
- 1第十一章 大数据技术与实践_大数据技术与实践研究内容
- 2数据结构之堆(优先级队列)
- 32024最新分享Java面试题库万字精华 github上标星80
- 4【鸿蒙】大模型对话应用(一):大模型接口对接与调试_模型 接口
- 51+X大数据平台运维职业技能等级证书中级_+x大数据平台运维职业技能等级证书题
- 6JedisConnectionException: Unexpected end of stream._redis.clients.jedis.exceptions.jedisconnectionexce
- 7本机部署大语言模型:Ollama和OpenWebUI实现各大模型的人工智能自由_ollama本地部署设置中文回复
- 8GradNorm:Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks,梯度归一化_grad norm
- 9【Verilog】期末复习——设计11011序列检测器电路_verilog序列检测器11011
- 10SpringBoot-基于注解实现Redis限流_基于注解实现限流
软考 系统架构设计师系列知识点之大数据设计理论与实践(15)_大数据技术点 软考架构师
赞
踩
接前一篇文章:软考 系统架构设计师系列知识点之大数据设计理论与实践(14)
所属章节:
第19章. 大数据架构设计理论与实践
第4节 Kappa架构
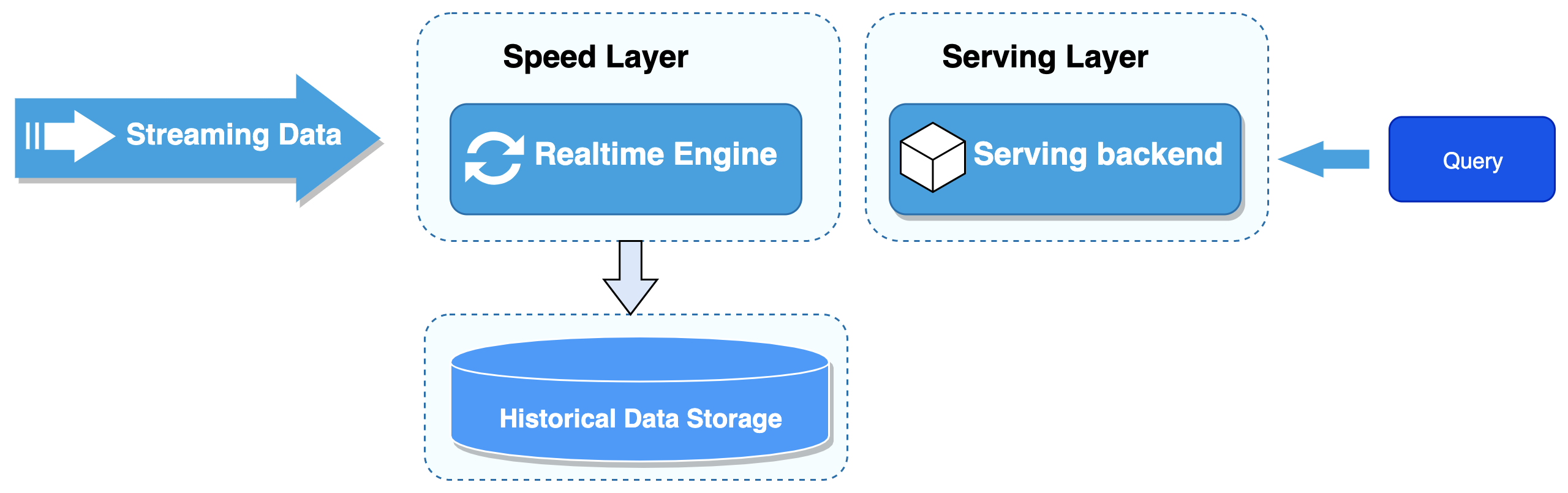
19.4.5 常见Kappa架构变型
1. Kappa+架构
Kappa+是Uber提出的流式数据处理架构,其核心思想是让流计算框架直接读取HDFS里的数据仓库数据,一并实现实时计算和历史数据backfill计算,不需要为backfill作业长期保存日志或者把数据拷贝回消息队列。Kappa+架构将数据任务分为无状态任务和时间窗口任务。无状态任务比较简单,根据吞吐速度合理并发扫描全量数据即可;时间窗口任务的原理是将数据仓库数据按照时间粒度进行分区存储,窗口任务按时间先后顺序一次计算一个partition的数据,partition内乱序并发,所有分区文件全部读取完毕后,所有source才进入下一个partition消费并更新watermark。事实上,Uber开发了Apache Hudi框架来存储数据仓库数据。Hudi支持更新、删除已有parquet数据,也支持增量消费数据更新部分,从而系统性解决了数据存储的问题。图19-11是完整的Uber大数据处理平台,其中Hadoop -> Spark -> 用户查询的流程涵盖了Kappa+数据处理架构。
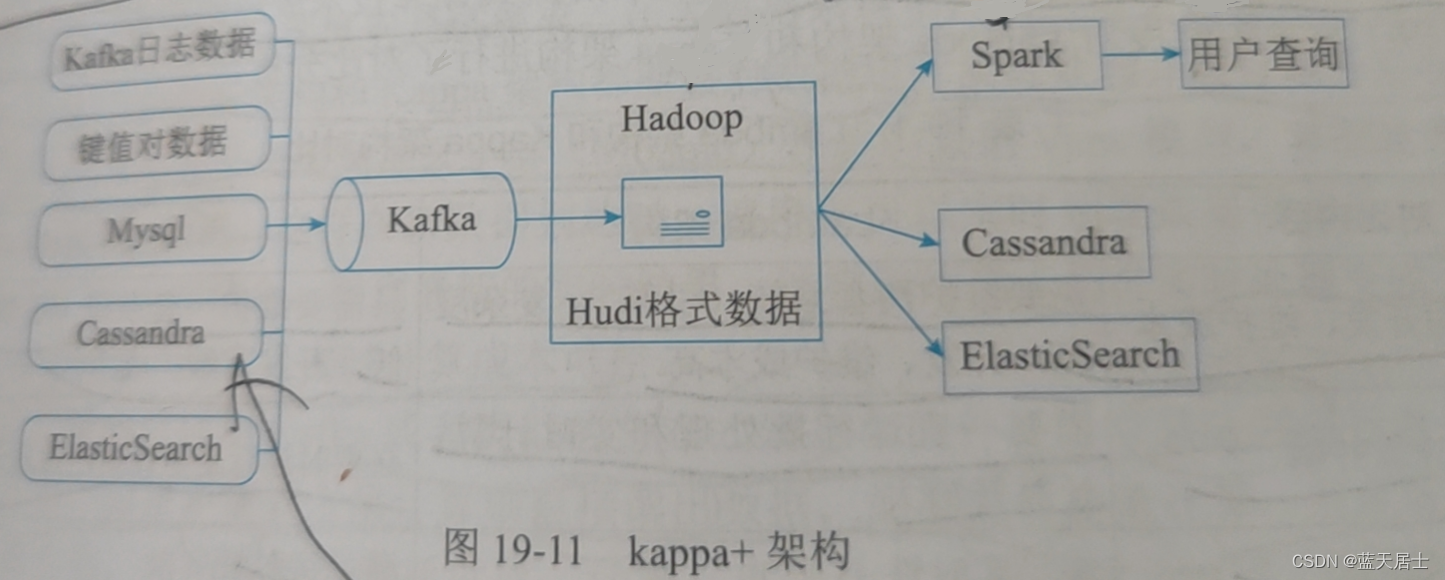
如上图所示,将不同来源的数据通过Kafka导入到Hadoop中,通过HDFS来存储中间数据,再通过spark对数据进行分析处理,最后交由上层业务进行查询。
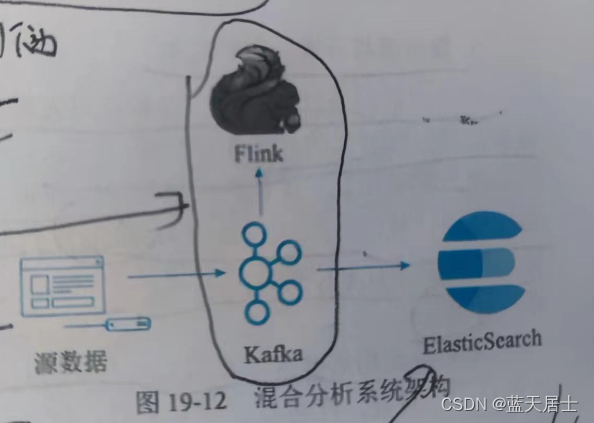
2. 混合分析系统的Kappa架构
Lambda和Kappa架构都还有展示层的困难点,结果视图如何支持热点数据查询分析,一个解决方案是在Kafka基础上衍生数据分析流程。
如图19-12所示,在基于使用Kafka + Flink构建Kappa流计算数据架构,针对Kappa架构分析能力不足的问题,再利用Kafka对接组合ElasticSearch实时分析引擎,部分弥补其数据分析能力。但是ElasticSearch也只适合对合理数据量级的热点数据进行索引,无法覆盖所有批处理相关的分析需求,这种混合架构其某种意义上属于Kappa和Lambda间的折中方案。
至此,“19.4.5 常见Kappa架构变型”的全部内容就讲解完了。更多内容请看下回。

