
- 1AnythingLLM教程系列之 02 AnythingLLM 允许您自定义实例的外观和风格,以匹配您的品牌和身份。_anyllm
- 2【python + django + bootstrap】Web开发试用_python+django+bootstrap业务
- 3kafka零拷贝_kafka 零拷贝
- 4JDK 8新特性——Lambda表达式_java8优雅开启线程
- 5Tomcat漏洞修复纪实_cve-2016-5388
- 6STM32移植FreeRTOS(图文实操)_stm32bootloader跳转到freertos
- 7python 'type' object is not subscriptable 是什么意思
- 8【人脸识别】初识人脸识别
- 9postgresql_internals-14 学习笔记(三)冻结、rebuild_pg判断当前元组是否被冻结
- 10git分支管理(三)_怎么看分支代码什么时候合进来的
DataHub安装配置详细过程_datahub部署
赞
踩
DataHub-----安装教程
Datahub,在国内使用的比较少,相关资料也比较少,具体是做什么的资料之类的,可以去看官方文档了解一下,这里我就不多做说明,毕竟我也是小白一个,这篇文章主要会写安装教程,具体哪一步是干啥的,就不要仔细问那么多了,我现在也还在研究阶段,这里就介绍一下步骤避免大家遇到坑,如果需要深入学习,请自学Py docker 官方文档等等等等。
安装步骤参考了官方文档:DataHub官方文档
以及大神的文章,这里附上传送门Datahub安装配置—附带详细步骤
同时简书上也还有一篇安装的教程,可以参考(但是我失败了)安装DATAHUB
因为我的电脑是全新的虚拟机,只安装了jdk,以及hadoop,所以其他的东西并没有安装太多。但是我整体安装下来发现还需要gcc,这个可以提前先安装一下(报错了好多次,才好不容易发现解决)
yum -y install gcc
- 1
1:然后就可以按照官方文档的内容来,需要安装docker 和 dockerCompose

命令如下:
$ yum -y install docker
# 启动docker
$ sudo systemctl start docker
# 测试是否正确安装
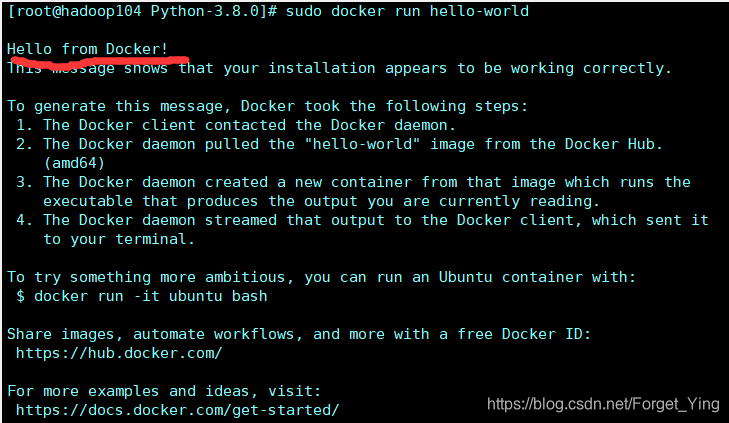
$ sudo docker run hello-world
- 1
- 2
- 3
- 4
- 5
这一步做完应该是
接下来是dockerCompose【docker的服务编排工具,主要是用来构建多个服务】,这两步正常复制粘贴着来,一般是没有什么问题 :
$ curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
$ chmod +x /usr/local/bin/docker-compose
- 1
- 2
- 3
然后启动docker
守护进程重启
$ sudo systemctl daemon-reload
重启docker服务
$ sudo systemctl restart docker
// 然后检查启动
$ docker container ls
- 1
- 2
- 3
- 4
- 5
- 6
这个执行完应该会看到这个,而且是没有任何信息。

这些步骤做完之后,我们先不按照大神的安装datahub,而是先安装Python3,因为官方文档说是需要保证有这些,所以我们接下来安装Python3.这里我不采用命令的方式安,因为从我安装多次情况来看,不如直接搞安装包快,可能我虚拟机配置的网不太行吧,如果大家虚拟机上网可以的话,也可以搜网上的Python3在线安装的命令。 这里只说我的方法。 需要Python 3.8.0 -tgz ,这个可以去官方页面下载。传送门:py包的仓库镜像
然后开始解压,这里上传到 /opt/module (自己建的),解压也弄这目录了,不愿意折腾。
tar -zxvf Python-3.8.0.tgz
- 1
然后可以先安装这个东东,一个库的包吧,不安装后面安装datahub会报错,还有这个玩意儿
yum install libffi-devel -y
yum install zlib* -y
- 1
- 2
然后正常安装python就可以了。
$ cd /opt/module/Python-3.8.0
#编译安装
$ ./configure --prefix=/usr/local/python3
$ sudo make
$ sudo make install
#创建软连接
$ ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
$ ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3
然后可以检查是否成功,成功了可以看到以下内容
$ python3 -V
$ Python 3.8.2
$ pip3 -V
pip 19.2.3 from /usr/local/python3/lib/python3.8/site-packages/pip (python 3.8)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
到这里应该差不多了,然后可以把这个东西安装上,别问,问就是我安装时候遇到的坑。
pip3 install toml
- 1
然后就可以开始搞dataHub了
$ cd /opt
$ yum -y install git
$ git --version
$ git clone git://github.com/linkedin/datahub.git
$ cd /opt/datahub/docker
$ source ./quickstart.sh
- 1
- 2
- 3
- 4
- 5
- 6
这个source整完是一个前台界面窗口,我这边是又重新打开了一个shell窗口连到虚拟机上。然后执行官方文档的第二步骤。
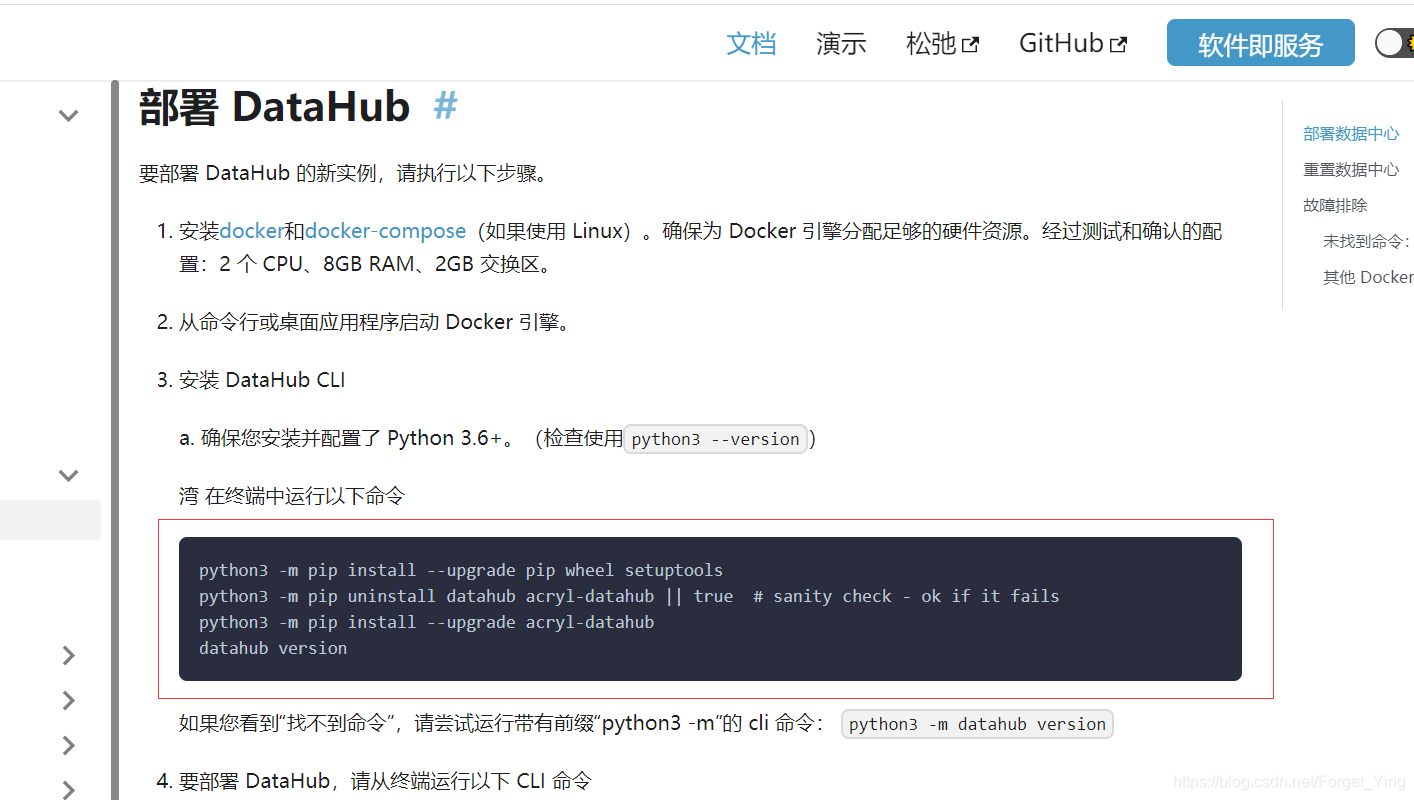
这里的命令,参考官方的步骤是会报一些错的,这里我添加了一些参数。 -i后面是国内豆瓣的镜像地址,下载一些东西会比较快一些。
$ python3 -m pip install --upgrade pip wheel setuptools -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
$ python3 -m pip uninstall datahub acryl-datahub || true # sanity check - ok if it fails
$ python3 -m pip install --upgrade acryl-datahub -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
$ datahub version
- 1
- 2
- 3
- 4
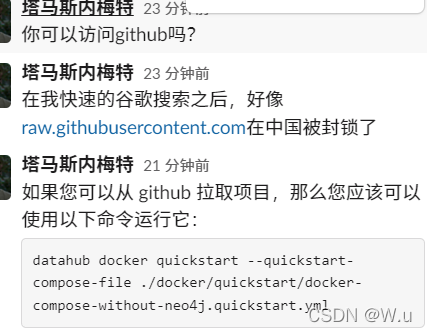
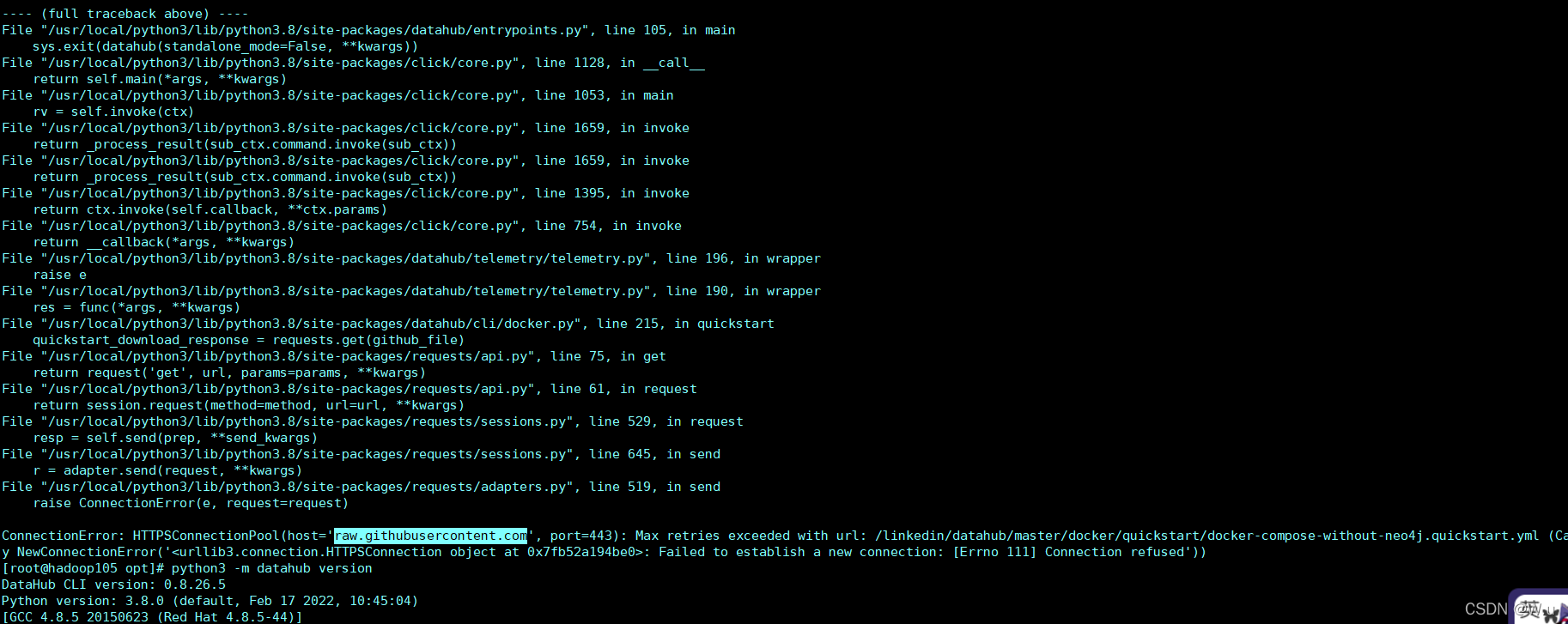
这里多提一嘴,如果你使用 datahub docker quickstart 是会报错的,如下图所示,我去问了官方大佬,原因是因为他会去这个网站找个文件,这个网站在中国被锁了,访问不了,所以只能克隆下来整个项目,然后进入目录里执行。 执行完就起来了,快乐摄入吧
datahub docker quickstart --quickstart-compose-file ./docker/quickstart/docker-compose-without-neo4j.quickstart.yml
- 1
 如果到这里能正常的话,基本就可以了。至于资料里的启动命令,我没有用,但是也可以直接通过访问我的地址直接访问到成功的UI界面。 地址为 hadoop104:9002,然后如图所示。这个地址是你虚拟机的地址,可别复制我这。然后登录名和密码都为datahub
如果到这里能正常的话,基本就可以了。至于资料里的启动命令,我没有用,但是也可以直接通过访问我的地址直接访问到成功的UI界面。 地址为 hadoop104:9002,然后如图所示。这个地址是你虚拟机的地址,可别复制我这。然后登录名和密码都为datahub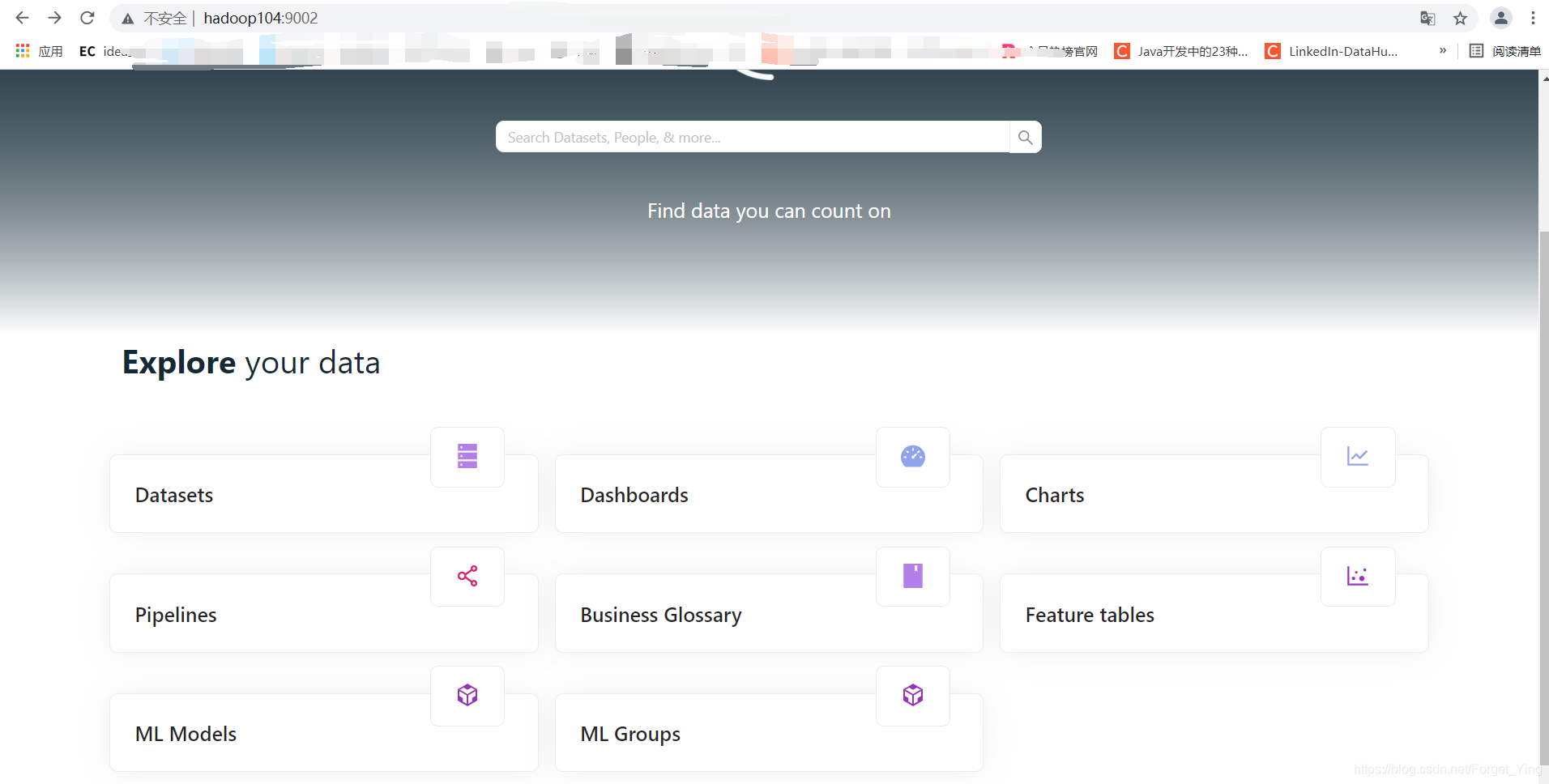
至于他是怎么起来的,我现在也一脸懵逼,反正是可以进一步跟着官方文档进行操作了。先这样记录一下吧,毕竟坑还是太多了。后面如何使用这个,等我玩明白了再说吧,现在资料也是少的可怜。
————————————————————————————————
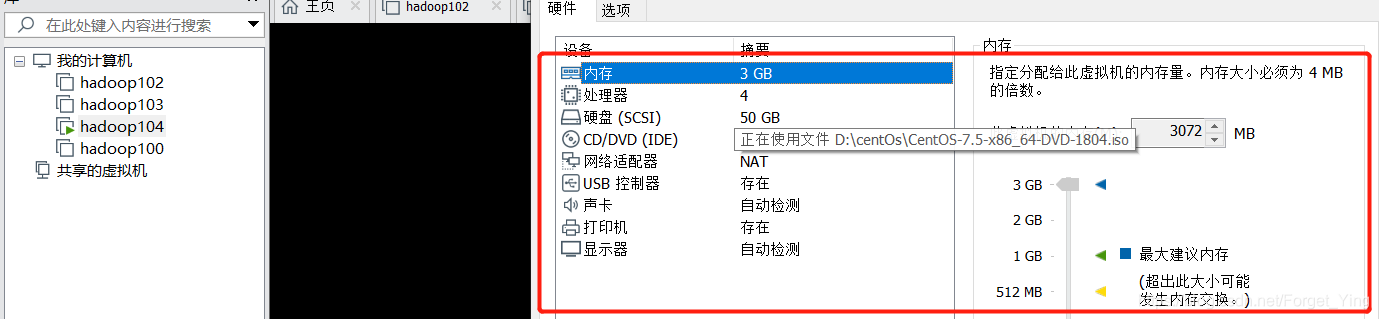
淦,第二天电脑重启虚拟机,就访问不了了,然后我又重新走了一遍datahub的安装,就那些带douban的几个命令,然后绝了,使用quikstart启动的时候报这个,人家需要最低4个G。

我的虚拟机最大内存不知道为啥只能设置3G,这还玩个der,敲里吗不玩了:
————————————————————————————————
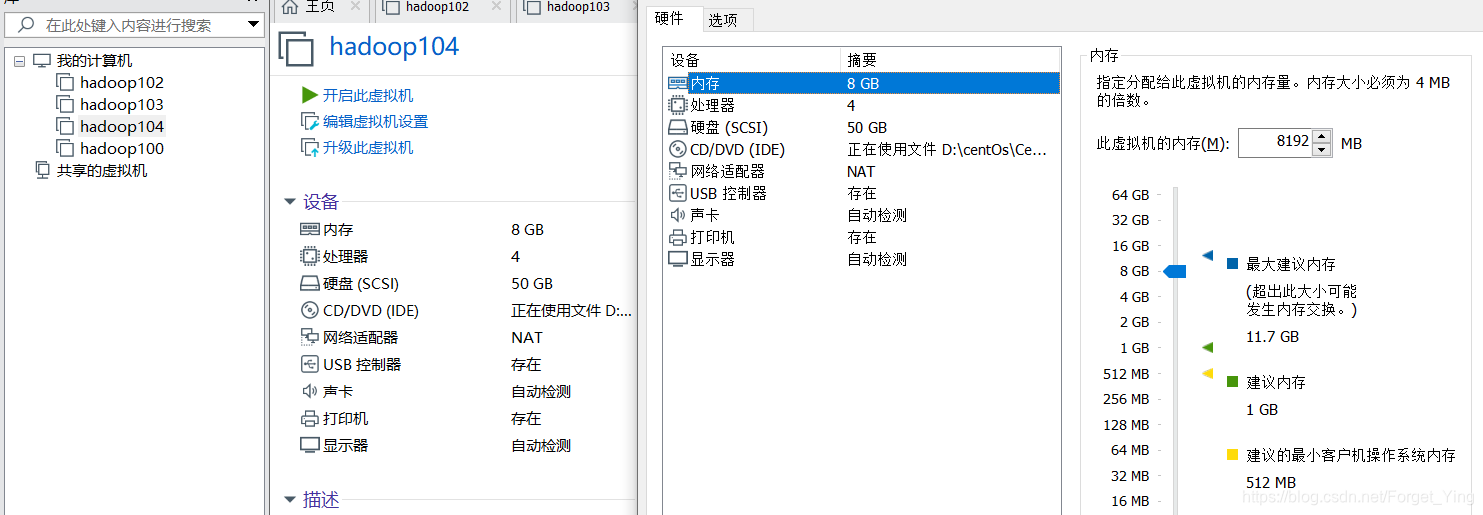
大家就当无事发生,虚拟机在开机情况下不能调内存的大小,我沙雕了,忘记了这个东西,现在可以重新开始快乐了。嘻嘻嘻嘻嘻嘻嘻嘻
————————————————————————————————
好的,又是快乐的过去了两天了,通过这两天启动这个破玩意儿,我发现,我用datahub docker quickstart 就第一成功启动了一次,后面一直报错,我也看不懂,然后我的解决方式就是,既然用不起来,那就不用这个破命令了,我直接去datahub的docker下开搞,反正不是也有快速启动的命令嘛。我直接./quickstart.sh。这样也能启动,然后页面访问,美滋滋。
今天呢,开始搞一下数据数据摄入好了,这个东东呢,自身是没有什么数据的,既然搞元数据管理,那肯定管的是其他地方的元数据咯,所以今天开始摄入一个mysql的数据库试试看。
首先呢,mysql要正常启动,这里我的集群是 hadoop102 hadoop103 hadoop104 三台虚拟机,我的datahub是部署在hadoop104的,mysql是在hadoop102的,别问为啥不部署在同一台机器上(那不是部署失败了好多次,感觉环境被我玩坏了),反正我这三台机器互通,也能玩,将来这个东西肯定也有可能是部署到能连接数据库服务器的另外一台服务器,所以这样也刚好可以试试直接摄取其他地方的数据库数据。
话不多说,直接开搞!
首先摄入的时候是需要插件的,可以理解为写了不同的脚本去访问不同的数据库吧。可以先看一下自己的datahub都安装了哪些玩意儿,一般来说mysql的是默认安装的。
$ datahub check plugins
- 1
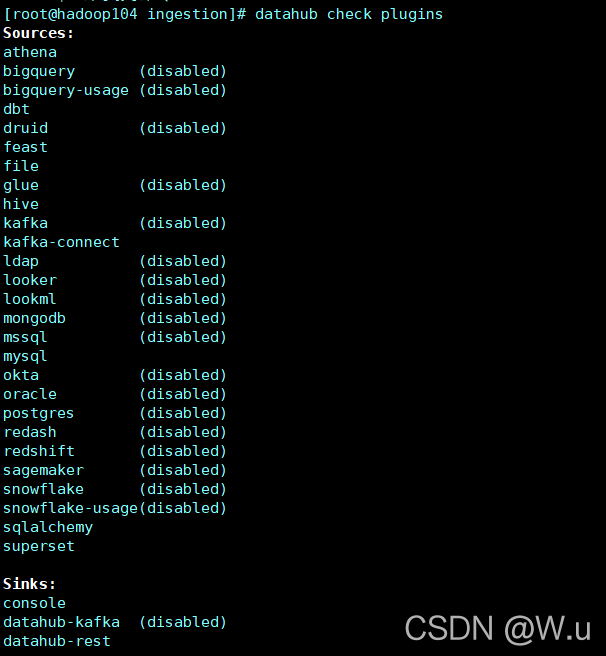
具体下面的参数我还没搞懂是什么个意思,等后面弄明白了再回来更新好了。反正可以看到没有disabled都是安装好的。
然后可以开始摄入数据了,在datahub/docker/ingestion目录下创建你的摄入文件信息的yml
vim /opt/module/datahub/docker/ingestion/recipe.yml
然后输入以下信息
source:
type: "mysql"
config:
username: "root"
password: "000000"
database: "mysql"
host_port: "hadoop102:3306"
sink:
type: "datahub-rest"
config:
server: 'http://localhost:8080'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这个sink里的server 我依然没有搞懂是干啥的,说的是目的地址什么的,我就寻思摄入了难道还要输出么? 等我后面琢磨明白了再说吧。接下来保存好就可以摄取数据了。 下面的路径可以写绝对路径或者你进目录里就不用写前面那一串了,然后执行就行。
datahub ingest -c /opt/module/datahub/docker/ingestion/recipe.yml
- 1
接下来会有这些信息:
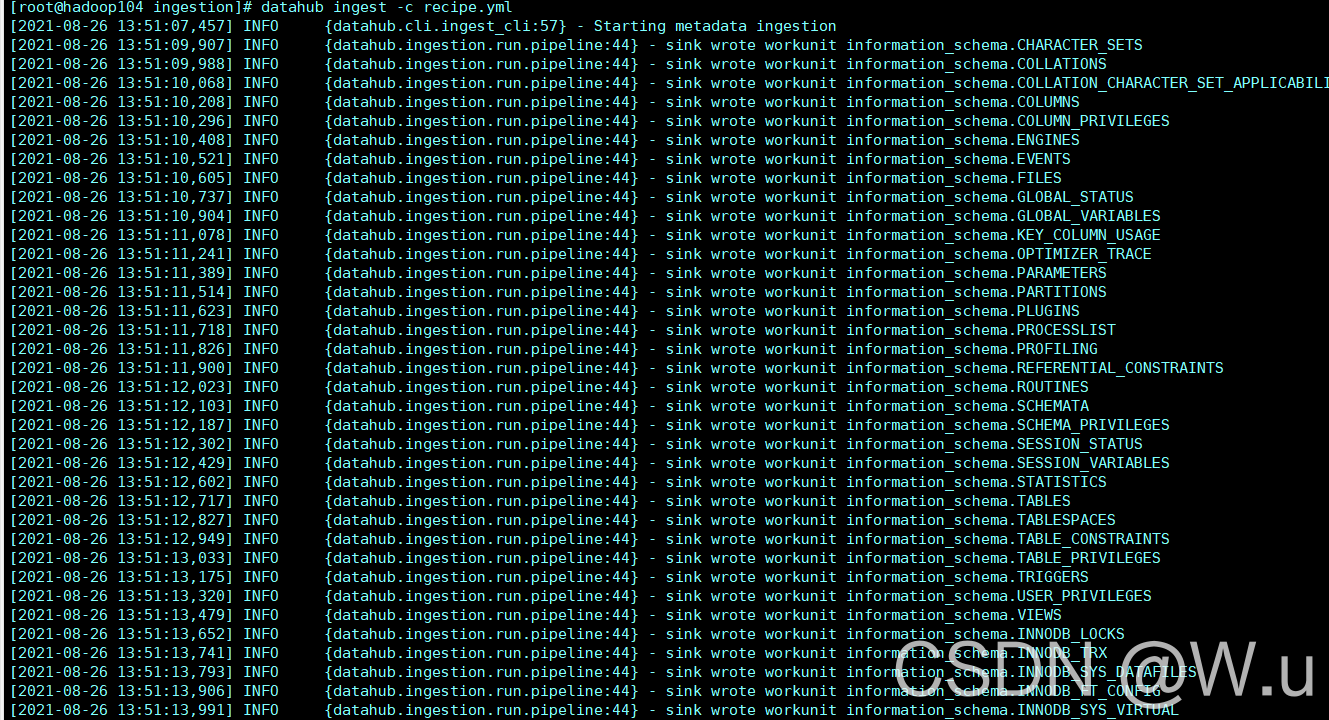
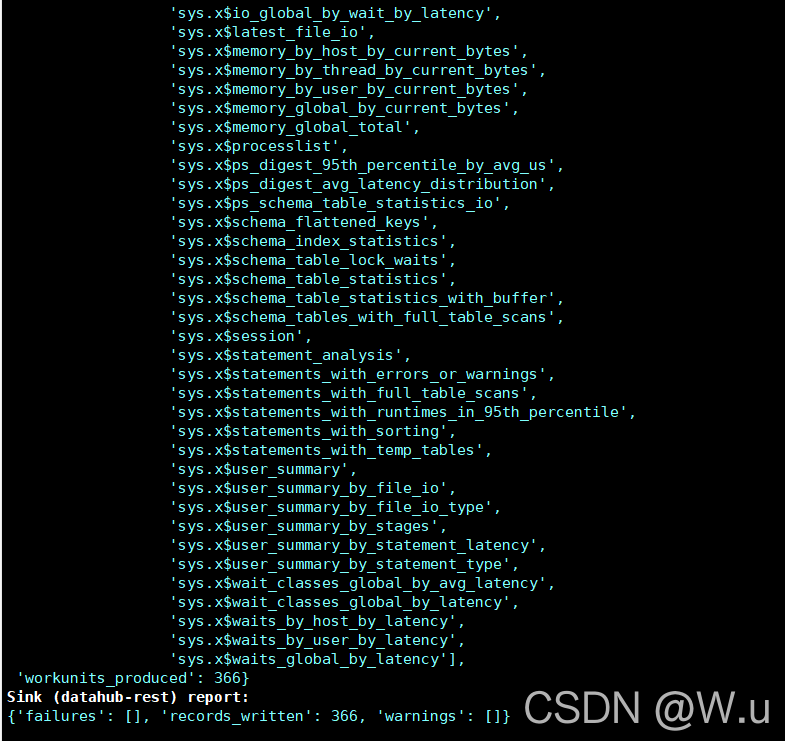
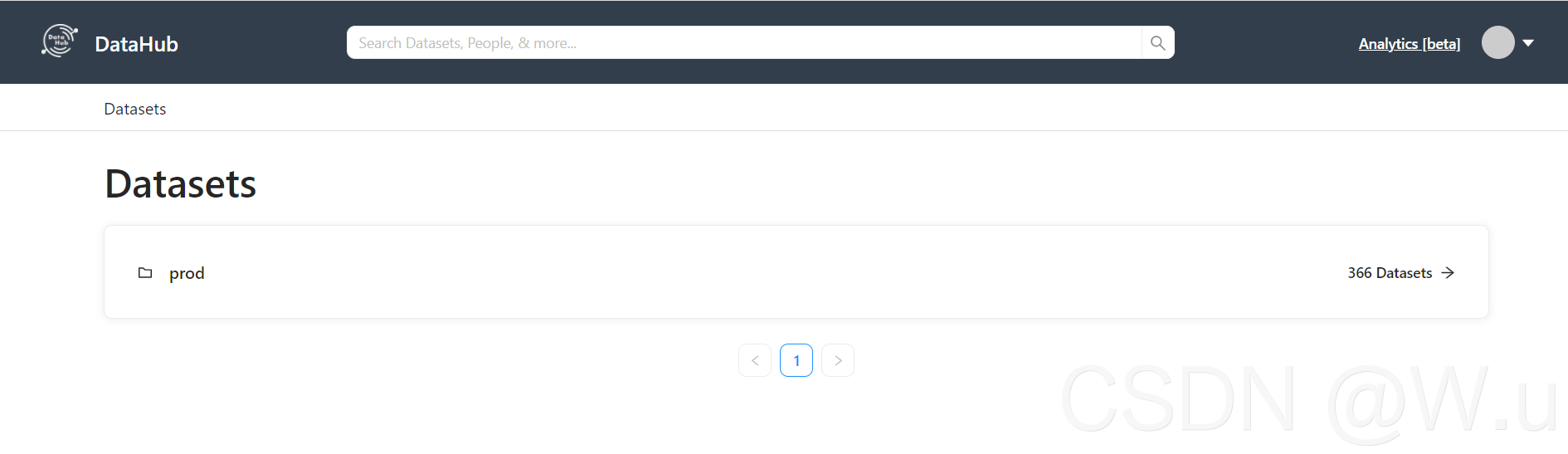
中间的信息就不截了,反正也还有挺长一部分吧,类似的。然后就可以去界面看了。这里就有了你mysql所有库的信息了,可以自己没事点一点看一看都是什么,后面该怎么用,我还没玩明白,反正先摄入了再说吧。有种感觉就想你写了一堆bug的拖拉机他莫名其妙飞起来的那种感觉。 这破玩意儿实在没啥人用。
摄取完mysql的,当然还要再摄入一下hive了,毕竟公司里大数据基本是在hive里,所以从hive里对数据进行摄取也是很有必要的。[PS:后面还会再试试Hbase以及直接从kafka里拿数据]
首先按照官方文档开始,需要安装hive的插件。
pip install 'acryl-datahub[hive]'
- 1
安装完别慌,还有坑呢,不然你摄入的时候绝对会报错,假如你的电脑也是新机的话。 我就纳闷了,这官方他电脑上装了多少东西他心里没点数么,也不做一下说明,就简单整这些完事儿了,懒得要死,哼,还好万能的度娘能帮我解决使用时候遇到的问题。 大家如果遇到了不要慌,基本是python的问题,网上也肯定会有详细讲解的。
大家可以先看一下g++ 有没有,我之前有安装gcc,但是g++这玩意儿他也需要,所以可以执行这个命令
yum -y install gcc-g++
// 然后再装这个,不然执行摄入会报错,装就完事了,反正也占不了多少空间
yum install python3-devel
// 装完别急 还有这个
yum install cyrus-sasl-devel
// 别问,问就是摄入失败我花了一两个小时找的解决办法。或者你先直接摄入试试,没有报错你当我放了个屁
- 1
- 2
- 3
- 4
- 5
- 6
之后就可以快乐摄入了,摄入时要保证你Hiveserver2 是正常启动的,端口是10000,既然你是摄入HIVE的,那这玩意儿我就不解释了,懂得都懂。
然后写YML摄入的配置文件,我的内容是这样的,基本和官方文档一样,就是我从我的mysql里改了个地址,删去账户密码就行的。
source:
type: hive
config:
database: default
host_port: "192.168.10.102:10000"
sink:
type: "datahub-rest"
config:
server: 'http://localhost:8080'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后继续走这个摄入命令,他就可以开始搞了
datahub ingest -c /opt/module/datahub/docker/ingestion/recipe.yml
- 1
日志打印这次就不截取了,和上面那些打印差不多,打多打少取决于你数据库表的量的大小。我就直接截取结果了,正常摄入完毕之后,页面就能看到你摄入的第二种数据了。如图所示
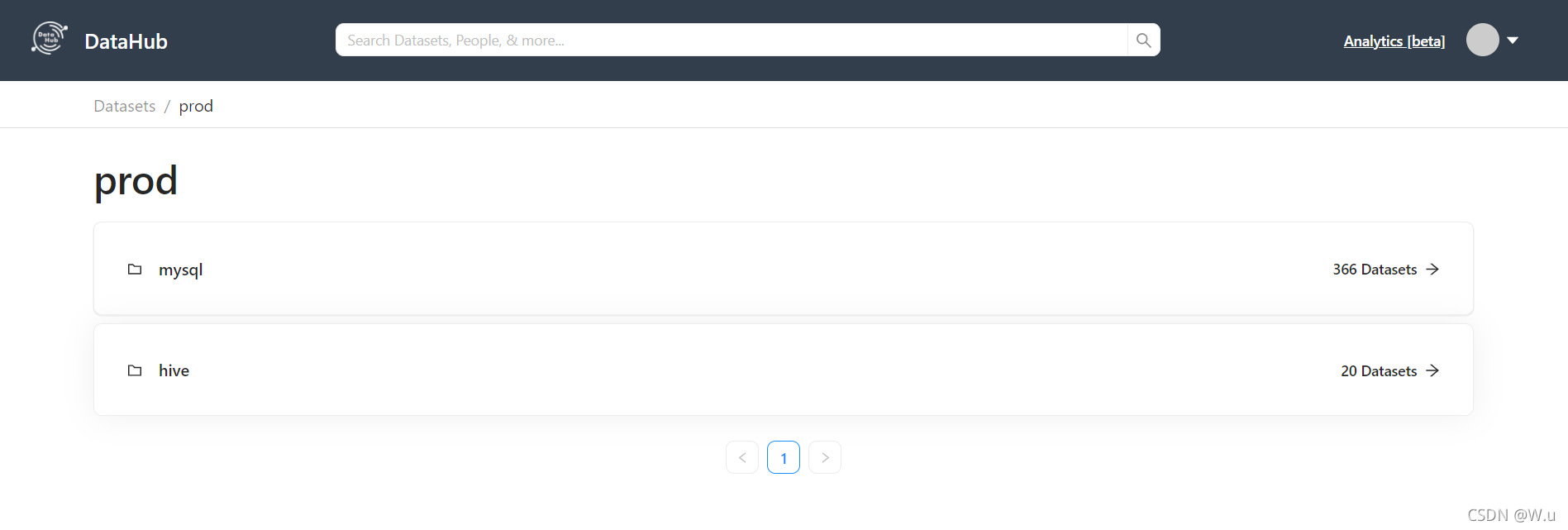
我检查这两个数据源里的东西,感觉mysql的他是给我所有表都摄入了,因为我库里的表只有十几张,然后其他的好多是系统表之类的,Hive的还好,都是我自己创建的表,先这样吧,等后面研究明白了再说。 【学习吧,不学习你永远都是弱鸡】
顺便补充一下,因为我启动都是 ./quickstart.sh ,这个是前台命令,我都是打开第二个窗口去执行各种,非常的不够银杏,非常的不合理,所以可以用nohup启动我们这个命令。这个logs目录是我自己创建的,后面两个参数就是把输出内容输出到这个文件里。完事。后面有进展了再更
nohup ./quickstart.sh > logs/log.log 2>&1 &
- 1
又过去了两天,好像出问题了,兄弟萌,现在datahub启动起来,界面首先和原本的不一样了,也不是官方文档里演示的界面,不知道是不是更新了什么东西,导致我拉取的时候更新了?现在界面是这样的
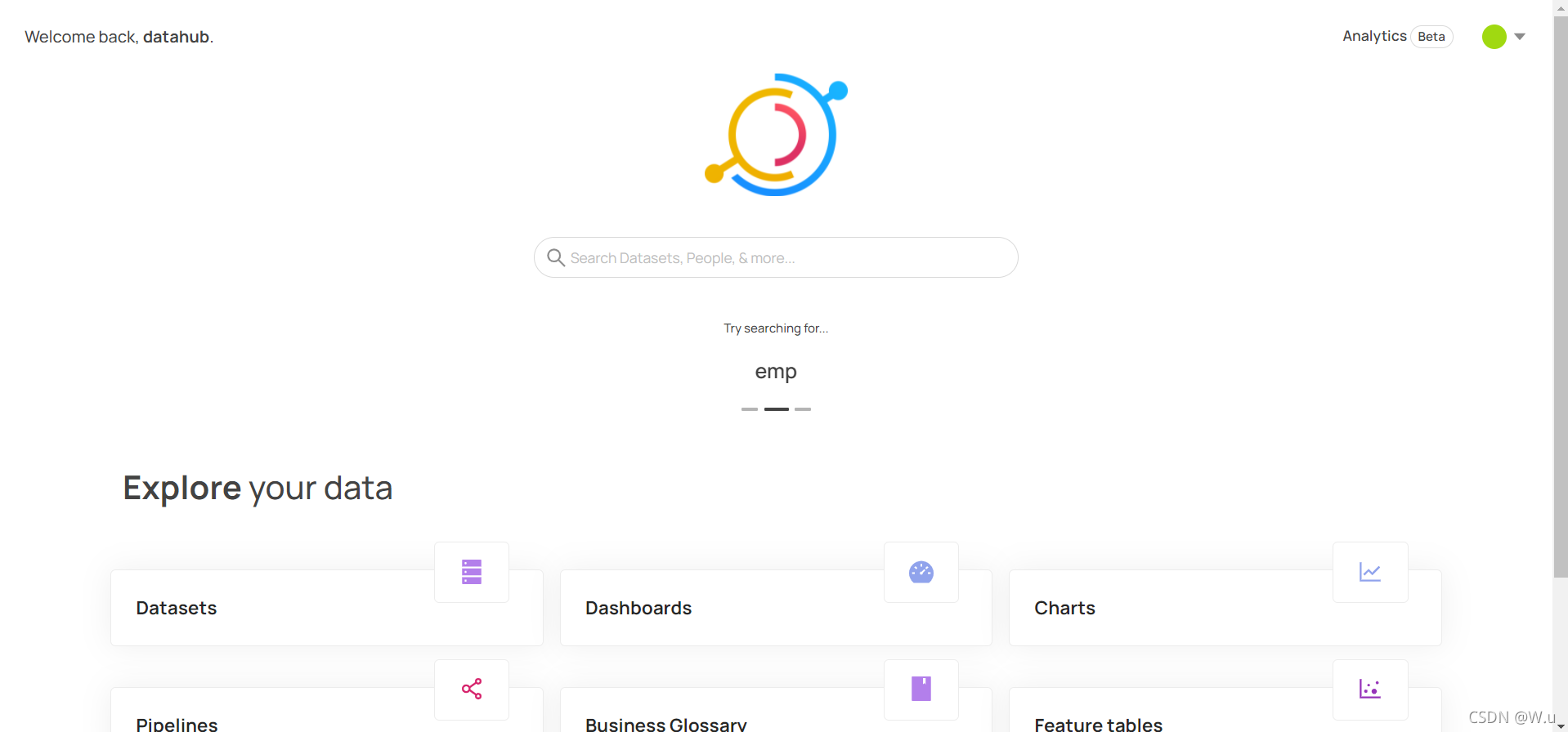
但是官方演示的是这样的:

然后在表展示这里,也有不一样了,我的血统分析,查询,还有最后面一个选项是不可用的。但是官方的好好的没问题啊。
这是我的表查看的截图
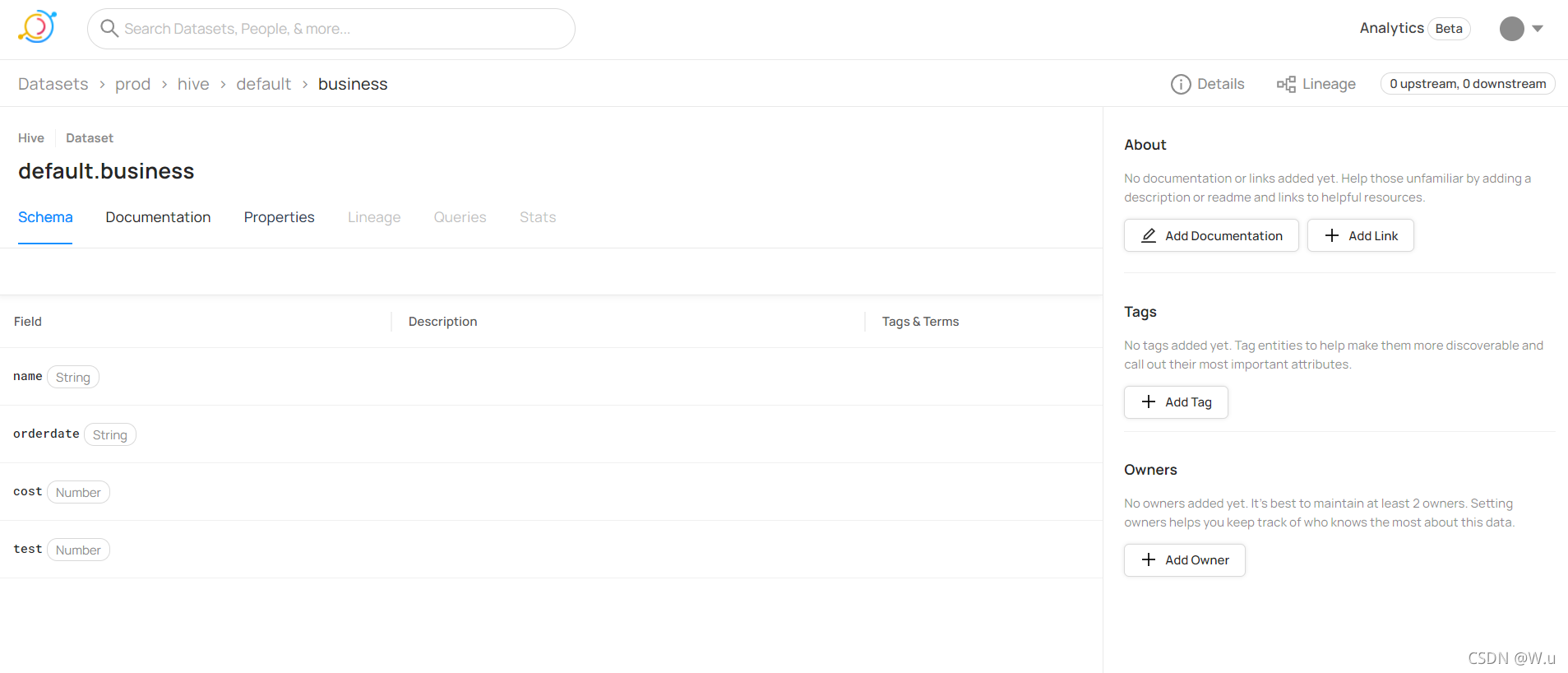
这是官方表查看的截图:
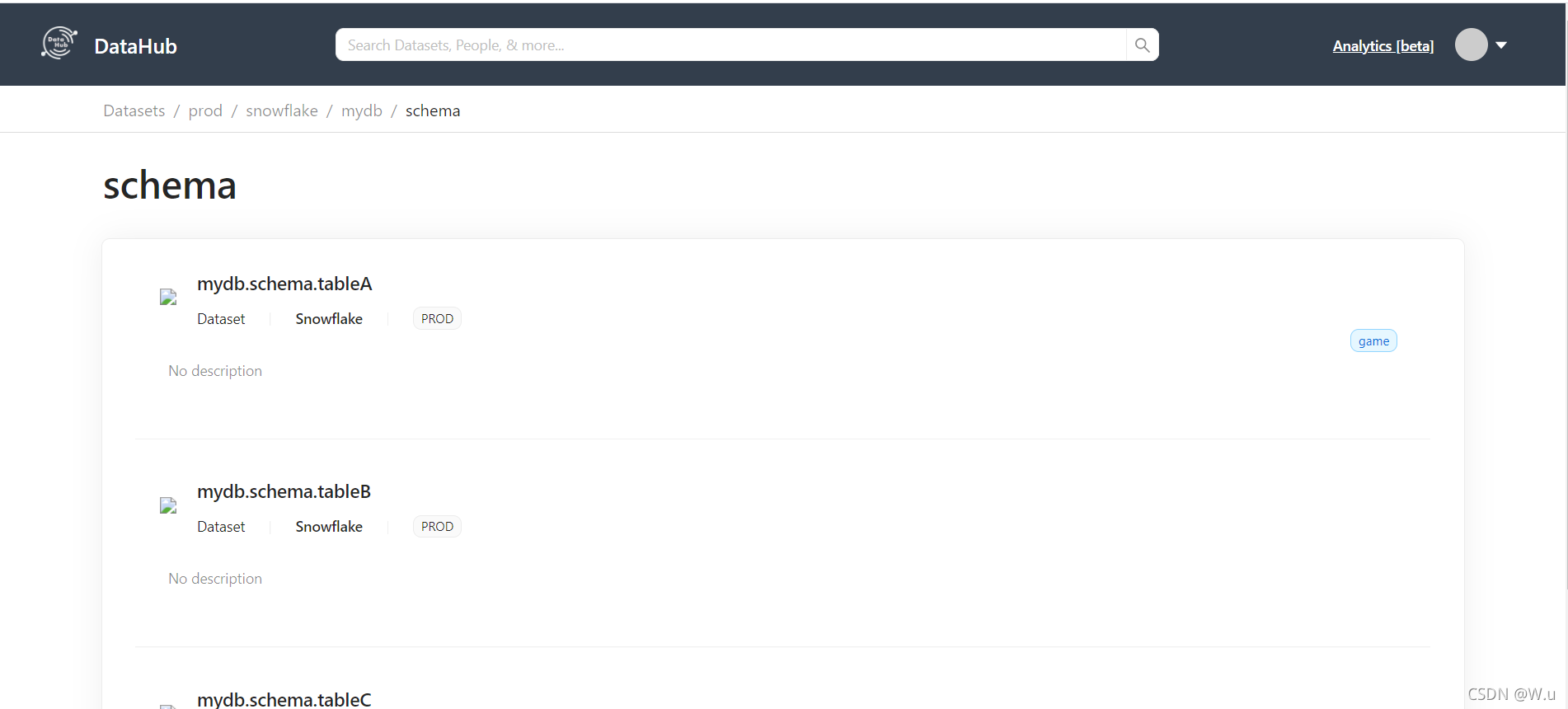
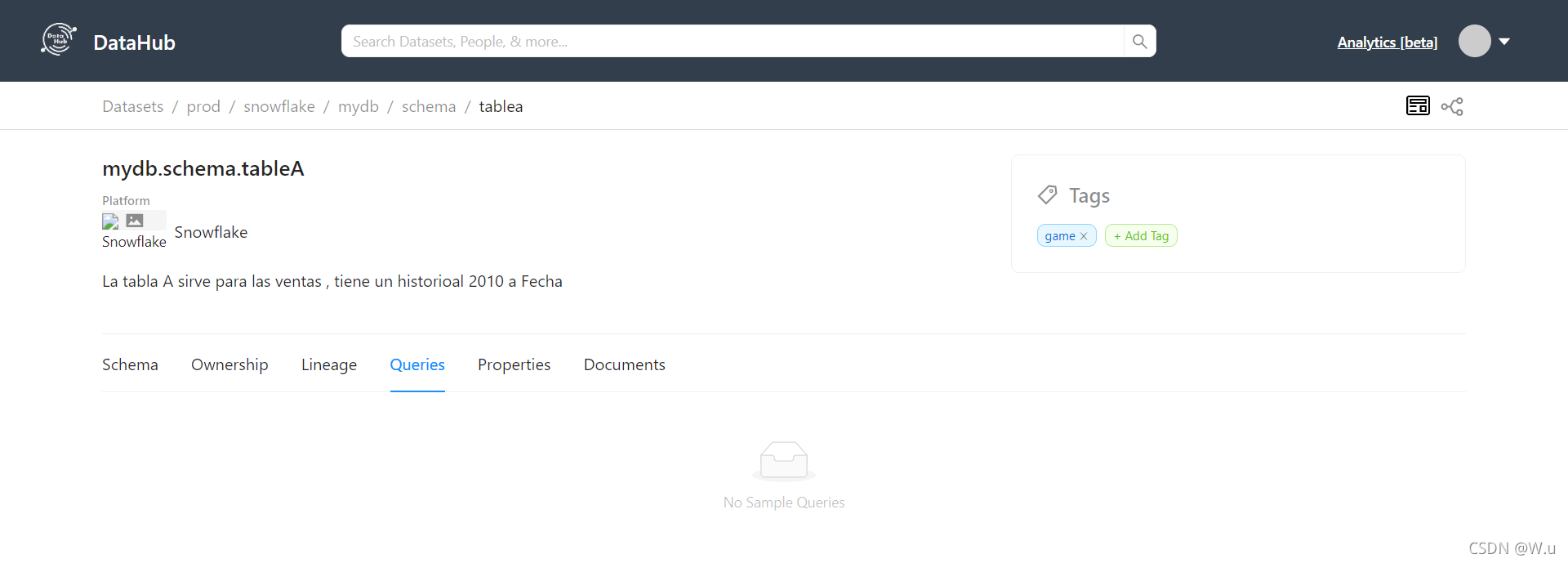
血统分析直接就变灰了,官方文档也没看到什么更新说明。这该咋整啊
破案了,今天去datahub的slack上看了一下,还真更新了UI界面,
而且我看他们的UI界面和现在的是一样的,那就是说本地是没问题的,就是系统UI升级了。
————————————————————————————————
版权声明:本文为CSDN博主「W.u」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

