
- 1PyCharm使用BitoAI插件调用ChatGPT,速度提升10倍!_pycharm怎么用ai插件
- 2100道python面试_python面试100题
- 3RocketMQ实战(三)之生产者、消费者
- 4使用Sivarc使PLC程序标准化
- 5Neo4j Spatial使用指南(一)
- 6[GIT]删除本地库;链接远程库的一些操作_vs2022 删除仓库
- 7【LLama】Llama3 的本地部署与lora微调(基于xturn)_llama3 lora
- 8DevExpress WinForms中文教程 - HTML & CSS支持的实战应用(一)
- 9Matplotlib箱线图的绘制_Python数据分析与可视化_matplotlib绘制箱线图
- 10什么是OLAP
计算机毕业设计hadoop+pyspark图书推荐系统 豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 知识图谱 图书大数据 大数据毕业设计 机器学习
赞
踩
该系统各个模块的实现细节:
1. 数据抓取模块实现
该模块使用Scrapy框架实现了对“豆瓣读书”网站上的图书数据的抓取。具体步骤如下:
- 分析目标网站:分析“豆瓣读书”网站的网页结构、URL链接等信息,确定需要抓取的数据。
- 定义爬虫:在Scrapy中定义Spider,包括指定起始URL、定义爬取规则和数据处理方法等。
- 解析页面:使用XPath或CSS Selector对HTML页面进行解析,提取出需要的数据,如书名、作者、评分等。
- 存储数据:将解析得到的数据存储到数据库中。
2. 用户模块实现
该模块实现了以下功能:
- 用户注册:用户可以通过注册页面填写用户名、密码、邮箱等信息进行注册,注册信息将被保存到数据库中。
- 用户登录:用户可以通过登录页面输入用户名和密码进行登录,系统会检查数据库中是否存在该用户,并验证账号密码是否正确。
3. 图书分类模块实现
该模块用于展示图书分类,并提供了分类查询功能。具体步骤如下:
- 提取分类信息:从数据库中提取所有的图书分类信息,如小说、历史、传记等。
- 展示分类信息:将提取到的分类信息在前端页面进行展示。
- 分类查询:用户可以选择一个特定的分类,系统会根据用户选择的分类来查询该分类下的所有图书信息,并将查询的结果展示在前端页面中。
4. 图书查询模块实现
该模块用于根据书名、书籍分类、作者和ISBN等信息筛选图书,分页查询的功能。具体步骤如下:
- 定义图书模型:通过Django内置的ORM框架创建图书模型,该模型定义了图书的各种属性,包括书名、作者、ISBN、价格、出版社等。
- 接收查询条件:用户可以在前端页面输入查询条件,如书名、作者、分类等,系统接收到这些查询条件后,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 数据查询:根据用户输入的查询条件,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 分页展示:使用Django自带的Paginator组件对查询结果进行分页,将其展示在前端页面中。
5. 协同过滤推荐算法实现
该模块实现了基于用户的协同过滤和基于物品的协同过滤算法。具体步骤如下:
- 构建评分矩阵:将用户对图书的浏览评分构建成评分矩阵,使用矩阵运算进行相似度计算。
- 基于用户的协同过滤算法:根据用户之间的相似度,预测目标用户对图书的评分,并为用户推荐相似性高的图书。
- 基于物品的协同过滤算法:根据图书之间的相似度,为用户推荐相似度高的图书。
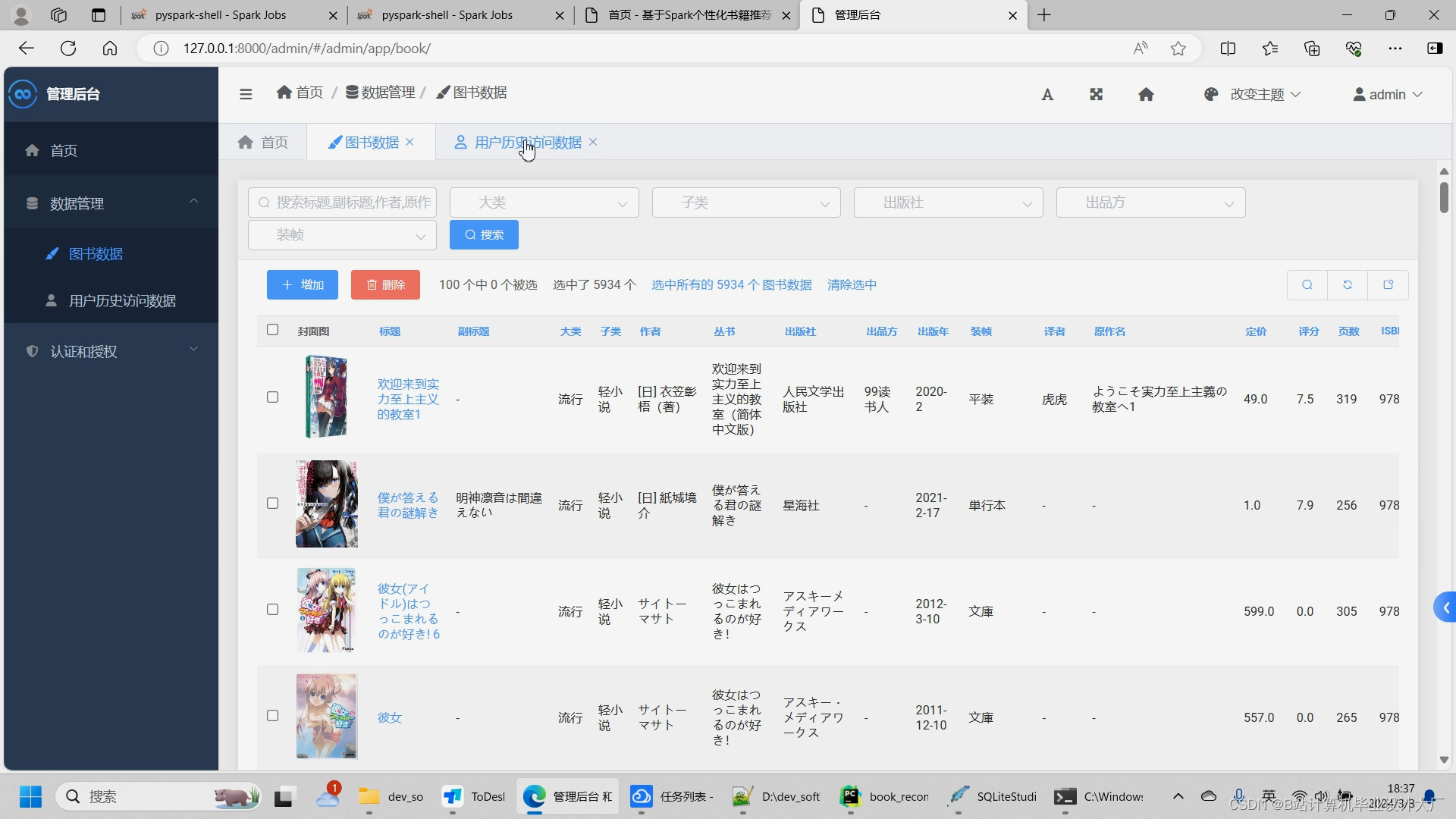
6. 后台管理模块实现
该模块提供了管理员对抓取到的图书数据进行管理的功能。具体步骤如下:
- 管理员登录:管理员输入用户名和密码,通过验证后进入后台管理系统。
- 数据管理:管理员可以查看和修改数据库中的图书信息,包括图书名称、作者、ISBN号、价格等。
技术及功能关键词:
python pyspark hadoop django scrapy vue element-plus 协同过滤算法
通过scrapy爬虫框架抓取“豆瓣读书”网站上的书籍数据
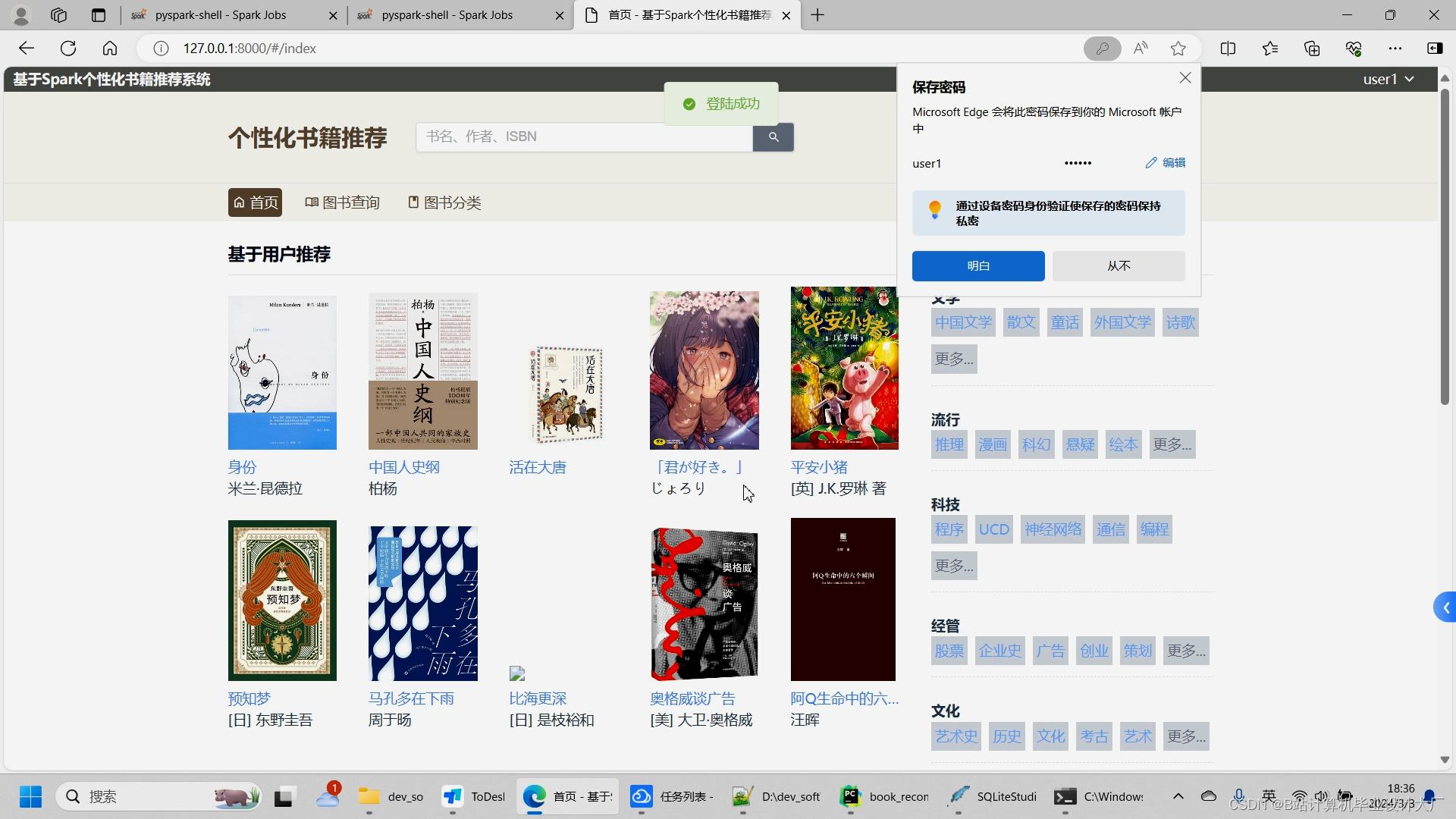
前台用户通过登陆注册后进入系统
管理员可在后台管理所有抓取到的图书数据
首页分为左右两侧,右侧展示所有图书的分类,比如文学、流行、科技、经管、文化、生活等大类,大类下亦有许多小类;左侧展示基于用户的协同过滤推荐算法给用户推荐的10个图书数据,下方是根据图书评分推荐的高分书榜
图书查询模块,可以根据书名、书籍分类、作者和ISBN等信息筛选图书,底部带有一个分页器,以10本书籍信息为一页实现分页查询,降低后端数据库的压力
图书分类模块,展示了所有图书的大类小类,用户可以通过点击某一分类,实现快速查找合适自己口味的图书信息
当用户访问某一书籍详情时,页面展示了图书的封面、作者、译者、出版社、出品方、类型、出版年、页数、装帧类型、ISBN等基本信息,还展示了图书的内容简介以及大纲等;在此页面的底部最后部分,我们向用户推荐了5本基于物品的协同过滤算法推荐的图书结果
————————————————




核心算法代码分享如下:

