
- 1华为的热机备份和流量限制
- 2前端7大常用布局方式_前端布局
- 3超简单,手把手教你在本地运行Llama 3大模型_ollama run llama3
- 4直播系统源码性能调优方案最全最详细
- 5【项目开发记录】微信小程序_colorui底部导航栏
- 6基于Hadoop2.7.2+ ICTCLAS2015的并行化中文分词
- 7HarmonyOS Next开发学习手册——UI开发 (兼容JS的类Web开发范式)
- 8信创基础软件之信创云介绍_信创软件
- 9英伟达A100、A800、H100、H800、V100以及RTX 4090的详细性能参数对比_a100 a800 h100 h800
- 10基于复旦微的 FMQL45T900 ARM+FPGA+AD全国产化解决方案,兼容XILINX的XC7Z045-2FFG900I (即ZYNQ7045)
论文理解【图像处理_sidd数据集
赞
踩
《CycleISP: Real Image Restoration via Improved Data Synthesis》
论文地址:https://ieeexplore.ieee.org/document/9156752
提出了一个框架,该框架在正向和反向方向上对相机成像管道进行建模。它允许我们生成任意数量的真实图像对,以便在RAW和sRGB空间中进行去噪。通过在逼真的合成数据上训练新的图像去噪网络,我们在真实相机基准数据集上实现了最先进的性能。我们模型中的参数比以前的最佳RAW去噪方法少约5倍。
在实践中,由于照明条件和相机/物体运动的变化,空间像素错位,颜色和亮度不匹配是不可避免的。此外,这种昂贵而繁琐的采集图像对的练习需要用不同的相机传感器重复,因为它们表现出不同的噪声特性。
常用方法:单图像去噪主要在合成设置中执行:拍摄大量干净的sRGB图像并添加合成噪声以生成其噪声版本。但与传统方法相比,它们对真实相机数据的泛化较差。
本文方法:主要思想是在通过我们学习的与设备无关的转换获得的RAW图像中注入噪声**,而不是直接在sRGB图像中注入噪声。数据集为MIT-Adobe FiveK数据集[10,Vladimir Bychkovsky, Sylvain Paris, Eric Chan and Frédo Durand, “Learning photographic global tonal adjustment with a database of input/output image pairs”, CVPR, 2011.]
关键见解:sRGB图像中存在的真实噪声被常规图像信号处理(ISP)流水线复杂化了。(原文:The
key insight behind our framework is that the real noise present in sRGB images is convoluted by the series of steps performed in a regular image signal processing (ISP) pipeline [6, 46].)例如RAW数据的噪声与信号相关,经过去马赛克处理后变为与时空与色度相关,经过ISP的其他处理后噪声不一定保持为高斯噪声。因此若要合成经过ISP处理后产生的噪声,需要用更复杂的模型。
本文需要解决的问题:将互联网上大量可用的sRGB图片转换回RAW测量值。
方法:提出CycleISP框架。CycleISP框架先将sRGB图像转换为RAW数据,再从RAW还原为sRGB图像,而无需任何相机参数知识。此属性允许我们在RAW和sRGB空间中合成任意数量的干净逼真的噪声图像对。
贡献:此转换无关设备,能够在RAW和sRBG之间来回转换;能够在RAW和sRGB空间中生成干净/嘈杂的配对数据;具有双重注意力机制;参数更少;除了去噪还实现了图像质量的提升
相机ISP将RAW传感器噪声转换为复杂的形式(时空色度相关,不一定是高斯)。(原文:The camera
ISP transforms RAW sensor noise into a complicated form(spatio-chromatically correlated and not necessarily Gaussian))
第三节描述将相机ISP建模为CNN。另外引入了辅助色彩校正网络分支,为RAW2RGB网络提供显式色彩关注,以便正确还原RAW的信息。

RGB2RAW
首先得到RGB图片I,然后通过卷积层M0获得低层特征图T0。继续通过N个用于提取深层特征Td的递归残差群(RRG,recursive residual group)
T d = R R G N ( … ( R R G 1 ( T 0 ) ) ) , (1) T_{d}=RRG_{N} (\ldots(RRG_{1}(T_{0}))), \tag{1} Td=RRGN(…(RRG1(T0))),(1)
每个RRG包含多个双重注意块。Td经过最后的卷积层M1得到图片I’,且M1的输出为三通道,以尽可能保存更多原始图像的结构信息,同时此结构也帮助网络更快、更准确的学习到从sRGB到RAW的映射。此结构仍可复原经过色调映射、伽马矫正、色彩校正、白平衡等的图片,使图片像素与场景辐射值线性相关。
为了生成经过马赛克的RAW图片Iraw,将参考拜尔模式(Bayer,即省略两个颜色通道)的函数Fbayer应用于以上步骤生成的结果。
I ^ ∗ r a w = f ∗ b a y e r ( M 1 ( T d ) ) . (2) \hat{\mathbf{I}}*{raw}=f*{bayer}(M_{1}(T_{d})).\tag{2} I^∗raw=f∗bayer(M1(Td)).(2)
RGB2RAW网络用L1损失在线性和log域进行优化。
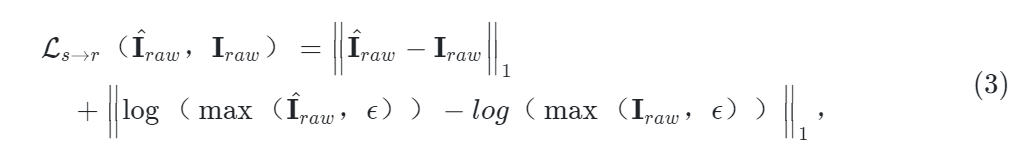
ε是数值稳定的极小值。Iraw是真实值,I’raw是生成的结果。log使图像像素值大致相等,使网络将更多注意力放在突出显示的区域。
RAW2RGB
为了保证转换前后的稳定性并降低计算成本,将Iraw中的像素点以2*2为单位转换为RGGB的四通道图片,从而将图像分辨率降低一半。由于输入RAW数据可能来自不同的相机,因此通过应该拜尔图案统一技术【39】来确保打包图像的通道顺序为RGGB。然后将打包后的RAW图像Ipack通过卷积层M2和K-1个RRG模块得到深层的特征向量Td’。
T d ′ = R R G K − 1 ( … ( R R G 1 ( M 2 ( Pack ( I r a w ) ) ) ) . (4) T_{d^{\prime}}=RRG_{K-1} (\ldots(RRG_{1}(M_{2}(\text{Pack}(\mathbf{I}_{raw})))).\tag{4} Td′=RRGK−1(…(RRG1(M2(Pack(Iraw)))).(4)
注意此处的Iraw不是学习结果,而是从相机中得到的数据,因为这里的目标是独立学习RAW到sRGB的映射。
色彩矫正单元color attention unit
为了解决不同相机的ISP对图片进行的处理的差异,本框架在RAW2RGB中加入色彩校正单元,通过色彩校正分支提供显示的颜色注意。色彩校正分支为CNN,sRGB图片为输入,生成颜色编码的深层特征向量。首先将图片进行高斯模糊处理,然后与卷积层M3、两个RRG和sigmoid激活函数σ。
T c o l o r = σ ( M 4 ( R R G 2 ( R R G 1 ( M 3 ( K ∗ I r g b ) ) ) ) ) , (5) T_{color}=\sigma(M_{4}(RRG_{2}(RRG_{1}(M_{3}(K\ast\mathbf{I}_{rgb}))))),\tag{5} Tcolor=σ(M4(RRG2(RRG1(M3(K∗Irgb))))),(5)
其中*表示卷积,K为参数12的高斯核。高斯模糊保证只有颜色信息经过色彩校正单元分支,结构和精细纹理来自RAW2RGB分支。使用较弱的模糊会破坏特征张量的有效性(4)。整体色彩关注单元流程变为:
T a t t e n = T d ′ + ( T d ′ ⊗ T c o l o r ) , (6) T_{atten}=T_{d^{\prime}}+(T_{d^{\prime}}\otimes T_{color}),\tag{6} Tatten=Td′+(Td′⊗Tcolor),(6)
Td’与Tcolor进行基本积。再将Tatten经过RRG和卷积层M5和上采样层Mup。
I ^ ∗ r g b = M ∗ u p ( M 5 ( R R G K ( T a t t e n ) ) . (7) \hat{\mathbf{I}}*{rgb}=M*{up}(M_{5}(RRG_{K}(T_{atten})).\tag{7} I^∗rgb=M∗up(M5(RRGK(Tatten)).(7)
在优化过程中采用L1损失函数:
L
∗
r
→
s
(
I
^
∗
r
g
b
,
I
∗
r
g
b
)
=
∥
I
^
∗
r
g
b
−
I
∗
r
g
b
∥
∗
1.
(8)
\mathcal{L}*{r\rightarrow s}(\hat{\mathbf{I}}*{rgb}, \mathbf{I}*{rgb})=\left\Vert\hat{\mathbf{I}}*{rgb}-\mathbf{I}*{rgb}\right\Vert*{1}.\tag{8}
L∗r→s(I^∗rgb,I∗rgb)=∥∥∥I^∗rgb−I∗rgb∥∥∥∗1.(8)

RRG递归残差群
RRG包含双重注意力块DAB,作用是抑制不太有用的特征。DAB采用两种注意力机制(1)通道注意(2)空间注意。
T D A B = T i n + M c ( [ CA ( U ) , SA ( U ) ] ) , (9) T_{DAB}=T_{in}+M_{c}([\text{CA}(U),\text{SA}(U)]),\tag{9} TDAB=Tin+Mc([CA(U),SA(U)]),(9)
Mc是1*1卷积层,U是经过卷积后提取的特征向量。
通道注意:通过平均池化、激活函数、
空间注意:最大池化
循环微调
由于RGB2RAW和RAW2RGB网络最初是独立训练的,因此由于它们之间的断开连接,它们可能无法提供最佳质量的图像。因此,我们执行联合微调,其中RGB2RAW的输出成为RAW2RGB的输入。关节优化的损失函数为:
L j o i n t = β L s → r ( I ^ r a w , I r a w ) + ( 1 − β ) L r → s ( I ^ r g b , I r g b ) \mathcal{L}_{joint}=\beta \mathcal{L}_{s\rightarrow r}(\hat{\mathbf{I}}_{raw}, \mathbf{I}_{raw})+(1-\beta)\mathcal{L}_{r\rightarrow s}(\hat{\mathbf{I}}_{rgb},\mathbf{I}_{rgb}) Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb)
合成噪声
The noise injection module adds shot and read noise of different levels to the output of RGB2RAW network. [Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet and Jonathan T Barron, “Unprocessing images for learned raw denoising”, CVPR, 2019.]对任意sRGB生成相应的干净噪声,得到噪声与无噪声的成对图片。利用数据集SIDD,此数据集在RAW和RGB空间内都有成对的噪声与无噪声图片对。

实验
优化器为Adam,图像裁剪为128*128。执行随机水平和垂直翻转。
数据集:
DND[Tobias Plotz and Stefan Roth, “Benchmarking denoising algorithms with real photographs”, CVPR, 2017.],没有ground truth
SSID[Abdelrahman Abdelhamed, Stephen Lin and Michael S Brown, “A high-quality denoising dataset for smartphone cameras”, CVPR, 2018.]
MIT-Adobe FiveK[Vladimir Bychkovsky, Sylvain Paris, Eric Chan and Frédo Durand, “Learning photographic global tonal adjustment with a database of input/output image pairs”, CVPR, 2011.]
评价方法:PSNR,SSIM

