
- 1第一次面试经验总结_大疆社招难吗
- 2AI相关数学知识_ai的数学
- 3Android 平台版本所支持的 API 级别_android api34
- 4java基于Springboot餐厅点餐系统_java食堂简易点餐
- 5金融基础知识-基金管理公司投资限制+保险公司投资限制
- 6数据仓库建设
- 7【RELM分类】基于鲁棒极限学习机RELM实现数据分类附matlab代码
- 8PMP考试不用报班可以自学?_pmp 能自己不培训 自己考吗
- 9Maven 3 各版本 下载方法_maven下载
- 10初识python爬虫 Python网络数据采集1.0 BeautifulSoup通过网站css爬取信息_《web scraping with python: collecting data from th
告别答非所问!三大优化让企业应用整体问答准确率超 80%!
赞
踩

在上一篇文章《使用亚马逊云构建企业智能知识问答助手第一篇之架构演进》中我们通过一个真实客户案例介绍了 Chatbot 在企业内部应用中扮演的重要角色。随着自然语言处理技术的进步,尤其是大语言模型(Large Language Model,LLM)的兴起,Chatbot 的能力得到极大增强,可以进行更加开放域的对话,生成更加人性化的回复,满足复杂个性化需求。在这个项目中,Chatbot 的发展经历了三个阶段:第一阶段基于关键词匹配,需要大量人工准备数据;第二阶段基于 BERT 等 NLP 模型进行语义匹配,减轻了数据准备工作;第三阶段融入 LLM,进一步提高了理解和生成能力。
在第三阶段最初的 PoC 过程中,项目组曾经遇到了在 Retrieval-Augmented Generation (RAG) 的架构下 LLM 回答准确率的挑战,其中最主要的挑战包括:1. 召回精度不够;2. LLM 的输出结果不理想;3. 数据质量不佳。以至于最初始基于 150 个 IT 相关问题的问答准确率仅达到了不到 30%,离客户要求的 80% 以上的准确率还相距甚远。因此在后续努力提高准确率的过程中,针对架构图中的数据召回部分和 LLM 生成部分(关于架构图的介绍请参考上一篇文章),围绕着这三个问题逐一实施了优化步骤。作为系列博客中的第二篇,我们会专注于介绍项目组在 PoC 中,针对 Knowledge Base 类型的数据提高整体问答准确率的优化思路和实践过程。
提高召回精度
提高召回精度通常会使用的手段主要包括如下几种,在这个项目中主要采用了前三种,并且取得了不错的效果。
选择效果更佳的 Embedding 模型
根据源数据的特点进行合理的 Chunk 拆分
采用多路召回扩大召回的范围并引入 Reranker 模型
微调 Embedding 模型
优化传统倒排索引
Embedding 模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多 LLM 应用必不可少的部分。北京智源人工智能研究院(BAAI)开源了 BGE 系列 Embedding 模型,免费商用授权的大模型,可以满足多种需要。是中文 Embedding 模型中的优质选择。
在项目的第二阶段中项目组选择的是 bge-large-zh-1.5,对于目标用户都在国内和基于 BERT 的场景,已经取得了不错的效果。由于在第三阶段的需求中增加了对海外办公室的支持,除了最基本的中文问答外,还需要支持英语日语韩语的问答,以及在未来加入对于长文档的总结和问答功能。因此项目组延续了之前使用的 BGE 系列模型,采用了支持多语言的 BGE-M3 模型部署在 Amazon SageMaker 的 Inference Endpoint 上面。BGE-M3 相对于单一语言的 bge-large-zh-1.5,支持了超过 100 种语言,Token 输入长度也从 512 增加到了 8K。并且同时支持密集检索(Dense Retrieval)、稀疏检索(Sparse Retrieval)和多向量检索(Multi-Vector Retrieval)。
该项目涉及的文本数据均是 Knowledge Base 类型的短文章,大约 200 字左右。这些短文章主题集中,语义连贯性较强。如果对这类短文章进行切分,可能会破坏其语义的上下文完整性。因此,在处理这些短文本时,项目组决定保留文章的完整性,不对其进行进一步切分。相反,将每篇完整的短文章视为一个单独的数据单元(chunk)进行处理,以最大程度地保持语义的连贯性和上下文的完整性。这种做法避免了不当切分可能带来的语义破坏,更有利于对主题集中、长度较短的文本进行整体分析和语义建模,从而提高了处理效果和质量。从最终效果上看,对比一开始使用的下一代智能搜索和知识库解决方案中默认按段落切分的方式,召回准确率从最初的 55% 显著提升到了 79%。
随着 RAG 逐渐成为当前大模型落地方案的主流选择,搜索技术在这一过程中扮演着至关重要的角色。然而,仅依赖 Embedding 相似性检索往往无法达到理想的效果。因此,为了进一步提升搜索性能,我们需要将基于字面相似的传统搜索算法(BM25)与向量相似性检索相结合,实现混合搜索。BM25 是一种经典的信息检索算法,被广泛应用于信息检索领域。BM25 的核心思想是基于词频(TF)和逆文档频率(IDF)来,同时还引入了文档的长度信息来计算文档 D 和查询 Q 之间的相关性。通过估计文档 D 与用户查询 Q 之间的相关性,在处理长文档和短查询时表现出色。
在 PoC 过程中,项目组也注意到刚刚开源的新一代检索排序模型 BGE Re-Ranker v2.0,因此也选择了这个同一 BGE 系列的 reranker 模型来做 Embedding 和 BM25 双路召回的重排序。一个完整的重排序参考流程如下图所示:
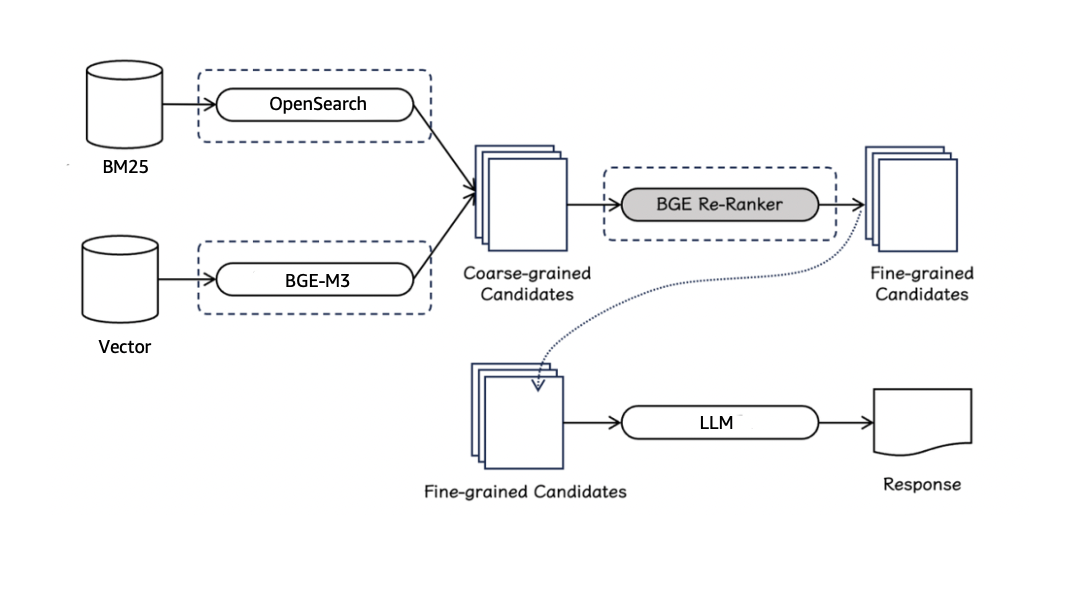
BGE Re-Ranker v2.0 系列排序模型采用了两种不同尺寸的模型基座,一种是基于 MiniCPM-2B,Gemma-2B 等性能卓越的轻量化大语言模型,另一种是基于性能出色、参数量更小的 BGE-M3-0.5B 模型。以上模型均通过多语言数据训练产生,具备多语言检索的能力。下图是在多语言评测 MIRACL 中,BGE Re-Ranker v2 对 BGE-M3 的 top-100 候选集进行重排的结果:

其中,BGE Re-Ranker v2-Gemma-2B 综合效果位居首位,而 BGE Re-Ranker v2-M3 则以较小的模型尺寸(0.5B)取得了与之相近的效果。综合考虑模型效果,模型的响应速度和模型部署的硬件要求,项目组选择了性价比最佳的 BGE Re-Ranker v2-M3 部署在 Amazon SageMaker 的 Inference Endpoint 上面。
项目组使用的多路召回加重排的逻辑如下:
利用 BGE-M3 基于 Embedding 召回 top2_1=[a1,a2]
利用 BM25 基于 Opensearch 关键词的倒排召回 top2_2 =[a3,a4]
recall_result = top2_1+top2_2=[a1,a2,a3,a4]
利用 BGE Re-Ranker v2-M3 模型进行重排得到四个分数,rerank(recall_result) = [score_1,score_2,score_3,score_4]
取分数最高的两个,如果分数最高的两个是同一篇文章,则只给 LLM 一篇文章的内容。
在实施了两路召回结合重排之后,同一批测试数据的召回准确率也从 79% 进一步提升到了 84%,这个提升基本上符合上图中官方给出的数据。并且在后续针对不同测试数据集的多轮测试中,召回准确率基本上都可以稳定的保持在 85% 左右。
选择大语言模型
在文章理解任务中,选择合适的大模型是获得佳绩的关键所在。首先需要考虑的是模型规模。通常规模越大,模型的表现就越优秀,能够更好捕捉语言的丰富语义和复杂上下文信息。因此建议选用参数量达数十亿甚至上百亿的大型模型。其次,模型的预训练语料质量和多样性也很关键。理想的语料应当覆盖广泛领域、风格和语境,包含高质量的中文数据。此外,全面客观的评估方法也不可或缺,需综合使用多种评估指标和测试集,可以选择 MMLU、HELM、AplacalEval 等常用评测数据集,避免评估结果的偏颇。最后,在实际应用中还需要权衡模型的推理效率、部署和维护成本等因素。总的来说,选择合适的大模型需要审慎考虑模型规模、预训练语料、评估方法及实际需求等多方面因素,才能在理解任务上取得理想的表现。除此之外,和 Embedding 模型一样,在大模型的选择上也需要综合考虑对多语言的支持能力、模型开源程度、模型的响应速度以及对硬件规格的要求。以选出一款性价比最优的大模型。
在大模型的验证过程中,因为 Amazon SageMaker 可以支持快速的部署和推理,项目组也能够在很短的时间内使用相同的数据集自动化的验证了多个大语言模型的准确率,包括 Baichuan2-13B、ChatGLM2-6B、ChatGLM3-6B、YI-34B、Mistral-7B、Mixtral-8x7B。本次,项目组基本上都是选择参数量相对较小的模型。从验证的结果来看,绝大多数情况下,模型的参数量很大程度决定了回答准确率,百亿参数级别的模型比十亿级别的模型在回答的准确率和逻辑上有较明显的优势。另外,项目组在几个中文模型上也发现了一些问题:比如,大模型的理解能力不足、幻觉问题较严重、回答更为活跃,不满足用户的严谨场景要求、复读机和拒答现象严重。
最终从这几个模型中项目组选择了 Mixtral-8x7B 的 4bit 量化版。当然除了看参数量级和其它模型上出现的一些难以接受的问题之外,还有一些其它原因让项目组选择了这款模型:
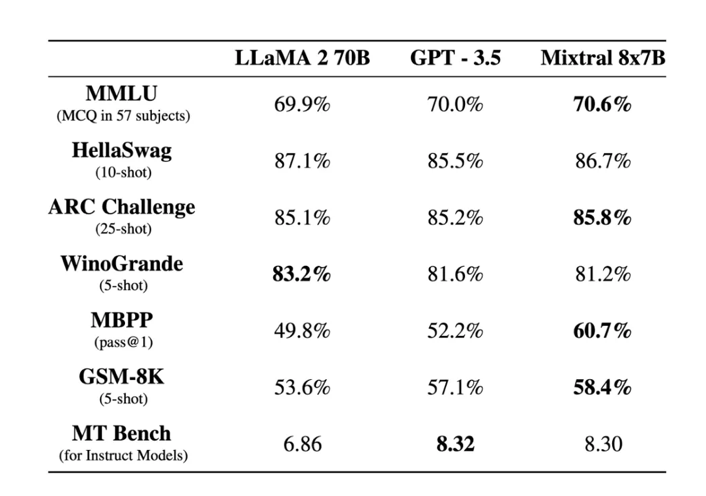
在 PoC 期间,Mixtral-8x7b 是在 LLM 排行榜中排名最高的开源模型,这必然会引起项目组的注意。下图是来自于 Mistral 官网的模型能力对比测试,可以看到 Mixtral-8x7b 在多个评测数据集中均已达到和超过 GPT-3.5 的能力。
Mixtral-8x7B 是一款采用稀疏混合专家机制即 Sparse Mixture of Experts Model(SMoE)的大语言模型,它在具有 46.7B 总参数的同时,每个 token 的预测只使用 12.9B 的参数。因此,它与 13B 模型有着相同的响应速度。
Mixtral-8x7B 对于世界各国语言的支持能力都是不错的,这也是没有简单的去使用一些大参数量的中文模型的原因。
相比于 Meta Llama 的许可,Mistral AI 选择了灵活性更强的 Apache 2.0 许可证来管理 Mixtral-8x7B。
Mixtral-8x7B 很早就登陆了亚马逊云科技的 Amazon Bedrock ,登录成功后,您就能在不需要自己部署模型的情况下就可在 Amazon Bedrock 上面进行快速的模型准确率验证。
部署大语言模型
在选择到正确的大语言模型之后,如何正确的把模型部署直至可以支撑生产环境下的推理任务也是至关重要的一步。项目组选择将 Mixtral-8x7B 的 4bit 量化版使用 Large Model Inference (LMI) 容器部署在 Amazon SageMaker Inference Endpoint 上面。LMI 容器是一组专门为大型语言模型推理而构建的高性能 Docker 容器。使用这些容器,您可以利用高性能的开源推理库,如 vLLM、TensorRT-LLM、DeepSpeed、Transformers NeuronX 将 LLM 部署到 Amazon SageMaker Endpoints 上。这些容器将模型服务器与开源推理库捆绑在一起,提供了一体化的 LLM 服务解决方案。关于 LMI 的详细介绍可以在参考链接中找到。
进入到部署的过程中,首先需要选择一个合适的机型配置。对于一个具有 46.7B 总参数的模型,即使是 4bit 量化版,仅仅加载模型本身就已经完全填满了一张 A10G 卡的 24GB 显存,再考虑到 KV cache 占用的显存空间和多用户同时请求时的并发要求,机型选择了拥有 4 块 A10G 的 ml.g5.12xlarge。
上面提到 LMI 容器提供了多种推理库供用户选择使用,那么接下来也需要选择其一来使用。推理库的选择需要考虑两点。一是这个推理库是否支持您所选择的模型,二是请求的输入输出长度是否比较固定。对于输入 token 数量和输出 token 数量都比较固定的情况,一般会建议使用 TensorRT-LLM。对于 token 数量和输出 token 数量在每次请求的变化都比较大的情况,一般会建议使用 LMI-Dist,vLLM 或者 DeepSpeed。当然,选择的前提还是要确认这个推理库的支持列表中有您要使用的模型。
使用 LMI 的一大好处是在模型的部署过程中,无论选择哪个推理库,您都可以用 serving.properties 来统一的指定模型部署的参数。如下是项目组在部署 Mixtral-8x7B-4bit 量化版所使用的参数:
- engine=Python
- option.model_id=s3://sagemaker-cn-northwest-1-3026341xxxx/aigc-llm-models/casperhansen/Mixtral-8x7B-Instruct-AWQ
- option.tensor_parallel_degree=4
- option.max_rolling_batch_size=64
- option.rolling_batch=vllm
- option.quantize=awq
左右滑动查看更多
其中:
在这个项目中,用户请求的输入 token 数量和输出 token 数量在每次请求的变化都比较大,因此我们使用 option.rolling_batch=vllm 来指定使用 vLLM 推理库,并且开启了 continuous batching 功能,目的是增加输入输出的吞吐。如果不确定应该使用哪个推理库,建议将 option.rolling_batch 设置为 auto,系统会自动选择最合适的推理算法。
engine 是推理代码的运行时,有两个选项,Python 和 MPI。两者如何选择取决于使用哪一个推理库,如果是 vLLM 就选择 Python,如果是 LMI-Dist 或者您设置的是 auto 的话,就选择 MPI。
option.tensor_parallel_degree 是模型推理使用的 GPU 数量。像 ml.g5.12xlarge 有 4 块 GPU,我们这里就设置成了 4。如果不确定自己的 GPU 数量的话,可以直接设置成 max 也可以。
option.quantize 根据模型所使用的量化方法来设置,像我们使用的模型是 Mixtral-8x7B-Instruct-AWQ,因此这里设置成 awq。其它的选项还有 GPTQ、SmoothQuant 和 INT8 等等。需要注意的是,不同的推理库能够支持的量化方式也不同,并不是每一个推理框架都支持所有的量化方法。
option.max_rolling_batch_size 的设置会影响到输入输出的吞吐量,它决定了在同一时间有多少请求可以被处理。根据公式 KV-Cache Size (bytes / token) = 2 * n_dtype * n_layers * n_hidden_size,可以算出每一个 token 所占用的显存空间。其中 n_dtype 代表模型中的每一个参数所使用的字节数,对于 4-bit 量化版的模型,n_dtype 就是 0.5。n_layers 和 n_hidden_size 分别代表模型 config.json 文件中的 num_hidden_layers 和 hidden_size。因此可以算出,Mixtral-8x7B-Instruct-AWQ 的每一个 token 占用 2 * 0.5 * 32 * 4096 = ~0.00013 GB 的空间。假设每个请求的输入加输出有 1000 个 token,那么每个请求就占用 0.13GB 的空间,这样我们就可以根据模型加载后的剩余显存空间来推算出当前配置可以同时容纳多少个请求。当然,这样计算出来的是一个理论最大值,option.max_rolling_batch_size 的默认值是 32,在这个基础上,您可以根据计算出的数字来逐步增加和减少这个参数,根据实测来获得一个最满意的效果。
此外,在亚马逊云科技中国区的 Amazon SageMaker 上部署模型的时候有一些要注意的事项:
如果因为网络原因无法使用 GitHub 上的一些样例代码直接拉取 huggingface 上的模型,可以选择在国内的一些第三方模型 Hub 上搜索是否有相同的模型提供,例如:
- !pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple -Uqq
-
-
- from modelscope.hub.snapshot_download import snapshot_download
- from pathlib import Path
-
-
- local_model_path = Path("./bge-reranker-v2-m3")
-
-
- local_model_path.mkdir(exist_ok=True)
- model_name = "Xorbits/bge-reranker-v2-m3"
-
-
- snapshot_download(model_name, cache_dir=local_model_path)
左右滑动查看更多
或者可以在一台网络条件允许的机器上用如下命令手动下载模型并上传到 Amazon S3 上面,例如:
- git lfs install
- git clone https://huggingface.co/<namespace>/<model>
-
-
- aws s3 cp model s3://my-model-bucket/model/ --recursive
左右滑动查看更多
然后在 serving.properties 中的 option.model_id 指定模型所在 Amazon S3 桶的 prefix 路径,例如:
option.model_id=s3://sagemaker-cn-northwest-1-3026341xxxx/aigc-llm-models/casperhansen/Mixtral-8x7B-Instruct-AWQ左右滑动查看更多
注意要使用中国区 SageMaker 的 DJL serving Deep Learning Container (DLC),例如:
inference_image_uri = f"763104351884.dkr.ecr.cn-northwest-1.amazonaws.com/djl-inference:0.26.0-deepspeed0.12.6-cu121"左右滑动查看更多
优化提示词
- PROMPT_TEMPLATE = """<s>[INST]<任务定义>
- 你是智能小助理,请用自然流畅以及专业的语言来回答用户问题。你的任务是帮助员工解答业务相关的问题。请默认使用中文回答问题,对于专有名词的复述与用户所使用的语言保持一致,不要自己编造改名。
- 下面将给你一个“问题”和一些“已知信息”。
- 如果可以从“已知信息”中获取答案,完整地回答用户的问题,答案请尽量引用原文,不要缺失任何相关信息,尤其是解决方案部分。
- 如果不可以从“已知信息”中获取答案,直接回答“我们暂时没有相关信息,后续会不断地更新知识库,如有任何问题,请联系xxx,电话400-xxx-xxxx。”。不要输出其他信息。
- </任务定义>
-
- <已知信息>
- {context}
- </已知信息>
-
- <问题>
- {question}
- </问题>[/INST]
- """
左右滑动查看更多
以上是项目组经过多轮测试之后针对 Mistral-8X7B 这个模型固定下来的提示词模版。其中:
<s> 是特殊的 Token,表示字符串的开始,[INST] 和 [/INST] 用于向经过指令调优的模型指示指令的位置,这也是 Mistral 官方给出的提示词格式。因为大模型通常是在专门构建的数据集上预先训练的,理论上遵从官方的提示格式可以让大模型更好的理解指令。
<任务定义> 用于表达明确的任务目标。针对不同的大语言模型,设计出一个合适的提示风格来指引它们来解决特定任务的能力是很重要的。简单来说,应该将提示表达为清晰的问题或详细的指令。比如在上面的提示词中,指定了模型的身份和它应该具有的能力,限定了它回答问题时的风格,规范和使用哪种语言来回答。同时,在能力比较优秀的大语言模型上,针对不同的召回内容,可以让它替我们做一些选择,从而完成更人性化的回答。比如在上例中我们要求大模型去判断能否基于给定的信息,直接把答案提供给用户。
<已知信息> 中存放多路召回 +Re-ranking 之后的结果。
<问题> 顾名思义就是我们要问大语言模型的问题了。
提升数据质量
在 PoC 的过程中,项目组发现问答的最终准确率很大程度上依赖于用户所提供 KB 类型文档的质量。例如 Confluence 里的内容组织上可能会出现一些无内容的母页面,并且在使用 Confluence 的 API 提取内容的时候,如果在文章中不做任何格式上的限定,很难提取到一些比较关键的段落信息。经过多轮的召回准确率和 LLM 回答准确率的测试,项目组也针对 KB 类型的数据总结出一些经验。基于这些经验,一方面可以对现存文章做相应的修正,另一方面也可以作为规范来指导未来文章的撰写:
在 Confluence 中避免出现无内容的母页面。
文章标题风格保持一致,例如都是疑问句,或都是陈述句。
文章标题内容尽量详尽,在使用缩写字母时,同时给出完整拼写。
正文段落分段方式保持一致。如分两段,第一段是问题描述,第二段是解决方案。
尽量使用 markdown 格式,Mistral 模型倾向于这种格式.
图片中的信息要有对应的文字描述并要求尽量具体。
避免出现内容重复或相似文章, 如有需要可以选择合并相似的文章。
在描述设备故障或设备连接指导的文章中,避免只给出设备型号,对设备类型要有描述。例如 xx 型打印机。
总结
为提高准确率,项目组从三个方面着手优化: 提高召回精度、选择合适的 LLM 模型,以及提升数据质量。
在提高召回精度方面,采用 BGE Embedding 模型进行语义相似度召回,并结合 BM25 关键词检索实现了混合召回策略。同时引入 BGE ReRanker 模型对候选结果进行重排序,最终将召回准确率从 55% 提升至 84%。
在 LLM 模型选择上,综合考虑模型规模、预训练语料、评估方法、推理效率等因素,最终选择了开源的 Mixtral-8x7B 模型。该模型在多语言支持、响应速度、开源许可等方面表现出色。
在提升数据质量上,总结了一些优化数据质量的经验,如避免无内容页面、保持标题风格一致、分段方式统一、使用 markdown 格式等,以修正现有数据集并指导未来知识库文章的撰写。
通过上述多方面的优化,LLM 知识问答系统的整体准确率最终被显著提升到了 80% 以上,为企业内部应用提供了更智能、人性化的服务。
本篇作者

郭松
亚马逊云科技解决方案架构师,负责企业级客户的架构咨询及设计优化,同时致力于 Amazon IoT 和存储服务在国内和全球企业客户的应用和推广。对企业级存储应用的高可用架构、方案及性能调优有深入研究。

原媛
亚马逊云科技解决方案架构师,负责基于亚马逊云科技云计算方案的架构咨询和设计实现,具有丰富的解决客户实际问题的经验,同时热衷于时间序列数据分析的相关研究与应用。

张雪菲
亚马逊云科技生成式 AI 创新中心应用科学家,拥有丰富的文本语义理解、文本生成等领域实践经验。她目前致力于大模型生成应用的研发,负责亚马逊云科技与合作伙伴共同构建生成式人工智能解决方案。并推动相关生态系统合作。

熊俊峰
亚马逊云科技行业解决方案架构师,主要领域包括人工智能与机器学习、制造业和医疗健康。负责国家医学影像云平台的产品架构设计和图像处理算法的开发工作。研究方向包括大语言模型和计算机视觉等,以第一作者发表 SCI 和国际会议论文 13 篇,以第一发明人申请发明专利 11 项。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!

