
- 1Python编程-二万字浅谈装饰器原理与装饰器设计模式和函数式编程案例讲解
- 2ShardSphere算法介绍(实现按年月日分片自定义算法)_时间间隔分片 interval sharding algorithm
- 3太强了!最全的大模型检索增强生成(RAG)技术概览!_检索增强生成模型
- 4Java知识体系图
- 5SCAU--数据结构练习--8580--合并链表_csdn 数据结构8580
- 6PaDiM【异常检测:Embedding-based】
- 7Mapper类/Reducer类中的setup方法和cleanup方法以及run方法的介绍_mapperd的setup方法
- 82022下半年软考成绩即将公布,附查分指南!_22年下 软考 成绩
- 9单机部署Kafka和开启SASL认证_kafka 开启sasl
- 10OpenAI 开源的免费 AI 语音转文字工具 - Whisper,一步一步本地部署运行_rust tts speech2t
调用AI聊天机器人自动回复信息(Python)_ai回复缓存机制
赞
踩
“人类正从IT时代走向DT时代”,随着移动互联网技术持续高速发展,海量数据计算存储、智能数据挖掘、低时延数据传送和可靠网络安全已经成为软硬件技术飞速发展的催化剂,也推动着数据中心从IT时代逐步迈向DT时代,对数据进行汇聚,在体系化融合中产生新的价值已成为未来发展的关键.
如今,大数据+智能化催生了许多的智能聊天机器人,如华为的小冰,小米的小爱同学还有苹果的Siri.于是,我有了新的想法: 1952年,在一场BBC广播中,图灵谈到了一个新的具体想法:让计算机来冒充人。如果不足70%的人判对,也就是超过30%的裁判误以为在和自己说话的是人而非计算机,那就算作成功了。这就是著名的图灵测试。
(图灵测试:被测试人,和一个是声称自己有人类智力的机器。测试时,测试人与被测试人分开的,测试人只有通过一些装置(如键盘)向被测试人问一些问题,这些问题随便是什么问题都可以。问过一些问题后,如果测试人能够正确地分出谁是人谁是机器,那机器就没有通过图灵测试,如果测试人没有分出谁是机器谁是人,那这个机器就是有人类智能的。)
于是,我打算尝试调用某公司的AI聊天机器人,在QQ上和好友进行交流,看看目前的AI聊天机器人能否通过图灵测试,先附上一张效果图吧:
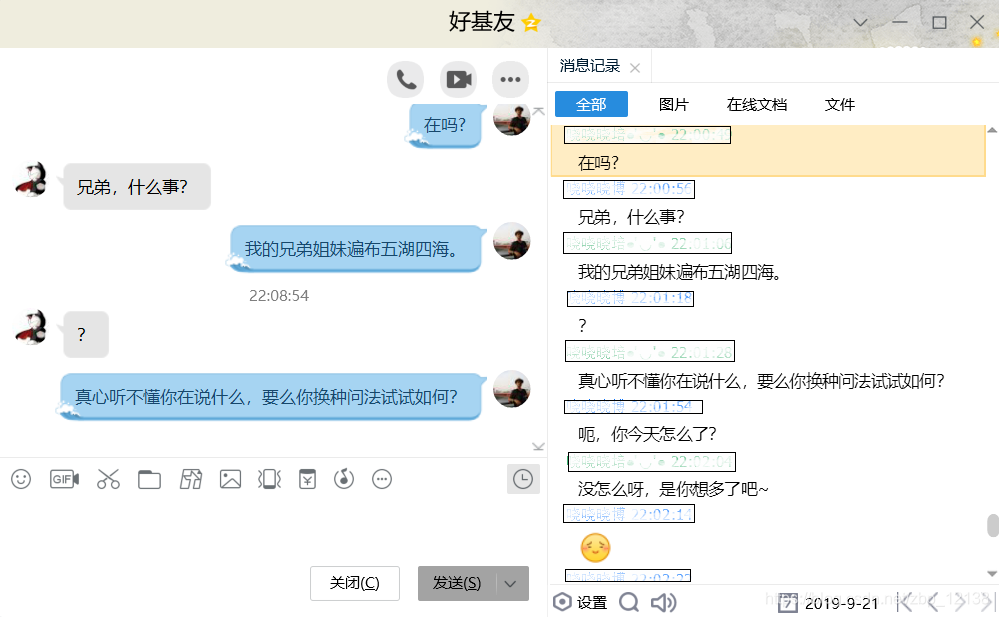
看来, 这个AI聊天机器人有点明显呀,差点点就露馅了呀,不过没关系,我们还是可以拿来学习的,话不多说,在上代码之前先了解一下要使用的库:urllib库
urllib中包括了四个模块,包括urllib.request,urllib.error,urllib.parse,urllib.robotparser.
- urllib.request可以用来发送request和获取request的结果
- urllib.error包含了urllib.request产生的异常
- urllib.parse用来解析和处理URL
- urllib.robotparse用来解析页面的robots.txt文件
我们主要用到的urllib.request库是一个为打开url提供的可扩展类库,可以用来发送request和获取request的结果.
来,先把这部分的代码写上:
url="http://nlp.xiaoi.com/robot/webrobot?&callback=__webrobot_processMsg&data=%7B%22sessionId%22%3A%22ff725c236e5245a3ac825b2dd88a7501%22%2C%22robotId%22%3A%22webbot%22%2C%22userId%22%3A%227cd29df3450745fbbdcf1a462e6c58e6%22%2C%22body%22%3A%7B%22content%22%3A%22" + x + "%22%7D%2C%22type%22%3A%22txt%22%7D"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
link = urllib.request.Request(url=url, headers=headers)
proxy = {'http': '218.108.175.15'}
# 创建代理Handler对象
proxy_handler = urllib.request.ProxyHandler(proxy)
# 以Handler对象为参数创建Opener对象
opener = urllib.request.build_opener(proxy_handler)
# 将Opener安装为全局
urllib.request.install_opener(opener)
response = urllib.request.urlopen(link)
page_source = response.read().decode('utf-8')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我这里用到的代理ip,大家可以自己在网上找一下,我给大家找了几个,现在还能不能用就不好说了:
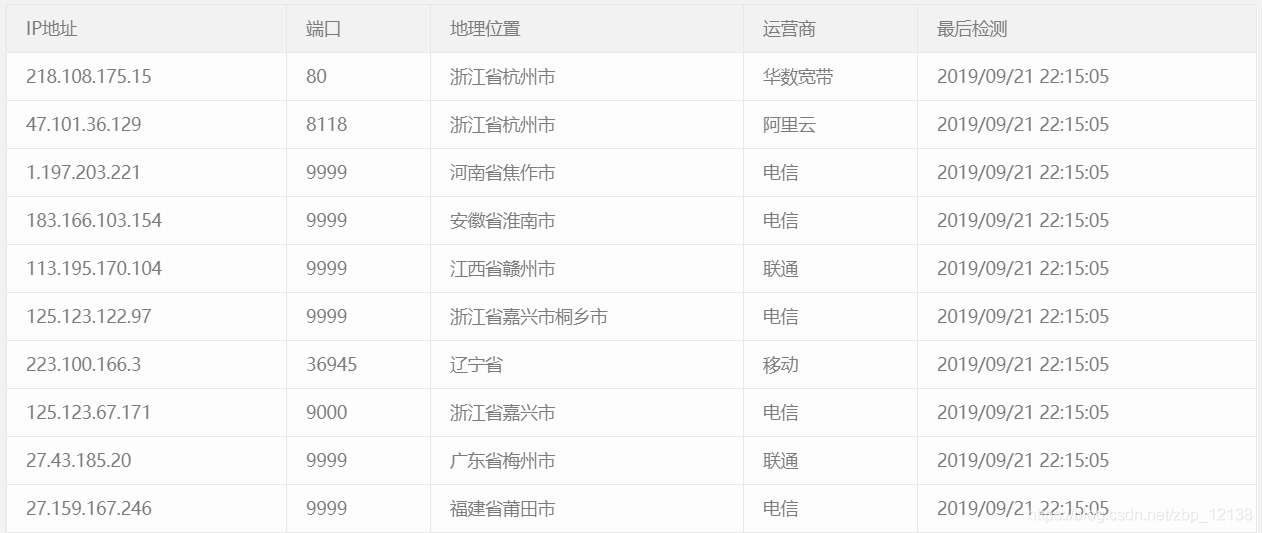
接下来,是最关键的一步,获取并选择返回的内容.于此同时,为了在将来能完善代码,我把聊天记录都存到了一个.txt文件下,我把这个文件命名为”my_output_demo”,相当于一个小型”数据库”.
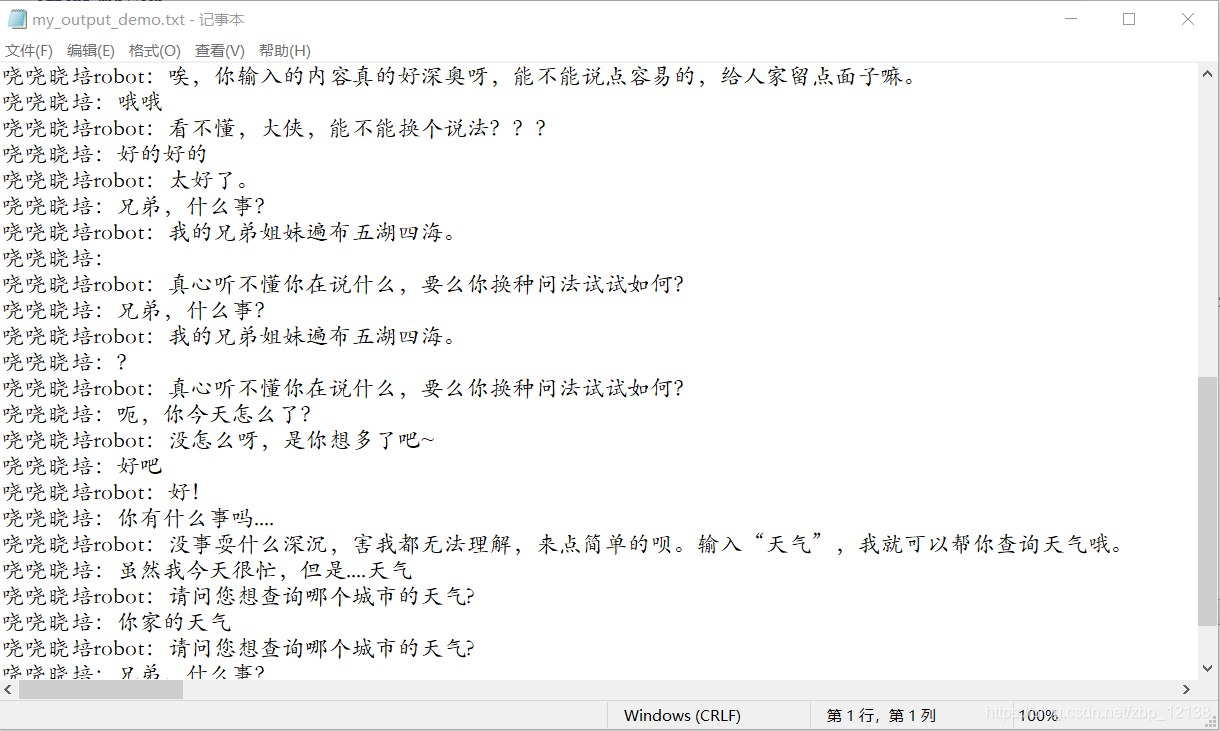
话不多说,敲代码!
x = input("哓哓晓培:")
doc.write("哓哓晓培:" + x)
doc.write('\n')
#屏蔽特殊的字符、比如如果url里面的空格!
x = urllib.parse.quote(x)
#正则表达式 re.findall 的简单用法:返回string中所有与pattern相匹配的全部字串,返回形式为数组
reply_list = re.findall(r'\"content\":\"(.+?)\\r\\n\"', page_source) #Python 正则表达式 re.findall 方法能够以列表的形式返回能匹配的子串; (.+?)为惰性匹配
print("哓哓晓培robot:" + reply_list[-1]) #代表索引该列表最后一个值,在python中索引从左往右是0,1,2,3… 从右往左是-1,-2,-3……
doc.write("哓哓晓培robot:" +reply_list[-1])
doc.write('\n')
doc.close()
doc=open(r'my_output_demo.txt','a')
#发送的消息
msg2 = (reply_list[-1])
#窗口名字
name = "好基友"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
有些知识点我单独拿出来讲的话会显得很啰嗦,但为了能让新手看明白我的代码,我把一些小知识点写在了注释里,在你的程序中,代码的注释应该简单明了,写上这部分的功能即可,没有必要把各种函数的具体用法都写上去!
回到正题!大家可能不太明白这句:x = urllib.parse.quote(x),我详细讲讲:x是user输入的内容,这个内容可能五花八门,天马行空,我相信当你在和各种智能语音助手聊天时,你也会这么干,想尽各种办法刁难他,哈哈哈,替这些智能语音助手心疼1秒钟.
url里面是不允许出现空格的。按照标准, URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的。所以 URL 中使用其他字符就需要进行 URL 编码。URL 中传参数的部分(query String),格式是:name1=value1&name2=value2&name3=value3.假如你的 name 或者 value 值中有&或者=等符号,就当然会有问题。所以URL中的参数字符串也需要把&,=等符号进行编码。URL编码的方式是把需要编码的字符转化为 %xx 的形式。通常 URL 编码是基于 UTF-8 的.
接下来,我们来讲讲正则表达式。对于新手来说可能会有点难度,没关系,问题不大!简单来说,正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
我们要用到的是findall,这个函数在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
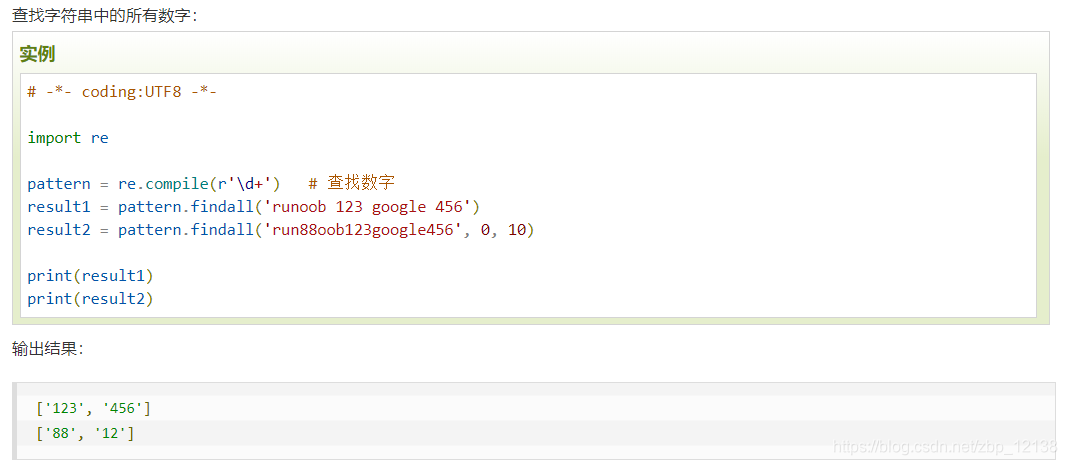
好了,核心代码其实主要还是爬虫方面的知识,接下来,我们继续完善功能!
复制粘贴实在是太麻烦了,我是学自动化的,说白了,想偷懒,哈哈哈,所以呢,我们来做一个让程序自己找到QQ聊天窗口并且自动发送消息的方法!先来分析一下,想要自动发送消息,需要两个条件:QQ窗口的按键操控以及内存的操控,换句话说,就是操控剪切板.
我们需要用到Pywin32,这是一个Python库,为python提供访问Windows API的扩展,提供了齐全的windows常量、接口、线程以及COM机制等等。以下是四个步骤:
- 一, 首先import win32gui, win32con
- 二, 使用win32gui.FindWindow找到目标程序:
- 三, 使用win32gui.FindWindowEx找到目标文本框:
- 四, 使用win32gui.SendMessage发送文本到目标文本框:
代码在这:
#获取窗口句柄
def Get_window_handle():
handle = win32gui.FindWindow(None, name)
if 1 == 1:
#睡眠1秒,不然可能会重复发送消息
time.sleep(1)
win32gui.SendMessage(handle, 770, 0, 0)
#回车发送消息
win32gui.SendMessage(handle, win32con.WM_KEYDOWN, win32con.VK_RETURN, 0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
操控剪切板,我们需要用到win32clipboard这个库:
#将测试消息复制到剪切板中
def setText():
w.OpenClipboard()
w.EmptyClipboard()
w.SetClipboardData(win32con.CF_UNICODETEXT, msg2)
w.CloseClipboard()
- 1
- 2
- 3
- 4
- 5
- 6
新上手的同学记得把这一句加上:
if __name__ == '__main__':
setText()
Get_window_handle()
- 1
- 2
- 3
如果觉得这方面比较困难的话,直接写也是可以的,就不需要定义方法了.
我做了一个视频,实现的功能在里面可以得到展示:调用AI聊天机器人自动回复信息(Python)
大公告成!快去试一下吧!

