
- 1【Caddy】Caddy实践1——此网站无法提供安全连接_安装caddy出错
- 2Git Cherry-Pick命令详解:轻松选取与移植提交_cherrypick 多个提交
- 3手把手教NLP小白如何用PyTorch构建和训练一个简单的情感分类神经网络_训练一种词向量,利用pytorch,搭建情感分析的深度模型运行截图
- 4Nginx 配置特定IP访问_nginx只允许指定ip访问
- 5NLP案例——命名实体识别(Named Entity Recongition)_nlp命名实体识别
- 6uibotrga初级/中级认证选择题答案_uibot初级认证选择题答案
- 7自定义view的简单实现(一)_简单实现自定义view
- 8cadence从原理图到pcb_cadence原理图转pcb
- 9LabelMe和x-anyLabeling标注工具的合二为一版_anylabelme
- 10brew常见命令 自用 实践笔记_慎用 brew upgrade
OCR——数据集调研_ocr数据集
赞
踩
调研数据集:ICDAR2015,ICDAR2017,ICDAR2019,CTW1500
ICDAR2015:
challenge:文字检测不仅要在自然场景下完成,而且字体变化如模糊、倾斜、背景干扰等。
1. 文本定位 Text Localization
(1)任务:用四边形对文本区域(单词或文本行)进行画框,并标识出画框区域内对应的文本内。
(2)数据集简介:
训练集:1000张图像+文本文件
测试集:500张图像+文本文件
图像标签:

注:LEADERSHIP,THROUGH这几处文本,其中###表示该文本区域不是我们关注的区域,一字或两个字符的单词以及被认为不可读的单词。我们以LEADERSHIP文本标注为例,前面8个数字为图片中文本的矩形框4个点的坐标(顺时针方向)
(3)比赛排名(前三):

注:TextFuseNet 武汉大学和悉尼大学,TH 清华大学和现代汽车集团AIRS公司, JDAI 京东智联云和中山大学
2. 单词识别 Word Recognition
(1)数据集简介:
训练集 4468图像+文本
测试集:2077图像+文本
图像标签:

注:对于每个单词,将提供紧密包含该单词的区域,作为边界框的四个角以顺时针的方式给出。
(2)比赛排名(前三):

注:SogouMM 搜狗,Hancom Vision 团队, Sogou_OCR 搜狗
3. 端到端识别 End-to-End
(1)数据简介:
训练集:1000张图像
测试集:500张图像
图像和图像对应的基本标注文件和文本定位数据集一样,比 文本定位 数据集 多了两个txt文件。
文件1:训练集中出现的所有单词(3个字符或更长的单词,只包含字母)

文件2:每张图像100个单词,包括图像中出现的单词和干扰物

(2)比赛排名(前三):

注:Alibaba-PAI 阿里巴巴-PAI OCR团队,Sougo_MM 搜狗, Baidu VIS v2+ 百度
(3)参考文章:
https://rrc.cvc.uab.es/?ch=4&com=tasks
https://zhuanlan.zhihu.com/p/60459597
https://blog.csdn.net/weixin_45779880/article/details/105642393
ICDAR2017:
challenge:增加了多国语言的文字检测
1. ICDAR2017-MLT(Competition on Multi-lingual scene text detection)自然场景多语言文本检测
(1)任务:文本定位 Text Localization,Script identification 脚本识别,Joint text detection and script identification 联合文本检测和脚本识别
(2)数据集介绍:
该数据集由9000张(训练7200,测试1800)多种混合语言标注的自然场景图片构成(中文,日文,韩文,英文,法文,阿拉伯文,意大利文,德文和印度文 9种语言),标注形式为四点标注,坐标格式顺时针坐标。
标注格式:x1,y1,x2,y2,x3,y3,x4,y4,脚本,转录

注:如果将抄写提供为“ ###”,则将文本块(单词)视为“无关紧要”。一些“无关”单词具有与一种语言相对应的脚本类,而其他一些则具有“无”脚本类。后一种情况是由于分辨率低或其他分类而无法识别单词脚本的情况。
(3)比赛排名(前三):
1)文本定位 Text Localization

注:AntAI Cognition Ant Financial AI部门和北大,TH 清华大学和现代汽车集团AIRS公司,Sougou_OCR 搜狗
2)Script identification 脚本识别

注: 4Paradigm-Data-Intelligence 第四范式
3)Joint text detection and script identification 联合文本检测和脚本识别

注: 4Paradigm-Data-Intelligence 第四范式,PMTD + CNN based method属于NCIA,首尔国立大学
(4)参考文章:
https://rrc.cvc.uab.es/?ch=8&com=tasks
2. ICDAR2017-RCTW (Reading Chinest Text in the Wild)
(1)数据集介绍:
主要是中文,共12263张图像,其中8034作为训练集,4229作为测试集(只有图片无GT),标注形式为四点标注。
数据集绝大多数是相机拍的自然场景,一些是屏幕截图。包含了大多数场景,如室外街道、室内场景、手机截图等等。
图像细节:
1)图像分辨率大小不等,小则300+,大则3000+
2)图像清晰程度不一,绝大多数背景和文字很清晰,极少数模糊
1)街道场景:主要是建筑、标志牌、条幅等带有文字的图像,这类场景占据大多数
2)截图:主要是网络上带有文字的图像截图、手机上带有文字的图像截图、带文字的表情包图像
3)室内:主要是商场、墙壁等带有文字的图像
4)证件类:主要是车牌照、驾驶证、身份证等带有文字的图像
文本
1)方向(multi-oriented):图像中的文本方向水平、垂直、倾斜均有,绝大多数是水平方向,弯曲方向极少数
2)大小(multi-scale):由于图像拍照远近,图像有近距离或远距离的,因此文本大小不等,有较多的长文本
3)质量:少数文本存在模糊、光照不均匀、低分辨率等情况
4)字体:绝大多数字体为楷书,极少数艺术字,几乎没有手写字体
5)遮挡:绝大多数文本没有遮挡,极少数有遮挡
数据集的标注保存在<image_nam>.txt文件中,其中格式如下:
x1,y1,x2,y2,x3,y3,x4,y4,<识别难易程度>,<"文本">
x1,y1,x2,y2,x3,y3,x4,y4,<识别难易程度>,<"文本">
x1,y1,x2,y2,x3,y3,x4,y4,<识别难易程度>,<"文本">

注:x1,y1,x2,y2,x3,y3,x4,y4分别为左上、右上、右下、左下四个坐标,值为像素值。
<识别难易程度>以0或1表示,0表示容易识别,即图像中文本清晰可见;1表示很难识别,即图像中文本较小或模糊不清楚。评测模型的实验结果可以用到,困难的都能检测和识别出来的话,会证明模型很好。
<"文本">中如果有不清楚的字符,以#表示。如果文本完全不清楚,很难识别(对应<识别难易程度>=1),则以"###"表示。
(4)参考文章:
https://blog.csdn.net/wl1710582732/article/details/89761818
http://rctw.vlrlab.net/dataset/ (官网已关闭)
ICDAR2019:
1. ICDAR2019-MLT
(1)任务:文本定位,脚本识别,联合文本检测和脚本识别,端到端文本检测与识别
(2)数据集介绍:
该数据集由20000张(训练10000,测试10000)多种混合语言标注的自然场景图片构成,标注形式为四点标注,坐标格式顺时针。
标注格式:x1,y1,x2,y2,x3,y3,x4,y4,语言类别,text
10,000个图像在训练集中排序,使得每个连续的1000个图像包含一种主要语言的文本(当然它可以包含来自1种或2种其他语言的附加文本,全部来自10种语言的集合)
00001 - 01000 :Arabic
02001 - 03000:French
03001 - 04000:Chinese
04001 - 05000:German
05001 - 06000:Korean
06001 - 07000:Japanese
07001 - 08000:Italian
08001 - 09000:Bangla
09001 - 10000:Hindi

(3)比赛排名(前三):
1)文本定位 Text Localization

注:TH 清华大学和现代汽车集团AIRS公司
2)Script identification 脚本识别

3)Joint text detection and script identification 联合文本检测和脚本识别

4)End-to-End text detection and recognition 端到端文本检测与识别

(4)参考文章:
https://rrc.cvc.uab.es/?ch=15&com=evaluation&task=1
2. ICDAR2019-LSVT (Large-scale Street View Text with Partial Labeling,弱标注大规模街景文字)
(1)任务:文本检测,端到端文字检测加识别(scene text spotting)
(2)数据集介绍:
该数据集由45w中文街景图像,包含5w(2w测试+3w训练)全标注数据(文本坐标+文本内容)构成,40w弱标注训练数据(仅文本内容),标注形式为可以是4、8、12个多边形顶点标注。
所有图像都是从街道上捕获的,街道上有各种各样复杂的现实世界场景,例如店面和地标。
标注格式:json格式标签

具有完整注释:
这些图像中显示了真相位置和相应的文本。黄色标记的字符包括中文,数字和拉丁字符。
带标签的文本区域展示了数据集中文本的多样性,包括水平文本,垂直文本,弯曲文本和具有透视失真的文本。水平和垂直文本用四边形注释,而弯曲文本实例用多边形边界区域注释。

弱标注数据:

弱注释的图像:
只有感兴趣的文本的转录。

注:其中,test数据集的label目前没有开源,如要评估结果,可以去官网提交:
(3)两个任务的比赛排名(前三):
1)文本检测

注:Tencent 腾讯,NJU 南京大学
2)端到端文字检测加识别

注:Tencent 腾讯,HUST 华中科技大学,PMTD(不清楚)
(4)参考文章
https://blog.csdn.net/qq_41895190/article/details/103253897
3. ICDAR2019-ReCTS(Robust Reading Challenge on Reading Chinese Text on Signboard 在招牌上阅读中文文本)
(1)任务:字符识别,文本行识别,文本检测,端到端文字检测加识别(scene text spotting)
(2)数据集介绍:
train:20000 test:5000 (混合语言)
标注格式:json格式标签
一个单词或文本行中的字符可以采用不同的字体,不同的方向或以不规则的布局分布(请参见图1a,1b,1c)。
以前的基于单词的阅读系统很难处理不规则的布局,例如三角形,如图2所示。在这种情况下,应考虑字符及其关系以语义方式阅读它们。
不仅注释文本行,而且注释字符,包括位置和字符代码,这可以激发和推动利用字符排列的新算法。


(3)四个任务的比赛排名(前三):
1)字符识别

注:IFLYTEK 科大讯飞,阿里安全图灵实验室的ATL Cangjie OCR算法
2)文本行识别

注:Eleme 饿了么,PingAn 中国平安保险股份公司,HIK 海康威视
3)文本检测

注:Tencent 腾讯
4)端到端文字检测加识别

注:NSTD-MCEM-iFLYTEK(不清楚),SCUT 华南理工大学,Tencent 腾讯
(4)参考文章:
https://rrc.cvc.uab.es/?ch=12&com=introduction(官网)
4. ICDAR2019-ArT (Arbitrary-Shaped Text,任意形状场景文字)
(1)任务:1、场景文字检测 (输出坐标和置信度)2、场景文字识别(识别裁剪图像补丁中的每个字符,输出一串预测字符) 3、端到端文字检测加识别(scene text spotting)
(2)数据集介绍:
语言: 混合 train:5603 test:4563
标注格式:json格式标签


标注:

其中“点”中的x1,y1,x2,y2,...,xn,yn是多边形边界框的坐标,可以是4、8、10、12个多边形顶点。
“转录”表示每个文本行的文本,“语言”表示转录的语言类型,可以是“拉丁”和“中文”。
“模糊性” 表示“无关”文本区域,当设置为“ true”时,这不会影响结果。
(3)三个任务的比赛排名(前三):
1)场景文字检测

2)文字识别

3)文字检测加识别端到端的做法

注:1-N.E.D 归一化编辑距离度量
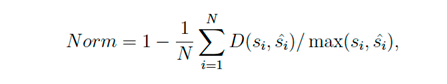
(4)参考文章:
SCUT-ctw1500(A Large Chinese Text Dataset in the Wild 任意形状的数据集标签)
(1)任务:针对弯曲文本检测的数据集
(2)数据集介绍:1500个图像(train1000,test500),10,751个边界框(3,530个是曲线边界框),每个图像至少有一个曲线文本。 这些图像是从互联网手动收集的,图像库如谷歌 Open-Image 和手机摄像头收集的数据,其中还包含大量水平和多向文本。 图像的分布是多种多样的,包括室内,室外,天生数字,模糊,透视畸变文本等。 此外,数据集是多语 言的,主要是中文和英文文本。
数据集图片:

标注:

注:每行共32个数字,前四个数字为该弯曲文本在整张图上的矩形框坐标值。
剩下的28个值为14个点,为相对于矩形框左上角的误差补偿即为与左上角坐标所形成的差值,形成封闭的弯曲文本框。
其计算方式可以简单的理解为:
1.将前4个坐标值的矩形框从原图中截取出来(左上右下4个点)
2.再截取之后的图中取14个点的坐标值
标注:

(3)参考链接和文章:
数据集的Paper《Detecting Curve Text in the Wild: New Dataset and New Solution》
github:https://github.com/Yuliang-Liu/Curve-Text-Detector
https://www.icode9.com/content-4-644848.html
待续

