
热门标签
热门文章
- 1Python 学习 ---> 函数、函数式编程、高阶函数、匿名函数、偏函数
- 2git clone 报错过早的文件结束符(EOF)_git clone eof
- 3Spring6入门_使用spring6的话spring-test的maven版本应该是多少
- 4java实现excel导入与导出(总结与实现)_java excel 导出
- 5如何在JMeter中玩懂KAFKA_jmeter kafka
- 63D绘图 WebGl引擎----ThreeJS 3D渲染引擎_webgl 图片转成3d
- 7利用docker-compose 安装 flowable-ui 工作流_docker-compose flowable
- 8基于FPGA的五子棋(论文+源码)_基于fpga的五子棋游戏论文
- 928岁从事功能测试被辞,面试2个月都找不到工作吗?
- 106月13日 植物大战僵尸杂交版 v2.1 Mac版下载 新增商店/背包
当前位置: article > 正文
python图片中文字识别_m1 python图片识别
作者:Guff_9hys | 2024-07-08 18:59:07
赞
踩
m1 python图片识别
一、前言
不知道大家有没有遇到过这样的问题,就是在某个软件或者某个网页里面有一篇文章,你非常喜欢,但是不能复制。或者像百度文档一样,只能复制一部分,这个时候我们就会选择截图保存。但是当我们想用到里面的文字时,还是要一个字一个字打出来。那么我们能不能直接识别图片中的文字呢?答案是肯定的。
二、Tesseract
文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别。Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别。但是在此之前我们需要完成一个繁琐的工作。
(1)Tesseract的安装及配置
Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/ ,我们可以看到如下界面:
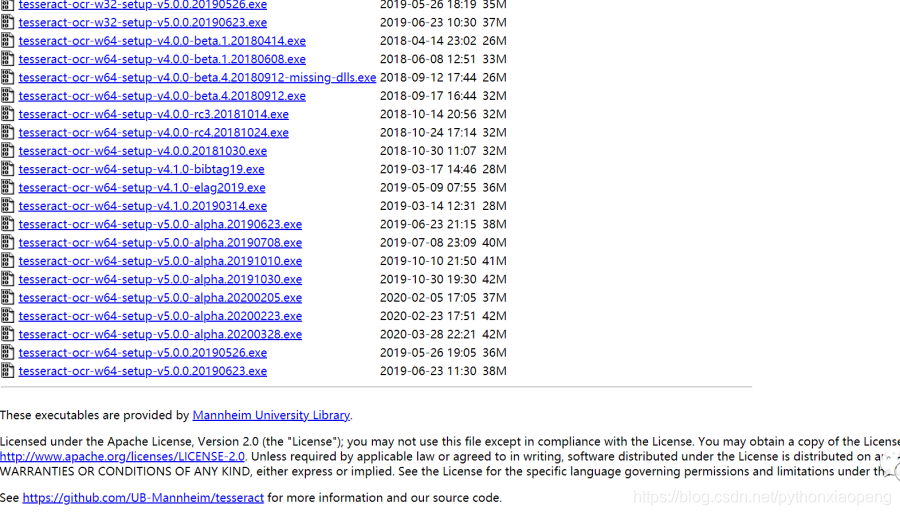
有很多版本供大家选择,大家可以根据自己的需求选择。其中w32表示32位系统,w64表示64位系统,大家选择合适的版本即可,可能下载速度比较慢。安装时我们需要知道我们安装的位置,将安装目录配置到系统path变量当中,我们路径是D:\CodeField\Tesseract-OCR。
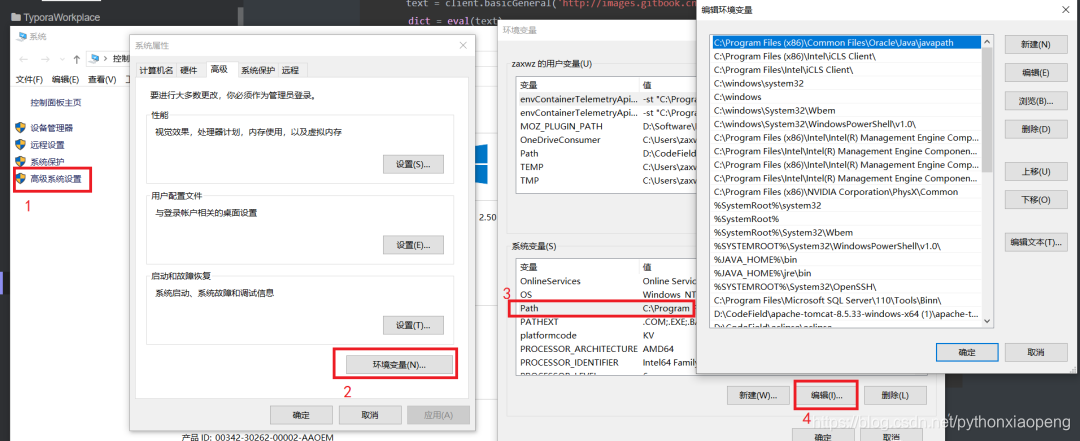
我们右击我的电脑/此电脑->属性->高级系统设置->环境变量->Path->编辑->新建然后将我们的路径复制进去即可。添加好系统变量后后我们还需要依次点确定,这样才算配置好了。
码字不易废话两句:有需要学习资料的或者有技术问题交流 “点击” 即可
(2)下载语言包
Tesseract默认是不支持中文的,如果想要识别中文或者其它语言需要下载相应的语言包,下载地址如下:https://tesseract-ocr.github.io/tessdoc/Data-Files ,进入网站后我们往下翻:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/799805
推荐阅读
相关标签

