
- 1机器学习之用Python使用ID3算法实例及使用sklearn的决策树算法对葡萄酒数据集进行分类_葡萄酒主要成分 id3
- 2MySQL的聚合函数是否忽略NULL_mysql什么时候加法求和不会忽略null
- 3ARM-Cortex_M3/M4处理器开发简介_arm芯片开发
- 4MYSQL _数据库_EXPLAIN(查询性能优化)_mysql explain
- 5区块链的“孪生姐妹”——Tangle_the dag-based blockchain with iota tangle
- 6provider:Named Pipes Provider,error:40 - 无法打开SQL Server的连接_偶尔(provider: named pipes provider, error: 40 - 无法打
- 7机器视觉工业相机客户端MVS V2.1.2(Linux)-安装教程_mvs软件
- 8个人博客怎么盈利?_个人博客盈利
- 9ubuntu遇到:无法定位软件包net-tools 解决办法_无法定位软件包 net-tools
- 10超级用户指南:轻松升级你的Ubuntu Linux内核版本_ubuntu升级内核
谷歌大脑AutoML最新进展:用进化算法发现神经网络架构
赞
踩

来源:AI中国
大脑的进化进程持续已久,从5亿年前的蠕虫大脑到现如今各种现代结构。例如,人类的大脑可以完成各种各样的活动,其中许多活动都是毫不费力的。例如,分辨一个视觉场景中是否包含动物或建筑物对我们来说是微不足道的。为了执行这些活动,人工神经网络需要专家经过多年的艰难研究仔细设计,并且通常需要处理一项特定任务,例如查找照片中的内容,称为遗传变异,或帮助诊断疾病。理想情况下,人们会希望有一个自动化的方法来为任何给定的任务生成正确的架构。
如果神经网要完成这项任务,则需要专家经过多年研究以后进行精心的设计,才能解决一项专门的任务,比如发现照片中存在的物体,发现基因变异,或者帮助诊断疾病。理想情况下,人们希望有一个自动化的方法可以为任何给定的任务生成正确的网络结构。
生成这些网络结构的方法之一是通过使用演化算法。传统的拓扑学研究已经为这个任务奠定了基础,使我们现如今能够大规模应用这些算法,许多科研团队正在研究这个课题,包括OpenAI、Uber实验室、Sentient验室和DeepMind。当然,谷歌大脑也一直在思考自动学习(AutoML)的工作。
除了基于学习的方法(例如强化学习)之外,我们想知道是否可以使用我们的计算资源以前所未有的规模进行图像分类器的编程演化。我们能否以最少的专家参与达成解决方案,今天的人工进化神经网络能有多好的表现呢?我们通过两篇论文来解决这些问题。
在ICML 2017上发表的“图像分类器的大规模演化”中,我们用简单的构建模块和初始条件建立了一个演化过程。这个想法简单的说就是“从头开始”,让规模的演化做构建工作。从非常简单的网络开始,该过程发现分类器与当时手动设计的模型相当。这是令人鼓舞的,因为许多应用程序可能需要很少用户参与。
例如,一些用户可能需要更好的模型,但可能没有时间成为机器学习专家。接下来要考虑的一个自然问题是手工设计和进化的组合是否可以比单独的任何一种方法做得更好。因此,在我们最近的论文“图像分类器体系结构搜索的正则化演化”(2018年)中,我们通过提供复杂的构建模块和良好的初始条件(下面讨论)参与了该过程。而且,我们使用Google的新TPUv2芯片扩大了计算范围。对现代硬件、专家知识和进化的结合共同产生了CIFAR-10和ImageNet两种流行的图像分类基准的最新模型。
一个简单的方法
以下是我们第一篇论文的一个实验例子。
在下图中,每个点都是在CIFAR-10数据集上训练的神经网络,通常用于训练图像分类器。每个点都是一个神经网络,这个网络在一个常用的图像分类数据集(CIRAR-10)上进行了训练。最初,人口由1000个相同的简单种子模型组成(没有隐藏层)。从简单的种子模型开始非常重要,如果我们从初始条件包含专家知识的高质量模型开始,那么最终获得高质量模型会更容易。一旦用简单的模型开始,该过程就会逐步推进。在每一步中,随机选择一对神经网络。选择更高精度的网络作为父类,并通过复制和变异生成子节点,然后将其添加到群体中,而另一个神经网络会消失。所有其他网络在此步骤中保持不变。随着许多这样的步骤陆续得到应用,整个网络就会像人类的进化一样。
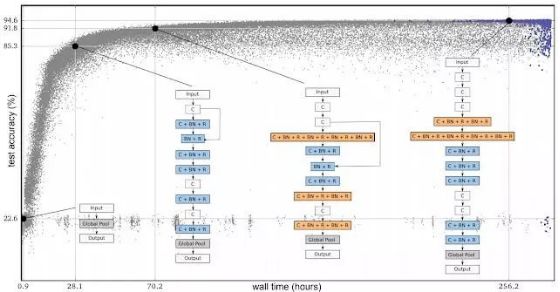
进化实验进程。每个点代表 population 中的一个元素。这四个列表是发现架构的示例,这些结构对应最好的个体(最右边,根据验证准确性筛选)和其三个 ancestor。
综上所述,尽管我们通过简单的初始架构和直观的突变来最小化处理研究人员的参与,但大量专家知识进入了构建这些架构的构建块之中。其中一些包括重要的发明,如卷积、ReLUs和批处理的归一化层。我们正在发展一个由这些组件构成的体系结构。 “体系结构”这个术语并不是偶然的:这与构建高质量的砖房相似。
结合进化和手工设计
在我们的第一篇论文后,我们希望通过给算法提供更少的选择来减少搜索空间,使其更易于管理。使用我们的架构推导,我们从搜索空间去掉了制作大规模错误的所有可能的方法,例如盖房子,我们把墙放在屋顶上的可能性去除了。与神经网络结构搜索类似,通过修复网络的大规模结构,我们可以帮助算法解决问题。那么如何做到这一点? Zoph等人引入了用于架构搜索的初始模块。已经证明非常强大。他们的想法是有一堆称为细胞的重复单元。堆栈是固定的,但各个模块的体系架构是可以改变的。
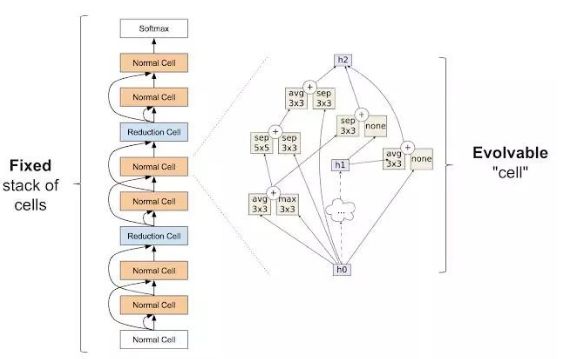
Zophet al. 中引入的构建模块。图左表示整个神经网络对外部结构,其通过重复的单元从下到上解析输入数据。右图单元格的内部结构。该实验的目的是发现能批生成高精度网络的单元
在我们的第二篇论文“图像分类器体系结构搜索的正则化演化”(2018)中,我们介绍了将演化算法应用于上述搜索空间的结果。突变通过随机重新连接输入(图中右侧箭头)或随机替换操作来修改单元格(例如,它们可以替换图中的“最大3x3”像素块)。这些突变相对简单,但最初的条件并不相同:现在的整体已经可以用模型进行初始化,这些模型必须符合由专家设计的细胞结构。
尽管这些种子模型中的单元是随机的,但我们不再从简单模型开始,这使得最终获得高质量模型变得更容易。如果演化算法的贡献有意义,那么,最终的网络应该比我们已经知道可以在这个搜索空间内构建的网络好得多。我们的论文表明,演化确实可以找到与手工设计相匹配或超越手艺设计的最先进模型。
控制变量比较法
即使突变/选择进化过程并不复杂,也许更直接的方法(如随机搜索)也可以做到这一点。其他选择虽然不简单,但也存在于文献中(如强化学习)。正因为如此,我们的第二篇论文的主要目的是提供技术之间的控制变量比较。
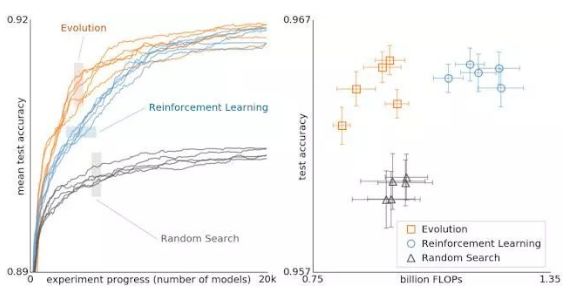
使用演化法、强化学习和随机搜索法进行架构搜索结果对比。这些实验在 CIFAR-10 数据集上完成,条件与 Zophet al. 相同,他们使用强化学习进行空间搜索。
上图比较了进化、强化学习和随机搜索。在左边,每条曲线代表一个实验的进展,表明在搜索的早期阶段进化比强化学习更快。这很重要,因为计算能力较低,实验可能不得不提前停止。
此外,演变对数据集或搜索空间的变化具有鲁棒性。总的来说,这种对照比较的目标是为研究界提供计算昂贵的实验结果。在这样做的过程中,我们希望通过提供不同搜索算法之间关系的案例研究来促进每个人的架构搜索。例如,上图显示,使用更少的浮点运算时,通过进化获取的最终模型可以达到非常高的精度。
我们在第二篇论文中使用的进化算法的一个重要特征是正则化的形式:不是让最坏的神经网络死掉,而是删除最老的一个,无论它们有多好。这改善了正在优化的任务变化的鲁棒性,并最终趋于产生更准确的网络。其中一个原因可能是因为我们不允许权重继承,所有的网络都必须从头开始训练。因此,这种正则化形式选择在重新训练时仍然保持良好的网络。换句话说,因为一个模型可能会更准确一些,训练过程中的噪声意味着即使是相同的体系结构也可能会得到不同的准确度值。只有在几代中保持准确的体系结构才能长期存活,从而选择重新训练良好的网络。篇猜想的更多细节可以在论文中找到。
我们发展的最先进的模型被命名为AmoebaNets,是我们AutoML努力的最新成果之一。所有这些实验通过使用几百个的GPU/TPU进行了大量的计算。就像一台现代计算机可以胜过数千年前的机器一样,我们希望将来这些实验能成为家用。这里我们旨在提供对未来的一愿。
原文地址:
https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

