
- 1分布式机器学习的模型并行与数据并行_分布式机器学习中数据并行和模型并行
- 2code-server on ubuntu-server_ubuntu codeserver
- 3WEB前端(2)—— HTML经典案例
- 4使用deepsort重新训练自己的多目标跟踪模型,以及Market1501和MARS数据集的介绍_deepsort模型训练
- 5【Devchat-AI】编程得力助手,DevChat会让你对编程有新理解新认识_编程助手
- 6Flink(58):Flink之FlinkCDC(上)_flink cdc 和flink
- 7Windows 8 安装SQL 无法登录问题解决方法
- 82024年华为OD机试真题-路口最短时间问题-Java-OD统一考试(C卷D卷)_路口最短时间od
- 9乡村振兴与乡村规划:科学规划乡村发展蓝图,合理布局乡村产业,打造宜居宜业的美丽乡村
- 10Gartner发布2024年网络安全9大趋势_gartner2024年网络安全八大关键预测》
【自然语言处理六-最重要的模型-transformer-上】_transformerencoder的输出一般怎么接全连接层
赞
踩
什么是transformer模型
- 它是编码器和解码器的架构,来处理一个序列对,这个跟seq2seq的架构是一样的。
如果没接触过seq2seq架构,可以通俗的理解,编码器用来处理输入,解码器用来输出 - 但与seq2seq的架构不同的是,transformer是纯基于注意力的。
之前花了几篇的篇幅讲注意力,也是在为后面讲解这个模型打基础。
transformer模型无疑是近几年最重要的模型,目前的大模型几乎都以它为基础发展,很多模型的名字都带有缩写T,正是transformer的缩写。
当然transfomer不仅仅用于自然语言处理领域,归集于自然语言处理模块下面来讲,是因为它在自然语言处理领域的应用非常广泛,下面就讲它的几种应用。
transformer 模型在自然语言处理领域的应用
编码器和解码器架构,比较擅长处理QA类的问题,但这个QA不仅仅是一个问题、一个答案的形式,许多的自然语言处理,都可以理解为QA类问题,比如:
- 真实的QA类问题。比如:机器人问答。
- 机器翻译。比如中英翻译
- 摘要提取。输入文章,提取摘要
- 情感分析。输入评价,输出正面/负面评价
等等
下面来介绍transformer的架构,看什么样子的架构能实现上面的这些功能
transformer 架构
它出自经典论文《attention is all you need》,论文地址是: http://arxiv.org/abs/1706.03762,本文中的诸多图片都是取自该论文,下面的架构图也是出自论文
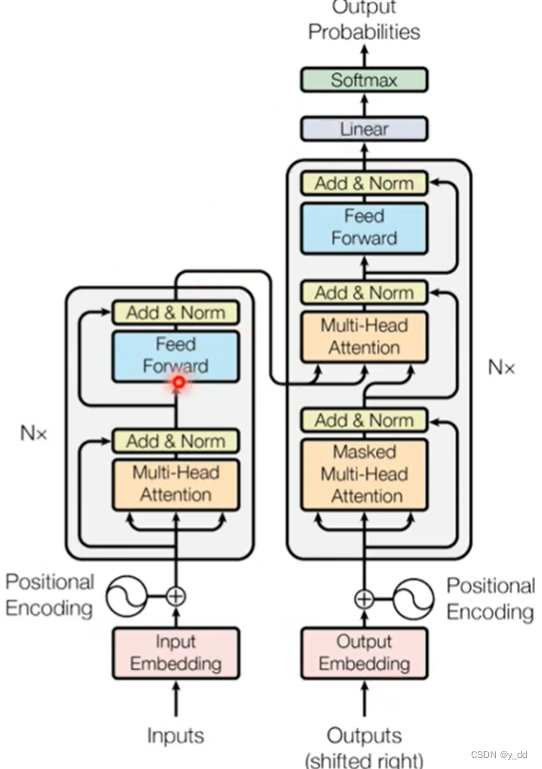
从上图就可以看出,transfomer的架构包括左边encoder和右边decoder,下面先来讲encoder部分
encoder
左侧的encoder部分,输入一排input vector向量,输出一排向量,忽略中间的细节来看,是如下的的架构:
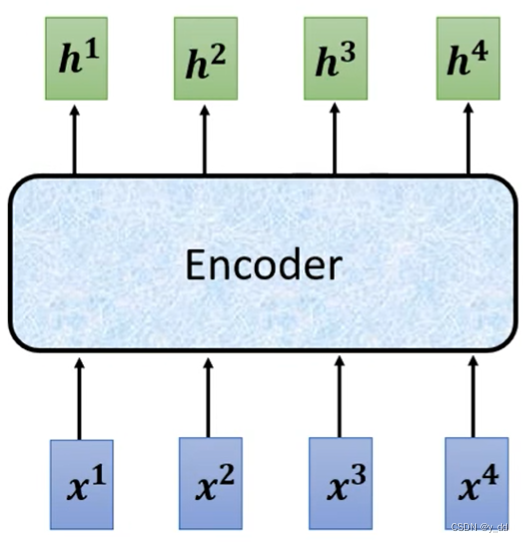
中间encoer部分,如果是seq2seq架构,就是RNN,transformer就相对复杂一些:
下面分部分介绍encoder的各个部分:
input处理部分(词嵌入和postional encoding)
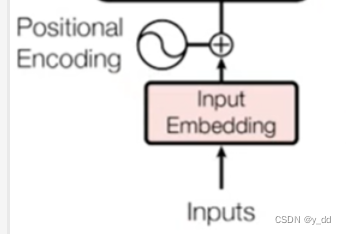
输入一排,经过词嵌入input Embedding,再加上位置信息,Postional Encoding (这部分可以在 位置编码有介绍),生成一排向量。
然后进入attention计算
attention部分
transformer最重要的attention部分,这部分是多头注意力。值得注意的是,这部分的输出并不会直接丢给全连接层,还需要在额外经过residual add和layer norm
add
add的操作:
执行residual 残差连接,将attention的输入加到self-attention后的输出
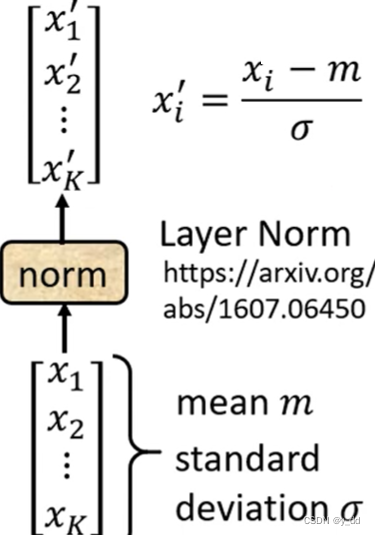
Norm
残差后的输出进行层归一化,层归一化的操作:
不考虑batch,将输入中同一个feature,同一个sample,不同的dimension 计算均值和标准差,然后如下计算
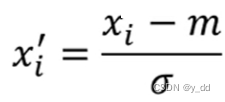
这个操作,用能听得懂的话翻译一下就是,是对每个样本里面的元素进行归一化
整个过程如下:
最终上述部分的输出作为全连接层的输入
Feedforward & add && Norm
上一部分的输出,输入到本部分
Feedforword,实际上就是两层全连接层,中间有激活函数等
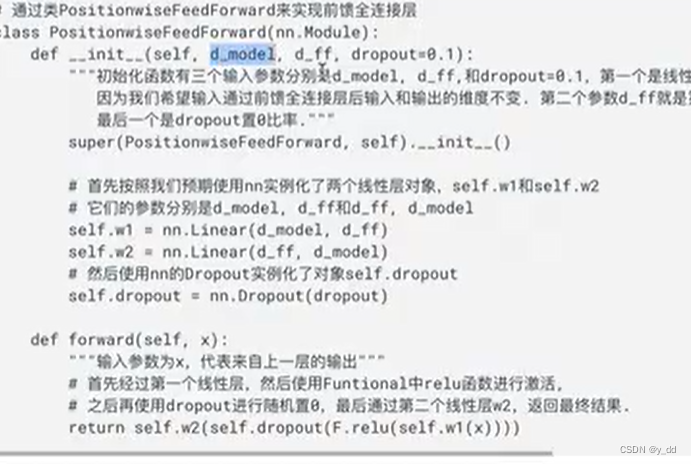
当然中间的卷积,可以换成线性层Linear
经过这个全连接层的输出之后,依然要经过残差add 和层归一化norm,然后输出.
add & Norm
这部分 同attention 那一层的操作,此处不赘述
最终encoder的输出
在encoder中,上面这三个步骤是可以重复多次的,所以看到架构图中表示了*N操作。
最终的输出才是encoder的输出。
篇幅所限,下一篇文章继续 transformer的decoder部分 自然语言处理六-最重要的模型-transformer-下

