop用户的用户目录,在终端输入./bin/hdfs dfs -mkdir input创建Hadoop用户的input目录。(其中./bin/hdfs dfs是指令前缀,后面是正常的Ubuntu指令。)
7、将本地配置文件夹上传到分布式文件系统
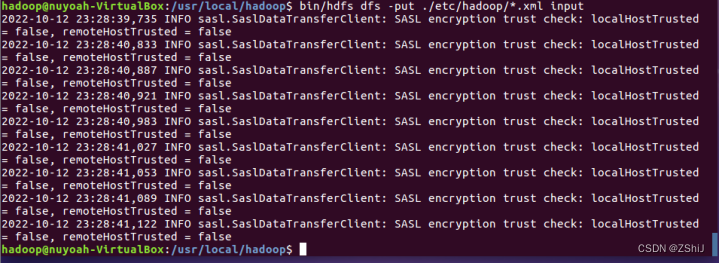
图50:将本地配置文件夹上传到分布式文件系统
在终端输入bin/hdfs dfs -put ./etc/hadoop/.xml input将本地配置文件夹上传到分布式文件系统.(bin/hdfs dfs是指令前缀,-put是命令,./etc/hadoop/.xml是源,input是目标。)
8、测试demo
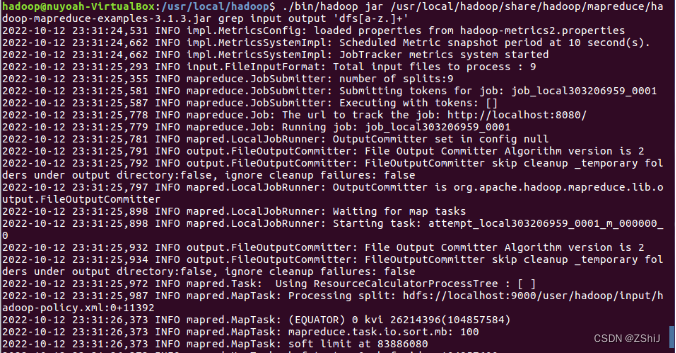
图51:测试demo
在终端输入./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/
hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'测试指令进行测试。
注意这里和单机hadoop测试不一样的地方是这里后面是input output,单机时是./input ./output。
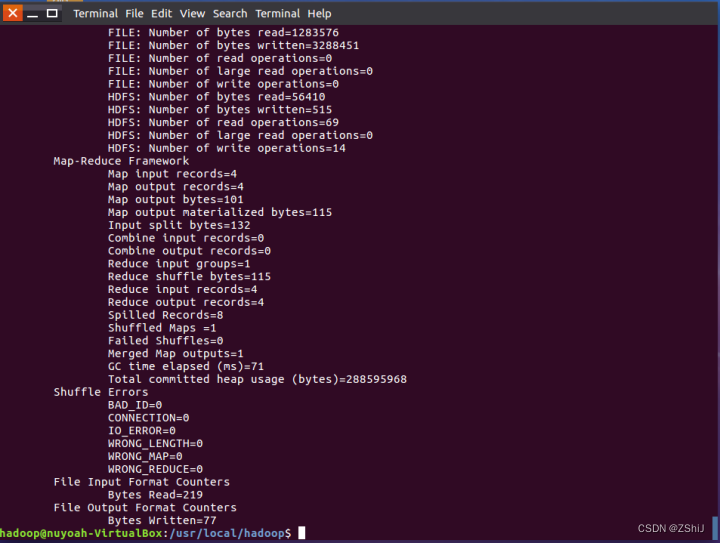
图52:测试完成
9、查看结果

图53:查看测试结果
在终端输入.bin/hdfs dfs -cat output/*查看测试结果。
10、关闭 hdfs

图54:删除output目录
在终端输入.bin/hdfs dfs -rm -r output删除output目录。(每次执行都要吧上一次的output删除,测试过应该是底层写死的无法修改)

图55:关闭hdfs
在终端输入./sbin/stop-dfs.sh停止执行hdfs。
七、HDFS常用命令
(1)功能:显示
指定的文件的详细信息。
hadoop fs -1s
。
(2)功能:1s 命令的递归版本。
hadoop fs -1s -R。
(3)功能:将
指定的文件的内容输出到标准输出 (stdout )。
hadoop fs -cat
。
(4)功能:将
指定的文件所属的组改为group,使用-R对
指定的文件夹内的文件进行递归操作。这个命令只适用于超级用户。
hadoop fs -chgrp [-RJgroup
。
(5)功能:改变
指定的文件所有者,-R 用于递归改交文件夹内的文件所有者。这个命令只适用于超级用户。
hadoop fs-chown [-R] [owner][ :[group]]
。
(6)功能:将
指定的文件的权限更改为。这个命令只适用于超级用户和文件所有者。
hadoop fs -chmod [- R]
。
(7)功能:将
指定的文件最后 1KB 的内容输出到标准输出 (stdout)上,一f选项用于持续检测新添加到文件中的内容。
hadoop fs -tail [-f]
。
(8)功能:以指定的格式返回
指定的文件的相关信息。当不指定format 的时候,返回文件
的创建日期。
hadoop fs -stat [format]
。
(9)功能:创建一个
指定的空文件。
hadoop fs -touchz
。
(10)功能:创建指定的一个或多个文件夹,-p选项用于递归创建子文件夹。
hadoop fs -mkdir [-p] 。(11)功能:将本地源文件复制到路径指定的文件或文件夹中。
hadoop fs -copy FromLocal 。(12)功能:将日标文件复制到本地文件或文件夾中,可用-ignorearc 选项复制CRC
校验失败的文件,使用-crc选项复制文件以及 CRC信息。
hadoop ts -copyToLocal [-ignorecrc][-crc] 。(13)功能:将文件从源路径复制到日标路径。
hadoop fs -cp 。(14)功能:显示
指定的文件或文件夾中所有文件的大小。
hadoop fs -du
。
(15)功能:清空回收站.
hadoop fs -expunge。(16)功能:复制指定的文件到本地文件系统-指定的文件或文件夹,可用-ignorecrc 选项复制 CRC
校验失败的文件,使用-crc 选项复制文件以及 CRC信息。
hadoop fs-get [ignorecrc] [-crc] 。(17)功能:对指定的源目录中的所有文件进行合并,写入指定的本地文件。-nl
是可选的,用于指定在每个文件结尾添加一个换行符。
hadoop fs -getmerge [-nl] 。(18)功能:以本地文件系统中复制<1ocalsrc>指定的单个或多个源文件到指定的目标文件系统中,也支持从标准输人(stdin
)中读取输人并写人目标文件系统。
hadoop fs-put 。(19)功能:与put 命令功能相同,但是文件上传结束后会从本地文件系统中删除指定的文件。
hadoop fs-moveFromLocal 。(20)功能:将文件从源路径移动到目标路径
hadoop fs -mv 。(21)功能:删除
指定的文件,只删除非室日录和文件。
hardoop 1s -rm
。
(22)功能:除
指定的文什实及其下的所有文件,-r选项表示删除子目录。
hadop fs -rm -r
。
(23)功能:改变
指定的文件的副本系数,-R 选项用于递归政变目录下所有文件的副本系数。
hadoop fs-setrep [-R]
。
(24)功能:检查
指定的文什或文件夾的相关信息。不同选项的作用如下。
hadoop fs -test -[ezd]
。 ①-e检查文件是否存在,如果存在则返回0,否则返回 1。 ②-z检查文件是否是 0字节,如果是则返回 0,否则返回1。 ③ -d如果路径是个日录,则返回1,否则返回 0。
(25)功能:将
指定的文什输出为文木格式,文件的格式世允许是zip和TextRecordinputStream 等
hadoop ts -text
。
(26)查看帮助
hdfs dfs -help
(27)查看当前目录信息
hdfs dfs -ls /
(28)上传文件
hdfs dfs -put /本地路径 /hdfs路径
(29)剪切文件
hdfs dfs -moveFromLocal a.txt /aa.txt
(30)下载文件到本地
hdfs dfs -get /hdfs路径 /本地路径
(31)合并下载
hdfs dfs -getmerge /hdfs路径文件夹 /合并后的文件
(32)创建文件夹
hdfs dfs -mkdir /hello
(33)创建多级文件夹
hdfs dfs -mkdir -p /hello/world
(34)移动hdfs文件
hdfs dfs -mv /hdfs路径 /hdfs路径
(35)复制hdfs文件
hdfs dfs -cp /hdfs路径 /hdfs路径
(36)删除hdfs文件
hdfs dfs -rm /aa.txt
(37)删除hdfs文件夹
hdfs dfs -rm -r /hello
(38)查看hdfs中的文件
hdfs dfs -cat /文件
hdfs dfs -tail -f /文件
(39)查看文件夹中有多少个文件
hdfs dfs -count /文件夹
(40)查看hdfs的总空间
hdfs dfs -df /
hdfs dfs -df -h /
(41)修改副本数
hdfs dfs -setrep 1 /a.txt
八、HDFS实验之通过JAVA-API访问HDFS
1、Hadoop用户下进入Ubuntu

图56:Hadoop用户下进入Ubuntu
2、把eclipse拖到/home/hadoop/Downloads下
图57:把eclipse拖到/home/hadoop/Downloads下
3、检查一下是不是整个Ubuntu都在hadoop用户下,是的话,解压到/uer/local
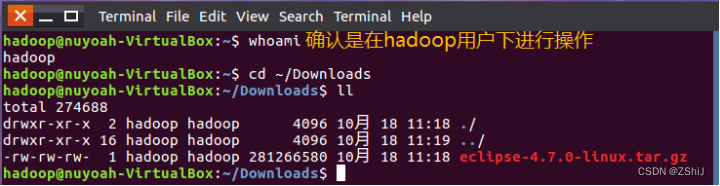
图58:确认是在hadoop用户下
在终端输入whoami,当出现hadoop表示现在是在hadoop用户下进行的操作(确保后面的操作能正常进行)。
进入Downloads查询当前文件夹所有文件,看eclipse安装包是否存在。

图59:解压eclipse安装包
在终端输入sudo tar -zxvf ./eclipse-4.7.0-linux.tar.gz -C /usr/local解压eclipse安装包。
图60:解压eclipse安装包完成
4、cd到解压后的文件夹/usr/local/eclipse,启动eclipse(启动指令./eclipse)
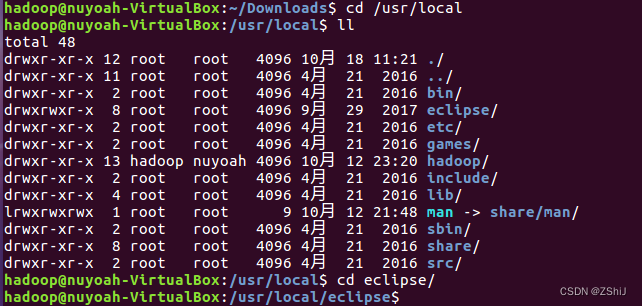
图61:检查解压情况
在终端cd到文件夹/usr/local内,查看是否有eclipse文件夹,如果有则解压成功。

图62:启动eclipse
在终端输入启动指令./eclipse启动eclipse。
5、默认workspace(这里必须是Hadoop用户下,如果是个人用户名下,就代表前面错误,你不是在Hadoop下完成的操作,会显示没有java路径)
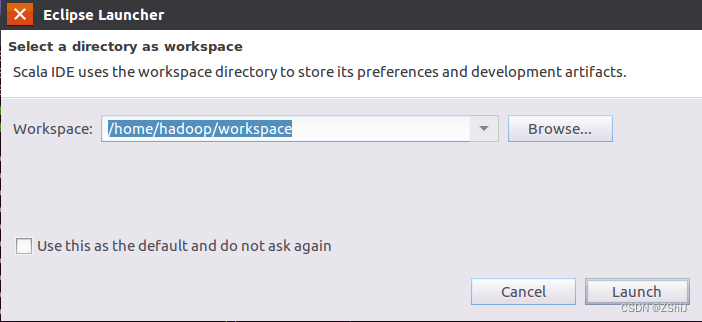
图63:默认workspace
默认workspace点击launch进入下一步。
6、启动成功
图64:启动eclipse成功
7、新建工程后选择java project,然后next
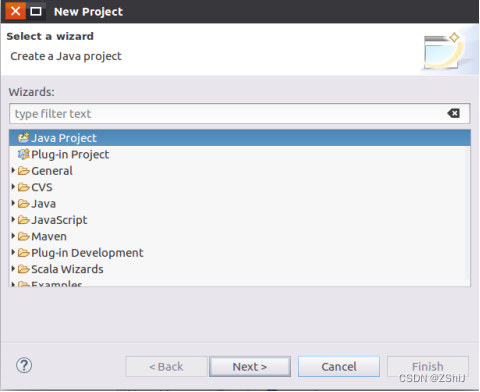
图65:新建工程
8、输入工程名称,其他默认即可,然后点击next
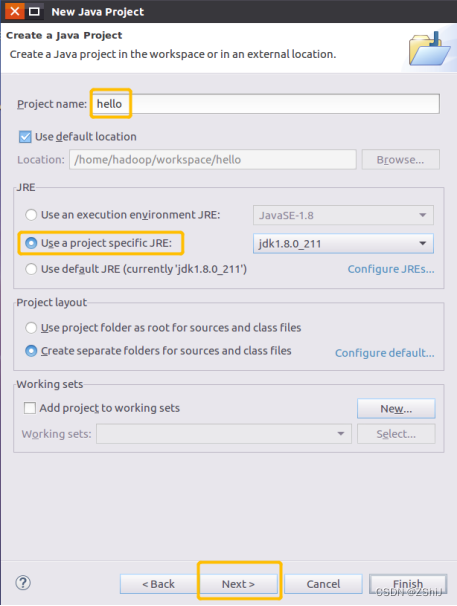
图66:输入新建的工程名称
9、点击libraries,添加jar包,添加完成后点击finish
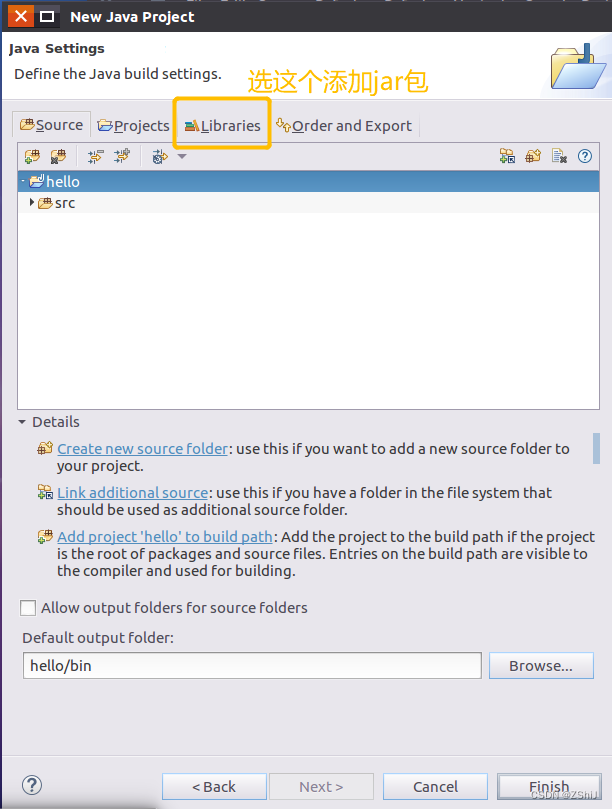
图67:添加jar包

图68:添加jar包
选择add external jars进行添加jar包。
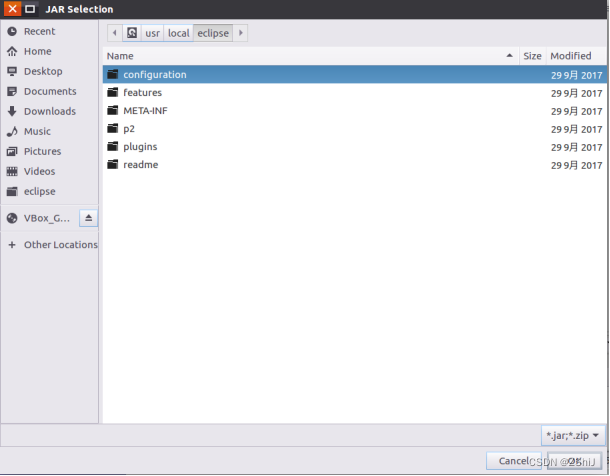
图69:添加jar包
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
图67:添加jar包
图68:添加jar包
选择add external jars进行添加jar包。
图69:添加jar包
[外链图片转存中…(img-AJ871EC7-1714676502656)]
[外链图片转存中…(img-aWSAHmfS-1714676502657)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

