
热门标签
热门文章
- 1WordPress安全防御攻略,2024年最新网络安全面试项目
- 2华为OD-2024年C卷D卷-欢乐的周末[200分](Python3 & Java)实现100%通过率
- 3Android studio实现仿微信界面_android studio 仿微信框架
- 4内网渗透之凭据收集的各种方式_credential dumping lsass
- 5pyqt5-tools的安装(深度学习)_pyqt5-tools安装
- 6系统学习区块链、Solidity 和前后端全栈 Web3 开发_前端后端区块链
- 7如何搭建一台永久运行的个人服务器?
- 8Java Stream map, Collectors(toMap, toList, toSet, groupingBy, collectingAndThen)等学习和使用理解及案例_java collectingandthen
- 9Python制作GUI小软件,VIP电影输入链接就能看。_代码在线vip影视会员怎么用
- 1020180611-前端系统学习-HTML之超链接_超链接前端显示
当前位置: article > 正文
《Python数据分析基础》笔记:“TypeError, 'int' object is not iterable”
作者:Gausst松鼠会 | 2024-06-09 03:24:42
赞
踩
int' object is not iterable
学习《Python数据分析基础》第3章最后一个例子:为每个工作簿和工作表计算总数和均值时,在pandas 实现这个例子中的data 处出现报错
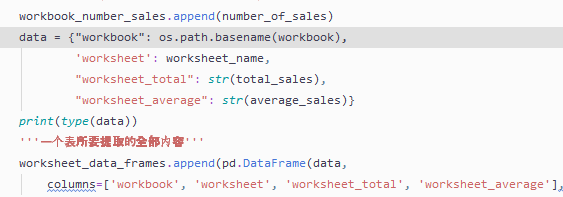
此处原例子没有添加str(),但是我运行是出现报错
TypeError, ‘int’ object is not iterable

找了半天没有解决,因为此处的
data = {"workbook": os.path.basename(workbook),
'worksheet': worksheet_name,
"worksheet_total": total_sales,
"worksheet_average": average_sales}
- 1
- 2
- 3
- 4
明显是一个dic格式,而
columns=['workbook', 'worksheet', 'worksheet_total', 'worksheet_average']
- 1
又是一个list格式,根本没有“int”object
但是报错一直过不了,只能一个一个的找,最后发现只有
data = {"workbook": os.path.basename(workbook),
'worksheet': worksheet_name,
"worksheet_total": total_sales,
"worksheet_average": average_sales}
- 1
- 2
- 3
- 4
处的
"worksheet_total": str(total_sales),
"worksheet_average": average_sales)}
- 1
- 2
存在"int"这样的数据结构,因而用str()强制字符串化

但是str()后又出现报错

需要索引,找到了博主August1226的文章《python – 解决If using all scalar values, you must pass an index问题》才解决了这个报错
在后面添加一个index = [0](ps:注意此处必须是[0],只是index = 0还是错的)
worksheet_data_frames.append(pd.DataFrame(data,
columns=['workbook', 'worksheet', 'worksheet_total', 'worksheet_average'],index = [0]))
- 1
- 2

但是即使这样,还是存在excel 文件中格式不正常的


试图使用列表推导式过滤,但是没有成功,筛选掉一些文件后,可以的,但是结果似乎还是不对

等待后续解决!!!!!!!!!!!!!!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/692405
推荐阅读
相关标签

