
- 1Kotlin 与 Java有什么区别(最全最新的)_java和kotlin
- 2【入门必看】MJ和SD的区别_ai绘画mj和sd差别
- 3陀螺产业区块链第七季 | 基于区块链的工业资源协同平台
- 4WanAndroid(鸿蒙版)开发的第四篇_鸿蒙 tabbar subtabbarstyle
- 5Vxe UI vue vxe-table 实现表格数据分组功能,根据字段数据分组_vxe-table分组展开
- 6GPU虚拟化技术
- 7Unity牛人博客,不断学习中......_unity 大佬博客
- 8android 各国语言对应的缩写
- 9Arduino使用ESP8266模块联网
- 10【红日靶场系列】ATT&CK红队评估1_01 att&ck红队评估
centos7搭建hadoop集群_在centos上搭建hadoop建
赞
踩
先期准备
| 主机 | 系统 | ip地址 |
|---|---|---|
| hadoop-master | centos7 | 192.168.196.162 |
| hadoop-slave1 | centos7 | 192.168.196.163 |
| hadoop-slave2 | centos7 | 192.168.196.164 |
ps:大家使用克隆的方式复制多个独立的虚拟机,每个虚拟机创建一个hadoop用户并加入到root组中useradd -m hadoop -G root -s /bin/bash 利用 passwd hadoop 配置密码遇到提示说密码简单就再输入一次
软件点击下面的下载:
jdk-8u121-linux-x64.rpm 或者访问 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
hadoop-2.7.3.tar.gz 不能下载的请访问 http://hadoop.apache.org/releases.html
网络配置
配置ip和主机名,hosts映射
利用root用户登陆hadoop-master主机上配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33- 1
打开网卡编辑如图
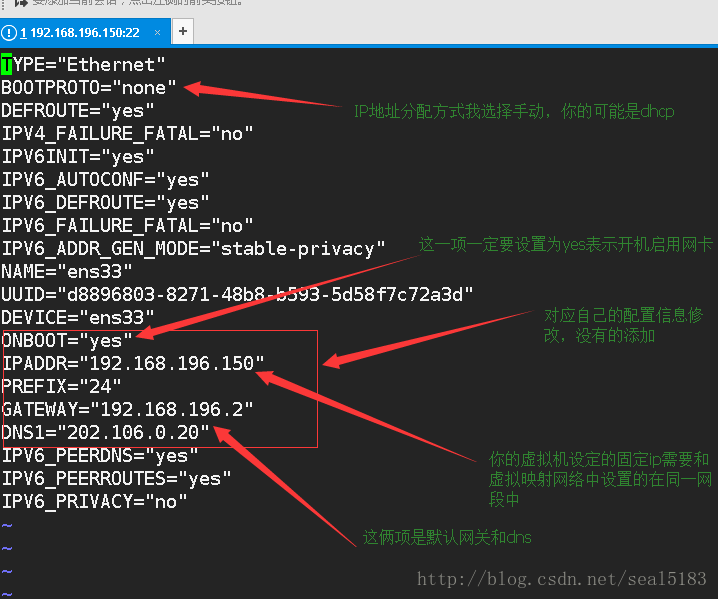
注意如果你是克隆的虚拟机那么每个虚拟机的网卡UUID是一样的,这个不行,所有要删除这个,让它自动在生成一个
重启网络服务systemctl restart network
我的实验是把上面图中的ip地址改为192.168.196.162 默认网关设置为192.168.196.2 为什么这么做,根据什么要看看你的虚拟机网络编辑器 这个在虚拟机菜单 编辑 中 我的设置如图:
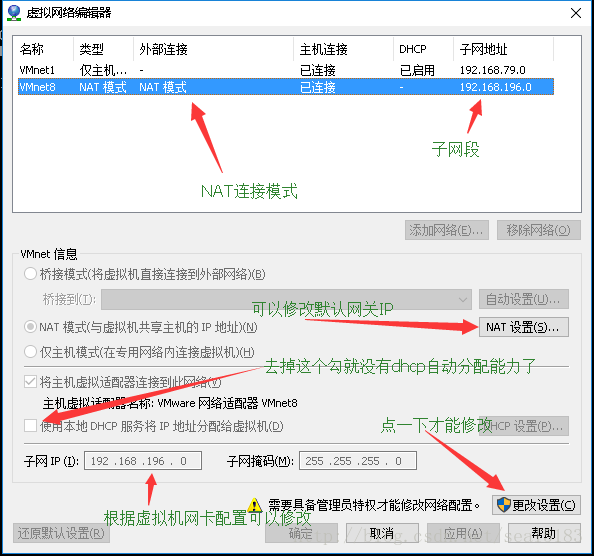
如果你在上图中设置取消了DHCP那么你想让你的电脑访问虚拟机就设置你的电脑中
配置静态IP如我一样
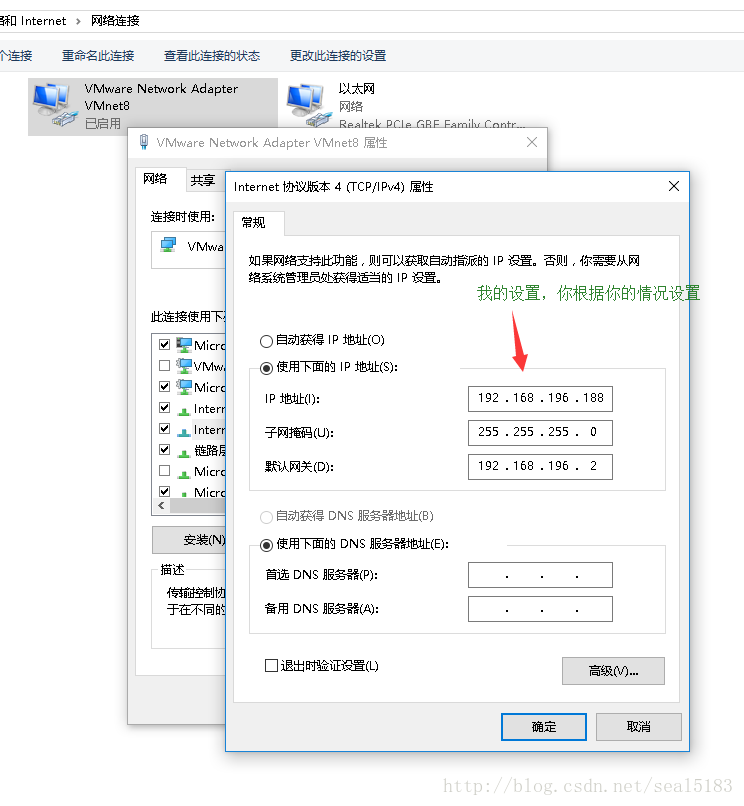
至此我们的主机和虚拟机就互通了,虚拟机还能访问外网。但是一定要明白我上面的设置。
修改hostnamevi /etc/hostname 删除原有内容添加 hadoop-master 保存退出vi
修改hosts vi /etc/ 添加如下图内容

保存退出,重启虚拟机。在每个虚拟机里重复修改网卡(ifcfg-enss*),hostname,hosts 的步骤,重启后测试互通性
要求在hadoop-master中能ping通slave1,slave2。其它任何一个虚拟机中都能ping通另外连个才行
例如:
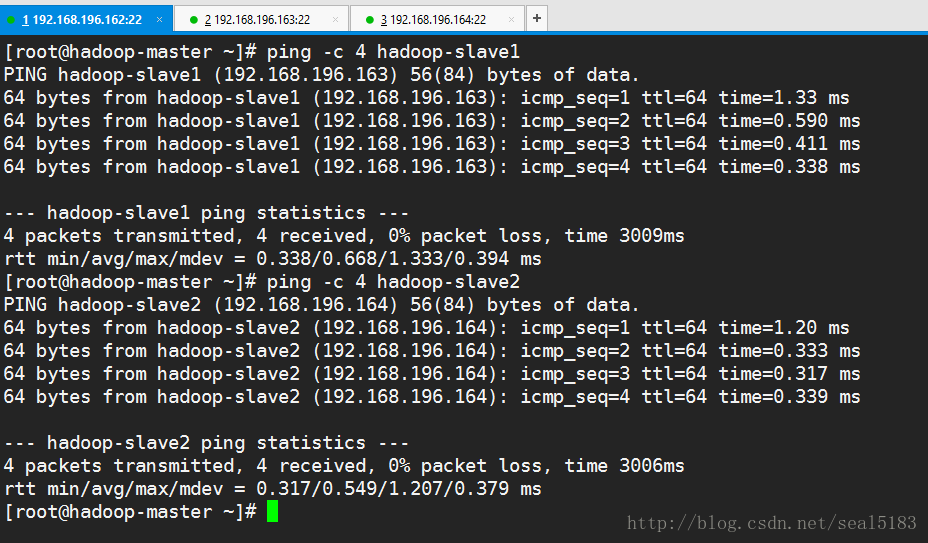
配置ssh无密码登陆到slave1,slave2上
检查每个虚拟机上是否安装了ssh 和 启动了sshd服务
rpm -qa | grep ssh
如图所示表示安装了
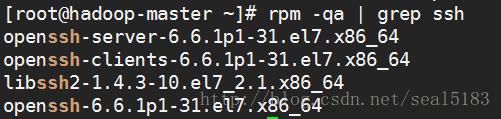

如果没有安装请执行下面的代码:
yum -y install openssl openssh-server openssh-clients- 1
退出所有虚拟机上root登陆用户,使用hadoop用户登录
在每个虚拟机上执行 ssh localhost 测试一下,最好都做一下,非常有用,会生成 .ssh 隐藏文件夹,遇到提示输入yes
如图
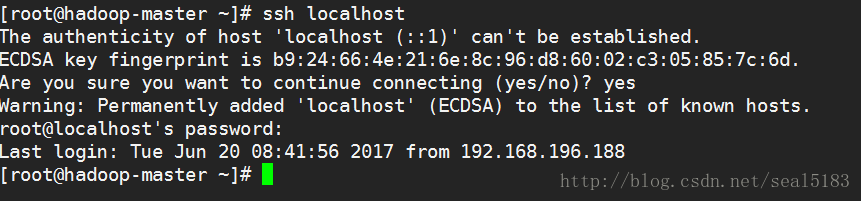
在hadoop-master虚拟机上生成ssh密钥
cd .ssh
ssh-keygen -t rsa #遇到提示一路回车就行
ll #会看到 id_rsa id_rsa.pub 两文件前为私钥,后为公钥
cat id_rsa.pub >> authorized_keys #把公钥内容追加到authorized_keys文件中
chmod 600 authorized_keys #修改文件权限,重要不要忽略- 1
- 2
- 3
- 4
- 5
至此hadoop-master可以无密码登陆自己了,测试 ssh localhost 不再提示输入密码,如果不争取请检查少了上面那一步
将hadoop-master的公钥传送到所有的slave上,实现hadoop-master无密码登陆到所有slave上
scp authorized_keys hadoop@hadoop-slave1:~/.ssh/
scp authorized_keys hadoop@hadoop-slave2:~/.ssh/- 1
- 2
hadoop登陆到每个slave上执行
cd ~/.ssh
chmod 600 authorized_keys - 1
- 2
测试hadoop-master ssh登陆hadoop-slave1,hadoop-slave1观察是否需要输入密码,如果不需要则成功,否则失败,请检查以上步骤
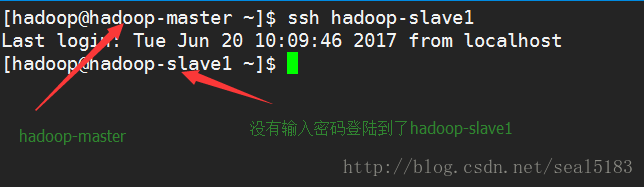
到这儿你就成功了一半了,加油,看好你哟!!!
jdk8+
使用xftp把jdk-8u121-linux-x64.rpm传送到每个虚拟机上
使用下面代码安装
sudo yum -y install jdk-8u121-linux-x64.rpm
如果出现这样的错误 hadoop 不在 sudoers 文件中。此事将被报告。
可以使用两种途径解决
a:切换到root用户
su
yum -y install jdk-8u121-linux-x64.rpm- 1
- 2
b:以后一劳永逸的做法
su
visudo- 1
- 2
之后输入:89 回车 添加 hadoop ALL=(ALL) ALL 注意不是空格是制表符
如图:
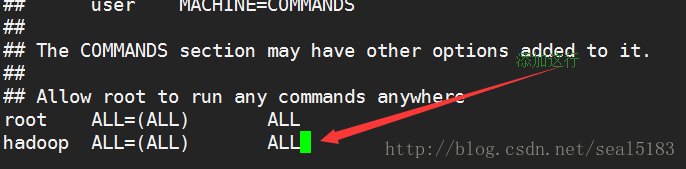
保存后退出 就是先 esc 之后输入 :wq
之后退出root 就是输入exit
在执行sudo yum -y install jdk-8u121-linux-x64.rpm 输入hadoop密码ok
设置环境变量,我使用本地环境变量,默认安装的jdk在/usr/java/jdk1.8.0_121
vi ~/.bashrc
添加
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin- 1
- 2
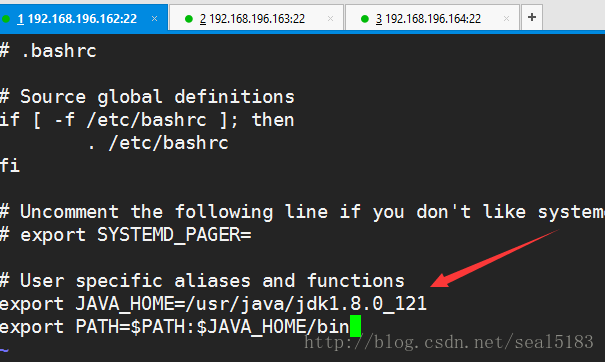
退出保存
执行source ~/.bashrc
测试是否成功java -version

记住每台上面都做
hadoop配置
使用xftp把hadoop-2.7.3.tar.gz传送到每个虚拟机上
使用tar -xzvf hadoop-2.7.3.tar.gz 解压
配置hadoop环境变量 vi ~/.bashrc 我的hadoop安装目录/home/hadoop/hadoop-2.7.3
添加
# Hadoop Environment Variables
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编辑如下5个文件 在 /home/hadoop/hadoop-2.7.3/etc/hadoop 目录中
1.core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/tmp</value>
</property>
</configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/tmp/dfs/data</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
</configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.slaves
hadoop-slave1
hadoop-slave2- 1
- 2
在每个虚拟机的/home/hadoop/hadoop-2.7.3/etc/hadoop 目录中都要改成一样的,不如改一份上传的每个地方来的方便。
运行案例
关闭防火墙和selinux
切换到管理员
su
systemctl stop firewalld
setenforce 0- 1
- 2
- 3
在每个机子上执行,上面的做法是临时关闭
启动hadoop集群
hdfs namenode -format #第一次启动要执行格式化,之后启动不用执行这个
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver- 1
- 2
- 3
- 4
在hadoop-master 执行 jps
看到如下算成功
[hadoop@hadoop-master ~]$ jps
3345 NameNode
3529 SecondaryNameNode
3962 JobHistoryServer
3678 ResourceManager
3998 Jps
[hadoop@hadoop-master ~]$ - 1
- 2
- 3
- 4
- 5
- 6
- 7
在hadoop-slave1 和 hadoop-slave2上 执行jps
看到如下算成
hadoop-slave1中
[hadoop@hadoop-slave1 ~]$ jps
3142 DataNode
3357 Jps
3246 NodeManager
[hadoop@hadoop-slave1 ~]$
- 1
- 2
- 3
- 4
- 5
- 6
hadoop-slave2
[hadoop@hadoop-slave2 ~]$ jps
3092 DataNode
3306 Jps
3196 NodeManager
[hadoop@hadoop-slave2 ~]$ - 1
- 2
- 3
- 4
- 5
上面的信息中数字表示进程ID,后面的字符表示进程名字
缺少任何一个进程表示集群启动失败
失败可以通过查看日志查找原因。
如果通过真机win访问hadoop web管理界面需要先配置真机的hosts文件它存在于C:\Windows\System32\drivers\etc 目录中
在文件中添加
192.168.196.162 hadoop-master
192.168.196.163 hadoop-slave1
192.168.196.164 hadoop-slave2- 1
- 2
- 3
之后访问 http://hadoop-master:50070 查看节点状态
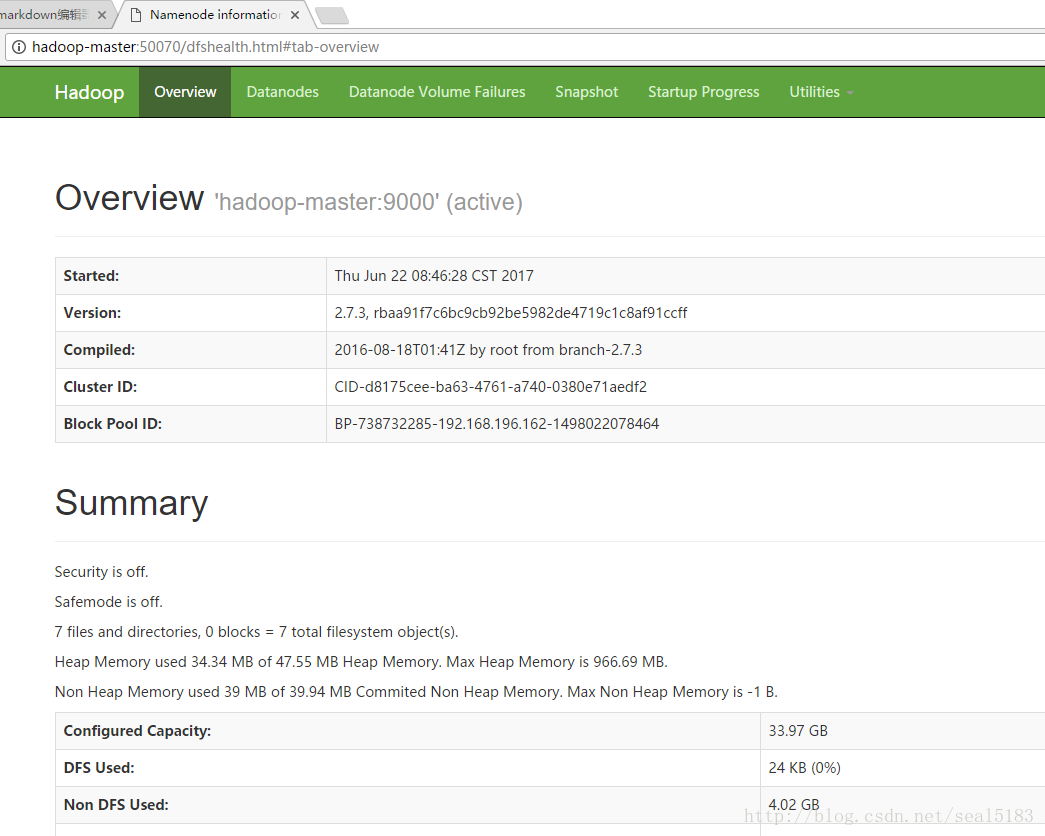
执行案例
先在集群上创建用户目录
hdfs dfs -mkdir -p /user/hadoop
接着创建资源文件目录
hdfs dfs -mkdir input
上传要分析的数据文件到input中
hdfs dfs -put hadoop-2.7.3/etc/hadoop/*.xml input
执行hadoop自带的案例,统计dfs开头的信息
hadoop jar hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
通过web查看任务执行情况
http://hadoop-master:8088/cluster
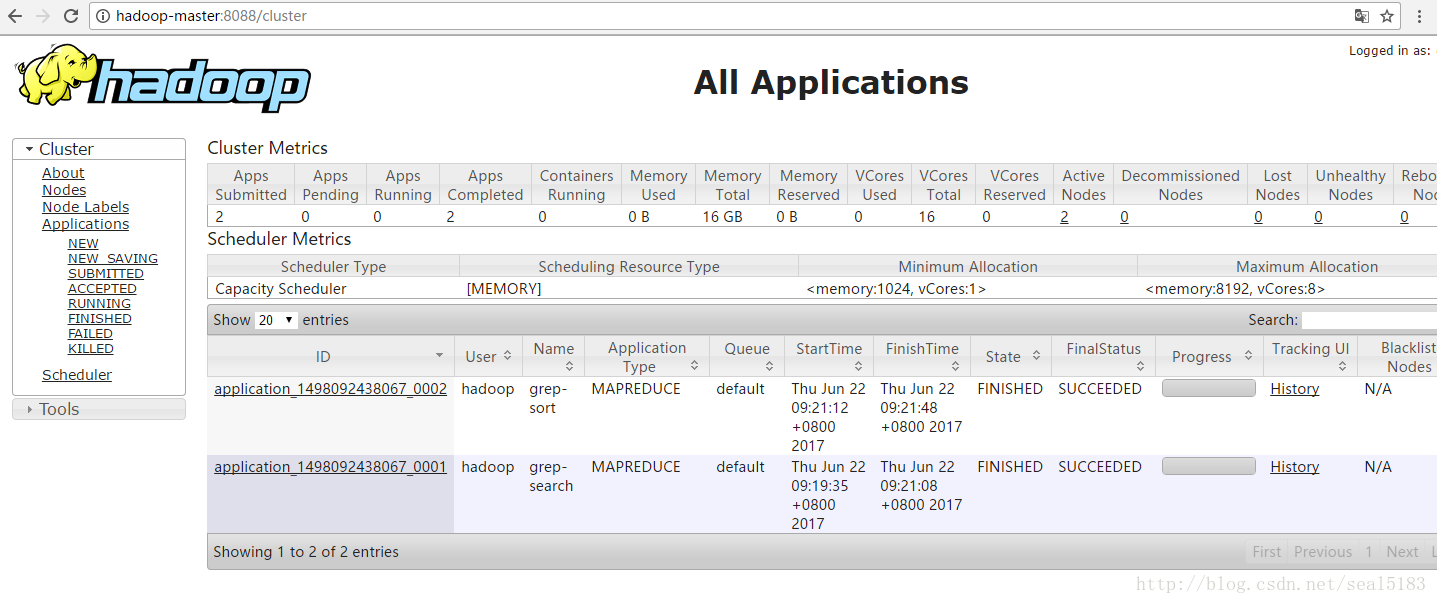
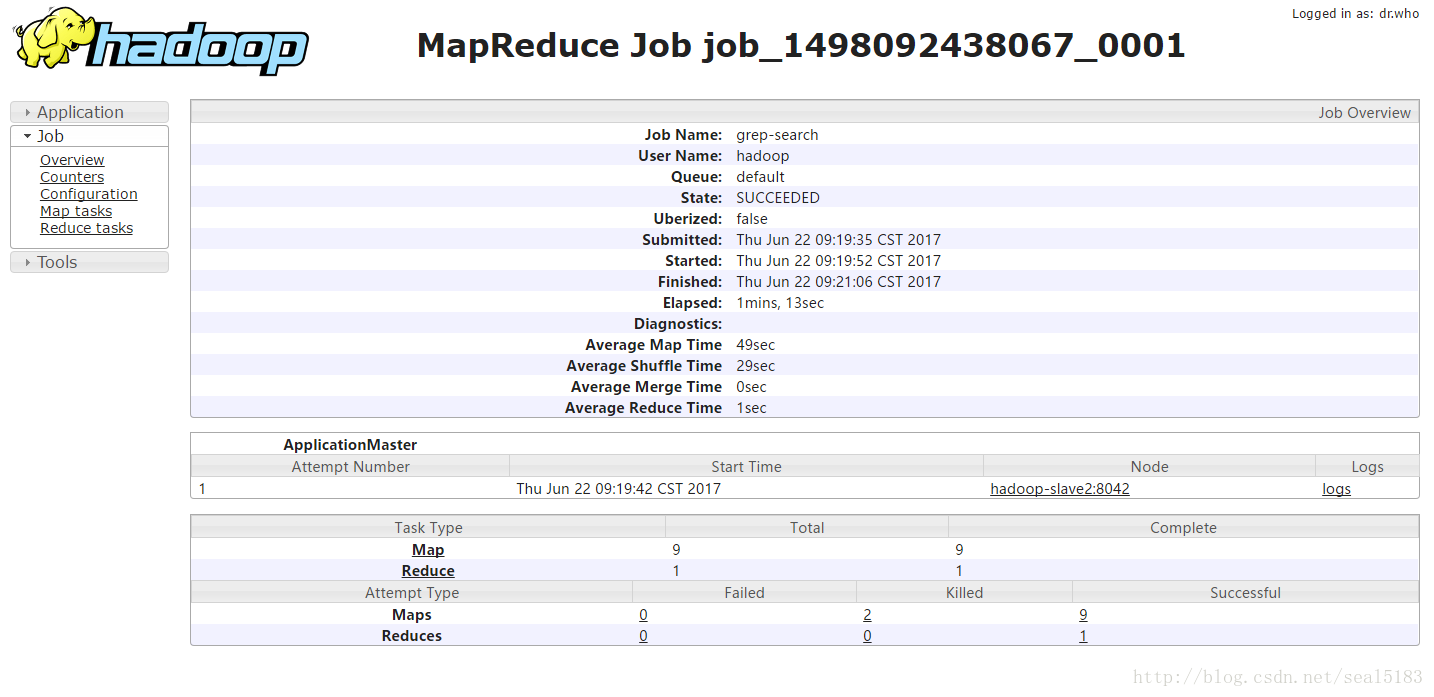
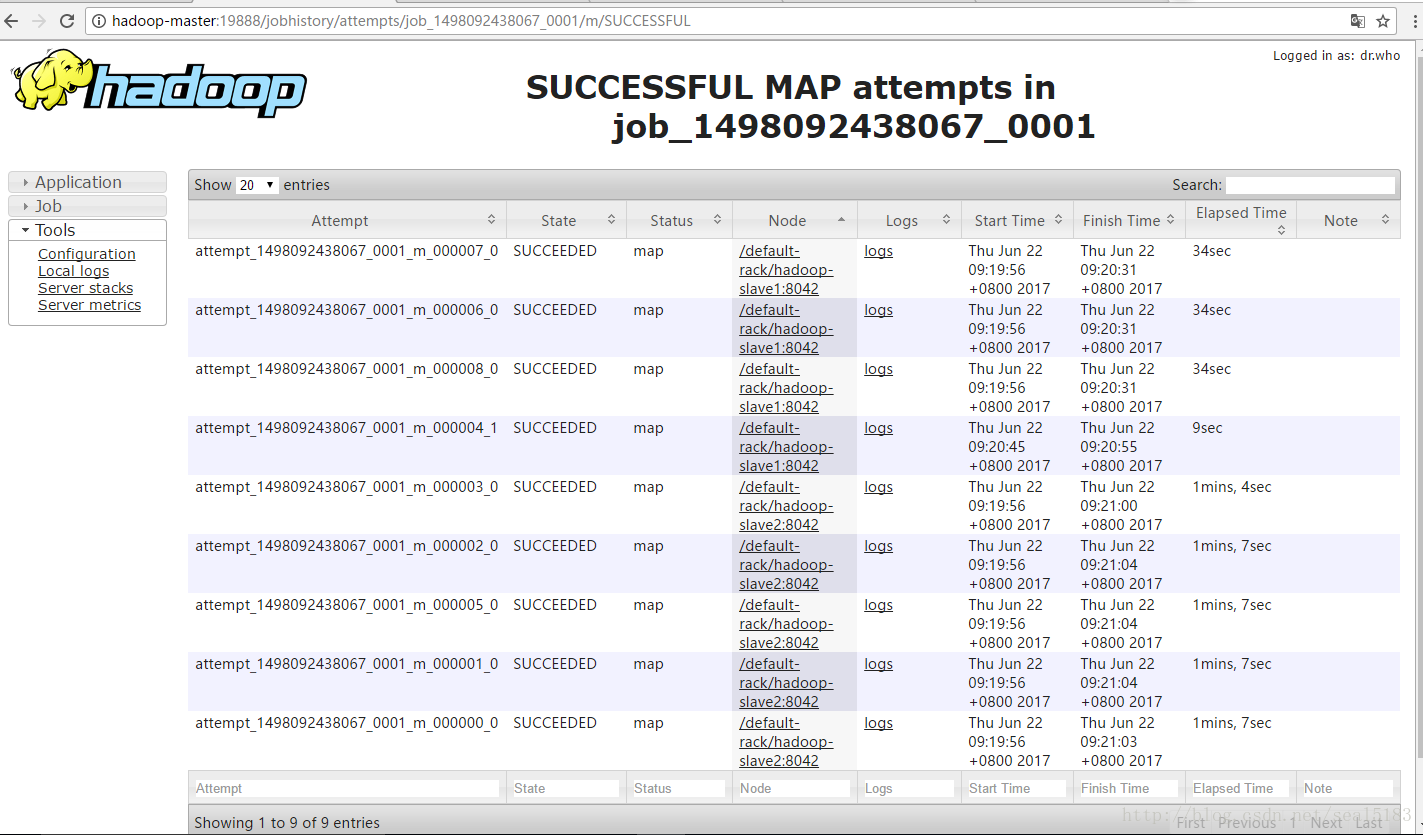
当然控台也有输出我就不截图了
查看输出结果:
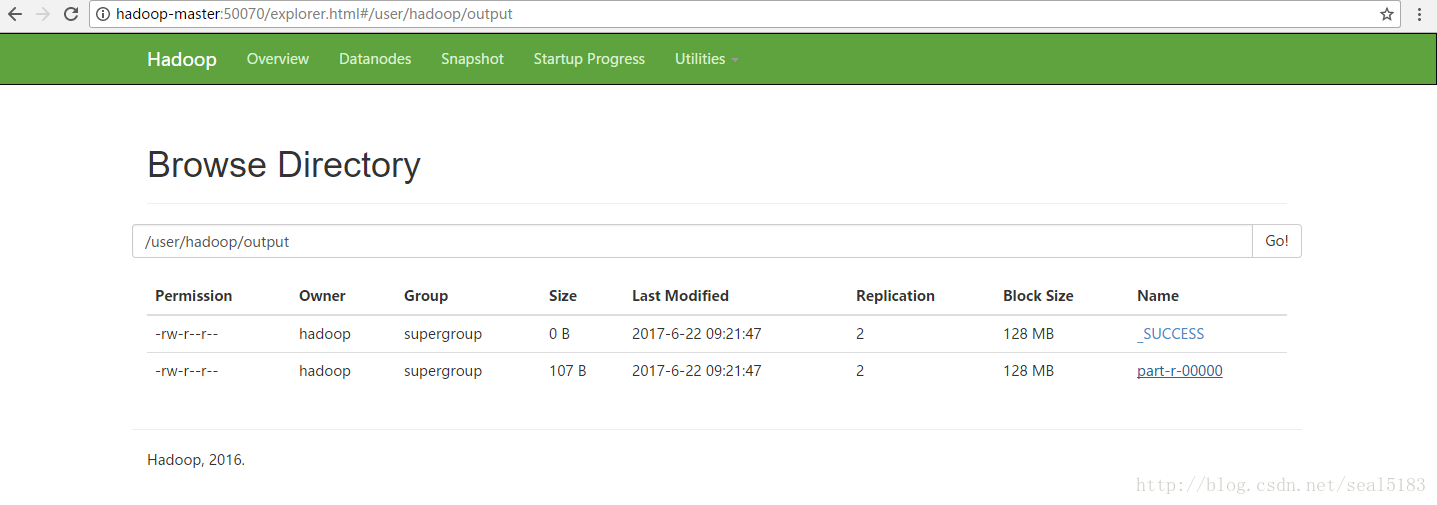
通过shell查看统计结果
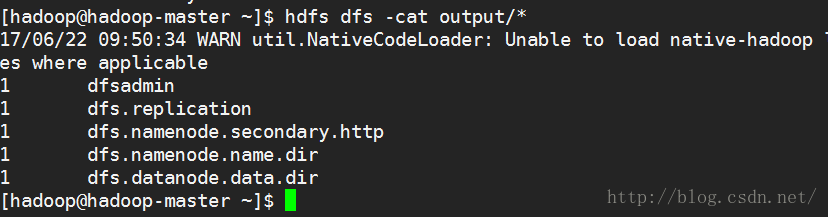
关闭集群服务,在hadoop-master上执行
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver- 1
- 2
- 3
怎么样你成功了吗?

