
- 1AI大模型引领金融创新变革与实践【文末送书】_金融加ai
- 2数据分析师学习路线与就业环境分析报告
- 3轻量级状态机框架 Sateless4j 实践_stateless4j permitdynamic
- 4STL复习-序列式容器和容器适配器部分
- 5#29 – User authentication failed问题总结_esm failure
- 6使用Github Actions自动同步到Gitee仓库_github gitee 自动同步github action
- 7vue的生命周期和父子组件渲染(需要结合react进行比较)_vue和react父子组件渲染周期对比
- 8go的爬虫工具教你如何去翻译(go调用js,colly的使用)_colly 执行js
- 9残差网络(ResNet)_residualblock
- 10pyqt5 QTimer使用_qtpy qtimer
小米发布SDXS,大幅增强SD图像生成速度,单个GPU实现SD1.5每秒钟100张图,SDXL每秒30张图_stable sdxs
赞
踩
小米也发布了一个大幅增强SD图片生成速度的项目SDXS,可以在单个GPU 上实现SD1.5每秒100张图的生成速度,SDXL每秒30张图。
推测是为了在小米的本地设备上运行 SD模型而研究的。比如博主本人之前参与研发的小米手机相册的AI写真功能。

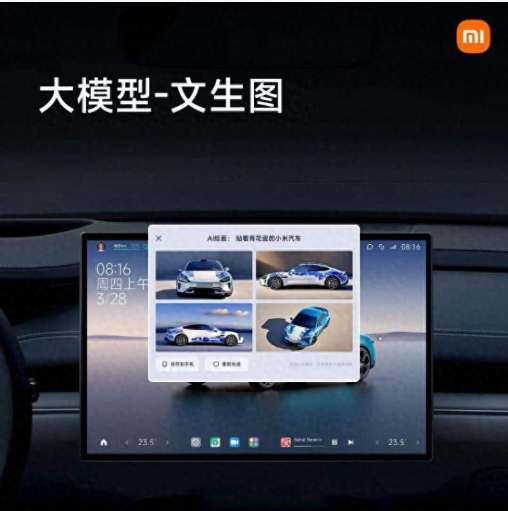
以及昨天发布的小米汽车也展示了相关的文生图功能。
相关链接
项目地址:https://github.com/IDKiro/sdxs
论文地址:https://arxiv.org/abs/2403.16627
模型地址: https://huggingface.co/IDKiro/sdxs-512-0.9
论文阅读

具有图像条件的实时一步潜伏扩散模型
摘要
最近扩散模型的发展使它们处于图像生成的前沿。尽管扩散模型性能优越,但并非没有缺点;
它们具有复杂的架构和大量的计算需求,由于其迭代采样过程而导致显著的延迟。为了降低这些限制,我们引入了一种涉及模型小型化和减少采样步骤的双重方法,目的是显著降低模型延迟时间。
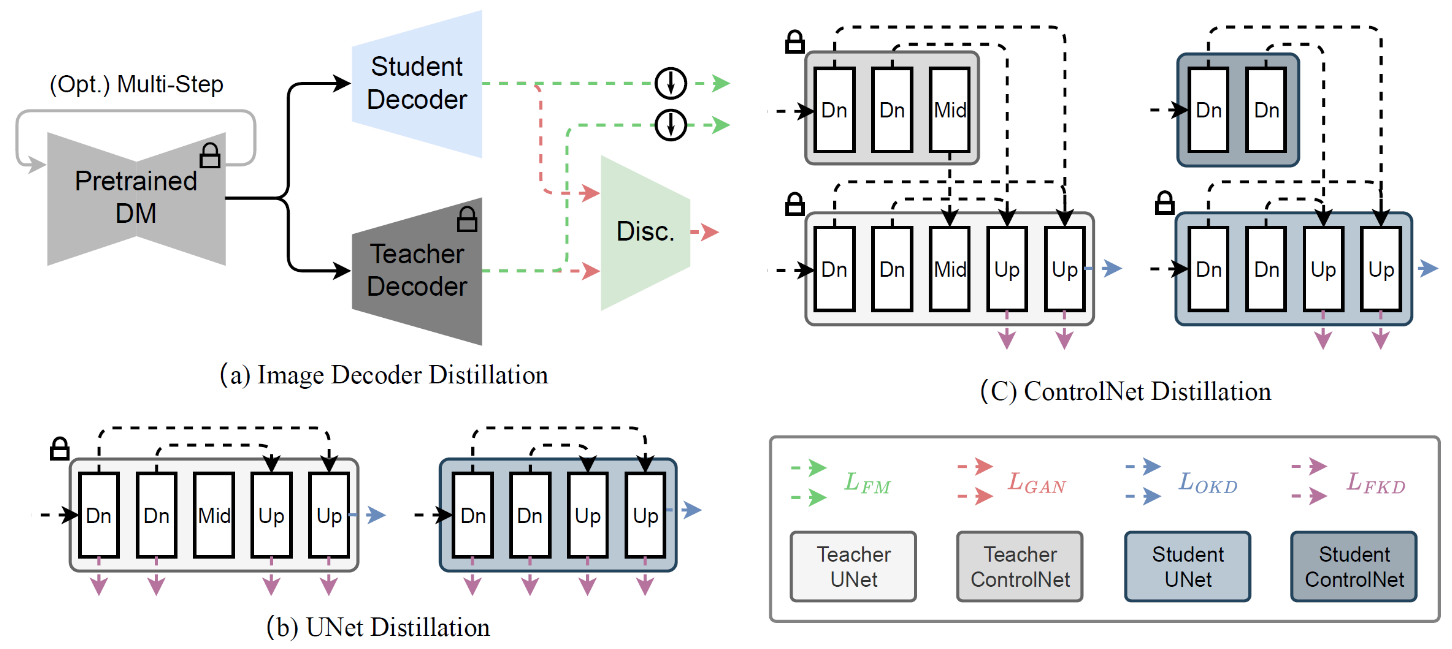
我们的方法利用知识蒸馏来简化U-NET和图像解码器的架构,并引入了一种创新的一步管理培训技术,利用特征匹配和评分蒸馏。
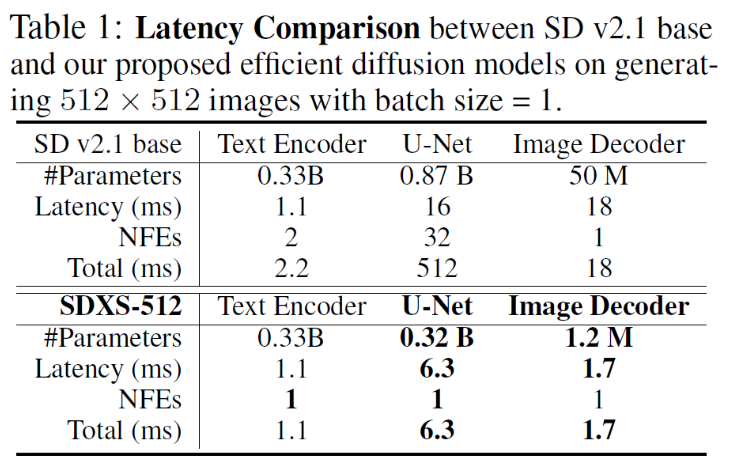
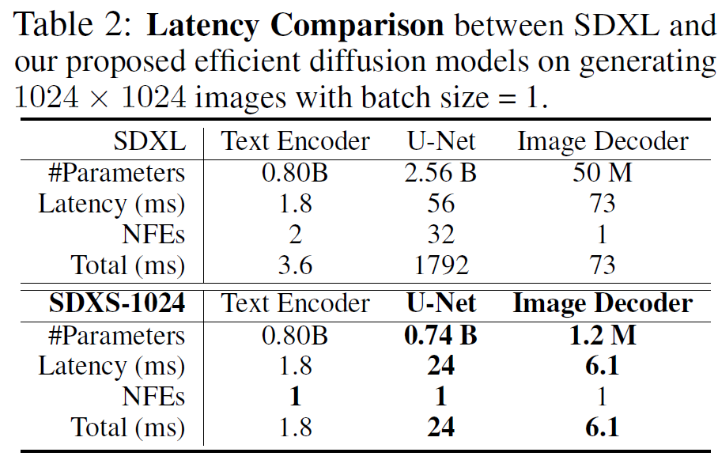
我们提出了两个模型,即SDX-512和SDX-1024,实现了大约 100 FPS (30x faster than SD v1.5) and 30 FPS (60x比sdxl快),分别在单个的GPU上。
此外,我们的培训方法在图像条件控制中提供了有前途的应用,促进了有效的图像转换。
概述
假设图像生成时间限于1秒,sdxl只能使用16个nfes来产生轻微模糊的图像,而sdxS-1024可以产生30个清晰的图像。除此之外,我们提出的方法也可以训练控制网。




方法
模型加速度
SDXS训练了一个极轻的图像解码器,通过输出精馏损失和甘氏损失的组合来模拟原始的VAR解码器的输出。还利用块清除蒸馏战略,有效地将知识从原来的U网络转移到更紧凑的版本。
SDXS显示的效率远远超过了基本模型,甚至在GPAR上的512x512图像和1024图像上的100FPS的图像生成。
文本到图像
为了减少NFES,我们建议通过用特征匹配损失代替蒸馏损失函数,来修正采样轨迹,快速地将多步骤模型调整为一步模型。然后,我们扩展了扩散训练策略,利用所提出的特征匹配损失的梯度来取代后半段分选精练提供的梯度。
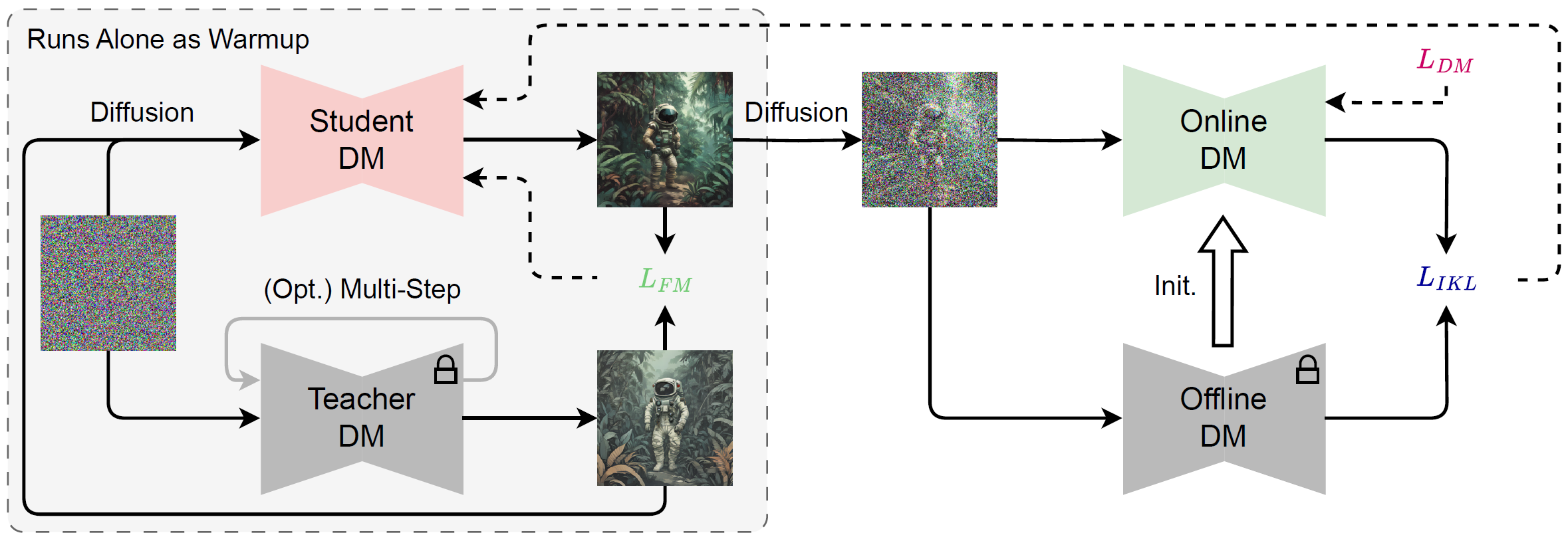
尽管模型的规模和所需取样步骤的数目都明显缩小,但SDX-512的快速跟踪能力仍高于SDV1.5。这一观察在SDX-1024的性能中得到了一致验证。

图像对图像
我们将我们提出的训练策略扩展到控制网的训练,依靠增加预先训练的控制网的得分功能。
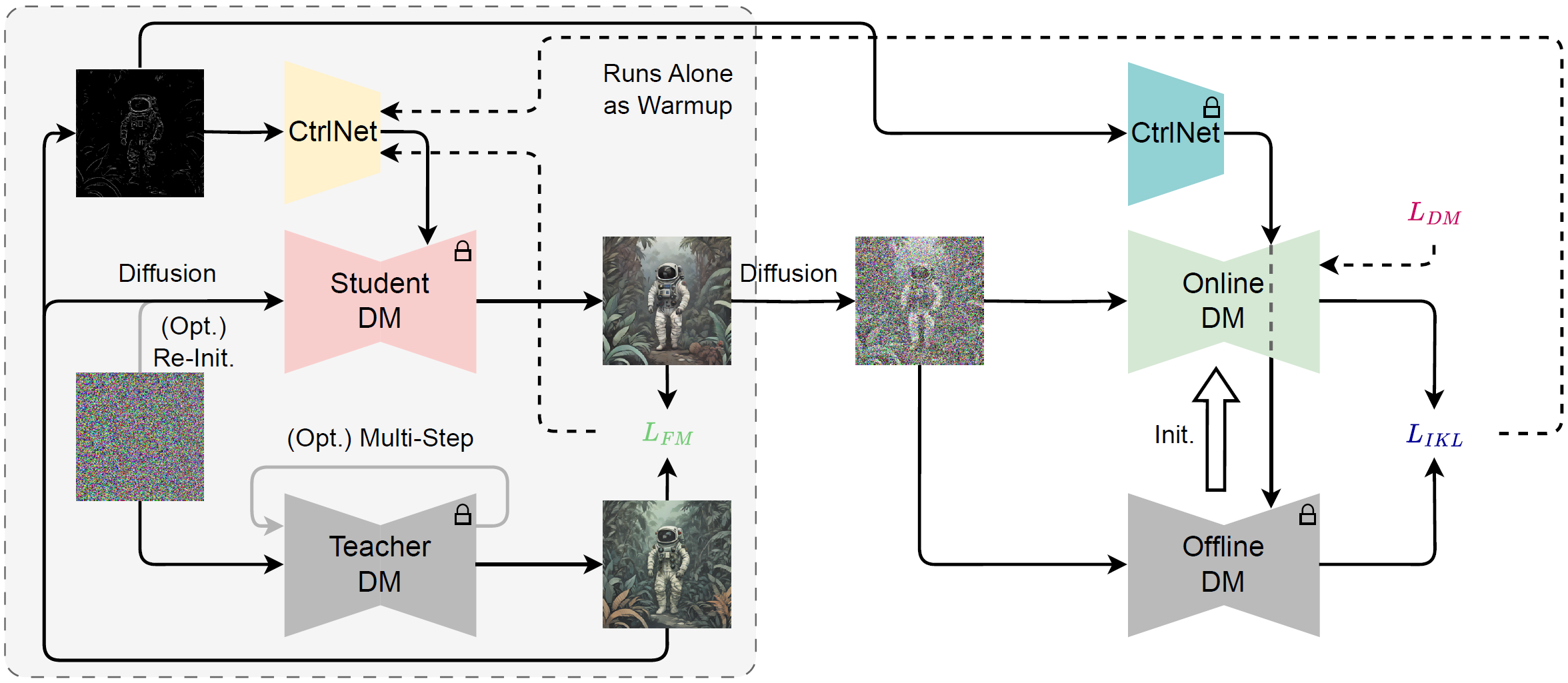
我们展示了它在利用控制网促进图像转换方面的有效性,特别是在涉及到精明边缘和深度地图的转换方面。

感谢你看到这里,也欢迎点击关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

