
热门标签
热门文章
- 1"不能为虚拟电脑 ubuntu 打开一个新任务"的解决办法
- 2【深度学习】详解 MAE
- 3算法通关村第九关-白银挑战二分查找与高频搜索树
- 4Python3 Selenium HTMLTestRunner 运行成功但没有生成测试报告的总结_xray不生成报告
- 5蓝桥杯-平方拆分_平方拆分组合数
- 6【数据结构】C语言实现单链表的基本操作
- 7深度学习(二)BERT模型及其一系列衍生模型_bert模型衍生
- 8第十一届蓝桥杯——解码_python小明有一串很长的英文字母,可能包含大写和小写。 在这串字母中,有很多连续的是重复的。
- 9xcode打包ipa_iOS逆向 教你重签名ipa包
- 10STM32矩形(矩阵)按键(键盘)输入控制LED灯 ——4*4矩阵按键源码解析_stm32 4×4矩阵同时按下
当前位置: article > 正文
IntelliScraper 更新 --可自定义最大输出和相似度 支持Html的内容相似度匹配
作者:Gausst松鼠会 | 2024-02-15 14:51:52
赞
踩
IntelliScraper 更新 --可自定义最大输出和相似度 支持Html的内容相似度匹配
场景
之前我们在使用IntelliScraper 初代版本的时候,不少人和我反馈一个问题,那就是最大输出结果只有50个,而且还带有html内容,不支持自动化,我声明一下,自动化目前不会支持,以后也不会支持,因为法律的问题,所以数据的前置和后置处理是需要自行处理,如有特殊需求,可联系我。
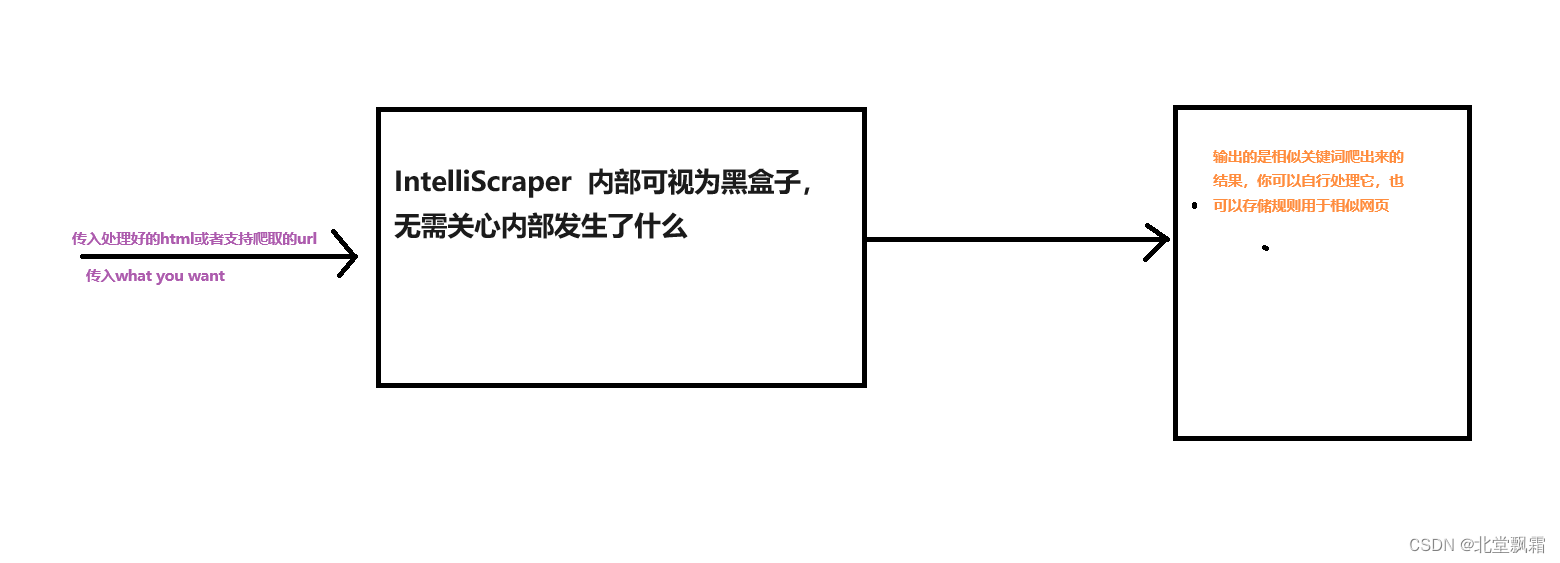
更新内容
最大关键字和相似度
此次更新,则是更新了最大关键字和相似度可以自己设置,你可以自己随意设置这些,直到拿到你想要的,原先的写法可能是
wanted_list = ['北堂飘霜']
scraper = WebScraper(wanted_list, url='https://blog.csdn.net/weixin_45487988?spm=1010.2135.3001.5343')
results = scraper.build()
for result in results:
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
结果和相似度都是内置的,你无法决定,结果最多50个,相似度0.7,更新之后,现在你的写法可能是:
wanted_list = ['北堂飘霜']
scraper = WebScraper(wanted_list, url='https://blog.csdn.net/weixin_45487988?spm=1010.2135.3001.5343',max_reasult=100,similarity=0.6)
results = scraper.build()
for result in results:
print(result)
- 1
- 2
- 3
- 4
- 5
你自己可以随意设置,并且对结果进行清洗。代码已经上传至github。
IntelliScraper
更新内容暂时没有发镜像,是因为要经过充分测试和考虑,后面如果更新镜像,令行通知!
支持Html的内容相似度匹配
如果说有些网页可能设置了延时加载机制,或者说在你请求的时候,没有完全加载元素,不用担心,我们现在提供了html的内容相似度匹配策略,该策略可以直接拿出两段html进行相似度匹配,代码可能是:
file_path = '/h10.html' # 替换为HTML文件的路径 with open(file_path, 'r', encoding='utf-8') as file: html_content = file.read() file_path = '/h11.html' # 替换为HTML文件的路径 with open(file_path, 'r', encoding='utf-8') as file: target_html = file.read() # 使用函数寻找相似元素 similar_elements = find_similar_elements(html_content, target_html, 0.4) print(len(similar_elements)) # 打印结果 all_link = [] for el in similar_elements: # print("------") print(el.text) # print(el.__str__()) # print("------") # 提取链接 unique_links = extract_unique_links(el.__str__()) # 将链接写入文件 all_link.append(unique_links) # print(unique_links) write_links_to_file(all_link, '/unique_links.txt')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这段代码很好的演示了如何在h10中找到h11的相似元素,在这里我做了后续数据清洗的工作,它能够很好的达到我的预期,同样的,并没有发镜像,待其彻底稳定后,会更新镜像。
结束
IntelliScraper 更新 --可自定义最大输出和相似度 支持Html的内容相似度匹配,你学废了吗?赶紧用起来,觉得好用,不要忘记点个star支持一下呦!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/85120
推荐阅读

相关标签

